







前言
前面写了吴恩达机器学习前两周的课程内容,第三章是矩阵的预备知识,不再进行总结,本文将从第四章开始。
一、WEEK4:多变量线性回归(Linear Regression with Multiple Variables)
4 - 1 - Multiple Features
本章节主要引入多变量的概念。
week2中讲了单变量的线性回归例子,即y=θ_0+θ_1·x.
如果对模型增加更多的特征,使y = ax+b变成y=ax1+bx2+cx3+……+d的形式,也就是原本的单变量线性回归特征为x,那么多变量回归的特征就是(x1,x2,x3……xn),我们假设n代表特征的数量,这里注意区分,全文中用m表示样本数量,用n表示特征数量,简单来理解就是把数据集看成一张表,m代表数据有多少行,n代表每个数据由多少列的属性构成。
支持多变量的假设 h 表示为:
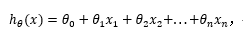
为了统一格式,引入x0=1:
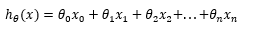
公式可以简化为:
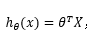
其中T代表转置矩阵,X是一个维度为m*(n+1)的特征矩阵。
4 - 2 - Gradient Descent for Multiple Variables
本章节主要介绍多变量线性回归的代价函数和梯度下降。
与单变量相同,多变量损失函数也由所有建模误差的平方和构成,即:
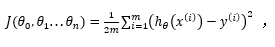
其中:
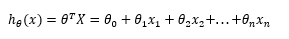
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))
得到代价函数后,优化目的也与单变量代价函数一致,找到使代价函数最小的一组参数,参数更新公式与单变量如出一辙:
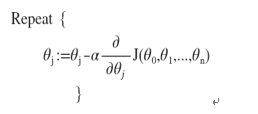
对代价函数J进行展开,进一步得到参数更新公式:
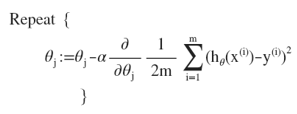
其中,分母中的2m是为了后继求导与2相约方便引入的,如果不引入计算会麻烦一点,为了方便约分所以约定俗成的引入了分母2m。
对其求导可得下面的公式:

这里取j=0,1,2的时候单独看每个参数的更新公式,如下:
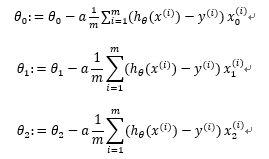
其实只是下标有所变化,这里要明确一下,j 表示第几个参数,i 表示第几个样本,可以看到该公式中所有变量的下标表示第几个参数,上标表示第几个样本,而在参数更新过程中,所有的样本从1~m都参与了第j个参数更新的运算(求和公式)。
4 - 3 - Gradient Descent in Practice I - Feature Scaling
本章节主要讲解特征缩放(归一化)的概念。
引入了多变量概念后,就会有一个问题,不同的变量取值范围可能是不同的,比如有的特征取值是百分比,有的特征取值是几千几万,如果直接用这些取值大小不一且相距很大的数值进行模型训练,通常梯度下降的收敛速度是非常慢且曲折的。此时就需要对特征进行归一化。
如果不对特征进行缩放,其代价函数的等高线图将扁而长,红线代表梯度下降的路线,可以看到相当曲折:
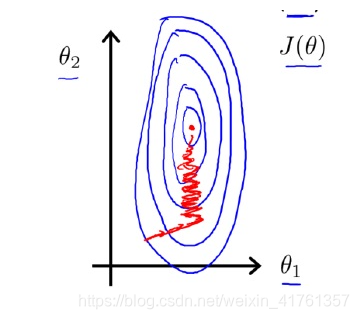
如果对特征进行归一化,尝试将所有特征都缩放到[0,1]之间(或者其他你想归一化的区间),等高线会变得更“圆”,梯度收敛的更快。
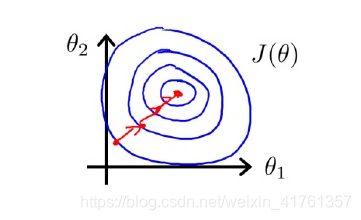
关于为什么归一化等高线图会变“圆”的解释,我觉得这篇文章写得很好,贴出来有兴趣的可以参考一下。
那么就涉及到归一化的方法,常见的有两种,一种是最大最小值归一化Min-Max scaling:
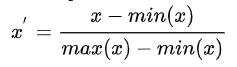
一种是均值标准差归一化Z-score standardization:
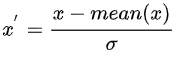
插一个题外话,关于归一化和标准化的区别,归一化约束数据数值到区间[0,1]之间,而标准化约束数值的均值0,方差1.本质上都是对数据进行约束。
4 - 4 - Gradient Descent in Practice II - Learning Rate
本章节主要介绍梯度下降的学习率α
梯度下降算法的每次迭代受到学习率的影响,如果学习率a过小,则达到收敛所需的迭代次数会非常高;如果学习率a过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试这些学习率:α=0.01,0.03,0.1,0.3,1,3,10
4 - 5 - Features and Polynomial Regression
前面提到的都是幂指数为一次的方程,有时直线并不能完全拟合所有数据,需要曲线来拟合,就需要用到多项式。
线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型:
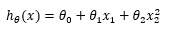
甚至三次方模型:
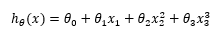
如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要
4-7、4-7正规方程
梯度下降应用的较多,不再对正规方程进行说明了。
week4课后习题
第1题
假设m=4个学生上了一节课,有期中考试和期末考试。你已经收集了他们在两次考试中的分数数据集,如下所示:
| 期中得分 | 期中得分^2 | 期末得分 |
|---|---|---|
| 89 | 7921 | 96 |
| 72 | 5184 | 74 |
| 94 | 8836 | 87 |
| 69 | 4761 | 78 |
你想用多项式回归来预测一个学生的期中考试成绩:
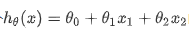
其中x1是期中得分,x2是(期中得分)^2。此外,你计划同时使用特征缩放(除以特征的“最大值-最小值”或范围)和均值归一化。标准化后的特征值是多少?(提示:期中=89,期末=96是训练示例1)
答案: 套公式自己算一下就行。
第2题
用α=0.3进行15次梯度下降迭代,每次迭代后计算J。你会发现的J值下降缓慢,并且在15次迭代后仍在下降。基于此,以下哪个结论似乎最可信?

答案:C
第3题
假设您有一个数据集,每个示例有m=1000000个示例和n=200000个特性。你想用多元线性回归来拟合参数到我们的数据。你更应该用梯度下降还是正规方程?

答案:A
第4题
以下哪些是使用特征缩放的原因?

答案:C
二、WEEK5:Octave教程(Octave Tutorial)
emmm教程我就没啥博客好写了,还是自己看视频吧。














 1983
1983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









