







目录
2.2 语法和知识库驱动的方法-符号主义阶段(20世纪60-80年代)
2.3 统计学习阶段:数据驱动的方法(20世纪90年代-2010年)
2.4.4 WordEmbedding: 深度学习解决语义问题
2.5 预训练语言模型和Transformer时代(2017年-至今)
3.3 循环神经网络(RNN)的基本概念以及它如何在序列学习问题中应用
3.10 GRU单元(Gated Recurrent Unit, GRU)
3.12 双向循环神经网络(Bidirectional RNN)
3.22 嵌入向量的维度之间一定是独立无关的么?一定有清晰的语义特征么?
3.23 情感分类(Sentiment Classification)
3.24 词嵌入除偏(Debiasing Word Embeddings)
3.28 改进集束搜索(Refinements to Beam Search)
3.32 注意力模型(Attention Model) 详解
3.33 触发字检测(Trigger Word Detection)
3.34 《深度学习专项》新增的课程——Transformer
4.1 GRU(门控循环单元)之所以能够选择性地更新或保持记忆的原因是什么?
4.2 GRU如何做到的选择性地更新记忆细胞?也即如何识别哪些词更具备更新价值?
4.7 独热编码经过词嵌入生成的表示,和经过词嵌入又经过自注意力生成的表示有何不同?
4.8 多头注意力表示多次利用自注意力机制,生成多个表示,就和CNN里N个卷积核能生成N个特征一样,你认同这种说法么?为什么?
4.9 “自注意力,顾名思义,就是对句子自己使用注意力机制”。如何理解这句话?
4.10 Transformer是在什么背景下提出的?之前的传统注意力模型不好使么?
4.14 Q、K、V的计算公式中,分母为啥要有一个编辑用于缩放呢?
4.16 每个单词的query, key, value是怎么得来的?
4.18 为啥transformers可以并行,传统的注意力模型不可以。
4.19 Transformer 默认会并行地输出结果。而在推理时,序列必须得串行生成,为什么?
4.20 解码器中,数据还会经过一个多头注意力层。这个层比较特别,它的K,V来自z,Q来自上一层的输出。为什么会有这样的设计呢?
4.21 为什么解码器的多头自注意力层前面有一个masked?
4.23 解码器的嵌入层和输出线性层的权重,编码器的嵌入层的权重,三者有何关联?
0 完整章节内容
深度学习入门指南——2021吴恩达学习笔记deeplearning.ai《深度学习专项课程》篇
1 优质笔记
2 NLP的前世今生
自然语言处理(Natural Language Processing, NLP)作为人工智能的重要分支之一,其发展历程可以大致分为以下几个阶段:早期规则方法、符号主义阶段、统计机器学习、深度学习、以及预训练模型阶段(如BERT)。下面我将从这几个阶段详细介绍NLP的发展历程。
注:本章节将重点关注深度学习阶段和预训练模型阶段。
2.1 早期阶段-基于规则的方法(20世纪50-60年代)
自然语言处理的研究最早可以追溯到20世纪50年代,当时的研究主要依赖于基于规则的方法。这些方法基于预定义的语法规则和词典,由人工编写和维护。
2.1.1 特点
- 手工编写规则:这一阶段,计算机科学和语言学领域的研究者主要依赖人工制定的规则和词典来处理自然语言。系统通过编写大量的语法规则(例如词法、句法规则)和使用词典匹配来进行句子分析和处理。
- 模式匹配:许多早期的系统通过简单的模式匹配来理解和生成语言,系统预先设定了一些问题与回答的模板。由于规则是手动编写的,这种方法对于语料库和语言特征的依赖较低。
2.1.2 典型工作
- 图灵测试(1950年):艾伦·图灵提出了用以测试机器是否具备智能的图灵测试,推动了人工智能和NLP领域的探索。
- 基于规则的机器翻译(1954年):IBM开发了乔治城-IBM实验,这是最早的基于规则的机器翻译系统,主要用于俄语和英语之间的简单翻译。
- 形式语言和自动机理论(20世纪50年代末):Noam Chomsky提出了生成语法理论,开启了形式语言学的研究,对NLP产生了深远影响。
- ELIZA(1966):MIT的Weizenbaum开发了ELIZA,一个模拟心理治疗师的简单对话系统,主要基于简单的模式匹配规则。
2.1.3 局限性
- 规则编写耗时且复杂:每种语言的规则需要人工编写,无法处理语言中的模糊性、多义性和复杂结构,这使得系统开发周期长且难以扩展。
- 泛化能力弱:规则方法只能处理规则覆盖范围内的情况,遇到新的或未覆盖的句子结构时表现不佳。
2.2 语法和知识库驱动的方法-符号主义阶段(20世纪60-80年代)
在20世纪60到80年代,NLP开始探索符号主义(Symbolism),即使用人工定义的规则和知识库来处理语言。
2.2.1 特点
- 符号主义方法:这一阶段,研究者开始探索符号主义(Symbolism)方法,利用形式语法和知识库等符号化手段进行语言分析。研究者认为,自然语言可以通过语法规则和知识库的符号表示来解析。
- 形式语法:利用生成语法(Generative Grammar)等理论,通过语法规则解析句子结构,如短语结构文法(Phrase Structure Grammar)、转换生成文法(Transformational Grammar)等。
- 知识库与语义网络:研究者引入了知识库和语义网络(Semantic Network)来捕捉词汇之间的语义关系,并将语言信息与现实世界的知识联系起来。例如,构建包含实体、概念及其关系的结构化数据库,作为语言理解的基础。
2.2.2 典型工作
- RAP (Rhetorical Analysis Program)(20世纪60年代):美国国防部资助了一系列基于符号方法的NLP研究,如RAP系统。RAP通过识别句子的修辞结构(如原因、结果、目的等)进行分析,并尝试提取文本中的关键信息。
- SHRDLU(1970s):由Terry Winograd开发的SHRDLU系统是早期符号主义方法的代表作之一。SHRDLU工作在一个虚拟的积木世界中,用户可以通过自然语言指令控制积木的移动。该系统使用了一套完整的语法规则,并通过结合领域知识库实现理解和执行用户指令。
- Frame语义理论与FrameNet(20世纪70年代中期):Charles Fillmore提出了框架语义(Frame Semantics)的概念,认为词汇的意义由其在认知框架中的角色来定义。FrameNet项目是这方面的一个重要应用,构建了一个涵盖多种语义框架的数据库,用于分析和理解句子的语义结构。
2.2.3 局限性
- 规模化与维护困难:基于语法规则和知识库的方法需要大量的人工构建和维护,随着语料库的扩大和应用场景的增加,规则和知识库的扩展变得极为困难。
- 语言的多样性和复杂性:符号主义方法过于依赖形式化语法,难以适应人类语言的复杂多变性。特别是面对模棱两可、上下文依赖的句子,这类方法常常无法给出准确的解析。
- 缺乏统计信息:这一阶段的方法没有考虑语言使用中的统计信息,如词的共现概率、句子的概率分布等,导致模型对数据中存在的语言模式缺乏泛化能力。
2.3 统计学习阶段:数据驱动的方法(20世纪90年代-2010年)
20世纪90年代是NLP的转折点。计算机硬件性能的提升、互联网的普及以及大规模文本数据的可用性(数据驱动),使得统计学方法成为主流。
2.3.1 特点
- 数据驱动:这一阶段的NLP方法从手工编写规则转向依赖大规模语料库,通过统计和机器学习方法挖掘语言模式和结构。统计学习方法通过计算词的共现概率、句子的概率分布等,从数据中自动学习语言规律。
- 特征工程:研究者需要为每个具体任务设计和提取特征,如n-gram、词袋模型(Bag of Words)、TF-IDF等。模型性能高度依赖于特征的质量和丰富度。
- 机器学习模型:常用模型包括朴素贝叶斯(Naive Bayes)、最大熵模型(Maximum Entropy Model)、隐马尔可夫模型(Hidden Markov Model, HMM)、条件随机场(Conditional Random Field, CRF)和支持向量机(SVM)。
2.3.2 典型工作
- n-gram语言模型(20世纪70年代):n-gram模型通过计算n个连续词出现的概率来估计句子的生成概率。这种方法简单且计算效率高,是早期语言建模的基础,但无法捕捉长距离依赖关系。
- 隐马尔可夫模型(HMM)(1960年代后期~1970年代前期):HMM是一种生成式模型,广泛应用于序列标注任务,如词性标注(POS Tagging)、命名实体识别(NER)和文本分块(Chunking)。HMM假设观察序列由一系列隐含的状态生成,通过最大化序列概率进行预测。
- 条件随机场(2001年):CRF是一种判别式模型,用于序列标注任务。相比HMM,CRF不假设观察序列的独立性,因此可以捕捉到更多上下文信息。
- 词向量模型(20世纪90年代末):Latent Semantic Analysis (LSA) 和 Latent Dirichlet Allocation (LDA) 等模型通过矩阵分解和概率模型将文本表示为稠密向量。这为后来的词嵌入方法(如Word2Vec)奠定了基础。
- 词袋模型(BOW)(1990年代):词袋模型(BOW)是一种文本表示方法,它将文本表示为一个词汇表中每个词的出现频率向量。BOW忽略了文本中的词序和语法结构,仅关注文档中各个单词的出现频率或存在与否。虽然BOW模型简单且计算效率高,但它无法捕捉词与词之间的上下文关系和语法信息,导致它在处理复杂语义时存在一定局限。
2.3.3 局限性
- 特征工程繁琐:设计特征需要人工经验,特征选择对任务的效果影响巨大,难以自动化。
- 长距离依赖问题:统计模型(如n-gram、HMM)只能捕捉局部上下文信息,无法处理句子中较远的依赖关系。
- 模型性能限制:基于传统机器学习的模型在处理复杂语言现象时表现有限,难以应对语言的多样性和复杂性。
2.3.4 BOW:统计学习阶段最具备代表性的工作
由于这个阶段最有代表性的方法是词袋模型(Bag of Words, or BOW),因此我们简单介绍一下。所谓BOW,即统计文章中每个词出现的频率,然后对这个频率的向量进行各种各样的统计分析。比如可以根据正向词汇和负向词汇在文中出现的频率对比,来判断文章的情感倾向。或者用词频向量去训练一个分类器,做文本分类任务。
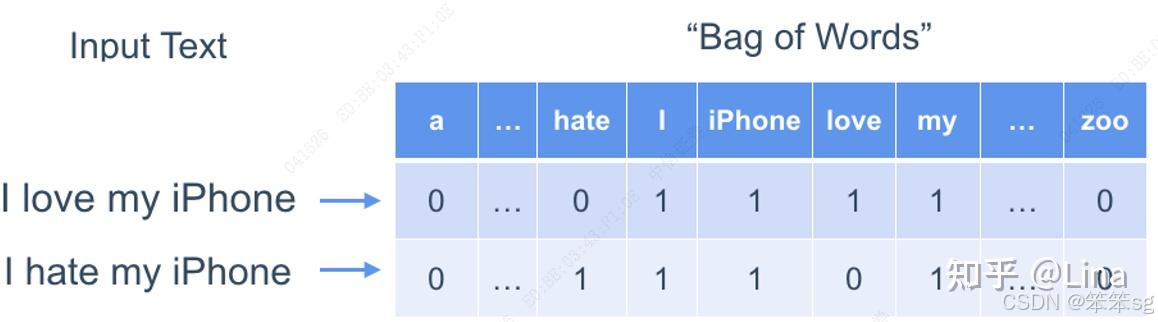
词袋模型是一个简单有效的办法。即使在普遍使用深度学习的今天,这个方法仍有时候被作为快速验证或比较基准来使用。
词频向量实际上是将人类语言翻译成了一种机器能看懂的方式,尽管这个翻译的过程损失了很多信息,有两项信息损失最为突出:
第一个是词袋模型中,每个词都是独立的,没有相对的语义关系,无法使用词与词之间的关联来更好地帮助分析。比如我们学英语,很快就知道abandon,但可能不认识renounce,如果能知道这两个是同义词,那么有renounce的文章也能理解了。词袋模型就无法体现这个信息。
第二个是词袋模型完全忽视了语序信息。例如,“我,很不好”和“不,我很好”两句的词频向量完全相同,但语义却相反。
不过在深度学习出现之后,这两个问题都得到了解决。
2.4 深度学习的兴起(2010年-2017年)
随着神经网络,尤其是深度学习技术的成熟,NLP在2010年代迎来了革命性的突破。这些方法大大提升了自然语言处理任务的性能。
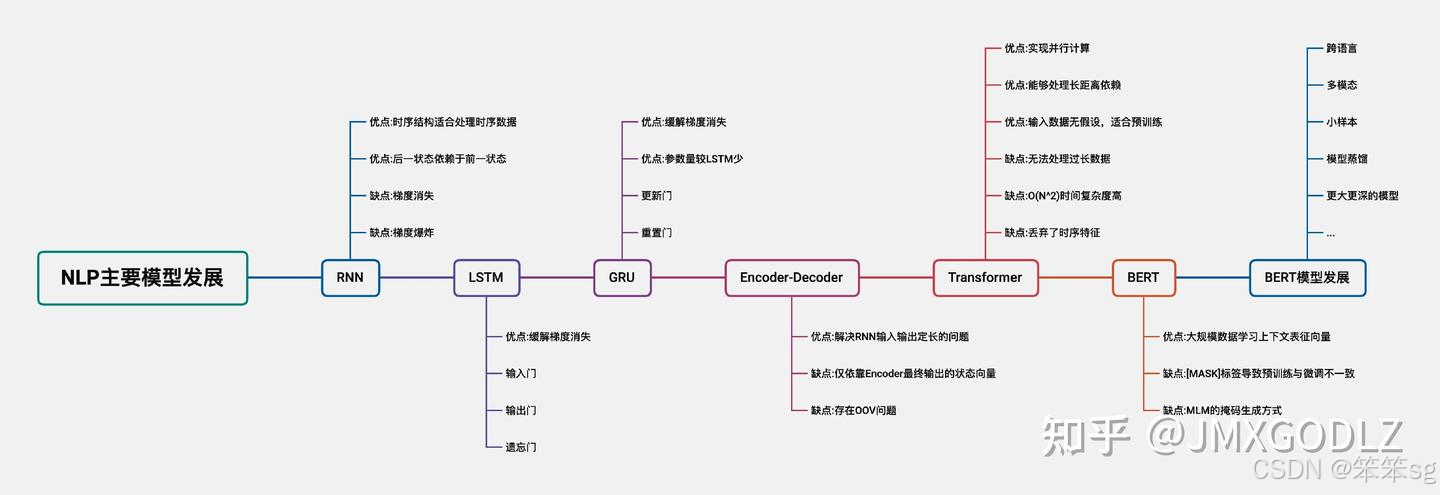
2.4.1 特点
- 端到端学习:深度学习方法可以从原始数据中自动学习特征,减少了繁琐的特征工程步骤,能够直接从文本中提取复杂的高层特征。
- 序列模型的突破:循环神经网络(RNN)、长短时记忆网络(LSTM)和门控循环单元(GRU)等模型在处理序列数据上展现出强大能力,尤其适用于语言建模、机器翻译等任务。
- 神经词嵌入:深度学习推动了神经网络词嵌入模型的快速发展,如Word2Vec、GloVe。词嵌入模型将词映射到低维稠密向量空间中,捕捉词语的语义相似性。
2.4.2 典型工作
- 循环神经网络(RNN)(1997):RNN非常适合处理序列数据,因此广泛应用于语言模型、机器翻译、文本生成等任务。
- LSTM/GRU(1997-2014):LSTM(Hochreiter和Schmidhuber提出)通过引入“记忆单元”和“门控机制”解决了RNN中的梯度消失问题,GRU是其简化版本。这些模型在语言建模、情感分析、机器翻译等任务中取得了显著成果。
- Word2Vec(2013):Mikolov提出的Word2Vec使用Skip-gram和CBOW模型,将词表示为稠密向量。词向量之间的关系能捕捉语义信息,如“king - man + woman ≈ queen”,之后又有GloVe和FastText等改进模型。
- Seq2Seq与Attention机制(2014 - 2015):Seq2Seq模型使用Encoder-Decoder结构,成功应用于机器翻译任务。Attention机制的引入(Bahdanau等人提出)解决了长句子翻译中信息丢失的问题,通过为输入序列中的不同位置分配权重,增强了模型对重要信息的关注能力。
- Transformer模型(2017):Vaswani等人提出了Transformer模型,完全基于自注意力机制(Self-Attention),无需序列化处理,大幅提高了训练效率。Transformer摆脱了RNN的序列计算限制,是现代NLP模型的基础。
2.4.3 局限性
- 数据需求高:深度学习模型需要大量标注数据进行训练,且训练过程计算成本高。
- 模型泛化能力依赖于数据:当训练数据不足或质量不高时,模型容易过拟合。
2.4.4 WordEmbedding: 深度学习解决语义问题
2013年,谷歌的研究员Mikolov使用神经网络训练了词向量(word embedding,有些文献又称“词嵌入”,但还是“词向量”更直观一些)。研究者使用一个简单的一层全连接的神经网络,通过“给出一句话的上文,让模型去预测下一个词”的方式去训练。在看过了大量文章之后,这个神经网络便可将语言中隐含的语义信息”记“在自己的参数中。比如“我想喝一杯”,后文是“水”或是”茶“的概率差不多,那么模型对这两个词的参数也会差不多,即输出的的词向量也是相似的。这样,模型便学会了同义词。
词向量的一个重要性质就是,这个向量在高维空间中的位置关系即可代表语义的关系。比如相似的词可能会聚拢在一起,甚至“法国“与”巴黎”的距离和”英国”与”伦敦”之间的距离都是相似的。
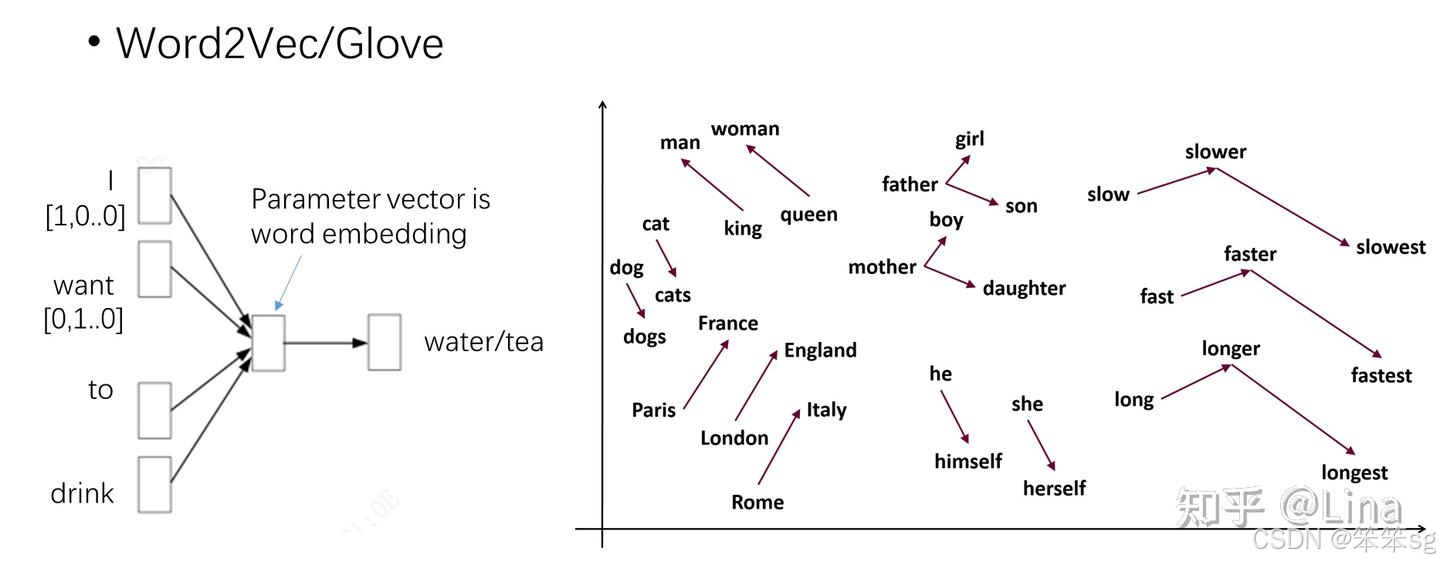
这种给模型喂上文,让模型去预测下文的训练方式,被称为Language Modeling,也就是语言模型或语言建模。这种训练方式不需要人工标注,模型结果可以直接和原文对比,从而能够利用到海量的数据。这种语言建模的方法后面还会一次又一次地被用到,目前实现技术突破的大语言模型也是应用此方法。
2.4.5 RNN: 循环神经网络解决语序问题
语义的问题解决之后,RNN的出现又解决了语序问题。
全连接神经网络是最简单的神经网络模型,在此之上又发展出两类主要的变体,一个是卷积神经网络(Convolutional Neural Network, or CNN) 和循环神经网络(Recurrent Neural Network, or RNN) 。CNN的输入采用滑动一个固定窗口的方式,每次只考虑附近的信息,适合处理图像问题,能做到又快又好。而RNN的输入是按顺序一个一个接收的,在处理完上一个信息之后才会处理下一个信息,天然是阅读文章的一把好手。
总体而言,使用词向量(语义)+RNN(语序)的方法成为这一时期的王者,在各项NLP通用任务上表现颇为亮眼。而研究者们在这一时期的主要工作是在词向量+RNN的基本思想上,对网络架构进行各种各样的改动,用叠加各种buff方式来提升模型的表现。比如LSTM从前往后读不够用,再叠加一层从后往前读的;两层RNN不够用,再加到四层;光RNN不够用,中间某几层给它变成CNN等等……这一时期的SOTA模型描述经常是非常长的一串,是一段很有意思的百花齐放,百家争鸣的时期。
此时,词向量+RNN这样的NLP已经相对比较接近人脑处理语言的方式了。然而还是有一个显著的缺陷,那就是无法像人一样根据上下文处理多义词的含义。由于词向量的训练方式,每个词只能有一个固定的词向量。如果一个词有两个同样常用的,但毫不相关的含义,那么这个词向量在高维空间内只能处于这两个位置的中间点,实际效果就是两边都没法准确建模。
2.4.6 ELMo语言模型解决上下文问题
这时ELMo出现了。
ELMo的作者大开脑洞,谁说没法处理上下文含义啊,语言模型不就是一个天然的、考虑了上下文的模型吗?当RNN一个一个吸收完前文,再吐出来的最后一个词,这个输出显然已经是包含了上文信息的。于是ELMo的作者训练了一个双向的LSTM模型(LSTM是RNN的一种)。这个模型通过把文章从前往后读一遍,再从后往前读一遍,来接收上文和下文的信息。然后作者将这个过程中的三层输出进行组合,就变成了ELMo词向量(Embeddings from Language Models)。从此,我们把文本放进ELMo模型里,拿到的输出就可以作为词向量使用。而每次的输入句子不同时,即使同一个词的词向量也会有所不同,因为ELMo的输出是考虑到了整个句子的信息的。
另外,这个ELMo是芝麻街里的人物,从此ELMo开始,NLP界就开始了芝麻街人偶给模型命名的风潮。后期的BERT,ERNIE,BIG BIRD等模型也都是芝麻街上的小伙伴儿。
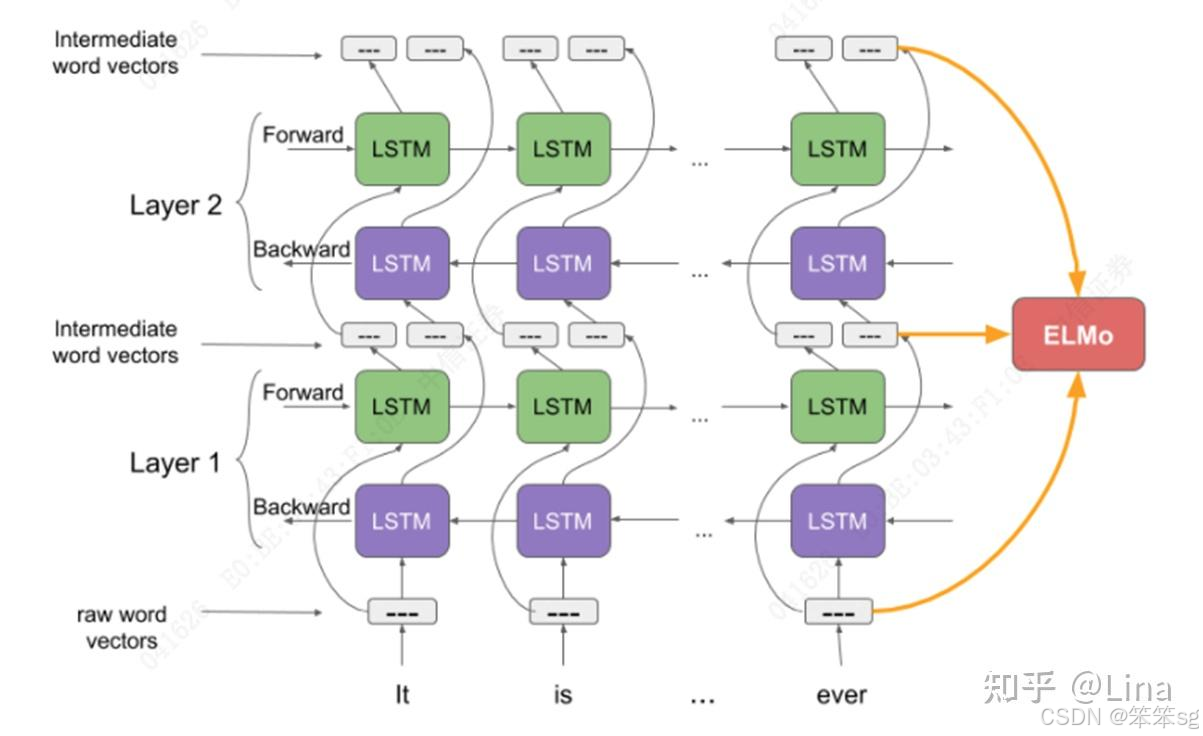
语义解决了,语序解决了,甚至上下文含义也解决了。从思想上看,这时NLP模型越来越接近人类处理语言的方式。但是需要处理的信息越来越多,RNN的弱点突然变得难以忍受:它实在是太慢了。不像全连接网络或是CNN一样可以一股脑儿把所有输入全放进去并行计算,RNN需要一个词一个词地处理,在处理大数据时,这个时间差异就十分巨大。另外,RNN的长期记忆还不太好。因为RNN把信息存储在一个固定纬度的向量里,就好比一个打包盒,每多加一个词,就往这个打包盒里压缩一次。到输出层,需要把这个打包盒打开、找到相关的信息的时候,恐怕最开始输入的信息都已经被压缩得面目全非了,很难解码。
2.4.7 Transformer大幅提升效果
2017年,本世纪NLP界最大的外挂诞生了。这就是Transformer。
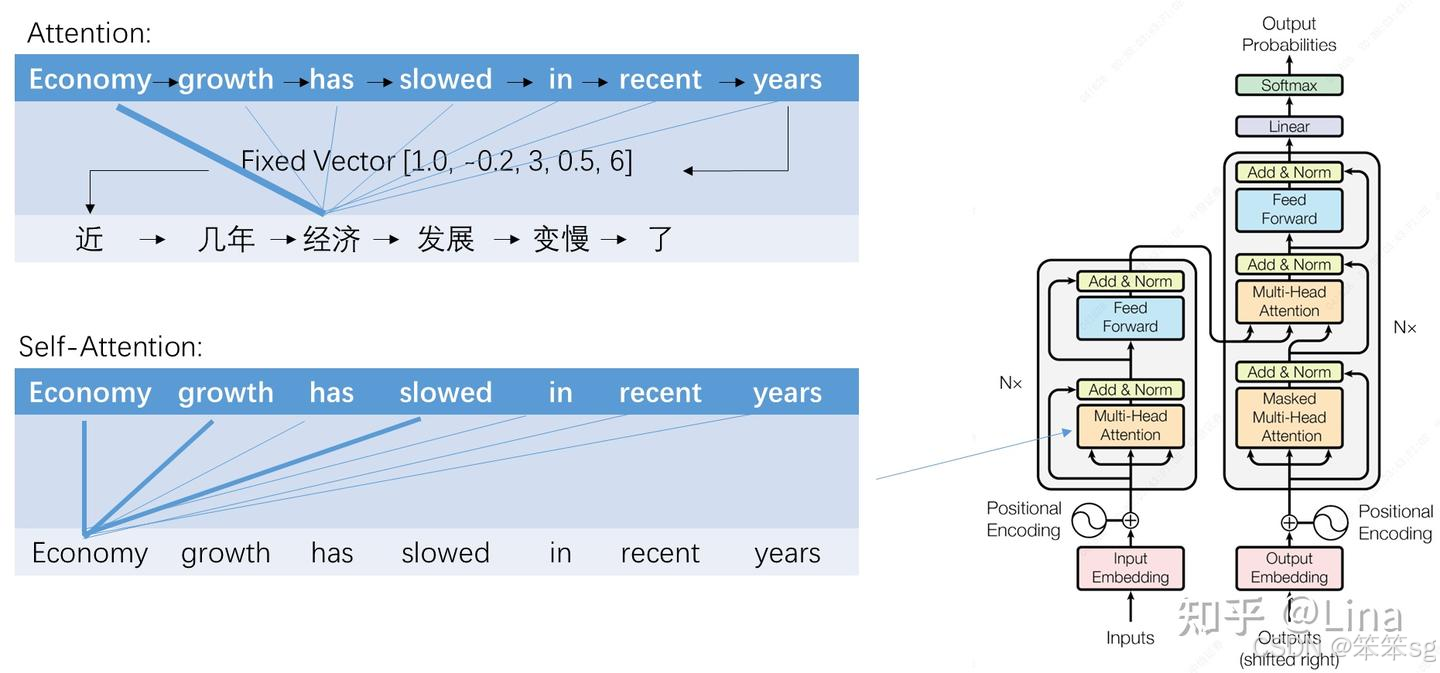
讲到Transformer,必须要先说一下注意力机制(attention)。在机器翻译中,人们发现如果能让输入和输出直接建立一个连接,让模型去学习特定的目标词应该更关注哪些输入词,而不是只从RNN压缩的打包盒里解码,会非常好地提升翻译的表现。在此之前,attention被作为一种增强手段,用在循环或卷积神经网络上。其中一个重要的点是,attention能非常有效地解决RNN长期记忆不好的缺点,输入序列的任何两个词之间都有联系关系,真正实现了“天涯若比邻”。
而Transformer的创新之处在于,将attention的输入与输出之间的连接,变为输入与输入自己的连接,这相当于在做任务时,把每个词都在上下文的语境中理解一次。作者称为自注意力机制(self-attention)。使用时将语义信息(词向量)和语序信息(序号)作为输入。由于自注意力模型之下词与词之间的联系变得很直接,这种模型能更好地编码输入的上下文信息,训练的反馈也能得到很好的传导。打个比方,RNN是将文章通读一遍,然后用一个词总结文章大意,Transformer就是反复读文章许多遍,好好理解了文章之后,然后用一个和原文一样长的句子总结文章,效果当然大大提升了。
Transformer的另一个厉害之处在于它可以毫无压力地进行并行计算。虽然它的计算量相比RNN大大增加了,但由于可以并行计算,在拥有足够算力的情况下,需要的时间反而变少了。
Transformer出现之后,由于效果太好,大家几乎完全抛弃了其他的架构。如果说RNN时代是百花齐放的春秋战国,Transformer就是秦王扫六合,一举统一了整个NLP模型江湖。Transformer的性能使整个NLP界从蒸汽时代迈入了内燃机时代,也使得后续效果超群的大模型的出现成为可能。
2.5 预训练语言模型和Transformer时代(2017年-至今)
有了Transformer以后,大家逐渐抛弃了原来五花八门的RNN架构,转而使用Transformer。而Transformer架构简单直接,并且也提供了足够多的参数,再胡乱魔改反而会影响表现。实际上直到今天,除了为了处理超长文本(文本越长,需要的算力呈几何级数增长)而发明了一些Transformer的更加高效的变体之外,大部分的模型还是使用原始的Transformer作为基本算子。
2.5.1 特点
- 大规模预训练和微调:这一阶段的核心思想是通过在大规模无标注语料上进行预训练,然后在特定任务上进行微调(Fine-tuning),从而实现模型在多个任务上的迁移学习。预训练模型可以捕捉丰富的语言信息,并应用于各种NLP任务。
- Transformer架构的主导地位:Transformer架构以其强大的并行计算能力和高效的自注意力机制,成为大规模语言模型的核心架构。
- 模型规模不断增长:随着计算资源和数据的增加,语言模型从最初的BERT、GPT逐渐发展到更大、更强的模型,如GPT-3、BERT-large、T5、ChatGPT等。
2.5.2 典型工作
- BERT(2018):BERT(Bidirectional Encoder Representations from Transformers)是Google提出的双向编码器模型。BERT使用Masked Language Model(MLM)和Next Sentence Prediction(NSP)进行预训练,解决了传统单向模型对上下文信息捕捉不完整的问题。在各种NLP任务上取得了SOTA(State-of-the-Art)性能。
- GPT系列(2018 - 至今):OpenAI提出的GPT系列模型采用自回归语言建模方法。GPT-3展示了强大的文本生成能力,通过少量示例(Few-shot Learning)即可完成特定任务。GPT-4进一步扩展到多模态输入,增强了模型的推理能力。
- T5(2019):Google提出的T5(Text-to-Text Transfer Transformer)模型将所有NLP任务统一为文本到文本的形式,如“翻译英语到法语:This is a test → C'est un test”。这种统一的任务表示方式简化了模型结构,并提高了任务间的迁移能力。
- ChatGPT与大语言模型(LLMs):OpenAI的ChatGPT展示了大规模预训练语言模型在对话和生成任务中的潜力,标志着AI助手和生成式模型应用的普及。
2.5.3 影响
- 性能飞跃:预训练模型在几乎所有标准NLP任务上取得了显著提升,推动了自然语言理解和生成领域的发展。
- 广泛应用:预训练语言模型被广泛应用于文本分类、情感分析、机器翻译、文本摘要、问答系统等任务,并逐渐扩展到跨模态任务,如视觉-语言融合。
- 模型优化与精简:随着模型规模和计算需求的增加,研究者提出了模型压缩(如DistilBERT、TinyBERT)和高效训练(如混合精度训练、量化训练)等技术,以提升模型的应用效率。
2.5.4 局限性
- 计算成本和资源需求高:训练大规模预训练模型需要巨大的计算资源,模型的参数规模和复杂性导致推理成本也较高。
- 数据偏见与解释性问题:模型从大规模文本中学习,可能继承其中的偏见和错误,导致生成有偏见或不准确的结果。此外,大型模型的内部机制难以解释,存在黑箱效应。
2.5.5 预训练-微调时代
2018年,BERT和初代GPT几乎在同一时间出现。BERT由谷歌开发,GPT由OpenAI开发,但是这两个模型有相当多的共同点:
- 首先,它们都采用了Transformer,甚至层数也相同。
- 其次,它们都使用了当时几乎所有开源的、较高质量的NLP数据,如wikipedia, 书籍等。
- 最后,它们的训练方法都是语言建模Language Modeling,即给模型输入上文,令其预测下文的方法。从而可以使用大量文本而无需人工标注。
BERT和GPT的参数量大约在亿级,在当时已经是从未出现过的“大模型”了。加上使用了当时可获得的几乎所有高质量文本数据训练,研究者发现,这两个模型在大量数据中学到了对语言的基本理解和一些通用的世界知识,并且将这些知识被储存在模型的参数中。有了这样的“义务教育”打底,在此基础上,只需针对各个专业下游任务(如情感分析、对话生成)进行一个小范围的基于监督学习的微调,比如只调整模型最后一层的参数,居然可以打败很多专门针对这些任务开发的模型。这就是‘’预训练-微调‘’模式。尽管当时人们还没有意识到,这实际上是用语言模型做通用人工智能的早期雏形。
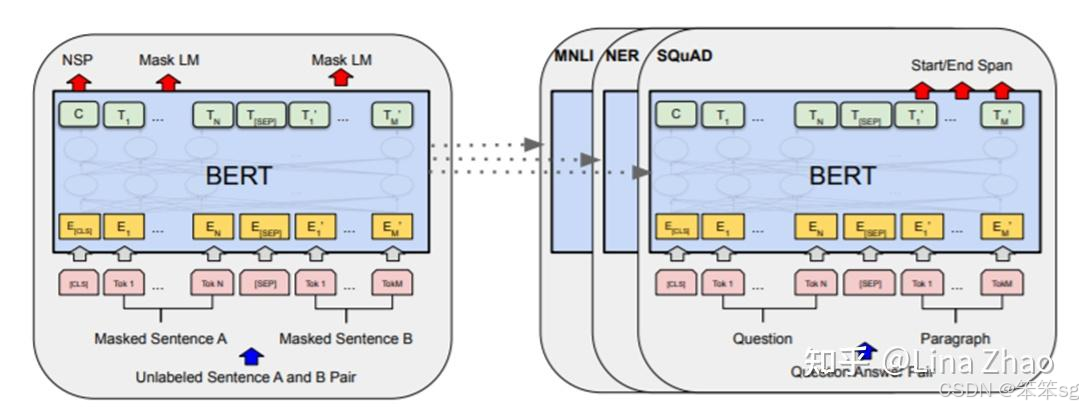
BERT和GPT的原理其实只有一点点区别,即:
- GPT是一个单向模型。OpenAI采用标准的Language Modeling方式进行训练,模型根据上文来推测下文。
- BERT是一个双向模型。Google在训练BERT的时候,挖掉输入文本中15%的词,让模型去完成类似完形填空的任务。
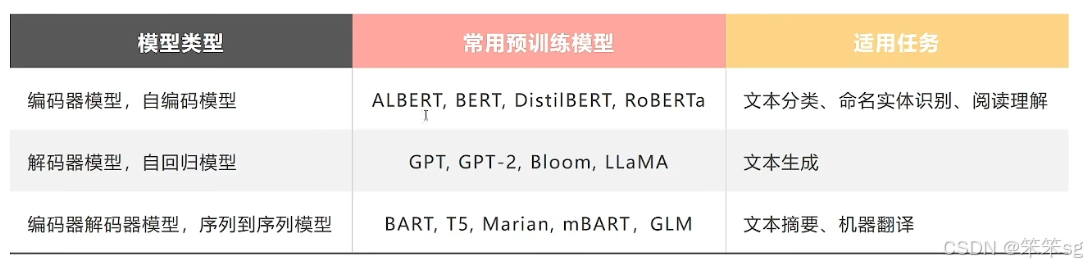
在实际测试中,BERT模型由于同时可以看到目标词上下文的信息,一般在理解类任务上表现较好。而GPT模型只能看到上文,在此类任务上表现略逊一筹。但是这类单向模型天然更适合生成类任务,表现也稍好。总体而言,BERT和GPT模型架构上的这一点点差异,在模型表现上差异并不大,然而却在之后的道路上却产生了巨大的影响。
这一时期的流行做法是,无论什么任务,先来一个BERT打底,再换掉最后一层,用自己的数据进行微调,让模型产出成为自己需要的格式。尤其是在自己的数据不多的情况下,这样做普遍比自己从头训练Transformer效果要好。
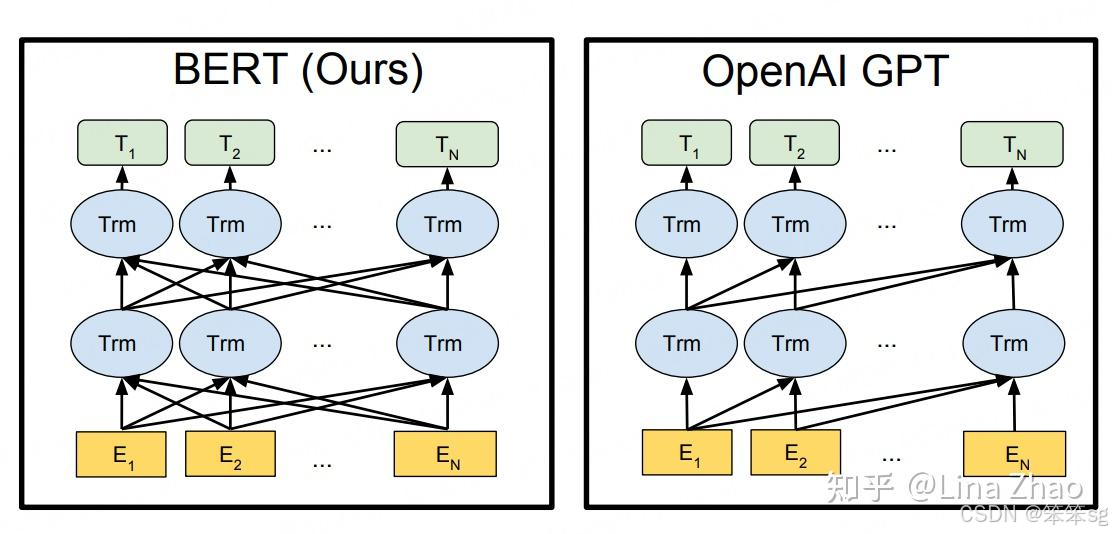
2.5.6 大语言模型时代:Prompt代替微调
接下来的时间里,其他有能力的机构不甘BERT独占鳌头,也纷纷推出自己的预训练模型。隔几个星期就会有一个模型被发布出来,刷新通用NLP任务业绩榜单。但是这些模型大多数在思想上没有太多创新,一般是添加不同的训练技巧和尝试,比如RoBERTa,只是将BERT训练了更长时间,使用更多数据和去掉了一个训练目标。或者是“大力出奇迹”——使用更多的数据和更大规模的模型,比如GPT、GPT2、GPT3,他们的架构几乎没有差别。
早在这时已有学者担心,NLP研究正在向更加集中化的方向发展。然而因为大模型+大数据的效果实在太好,我们仍是无可避免地向着这条集中化的道路狂奔而去。
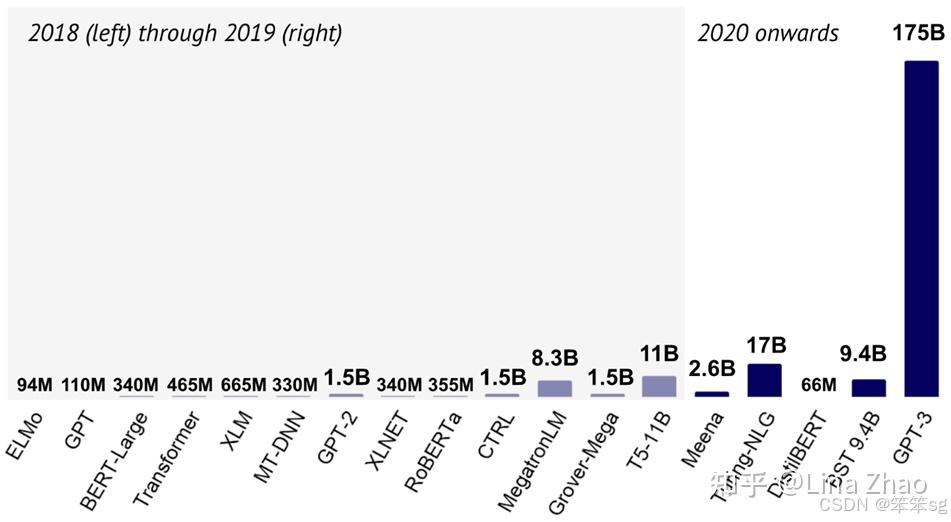
2019年,OpenAI发布了GPT-2,他们并没有像以往一样把模型开源供大家下载。这其中当然有商业上的考虑,但一个现实原因是模型参数已经相当大,难以部署到普通人的机器上。于是OpenAI提出了非常巧妙的办法来忽悠模型完成任务——小样本提示词(Few Shot Prompt),也就是先给模型一些问答的例子,最后留出一个问题。因为作为预测下文的语言模型,GPT-2的目标是续写我们提供的输入,而在这个过程中,就正好回答了我们最后留出的问题。使用这样的方法,GPT-2就可以在未经微调的情况下来完成各种它并没有被专门训练过的任务。

当然GPT-2当时与很多“预训练-微调”模型的效果还不能比,但是用Prompt的方式,对模型大小就不必限制,开发者可以一直增加数据量和模型规模,直到模型的效果变得足够好。这实际上就去掉了“微调”的必要。
另外,Prompt模式本质是文本生成,刚好是GPT这样单向模型更为擅长的。因此在目前大语言模型的训练中,研究者们变成了更多采用GPT而不是BERT。
由于BERT的表现一开始较好,其他机构的预训练模型也大多采用双向模型。只有OpenAI还默默坚持使用单向模型。当时很多人不理解为什么,但是从现在往回看,大家就明白了——因为OpenAI想要做通用人工智能。他们的目标是要做一个足够大的语言模型,吸收了人类社会所有的知识,再根据这些知识和与人类的交互来完成各种任务。这样大的模型必然不可能再使用部署在个人机器上微调的模式。
2.5.7 大模型的涌现能力:大力出奇迹
OpenAI继续沿着大力出奇迹的道路前行,发布了GPT-3。
GPT-3与GPT-2在模型架构上没有区别,只是采用了更大的模型和更多的数据,将参数提升到千亿级别,是BERT的五百倍。在标准NLP任务的测试中,又展现出了不小的提升,而且人们发现了这个模型出现了一些之前模型没有的,处理复杂任务能力。
为什么模型越大往往表现越好呢?一些研究者发现,模型解决某些相对简单直接的任务能力是随着模型的增大逐渐线性增长的,而解决另外一些较复杂任务的能力,则是在模型达到某个量级之后突然出现的,我们称之为涌现能力(Emergent Ability)。打个比方说,线性增长的能力就好比算数的能力,一年级的小朋友比幼儿园的强一点,二年级的又比一年级的强一点。涌现的能力就好比算微积分,一二三年级的小朋友都一样搞不懂,只有长大成高中生了,才有解微积分的能力。
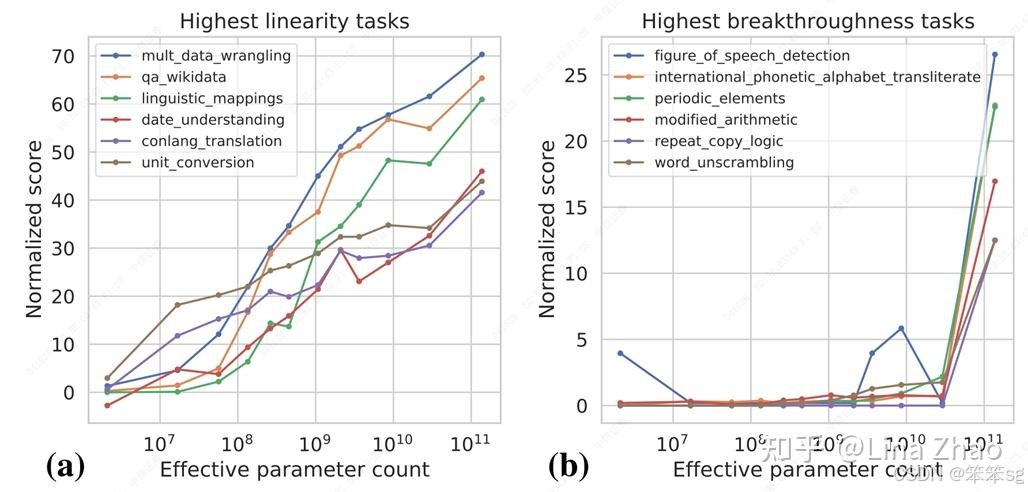
这类涌现能力有一些共同的特点:比如任务是需要多步骤解决,逻辑推理能力比较重要等等。
一个突出的涌现能力叫做思维链能力(Chain-of-Thought,简写为CoT)。这个现象是:如果在prompt当中加入一个一步步推理的例子,然后再问问题,能够提高模型的准确率,把以前做不对的题做对。比如下图中的示例。左边的prompt直接给出问题,模型回答不对,右边的prompt则加入了一个相似的示例 (第一段Q和A),并在A这一段里详细得将解题步骤写出来,最后再问和左边相同的问题,模型就回答对了这道题。
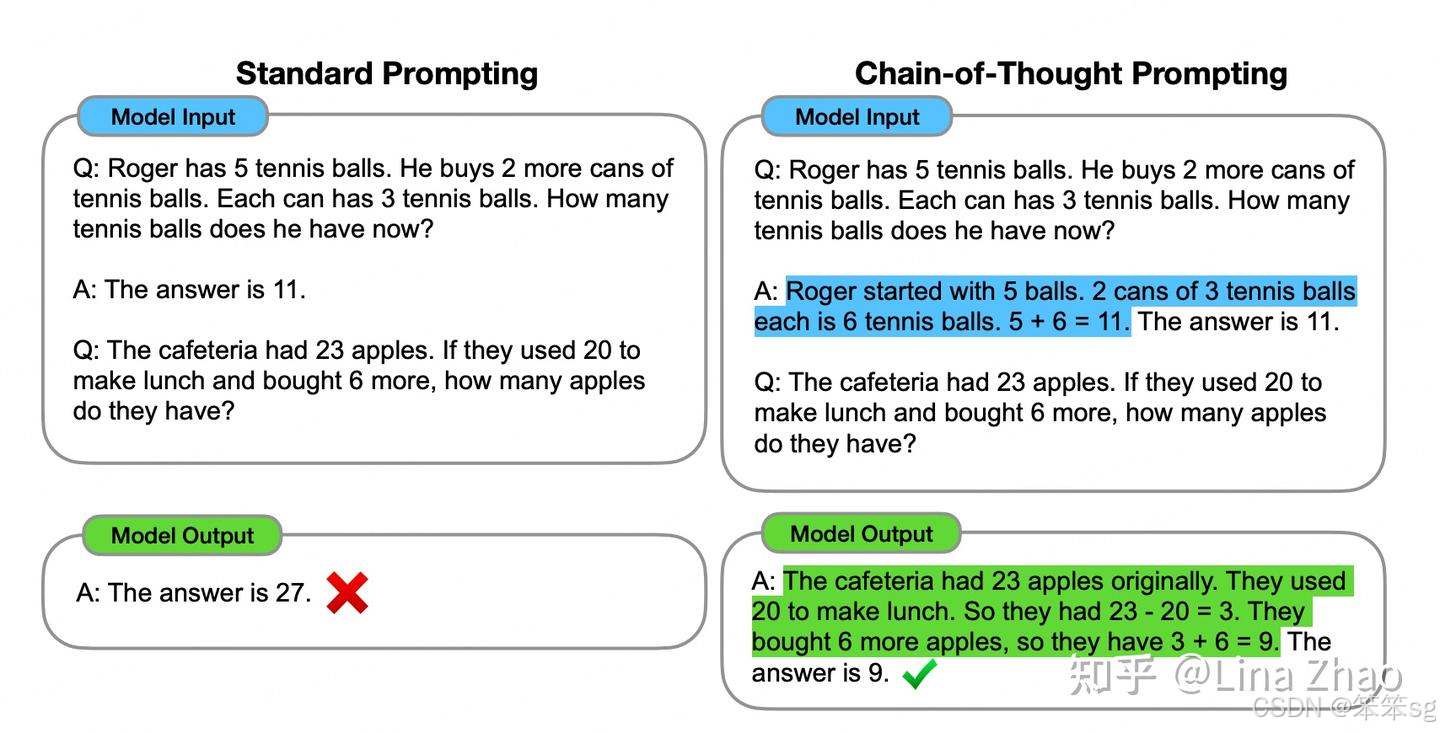
至于为什么模型会涌现这个思维链能力(或是其它的高级能力),学界还没有定论。深度学习的发展可以说是数据和实验驱动的,目前还有非常多的现象我们没法解释,其实prompt为什么能用我们都没有定论。一个可能的猜想是思维链prompt中给出了与目标答案更加相关的文本(也就是人工写的相似的例子),这些文本会激发模型中的相似记忆,帮助它找到更相关的答案。
2.5.8 引爆全球:逻辑思维和对话能力的增强
OpenAI在GPT-3之后,ChatGPT之前,还训练了两个中间模型,他们都对ChatGPT的出现功不可没。
一个是Codex,这是一个在GPT-3的基础上,增加GitHub上所有的代码作为训练数据的模型。代码数量是原来的文本数据数量的2/3左右。在使用代码训练过后,Codex的逻辑推理能力(比如思维链能力),比起GPT-3来增强了许多。实际上,还有其它的实验表明,只要增加代码数据,就可以使大模型的推理能力变强。虽然我们仍然没有确定的解释,但是比起一般文本,代码本身就是相当有逻辑的数据,所以有这样的结果从直觉上倒也能理解。
另一个是InstructGPT,是在GPT-3的基础之上,增强模型听懂指令的能力。GPT-3作为基础模型,知识和能力其实已经具备,但是由于GPT-3是一个以“续写下文”为目标的语言模型,而不是以“回答问题”为目标的问答模型,它的交互性并不太好。有时候想得到合适的回答并不容易,必须找到特定的、甚至是机械的Prompt才能得到有用的答案。可以说,很多时候GPT-3是茶壶里煮饺子,有货倒不出来,人必须学会用GPT-3的语言才能进行交互。而InsturctGPT是对GPT-3进行了指令微调,目的是让机器听懂人类语言。这里OpenAI使用了一种基于强化学习的方法RLHF(Reinforcement Learning from Human Feedback with dialogue)。指令微调还可以使用别的方法,我会在以后的文章中详细介绍。
RLHF的具体方法是首先让人类标注员来写一些prompt和对应的答案,然后用这个数据集去微调GPT-3,然后再让人工为这个新GPT-3的输出排序,用这个排序信息训练一个reward模型来辨别什么样的回答是人类喜欢的,最后再用这个reward模型和强化学习的方法去继续训练GPT-3。OpenAI自己的论文中写到,相比GPT-3, 标注员确实更喜欢InstructGPT的回答。
而到了这一步,当前引爆全球的ChatGPT已经呼之欲出。ChatGPT在GPT-3的架构和训练数据基础上,增加代码数据,再加上RLHF指令微调训练而成,内部代号GPT-3.5。其能力分解开来大致就是GPT-3提供语言理解能力和世界知识,Codex增强逻辑推理能力,InstructGPT提供对话能力。ChatGPT发布后,OpenAI又对后端基础模型进行了升级,从最开始的GPT-3.5升级到了GPT-4,性能上又有大幅提升,而且可以接受图像作为输入。值得一提的是,在美国职业法律考试中,和人类考生相比,GPT-3.5排名是倒数10%,但GPT-4超过了90%人类考生的成绩,从学渣变成了妥妥的学霸。OpenAI迫于竞争压力,并没有在GPT-4的技术报告中公开数据集和模型的规模,不过整体的方法论应该是差得不远的,仍然是大力出奇迹的延续。
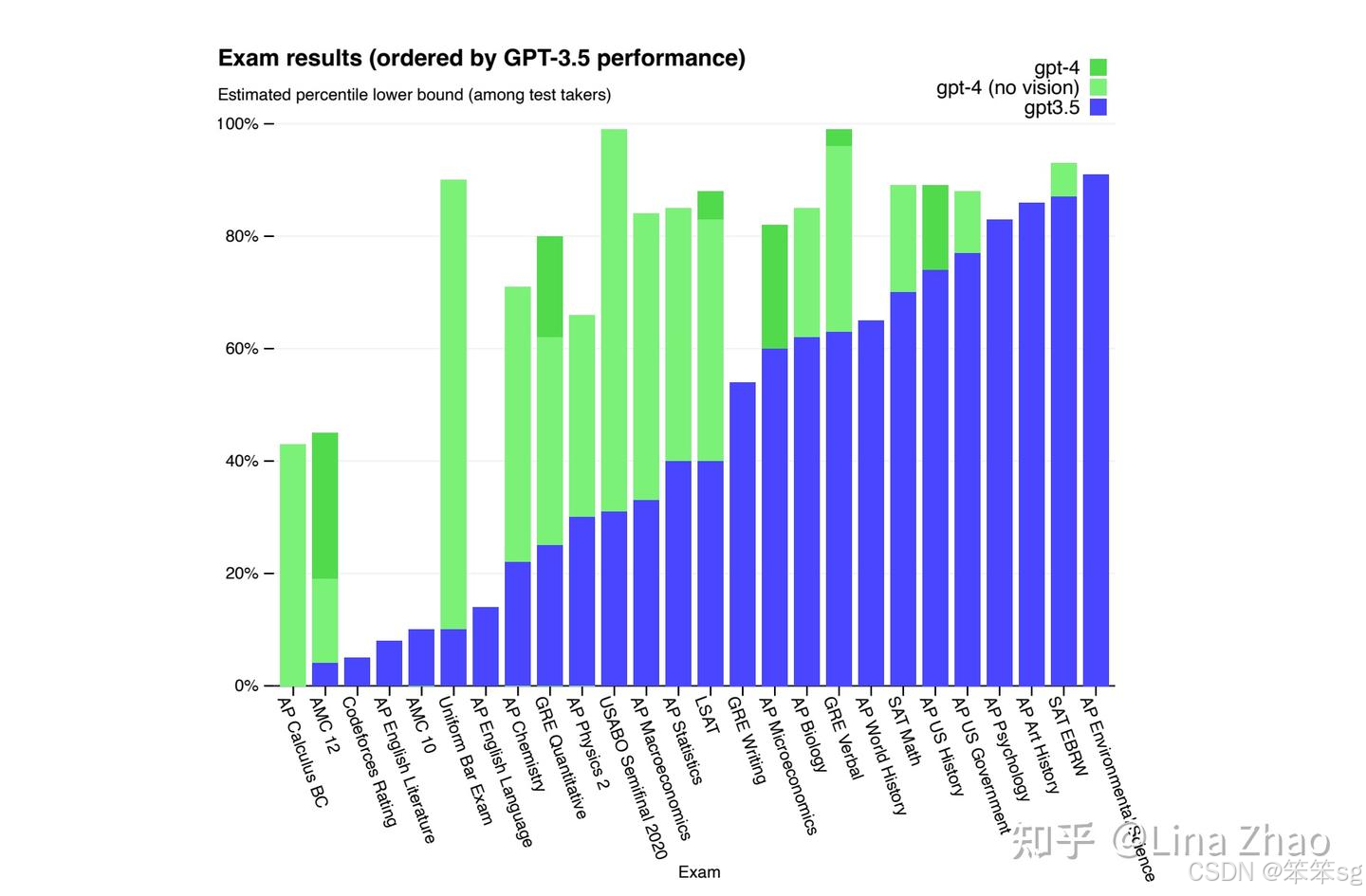
至此,我们已经回顾完了NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的模型架构是两大发展趋势。置身在ChatGPT引发的全球AI热潮中,抬头看看远方,仿佛已经能看到通用人工智能的灯塔。
2.6 NLP的5个发展阶段通俗比喻
可以把NLP的发展历程想象成一个人学会使用语言的过程,从一开始模仿规则到后来理解语义,再到最后能够像专家一样处理复杂问题。以下是每个阶段的比喻和通俗解释:
1. 早期阶段-基于规则的方法(20世纪50-60年代)
比喻:这是婴儿学说话的阶段,依靠大人告诉他们“这个场景应该说什么话”,完全按照大人的规则去模仿。
通俗解释:
- 在这个阶段,NLP系统就像一个初学者,通过人工编写的规则和词典来处理语言。就像婴儿学习“看见猫就说‘猫’”,所有的回答都是预先规定好的。
- 例如,早期的翻译系统就是按照预定的词汇和语法规则来逐句翻译,而无法应对复杂句式和新词。
2. 符号主义阶段(20世纪60-80年代)
比喻:像小学生学语法和知识库,努力记住“主谓宾”、“修饰词”等规则,通过背书和死记硬背来分析句子。
通俗解释:
- 符号主义方法试图用语法规则和知识库来理解语言,就像学生学语法一样,解析每个句子的结构,并试图从知识库中找到对应的语义。
- 比如,系统会解析句子“猫抓老鼠”,并通过知识库知道“猫”和“老鼠”的关系,从而理解这是一个捕猎行为。
3. 统计学习阶段(20世纪90年代-2010年)
比喻:就像学生开始大量阅读文章,通过积累经验,使用统计概率来猜测句子可能的意思。
通俗解释:
- 在这个阶段,NLP不再依赖人工规则,而是从大规模数据中学习。通过统计方法,系统可以发现“猫”和“抓”经常出现在一起,从而推断出“猫喜欢抓东西”。
- 例如,n-gram模型就是通过计算词语之间出现的概率,来预测下一个词是什么。比如"猫抓"后面常常出现"老鼠"。
4. 深度学习的兴起(2010年-2017年)
比喻:这时,学生变成了能自主学习的大学生,可以通过深入分析文本并理解其中的复杂关系。
通俗解释:
- 深度学习通过神经网络,可以像大学生一样从复杂的数据中学习,自动提取高级特征,不再需要人工干预。它们能从大量文本中学到“猫抓老鼠”这一现象背后的隐含含义,而不只是简单地统计词频。
- 例如,LSTM能理解句子中的上下文关系,识别出“虽然猫很饿,但它并没有抓老鼠”中,"虽然"与"但"之间的对比关系。
5. 预训练语言模型和Transformer时代(2017年-至今)
比喻:这是学生成为语言专家的阶段,能够从大量书籍中学习,并且快速适应新领域,就像拥有了一本“百科全书”,甚至具备一些语言创造能力。
通俗解释:
- 预训练模型通过大规模训练,可以理解和生成类似于人类写作的自然语言。它们不再需要手动教,而是通过海量数据自行学习语言的复杂规律。
- 例如,BERT可以在句子中填空,并能理解“猫和老鼠是敌人”这样的抽象概念。GPT-3甚至可以基于上下文生成一篇文章或回答问题,表现得像一个有知识和创意的写作者。
总结
- 早期阶段:学说话,完全依靠手动编写的规则。
- 符号主义阶段:学语法和知识库,试图通过规则和知识理解句子。
- 统计学习阶段:大量阅读,利用统计方法从数据中找规律。
- 深度学习阶段:自主学习,能理解复杂句子并自动提取特征。
- 预训练语言模型阶段:成为语言专家,能理解并生成高质量的自然语言文本。
这五个阶段就像一个人的成长过程,从简单模仿,到逐渐掌握复杂规则,最后成为能够自主理解和创造语言的专家。
3 重点
3.1 序列模型有哪些应用场景?
序列模型在深度学习中非常重要,尤其在语音识别、自然语言处理等领域,取得了巨大的成功。以下是一些应用场景,说明了为什么序列模型如此关键:
-
语音识别:输入是一个按时间顺序播放的音频片段,输出是对应的文字记录,二者都是序列数据,因此需要使用序列模型来捕捉音频和文本之间的关系。
-
音乐生成:在音乐生成中,输出是一个音乐序列,可以根据给定的输入(如想要生成的音乐风格或部分旋律)来创作音乐。
-
情感分类:情感分类问题中的输入是文本序列(例如电影评论),模型需要通过理解整个句子的上下文来判断情感倾向(如评分)。
-
DNA序列分析:DNA序列由四个字母表示,序列模型可以用来分析并标记出DNA中与特定蛋白质匹配的部分。
-
机器翻译:输入是一个语言的句子,输出是对应的翻译。尽管输入和输出的序列可以有不同的长度,序列模型仍然能够处理这些关系。
-
视频行为识别:视频帧是按时间顺序排列的序列,序列模型可以帮助识别视频中的动作和行为。
-
命名实体识别:给定一个句子,序列模型能够识别出其中的实体(如人名、地名等)。
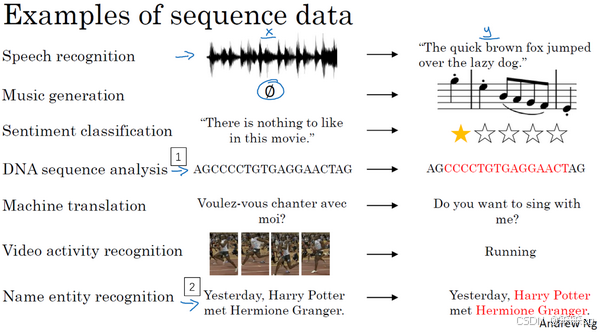
这些问题都涉及到使用序列数据作为输入或输出的监督学习任务。通过这些例子,我们看到序列模型适用于不同类型的序列问题,有时输入和输出序列长度不同,有时相同。接下来,我们将进一步学习如何定义并处理这些序列问题。
3.2 如何使用符号表示训练集中的序列数据?
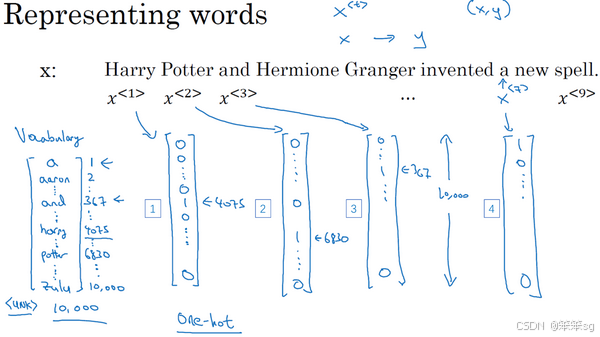
-
序列数据的表示:以命名实体识别为例,输入数据是一个句子,例如“Harry Potter and Hermione Granger invented a new spell.”,目标是识别句子中的人名。这个任务是一个典型的序列标注问题,输出是与输入序列长度相同的标签序列,每个标签表示对应单词是否属于人名的一部分。

-
训练集中的序列表示:为了表示输入序列中的每个单词,我们首先需要构建一个词典。词典中的每个单词都有一个唯一的位置,例如“Harry”可能在词典的第4075位置。每个单词可以通过一个one-hot向量表示,向量中仅有一个位置为1,表示该单词在词典中的位置,其余位置为0。
-
词典大小和表示方法:词典的大小通常根据数据集的规模来选择,常见的词典大小从30,000到50,000词不等。但是100,000词的也不是没有,而且有些大型互联网公司会用百万词,甚至更大的词典。许多商业应用用的词典可能是30,000词,也可能是50,000词。不过我将用10,000词大小的词典做说明,因为这是一个很好用的整数。通过one-hot向量表示单词,使得每个单词对应一个固定长度的向量(例如,词典大小为10,000时,每个词的向量长度为10,000维)。
-
处理未知单词:对于词典中没有的单词,我们使用一个特殊的标记(如<UNK>)来表示,称为“未知词”,这确保了即使遇到不在词典中的单词,也能进行处理。
3.3 循环神经网络(RNN)的基本概念以及它如何在序列学习问题中应用
1)标准神经网络的局限性:
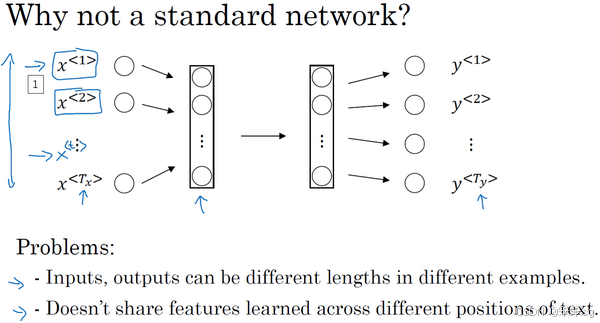
- 输入输出长度不一致:不同的序列可能有不同的长度,即使填充(padding)使输入统一长度,也并非最优。
- 不能共享学习到的特征:标准神经网络不能像卷积神经网络那样自动将学到的特征推广到序列中的其他位置,也即它并不共享从文本的不同位置上学到的特征,具体来说,如果神经网络已经学习到了在位置1出现的Harry可能是人名的一部分,那么如果Harry出现在其他位置,比如位置5时,它也能够自动识别其为人名的一部分的话,这就很棒了。但它无法做到,因为标准神经网络(缺乏时间或位置信息的共享机制、每个位置的特征学习是独立的、缺乏共享权重的机制)。
- (补充)参数量巨大:之前我们提到过对于这些序列数据的编码都是10,000维的one-hot向量,因此这会是十分庞大的输入层。如果总的输入大小是最大单词数乘以10,000,那么第一层的权重矩阵就会有着巨量的参数,这对于模型的的训练是很不利的。
2)循环神经网络(RNN):
- RNN的结构:RNN通过将每个时间步的隐藏状态传递给下一个时间步,使得网络能够记住先前的状态信息。
- 前向传播过程:每个时间步输入一个单词,并计算激活值,同时隐藏状态会传递到下一时间步。例如,在处理句子“Harry Potter and Hermione Granger”的时候,RNN会在每个单词的时间步上根据当前输入和前一个时间步的隐藏状态预测输出。
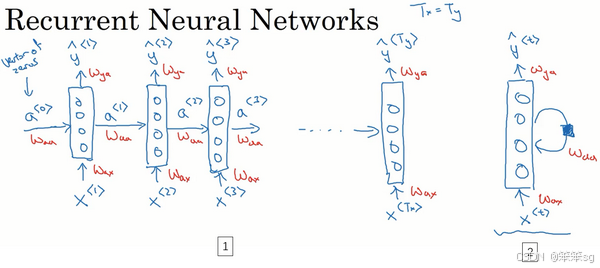
- 共享参数:RNN使用共享的参数来进行每个时间步的计算,从而减少了参数数量。
- 初始化:RNN的初始激活值通常是零向量,除非另行初始化。
3)RNN的限制:
- 信息传播的限制:RNN只能使用序列中之前的信息进行预测,不能利用序列中后面的内容。这意味着,像“是否Teddy是人名”的问题,如果仅依赖前面部分的信息,可能无法做出准确判断。这个问题可以通过**双向循环神经网络(BRNN)**来解决,后者会同时考虑前后文的信息。
- 举个例子:“Teddy Roosevelt was a great President.”,为了判断Teddy是否是人名的一部分,仅仅知道句中前两个词是完全不够的,还需要知道句中后部分的信息,这也是十分有用的,因为句子也可能是这样的,“Teddy bears are on sale!”。因此如果只给定前三个单词,是不可能确切地知道Teddy是否是人名的一部分,第一个例子是人名,第二个例子就不是,所以你不可能只看前三个单词就能分辨出其中的区别。
3.4 RNN的前向传播:
- 每个时间步的计算由输入向量和前一个时间步的隐藏状态决定。通常,RNN使用tanh激活函数,或者在某些情况下使用ReLU。
- 损失函数:对于分类任务(如命名实体识别),输出激活函数可能是sigmoid(二分类任务)或softmax(多分类任务)。
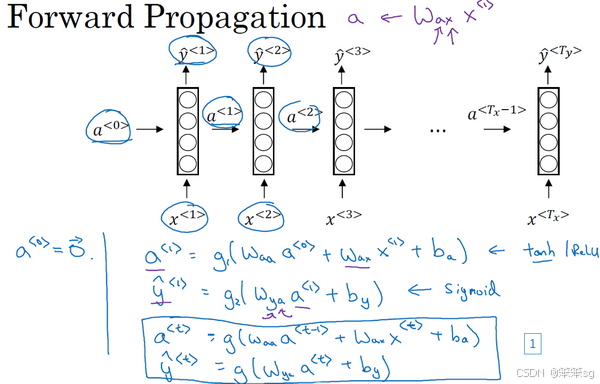
如上图所示,举个简单的例子:
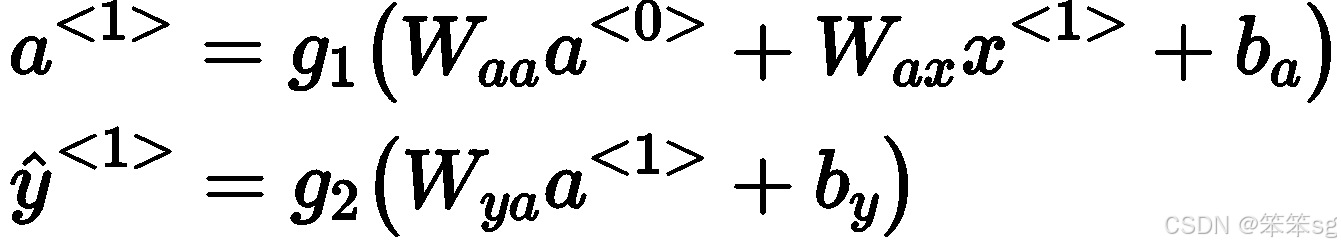
通用例子:
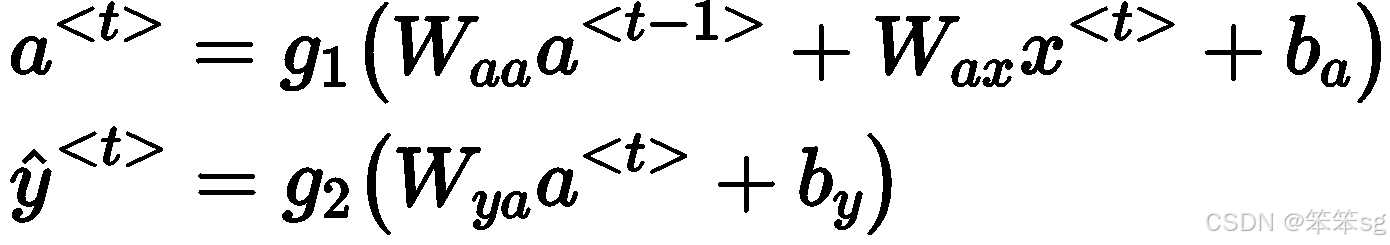
代表不同层的激活值(用于输入、输出);
则代表两个激活函数,分别是隐藏层的和输出层的;
则表示3个权重矩阵,主题RNN里面也是权重共享,从头用到尾;
分别是输入和输出。
为了帮我们建立更复杂的神经网络,我实际要将这个符号简化一下,也即合并一下
采用矩阵堆叠来优化计算,这样做使得在计算过程中能更清晰地表示不同的矩阵和向量操作。
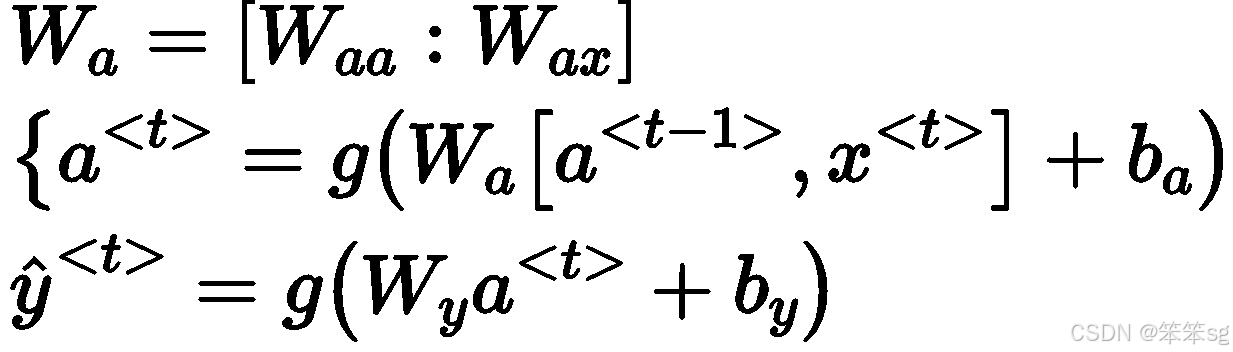
整体的示意图如下所示:
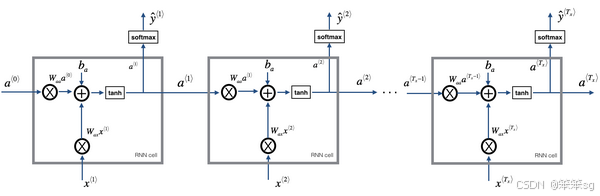
3.5 RNN的反向传播
1)定义损失函数:
- 对于每个时间步的输出,通过预测结果与真实标签(例如是否为人名)之间的差异来计算损失。这个损失函数通常使用交叉熵损失函数(Cross Entropy Loss),并且在RNN中计算总损失时,会将所有时间步的损失加总,得到序列的总体损失。
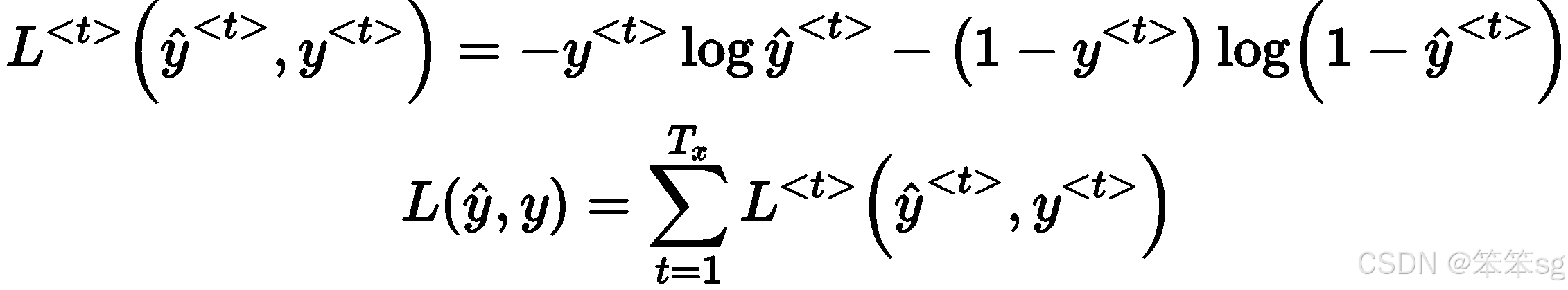
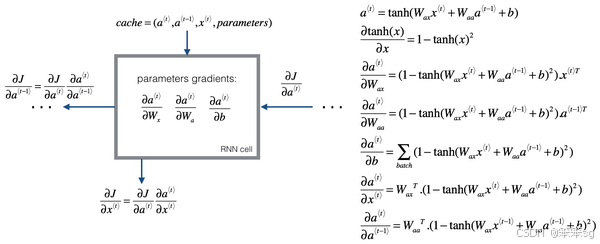
2)反向传播示意图:
整体的反向传播流程和标准神经网络没啥区别
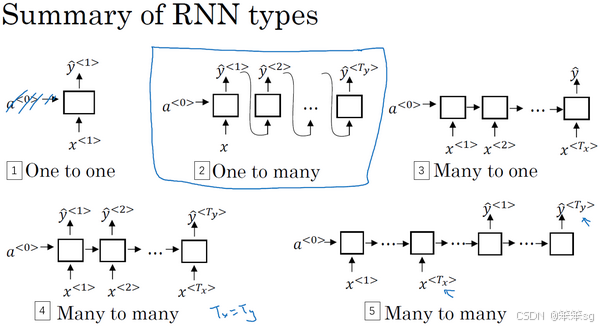
3.6 不同类型的循环神经网络(RNN)
现在你已经了解了一种RNN结构,它的输入长度等于输出长度。事实上,对于其他一些应用,和并不一定相等。
具体来讲,主要有以下四种基础的RNN结构(不包括1对1那种简单的标准神经网络):
1. 多对多(Many-to-Many)结构:
- 输入和输出长度相同,这种结构适用于输入和输出序列长度一致的任务。例如,命名实体识别(NER)任务中,输入为一个序列(例如一段文本),每个单词都需要进行分类,输出序列的长度与输入相同。每个时间步上都有一个输出。
- 例如:在文本中的每个词都对应着一个标签(如实体标识),所以输入和输出的序列长度一致。
2. 多对一(Many-to-One)结构:
- 输入是一个序列,输出是一个单一的值,这种结构适用于序列到单一值的任务。例如,情感分类任务中,输入是一个文本序列(如电影评论),输出是该评论的情感评分(如1到5的星级,或者0/1表示负面/正面情感)。在这种情况下,RNN读取整个输入序列,最后给出一个结果。
- 例如:输入序列为“这部电影很糟糕”,输出为情感标签(如负面评价)。
3. 一对多(One-to-Many)结构:
- 输入是一个单一的值,输出是一个序列,这种结构适用于从一个单一的输入生成多个输出的任务。例如,音乐生成任务中,输入可以是一个单一的音乐类型或者是音乐的第一个音符,网络根据这个输入生成一系列音符,从而构成一段完整的音乐序列。
- 例如:输入一个音乐风格(如古典音乐),然后生成一段音乐序列。
4. 多对多(Many-to-Many)结构(输入和输出长度不同):
- 这种结构适用于输入和输出序列长度不同的任务。例如,机器翻译中,输入一个法语句子,输出一个不同长度的英语句子。在这种情况下,RNN的结构分为两个部分:编码器和解码器。编码器处理输入序列,解码器生成输出序列。
- 例如:输入“Je suis étudiant”(法语),输出“I'm a student”(英语)。这里的输入和输出长度可能不同。
5. 总结:
处理不同类型的{输入输出}需要采用不同的模型架构,如下图所示
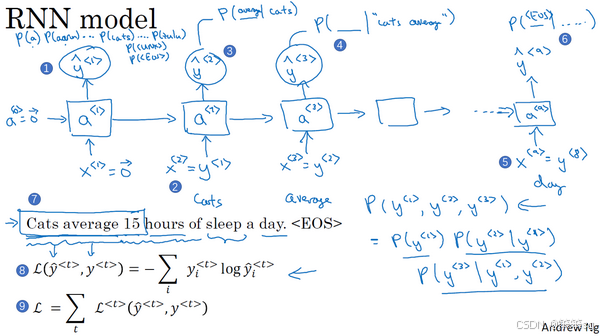
3.7 语言模型和序列生成
语言模型在自然语言处理中非常基础且重要,它通过计算句子或文本序列的概率,帮助系统做出合理的预测。RNN(循环神经网络)是一种常用的工具,可以有效地构建语言模型。
1)语言模型的定义
语言模型用于计算给定文本序列的出现概率。例如,在语音识别中,当系统听到相似的句子(如“the apple and pear salad”与“the apple and pair salad”)时,语言模型能够根据上下文判断哪个句子更为合理。语言模型通过评估句子中单词出现的概率,帮助系统选择最可能的句子。
2)语言模型的建立
-
数据准备:首先,需要一个大规模的文本语料库,这个语料库是训练模型的基础。通过标记化(tokenization),每个单词被转化为相应的数字索引或“one-hot”向量。一个句子的结束通常会用特殊的EOS(End of Sentence)标记。
-
RNN的使用:通过RNN,模型可以根据前一个单词来预测下一个单词。举个例子,给定句子“Cats average 15 hours of sleep a day”,通过RNN,模型依次计算每个单词出现的概率。每个时间步,RNN接收前一个单词的信息,并通过Softmax层计算下一个单词的概率分布。
-
输入与输出:例如,在预测“Cats average 15 hours of sleep a day.”时,RNN根据前面两个单词“Cats average”来预测第三个词“15”。然后,它会继续预测下一个单词直到整个句子完成。
-
损失函数:RNN通过计算预测单词与真实单词之间的差异来优化模型。这通常通过Softmax损失函数实现,在每个时间步计算输出的概率与实际单词的差距。
3)训练与生成
-
训练:RNN通过训练数据学习单词序列的模式,并调整权重以优化预测准确度。通过不断对比预测和实际单词,模型逐渐提高生成的文本质量。
-
生成文本:一旦语言模型训练完成,它可以用于生成文本。这是通过从训练中学到的单词序列中采样新的文本,实现自动生成类似莎士比亚风格或其他类型的文本。
3.8 对新序列采样
训练好一个序列模型后,了解其学到的内容的一种方式是通过新序列采样。序列模型可以模拟特定单词序列的概率分布,采样则是从这些概率分布中生成新的单词序列。
1)采样过程:
- 第一步是采样第一个词。输入一个起始符号,然后通过模型输出的softmax层来预测所有可能的下一个词,并根据该概率分布进行随机采样。
np.random.choice等函数可以用于这一操作。 - 接下来,将采样得到的第一个词作为输入,进入模型的下一时间步。模型会输出第二个词的概率分布,再进行采样。这个过程依此类推,每一步都将上一步的输出作为输入。
- 结束条件:如果模型字典中有EOS(句子结束标志),则可以继续采样直到遇到EOS标记。如果没有EOS标记,可以设定最大时间步数,或者不断采样直到满足其他终止条件。
2)基于字符与基于词汇的语言模型:
- 基于字符的模型:模型的字典包含字符(如字母、数字、空格等)。这种模型能够处理不在字典中的词(例如新词),但生成的文本通常会更长,并且捕捉长距离依赖的能力较差。训练时计算资源消耗大,因此不如基于词汇的模型广泛应用。
- 基于词汇的模型:字典包含整个单词。它在捕捉语言结构和长距离依赖时表现较好,但需要处理词汇外的词(如未知词)。
3)实际应用:通过基于词汇或字符的语言模型训练,你可以从训练过的模型中采样,生成新的文本。例如,如果用莎士比亚的作品训练模型,生成的文本可能如下所示:

"The mortal moon hath her eclipse in love. And subject of this thou art another this fold."
4)总结:语言模型的采样过程是基于已训练好的模型的概率分布来生成新的文本。无论是基于字符还是基于词汇的模型,它们都有各自的优缺点。基于字符的模型适用于处理未知词汇,但生成的序列较长且计算量大;基于词汇的模型则更高效,尤其是在捕捉长范围依赖时。
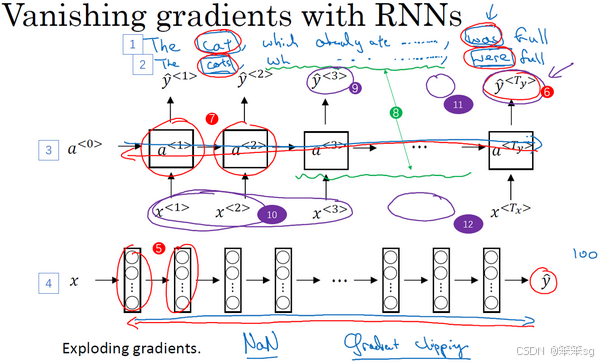
3.9 循环神经网络的梯度消失
1)梯度消失问题:
- 在RNN模型中,长期依赖关系(如语法中单数与复数形式的匹配)对于序列中的后续部分至关重要。然而,基本的RNN模型难以捕捉这种长期依赖,原因在于梯度消失问题。
- 当进行反向传播时,梯度会逐渐消失,尤其是在处理长序列时。即使输入序列的前部分(如单词“cat”)对后续输出(如“was”或“were”)至关重要,RNN也难以通过反向传播影响前面的计算。
2)原因:
- 在一个深层网络中,梯度逐层反向传播,如果网络层数过多,梯度很难有效传播回去,从而无法调整网络前层的参数。对于RNN,这个问题更为严重,因为时间步的数量(即序列的长度)可能很长,导致梯度逐渐消失。
3)梯度消失的影响:
- 由于基本RNN无法有效捕捉长期依赖,它的输出通常只受附近输入的影响,而无法依赖于序列开头的内容。
- 对于像“cat”和“cats”这种需要长期记忆的语法规则,RNN往往不能在后续词汇(如“was”和“were”)中做出正确的预测。
4)梯度爆炸:
- 另一个问题是梯度爆炸。随着网络层数增多,梯度有时会指数型增加,导致权重参数爆炸,从而使得网络计算出现数值溢出(如NaN错误)。
- 解决方法:使用梯度修剪,即当梯度超出某个阈值时,缩放梯度向量,以避免其过大。
为了解决这些问题,我们可以使用RNN模型的一些变体,包括门控循环单元(GRU)和长短期记忆网络(LSTM)等等。这些内容将在下节给出。
3.10 GRU单元(Gated Recurrent Unit, GRU)
在本节中,我们将学习GRU(门控循环单元),它是RNN的一个改进,能够更好地捕捉深层的依赖,并有效缓解梯度消失问题。GRU的设计通过引入门控机制,使得网络能够在处理长序列时,选择性地更新或保持记忆,从而解决了传统RNN在长序列中难以记住信息的问题。
1)GRU的核心结构:
- 记忆细胞:在GRU中,每个时间步都有一个记忆细胞,类似于RNN中的隐藏状态,但它具备更强的记忆能力。
- 更新门(Update Gate):更新门决定了记忆细胞的更新时机。它是通过sigmoid函数计算得到的,输出一个0到1之间的值。值接近1时,记忆细胞会被新候选值更新,值接近0时,记忆细胞的值保持不变。
- 重置门(Reset Gate):用于控制如何利用上一时间步的记忆状态来生成候选记忆值。重置门的值在每个时间步都通过一个sigmoid激活函数计算,范围在0到1之间。重置门的作用是决定如何遗忘上一时间步的记忆。
- 候选值:GRU通过计算候选记忆值来更新当前的记忆状态,候选值是由输入和上一时间步的隐藏状态共同计算得到的。
2)GRU工作原理:
- 输入:每个时间步的输入包括上一时间步的隐藏状态和当前输入。
- 候选记忆值:通过一个新的tanh激活函数计算得到候选值,用于替代当前记忆细胞的值。
- 重置门:通过sigmoid函数计算得到更新门值,决定是否使用新的候选记忆值。
- 更新门:通过sigmoid函数计算得到更新门值,决定是否使用新的候选记忆值。
- 记忆细胞更新:根据更新门的值来决定是否更新记忆细胞。如果更新门的值为1,记忆细胞会被新的候选值更新;如果更新门的值为0,记忆细胞保持原来的值。
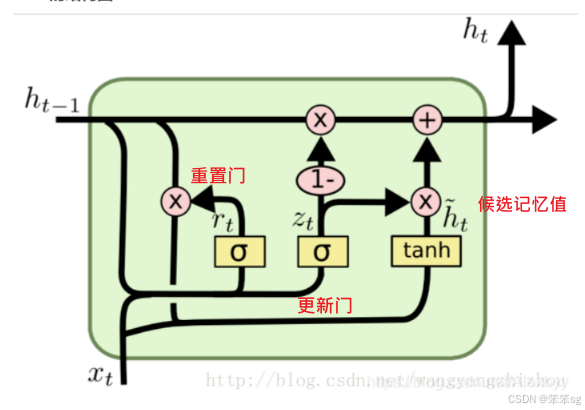
具体的计算公式如下:
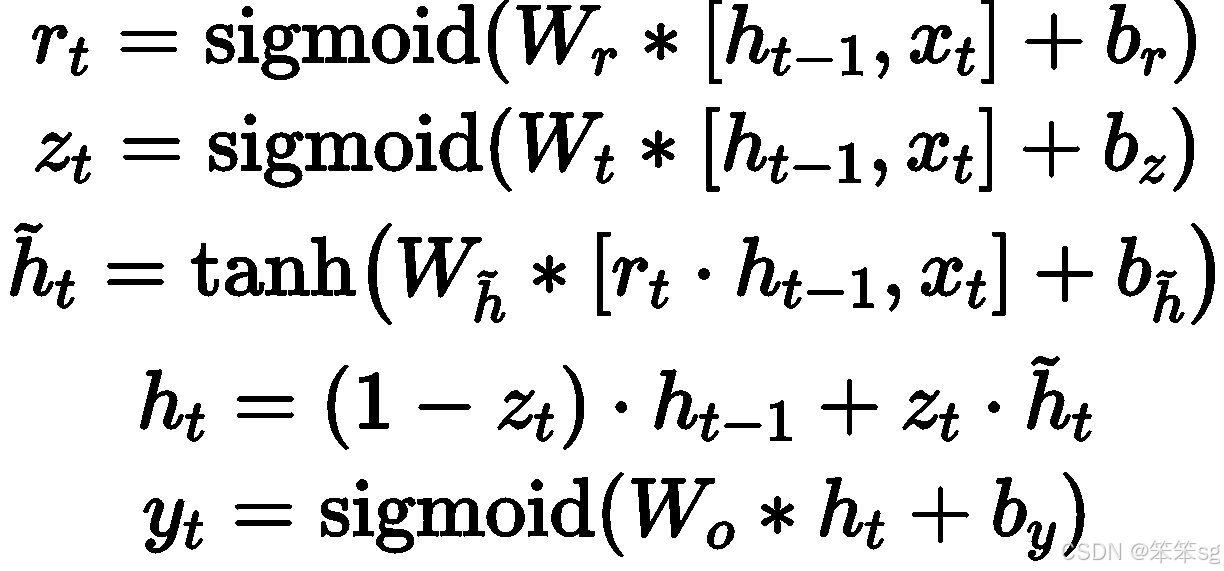
核心思想就是: 选择性地更新或保持记忆
3)GRU的优势:
- 缓解梯度消失问题:由于更新门的存在,GRU能够在较长的序列中保持记忆,从而避免了梯度消失问题。即使在长时间步的序列中,网络也能够有效地保留前期信息。
- 适应长依赖:通过动态控制记忆的更新和遗忘,GRU能处理长序列数据中复杂的长期依赖关系,特别适用于处理自然语言处理(NLP)中的任务,如机器翻译和文本生成等。
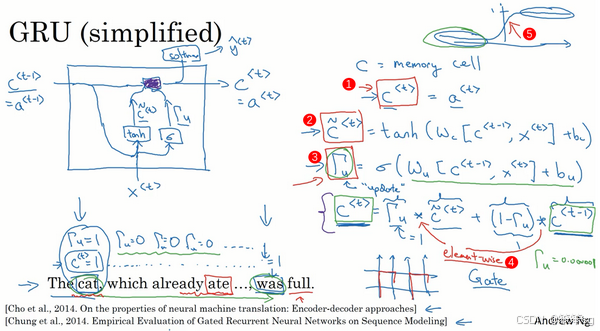
GRU是LSTM(长短时记忆网络)的简化版,广泛应用于序列建模任务中。它与LSTM相比,具有结构上更简单、计算效率更高的优点,但依然能够有效地解决梯度消失的问题,并且在许多实际问题中表现出色。
3.11 LSTM(长短时记忆网络)
1. 背景与动机
- RNN(Recurrent Neural Network)能够处理序列数据,具有很强的时间序列建模能力,但存在一个显著的问题——梯度消失。在长序列数据中,传统RNN无法有效记住早期的信息,导致模型难以捕捉长期依赖。
- LSTM由Sepp Hochreiter和Jürgen Schmidhuber于1997年提出,专门为解决RNN中的梯度消失问题设计,是一种特殊的RNN单元,能够有效地捕获长时间依赖。
2. LSTM的核心概念
LSTM通过引入记忆细胞(Cell State)和三个门控机制(Gate Mechanisms),来控制信息的流动,实现长期记忆的选择性保留和更新。
- 记忆细胞(Cell State,
): LSTM的核心结构,用于长期存储信息,类似于传输带,能够长时间保持和传递信息。
- 隐藏状态(Hidden State,
): 用于短期存储和输出信息,是模型的主要输出。
- 三个门控机制:
- 遗忘门(Forget Gate,
): 决定记忆细胞中的哪些信息需要被遗忘。
- 输入门(Input Gate,
): 决定当前时间步的输入信息要存入多少到记忆细胞中。
- 输出门(Output Gate,
): 决定从记忆细胞中输出多少信息作为隐藏状态。
- 遗忘门(Forget Gate,
3. LSTM的公式推导


4. LSTM工作流程图
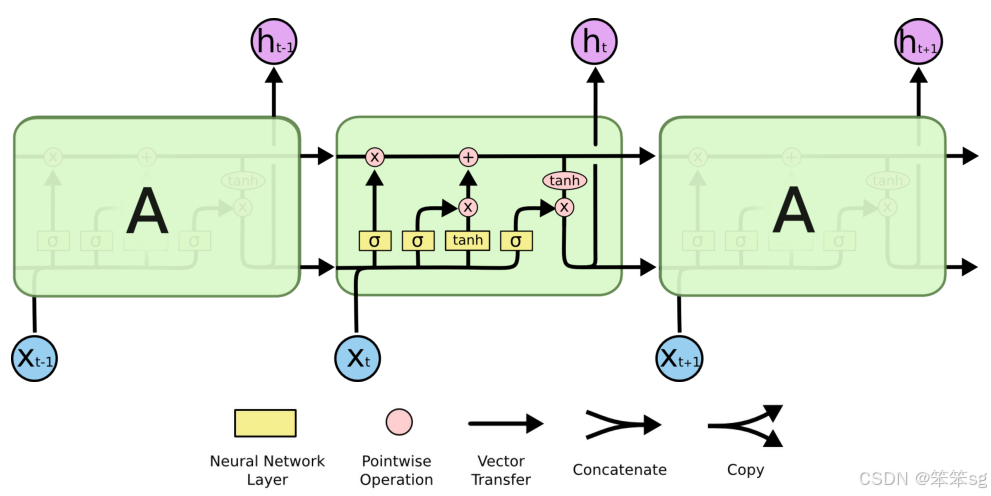
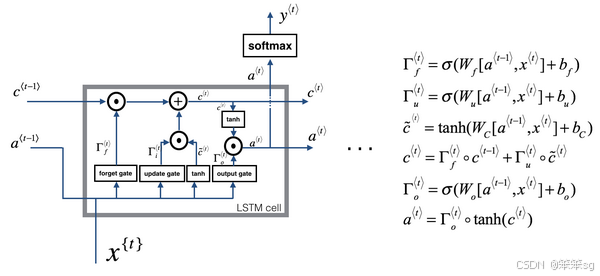

5. LSTM的优势
- 解决梯度消失问题:通过引入记忆细胞和门控机制,LSTM 能够长时间保留关键信息,避免信息在长时间序列中的衰减。
- 长期依赖建模:LSTM 能够选择性地保留或遗忘信息,适用于时间跨度较长的序列任务,如语言建模和时间序列预测。
6. LSTM的变体
- Peephole LSTM:增加了窥视孔连接,使门控机制直接访问上一个时间步的记忆细胞状态,提升信息捕获能力。
- Bi-LSTM(双向LSTM):通过正向和反向两个LSTM单元,结合两个方向的信息,适用于需要考虑上下文关系的任务(如自然语言处理)。
- Stacked LSTM:将多个LSTM层堆叠,提高模型的深度和表达能力。
7. LSTM和GRU的对比
在深度学习的历史上,LSTM也是更早出现的,而GRU是最近才发明出来的,它可能源于Pavia在更加复杂的LSTM模型中做出的简化。研究者们在很多不同问题上尝试了这两种模型,看看在不同的问题不同的算法中哪个模型更好。
如果你想选一个使用,我认为LSTM在历史进程上是个更优先的选择,所以如果你必须选一个,我感觉今天大部分的人还是会把LSTM作为默认的选择来尝试。虽然我认为最近几年GRU获得了很多支持,而且我感觉越来越多的团队也正在使用GRU,因为它更加简单,而且还效果还不错,它更容易适应规模更加大的问题。
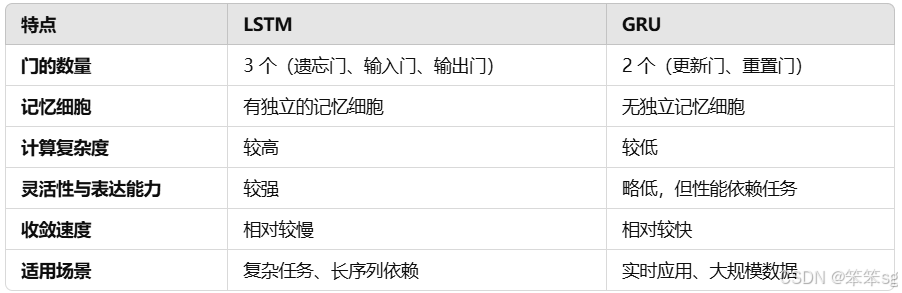
8. 应用场景
- 自然语言处理:如文本生成、机器翻译、情感分析,LSTM能够捕捉长时间的依赖关系。
- 时间序列预测:如股票价格预测、天气预测,LSTM擅长处理长时间依赖的时间序列。
- 语音识别:LSTM能够在序列数据中捕获特征的长期依赖性,提升识别准确度。
9. LSTM的缺点
- 计算复杂度高:参数量大,训练时间长,不适合大规模数据或计算资源有限的场景。
- 训练难度:LSTM 虽然缓解了梯度消失问题,但训练过程中仍存在梯度爆炸的风险,需要配合梯度裁剪等技术使用。
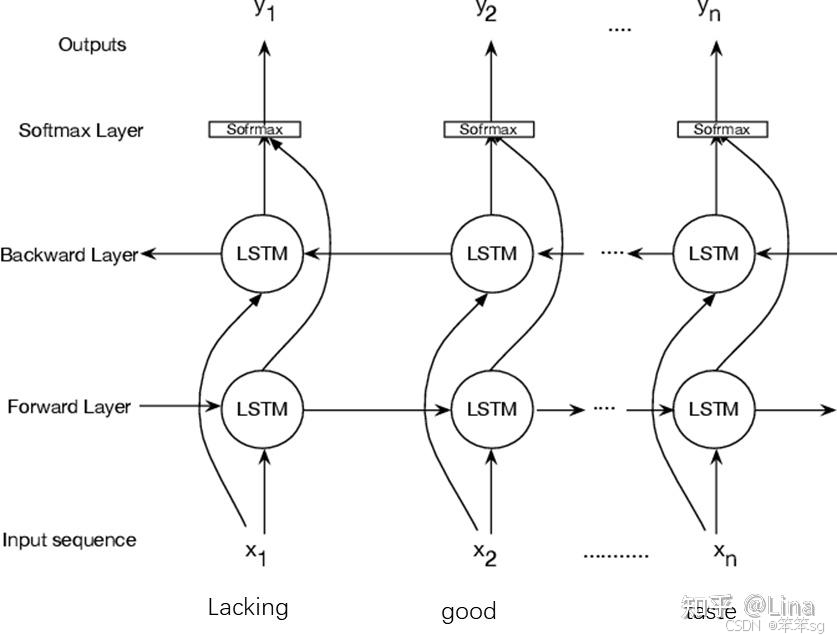
3.12 双向循环神经网络(Bidirectional RNN)
1. 动机与优势
双向循环神经网络(Bidirectional RNN,简称 BiRNN)的主要优势在于能够同时利用序列的前向和反向信息。传统的RNN只能利用历史信息(即前向信息),在一些任务中仅考虑过去的上下文是不够的。比如在命名实体识别(NER)任务中,仅根据“他提到Teddy…”无法判断Teddy是一个人名还是Teddy熊,但如果我们能看到后面的单词“Roosevelt”,则可以确定Teddy是美国总统Teddy Roosevelt。因此,通过引入反向传播层,BiRNN能更全面地捕捉序列中每个位置的上下文信息。
2. 结构
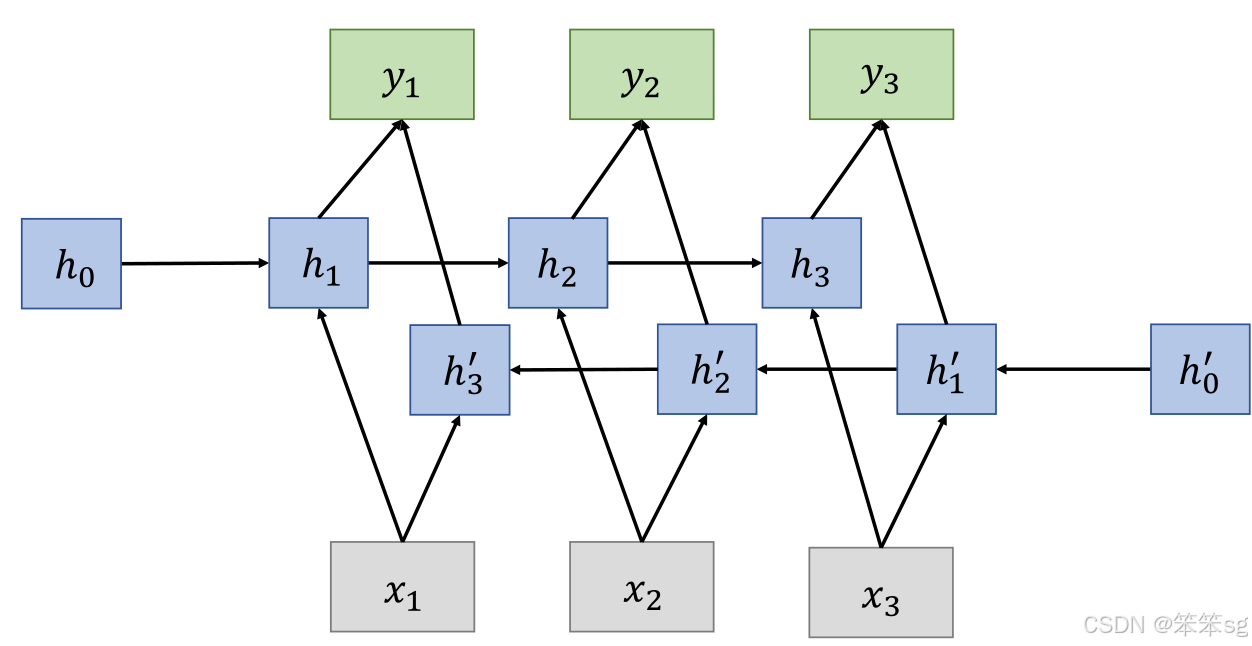
双向RNN包含两个隐藏层:
- 前向RNN层:从左到右处理输入序列,捕捉历史(前文)信息。
- 反向RNN层:从右到左处理输入序列,捕捉未来(后文)信息。
3. 计算流程
从前往后:从0到3时刻正向计算,得到并保存每个时刻的隐藏层的输出向后传播
从后往前:从3时刻向0反向传播,得到并保存每个时刻向后隐藏层的输出
![]()
![]()
对于每个时刻t,输入会同时提供给两个方向相反的RNN。
- 先从前往后计算
,再从后往前计算,最终得到两个隐状态;
- 完整的隐藏状态是把前向和后向的隐藏状态拼接起来:(如果前向和后向的隐状态都是1000*1维的,拼接后的就是1000*2维的)
![]()
- 输出由这两个单向RNN共同决定:
![]()
4. 总结
以上就是双向RNN的内容,这个改进的方法不仅能用于基本的RNN结构,也能用于GRU和LSTM。通过这些改变,你就可以用一个用RNN或GRU或LSTM构建的模型,并且能够预测任意位置,即使在句子的中间,因为模型能够考虑整个句子的信息。
这个双向RNN网络模型的缺点如下:
1)你需要完整的数据的序列,你才能预测任意位置。比如说你要构建一个语音识别系统,那么双向RNN模型需要你考虑整个语音表达,但是如果直接用这个去实现的话,你需要等待这个人说完,然后获取整个语音表达才能处理这段语音,并进一步做语音识别。对于实际的语音识别的应用通常会有更加复杂的模块,而不是仅仅用我们见过的标准的双向RNN模型。但是对于很多自然语言处理的应用,如果你总是可以获取整个句子,这个标准的双向RNN算法实际上很高效。
2)另一个缺点就是:引入反向层后,计算量翻倍,训练和推理速度会有所降低。
3.13 深层循环神经网络(Deep RNNs)
1. 背景与动机
在之前的学习中,我们介绍了基本的RNN模型及其改进版本(如LSTM、GRU、BiRNN),它们已经能够处理序列数据,并捕捉序列中的时间依赖性。然而,单层RNN的表达能力有限,难以学习复杂的序列特征和长期依赖。为了提升模型的表示能力和捕捉更深层次的特征,我们通常会堆叠多个RNN层,构建深层循环神经网络(Deep RNNs)。
2. 深层RNN的结构
深层RNN是在时间序列上进行展开的多个RNN层的堆叠。结构上类似于普通的深层神经网络(DNN),只是这里每一层是RNN而不是全连接层。

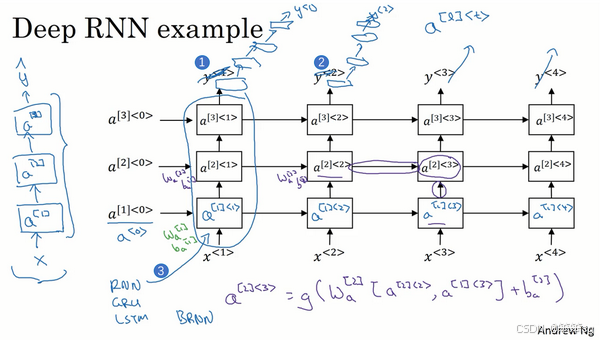
对于像左边这样标准的神经网络,你可能见过很深的网络,甚至于100层深,而对于RNN来说,有三层就已经不少了。由于时间的维度,RNN网络会变得相当大,即使只有很少的几层,很少会看到这种网络堆叠到100层。
但有一种会容易见到,就是在每一个上面堆叠循环层,把这里的输出去掉(上图编号1所示),然后换成一些深的层,这些层并不水平连接,只是一个深层的网络,然后用来预测。同样这里(上图编号2所示)也加上一个深层网络,然后预测y1。这种类型的网络结构用的会稍微多一点,这种结构有三个循环单元,在时间上连接,接着一个网络在后面接一个网络,当然y2和y3也一样,这是一个深层网络,但没有水平方向上的连接,所以这种类型的结构我们会见得多一点。
通常这些单元(上图编号3所示)没必要非是标准的RNN,最简单的RNN模型,也可以是GRU单元或者LSTM单元,并且,你也可以构建深层的双向RNN网络。由于深层的RNN训练需要很多计算资源,需要很长的时间,尽管看起来没有多少循环层,这个也就是在时间上连接了三个深层的循环层,你看不到多少深层的循环层,不像卷积神经网络一样有大量的隐含层。
3.14 词嵌入
在自然语言处理中,词嵌入(word embeddings) 是一种通过高维向量表示词汇的方式,克服了传统one-hot向量的局限性。这种方法显著提升了算法的泛化能力,使其能够理解词语之间的语义关系,成为NLP领域的核心概念之一。
1)One-Hot 表示的局限性
- 每个词被孤立表示,无法体现词语之间的语义相似性。
- 任何两个one-hot向量的内积为0,算法难以理解类似词之间的关系(如
apple和orange)。
2)词嵌入的优越性
- 特征化表示:用高维向量(例如300维)表示每个单词,向量的不同维度可以对应不同的特征。
- 如:性别(Gender)、高贵(Royal)、年龄(Age)、食物(Food)等。
- 相似词的向量具有相似的特征值。例如:
apple和orange的向量接近,因为它们都表示水果。king和queen的向量也接近,因为它们都与“高贵”和“成年”相关。
- 通过这种表示,算法能从现有知识(如“orange juice”)泛化到新知识(如“apple juice”)。
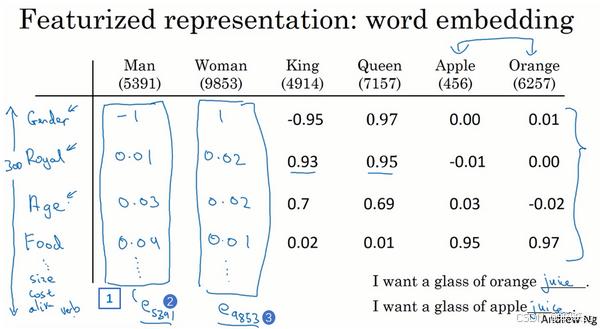
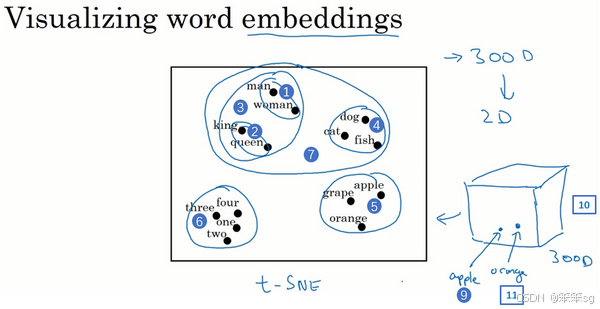
3)词嵌入的可视化
- 使用 t-SNE 等降维算法,将高维词向量投影到2D空间。
- 可视化结果展示了相似词的聚集现象(如“人”、“动物”、“水果”等分别形成聚类)。
3.15 使用词嵌入
在本节内容中,我们学习了如何将词嵌入应用于自然语言处理(NLP)任务,并通过迁移学习提升模型性能,特别是在标注训练数据较少的情况下。以下是关键要点的总结:
1. 词嵌入的应用场景
- 词嵌入将单词表示为稠密的向量,使得具有相似意义的单词在向量空间中的表示也更为接近。
- 在命名实体识别任务中,词嵌入帮助算法理解不常见词汇的语义关系。例如,能够从“orange farmer”(种橙子的农民)类推到“durian cultivator”(榴莲培育家)。
2. 词嵌入与迁移学习
- 第一步:从大量的无标签文本中学习词嵌入。这可以通过自行训练,也可以直接使用预训练的词嵌入模型(如Word2Vec、GloVe等)。
- 第二步:将预训练的词嵌入应用于小型标注训练集,用稠密向量表示单词,替代高维的one-hot向量。
- 第三步:在任务训练中决定是否微调词嵌入。如果标注数据集较小,通常不需要调整嵌入向量。

3. 优势
- 泛化能力:词嵌入捕获了单词间的语义关系,可以帮助算法更好地理解和推理语义相近的单词。
- 效率提升:相比于高维one-hot向量,低维词嵌入向量更加紧凑且易于计算。
- 迁移学习:通过预训练的知识迁移,提升在小型数据集上的性能。
4. 适用范围
- 词嵌入广泛用于任务数据量较小的NLP应用中,如命名实体识别、文本摘要、指代消解等。
- 对于有大量数据的任务(如语言建模和机器翻译),迁移学习的价值较低,因为可以直接利用大规模数据进行训练。
5. 词嵌入与人脸编码的相似性
- 两者都学习固定维度的向量表示(人脸编码为128维,词嵌入通常为300维)。
- 不同点在于,人脸编码模型可以处理任意新的人脸图像,而词嵌入的单词表示基于固定的词汇表,未见过的单词会被处理为“未知单词”。
3.16 词嵌入的特性
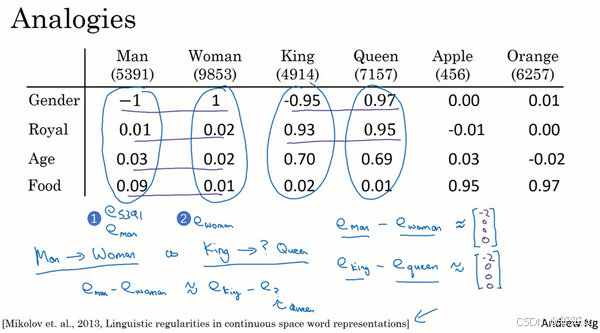
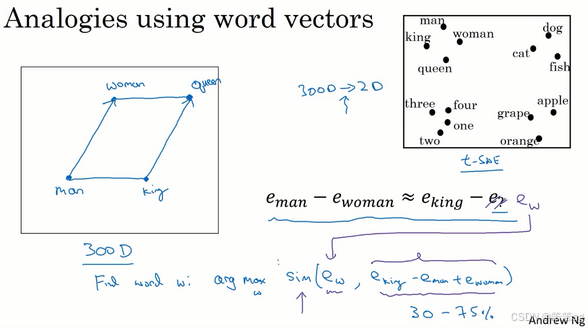
1. 类比推理的实现:
- 词嵌入可以帮助实现类比推理。例如:
- man 对应 woman,那么 king 对应 queen。
- 算法通过向量运算实现类比推理:
- 对嵌入向量
和
,计算它们的差值:
;
- 类似地计算
;
- 结果显示两组差值在语义上的一致性主要体现在性别维度。
- 对嵌入向量


2. 实现类比推理的核心思想:
- 给定已知的三个词嵌入向量
,寻找
使得:
- 使用相似度函数(如余弦相似度)找出与
最接近的向量
3. 类比推理的应用及局限性:
- 通过大规模语料库训练,词嵌入可以学习常见的关系模式:
- 性别关系:man:: boy;
- 国家与首都:Canada:: Kenya;
- 比较关系:big:: tall;
- 货币关系:Yen:: Ruble。
- 准确率取决于训练细节,通常在 30%~75%。
4. 词嵌入的可视化:
- 通过 t-SNE 将高维词嵌入向量投影到 2D 平面,可视化其关系。
- 注意:t-SNE 是非线性映射,可能无法保持原高维空间中的平行四边形关系。
5. 相似度测量方法:
- 余弦相似度 是常用方法,用于衡量两个向量的相似性:
-

- 夹角越小,余弦相似度越接近 1(向量越相似)。
- 欧氏距离 可用于测量向量之间的距离。
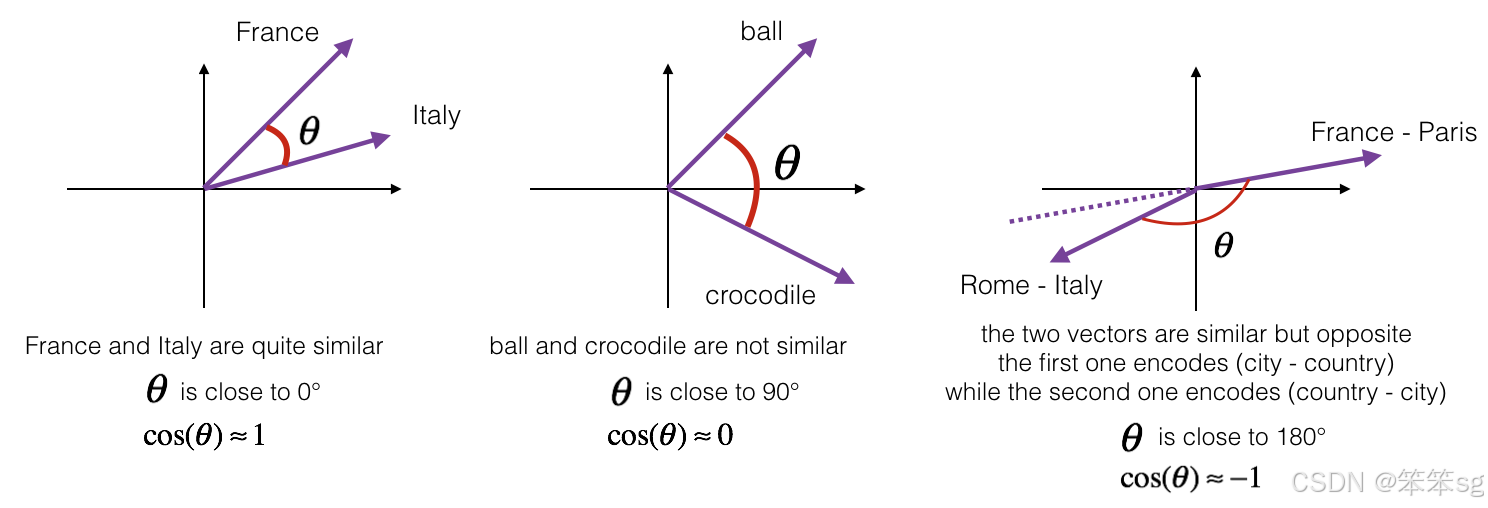
6. 词嵌入的意义:
- 词嵌入能自主捕捉语义上的一般性模式,揭示单词之间的内在关系;
- 虽然类比推理并非 NLP 中最核心的任务,但它展示了词嵌入在捕捉语义信息上的强大潜力。
3.17 嵌入矩阵
1. 嵌入矩阵的定义与结构
- 嵌入矩阵(Embedding Matrix):一个维度为 d×V 的矩阵,其中:
- d 是嵌入向量的维度(例如 300)。
- V 是词汇表的大小(例如 10,000 或包括未知词 <UNK> 为 10,001)。
- 矩阵的每一列代表词汇表中一个单词的嵌入向量。
2. 嵌入向量的提取
- 假设某个单词的编号是 j,我们使用一个 V-维的 one-hot 向量来表示它,记作
,这个向量:
- 仅在第 j 位置是 1,其他位置为 0。
- 嵌入向量的计算:
- 用嵌入矩阵 E 乘以 one-hot 向量
- 因为
- 用嵌入矩阵 E 乘以 one-hot 向量
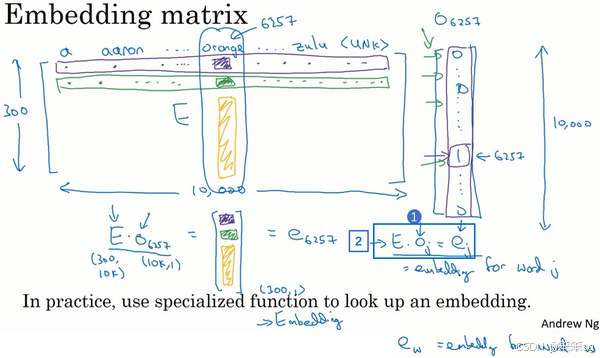
3. 矩阵计算的优化
- 理论上,用矩阵乘法计算嵌入向量是可以的,但效率低下:
- V-维 one-hot 向量大部分元素为 0。
- 矩阵乘法会浪费大量计算资源。
- 实际上,深度学习框架(如 Keras)会通过优化函数直接查找嵌入矩阵中对应列,避免矩阵乘法,提高效率。
4. 嵌入矩阵的学习
- 学习嵌入矩阵的目标是优化矩阵中的参数,使嵌入向量更好地表示单词的语义关系。
- 嵌入矩阵的初始化通常是随机的,通过梯度下降法逐步优化。
- 嵌入层(如 Keras 的
Embedding层)用于高效地存储和提取嵌入向量。
3.18 学习词嵌入
1. 学习词嵌入的基本方法
- 通过语言模型的构建来学习词嵌入。
- 语言模型目标:给定上下文,预测目标词(如“___orange ___”)。
- 这种方法可以通过优化语言模型的表现来间接学习嵌入向量。
- 嵌入矩阵的优化:
- 随机初始化嵌入矩阵。
- 通过神经网络学习,使嵌入向量能有效捕捉单词语义关系。
2. 具体算法步骤
- 输入上下文词
- 每个上下文单词用 one-hot 向量表示。
- 将 one-hot 向量与嵌入矩阵相乘,得到对应的嵌入向量。
- 神经网络处理
- 嵌入向量组合成固定维度的输入(如 4 个单词组成 1200 维向量)。
- 经过隐藏层和 softmax 层,预测目标词在词汇表中的概率分布。
- 优化目标
- 通过反向传播和梯度下降,最大化目标词的预测准确率。
- 训练过程中,嵌入矩阵的参数逐渐优化,单词的嵌入向量捕捉其语义关系。
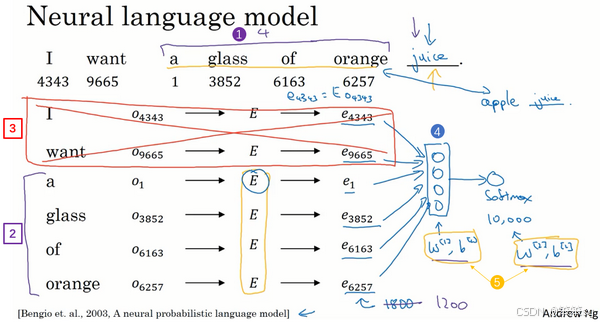
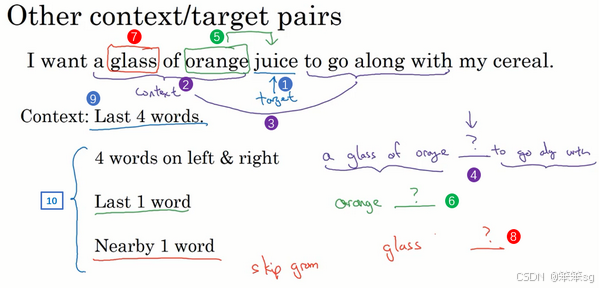
3. 不同上下文的选择
- 常见上下文:目标词前几个单词。例如:
- 输入目标词前 4 个单词,预测下一个词。
- 适用于构建语言模型。
- 其他上下文形式:
- 左右上下文:例如目标词的左右各 4 个单词。
- 单词邻近关系:用目标词前一个单词或附近一个单词作为上下文。
- 简化上下文:如仅用目标词前一个单词。
4. 算法的效果
- 嵌入向量的优化机制:
- 词嵌入优化的目标是让语义相似的单词(如 "apple" 和 "orange")具有相似的向量表示。
- 算法通过在不同上下文中学习共现关系来捕捉单词的语义。
- 简单的上下文(如 Skip-Gram 模型的单个词上下文)也能实现良好的词嵌入。
3.19 Word2Vec
1)背景与目标
Word2Vec 是一种用于学习高质量词嵌入的方法。相比传统神经语言模型,其计算效率更高。Word2Vec 包括两种主要模型:
- Skip-Gram: 给定一个目标词,预测其上下文词。
- CBOW(Continuous Bag-of-Words): 给定上下文词,预测中间的目标词。
2)Skip-Gram 模型
-
工作原理:
- 从语料中抽取一个目标词(如 orange)和其上下文词(如 juice、glass、my),构造一个监督学习问题。
- 随机从目标词的正负一定范围(如 ±10 个词距)内选择上下文词。
- 使用神经网络得到目标词映射到上下文词的概率分布。
-
模型结构:
- 目标词通过 one-hot 向量表示。
- 嵌入矩阵用于将 one-hot 向量转化为低维嵌入向量。
- 该低维嵌入向量进入神经网络。
- 使用 softmax 函数计算上下文词的概率分布。
- 优化 softmax 的交叉熵损失函数,更新嵌入向量。
- 目标词和上下文词的嵌入向量表示均得到了优化。
-
挑战:
Softmax 的计算复杂度较高,尤其是当词汇表较大(如 10,000 或更多单词)时,需要对所有词的概率求和,计算成本昂贵。
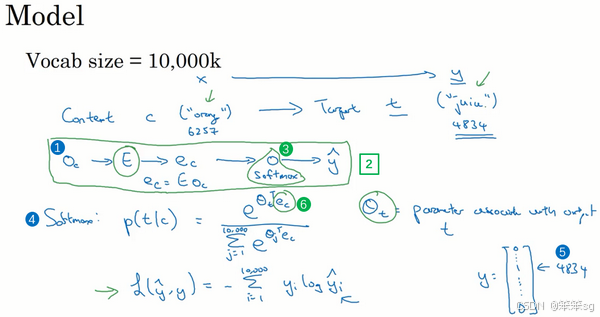
3)优化方法
-
分级 Softmax(Hierarchical Softmax):
- 构建一个分类树,使用多个二分类器逐步缩小范围,直到确定目标词。
- 计算成本由线性降低到对数级,与词汇表大小对数成正比。
- 树形结构可根据词频优化,使常见词位于树的顶部,罕见词位于较深的叶子节点。
-
负采样(Negative Sampling):
- 修改训练目标,降低对大词汇表的依赖。
- 在下个章节中会详细讲解。
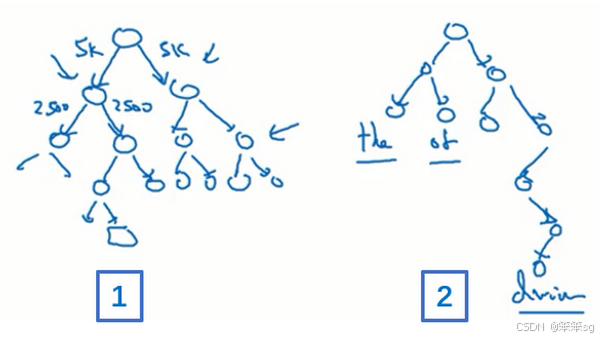
4)语料采样策略
- 问题:高频词(如 the、of)会频繁出现,影响模型对低频词(如 durian)的学习。
- 解决方案:使用非均匀采样方法,平衡高频和低频词的权重,确保模型能够学习到稀有单词的嵌入。
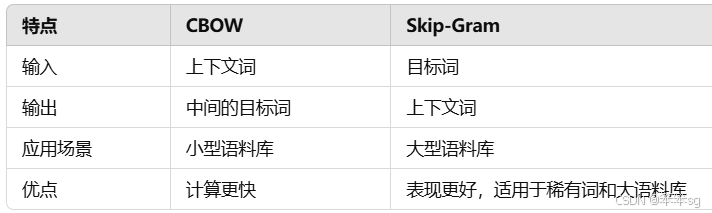
5)CBOW 与 Skip-Gram 比较

3.20 负采样(Negative Sampling)
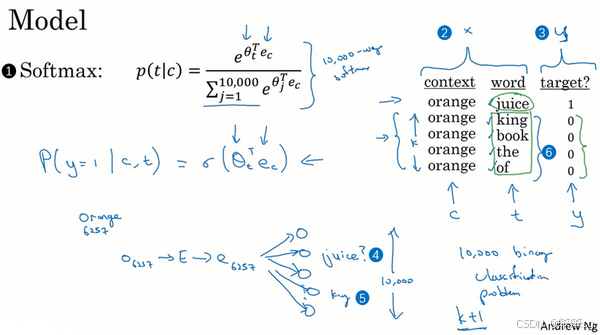
负采样(Negative Sampling)是 Skip-Gram 模型中的一种优化技巧,它旨在降低模型训练时的计算复杂度,尤其是减少了计算 softmax 时的高昂代价。负采样通过将原本需要计算所有词汇的概率分布的任务,转变为一个更加高效的二分类问题来解决这个问题。以下是负采样的关键步骤和原理:
1. 生成正样本和负样本
正样本:
- 给定一对目标词和上下文词(例如“orange”和“juice”),如果它们在文本中出现在相邻位置,就认为这是一个正样本,并给它标记为1。
负样本:
- 为了生成负样本,从词汇表中随机挑选一个不在上下文范围内的词(例如“king”),并将其标记为0。
- 这样,对于每个正样本,都会生成多个负样本。例如,“orange”和“juice”是正样本,接着可以随机选取其他词汇(如“king”、“book”等)作为负样本,标记为0。
- 那么,选择多少个负样本合适呢?Mikolov等人推荐小数据集的话,K从5到20比较好。如果你的数据集很大,就选的小一点。对于更大的数据集K就等于2到5,数据集越小就越大。那么在这个例子中,我们就用K=4。
2. 训练模型
负采样将问题转化为二分类问题。每一对词(目标词与上下文词或随机挑选的词)被当作一个输入,模型要预测这个输入是正样本(上下文词和目标词)还是负样本(随机词对)。具体步骤如下:
- 使用目标词和上下文词的嵌入向量,通过它们的内积来计算它们的关联度。
- 然后,将结果传递给一个 sigmoid 函数,预测概率为 1 或 0,表示这是一个正样本还是负样本。
3. 如何减少计算成本
-
避免计算整个词汇表的 softmax:传统的 Skip-Gram 模型需要计算整个词汇表(通常包含成千上万的单词)的 softmax,计算量巨大。而负采样只关注少数的负样本,每次只选择一小部分词汇(例如5个负样本 + 1个正样本),极大地减少了计算量。
-
训练多个二分类器:负采样将整个任务拆分成多个独立的二分类问题。对于每个目标词,只需训练一些正样本和负样本,避免了高维的softmax计算。(每个上下文词有多个二分类器)
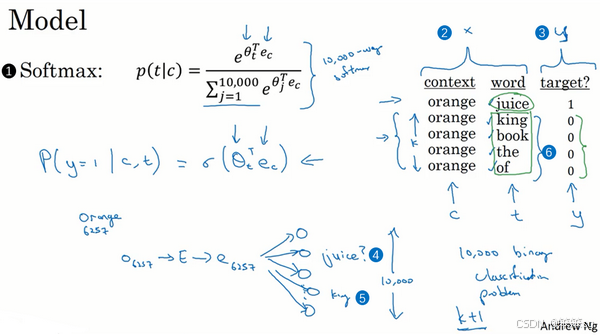
- 如上图所示,预测词汇表中这些可能的单词。把这些看作10,000个二分类逻辑回归分类器,但并不是每次迭代都训练全部10,000个,我们只训练其中的5个,我们要训练对应真正目标词那一个分类器,再训练4个随机选取的负样本,这就是K=4的情况。 所以不使用一个巨大的10,000维度的softmax,因为计算成本很高,而是把它转变为10,000个二分类问题,每个都很容易计算,每次迭代我们要做的只是训练它们其中的5个,一般而言就是K+1个,其中K个负样本和1个正样本。这也是为什么这个算法计算成本更低,因为只需更新K+1个逻辑单元,K+1个二分类问题,相对而言每次迭代的成本比更新10,000维的softmax分类器成本低。
4. 如何选择负样本
负样本的选择对于模型的效果有很大影响,通常有两种常见方法:
- 频率采样:根据词的频率进行负采样,高频词(如“the”、“is”等)会被更多地选择为负样本。Mikolov等人提出,通过对词频进行某种调整(如频率的某个幂次方),可以有效避免高频词过于频繁地出现在负样本中。
- 均匀采样:随机选择负样本,不考虑词频,但这种方法在实际中表现较差,因为它没有利用到语料库的统计特性。
- 经验值法——次方采样:上述两个方法的折中。次方采样是作者提出的一种折中的方法。它基于词频进行采样,但不是直接按词频比例来采样,而是将词频的次方作为权重,来调整各个词被选中的概率。例如,如果某个词 "like" 出现频率较高,我们并不会按其原始频率来采样,而是按其频率的 次方(例如频率的 0.75 次方)来采样。这样频繁出现的词会被相对减少采样的概率,但依然保持了一定的选择倾向。这种方法的好处是它避免了过度选择高频词(如“the”、“is”等),同时也避免了完全随机选择,既能捕捉到一些常见词的语境,也不会让模型过于依赖这些常见词。(Mikolov 等人承认他们并没有理论证明这个次方采样方法是最优的,但他们发现实验结果表明这种方式的效果非常好,且广泛被采用。)
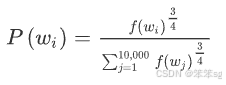
5. 优化目标
负采样的优化目标是:
- 正样本:使目标词和上下文词的内积值接近1。
- 负样本:使目标词和随机选出的词的内积值接近0。
3.21 GloVe算法概述:
GloVe(Global Vectors for Word Representation)是一种用于计算词嵌入(word embeddings)的算法,由Jeffrey Pennington、Richard Socher和Chris Manning于2014年提出。与Word2Vec和Skip-Gram等算法不同,GloVe并非直接基于局部上下文窗口,而是通过统计全局词与词之间的共现信息来学习词向量。
1)主要思想:
GloVe的核心思想是将词与词之间的共现信息作为输入,通过最小化一个损失函数来学习词向量。它的目标是使得词嵌入能够很好地预测某两个词在上下文中的共现频率。
具体来说,假设一个词i和另一个词j在某个上下文窗口中共同出现的次数为,Glo
Ve试图通过以下公式来最小化误差:
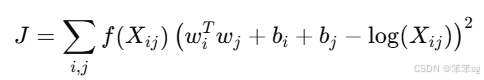
其中:
和
是词
i和词j的词向量。和
是词
i和j的偏置项。是词
i和词j在训练集中的共现次数。是加权函数,用于对频率较高或较低的共现进行调整。
2)算法流程:
- 统计共现矩阵:首先,统计整个语料库中所有词对的共现次数,构成一个共现矩阵。
- 加权函数:由于某些词(如停用词)出现频率过高,可能会干扰训练,因此使用加权函数
- 如果
- 对于频率较低的词,也会给予一定的权重,避免完全忽略它们。
- 如果
- 优化目标函数:GloVe算法的目标是通过最小化上述损失函数来优化词向量。
3)GloVe的优点:
- 全局信息:GloVe利用了全局共现信息,能够捕捉到词与词之间的全局关系。
- 对称性:词
i和词j的关系是对称的,即与
相同,优化过程也具有对称性。
4)关键点:
- 加权函数:加权函数的设计至关重要,通常采用类似
的形式,其中
α控制了权重的衰减程度。这个设计可以避免过于频繁的词对(如停用词)在训练中占据过大的权重。 - 对称性:共现矩阵的统计是对称的,因此GloVe优化过程中,词对的顺序不影响最终结果,优化目标具有对称性。
3.22 嵌入向量的维度之间一定是独立无关的么?一定有清晰的语义特征么?
1. 词向量的维度和语义组合:
词嵌入算法(如Word2Vec、GloVe等)通过优化一个目标函数,学习出词语之间的关系和语义相似性。每个词的嵌入向量通常是高维的(例如100维、300维等),而每一维并不代表某个清晰可理解的语义特征。例如,某个维度可能与“性别”(Gender)相关,另一个维度可能与“贵族身份”(Royalty)相关,但这些维度并没有明确的对应关系,而且这只是我们举的例子罢了。词嵌入向量的维度实际上是算法学习到的高维空间中的抽象表示,它们并没有直接与具体的语义特征(如Gender、Age等)一一对应。
2. 线性组合与特征不可分:
词嵌入的每个维度并不一定是完全独立的。事实上,词嵌入是通过对大量文本数据的上下文关系进行建模,从而找到一种空间中的结构,使得语义相似的词语尽量在嵌入空间中接近。然而,这种结构是通过学习到的“线性变换”来表示的,嵌入空间中的每个维度可能是多个潜在语义特征的组合。一个词向量的某个维度可能同时反映了多个特征(如Gender和Age),因此很难单纯地从向量的每一维度中提取出一个清晰、单一的语义特征。

3. 非正交性:
在理论上,我们可能希望词嵌入的各个维度之间是“正交的”(即相互独立的)。但在实际的词嵌入训练中,这些维度通常不是正交的。也就是说,某些维度可能会有重叠,表示的是多种语义特征的组合。这样一来,我们无法直接从嵌入向量中区分出具体的单一特征,而只能将其看作是多个语义特征的交集或组合。
4. 上下文依赖:
词嵌入是通过上下文中的词语信息来学习词的表示的。一个词的词向量在不同的上下文中可能会发生变化。因此,学习到的词向量在某些上下文中可能会有不同的解释和表现,而不是固定的、易于理解的语义特征。这种依赖上下文的特性使得词嵌入中的每个维度并不直接对应到一个具体的、独立的语义特征。
值得注意的是,实验表明,尽管嵌入向量的各个维度不能直接解释为具体的特征,但它们能够有效地表示词语间的语义和上下文关系。
3.23 情感分类(Sentiment Classification)
情感分类(Sentiment Classification)任务是自然语言处理(NLP)中的一个重要模块,其目的是分析文本的情感倾向(如积极、消极或中立)。例如,分析餐馆评论的情感,判断评论者的评分和评价内容。情感分类广泛应用于社交媒体监控、产品评论分析、客服反馈等领域。

1)情感分类挑战:
- 标注数据集有限:在很多实际情况中,标注的数据集较小,通常为几千到几万个词,这使得训练准确的分类模型具有挑战性。
- 词嵌入的帮助:词嵌入技术通过将词语转换为向量表示,可以有效提升分类模型的性能,特别是在训练数据较少时。
2)情感分类模型的基本步骤:
- 输入和词嵌入:首先,输入文本(如餐馆评论)会被转换为词向量(通过预训练的词嵌入矩阵)。每个词都对应一个向量,这些向量在大规模语料库中通过算法(如Word2Vec、GloVe等)学习得来,能够捕捉词之间的语义关系。
- 特征向量合成:将每个词的词嵌入向量进行加和或平均,得到一个固定长度的向量表示整个句子的语义信息。这些合成的特征向量被传入分类器进行预测。
3)问题与优化:
- 忽略词序的问题:简单的向量加和或平均会忽略词序信息,可能导致误分类。例如,多个“good”出现在评论中时("Completely lacking in good taste, good service, and good ambiance."),简单加和后可能错误地推断为正面评价,而这句话实际上是负面评价。
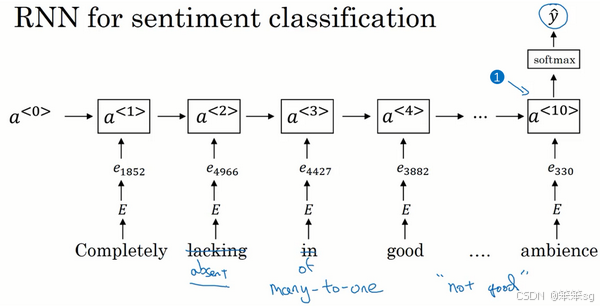
- 改进方案:RNN(循环神经网络):为了解决词序问题,可以使用RNN。RNN通过顺序处理文本,能够捕捉上下文和词序信息,更准确地反映情感的变化。例如,"not good" 和 "good" 会有不同的处理方式,避免了简单加和的错误。
4)泛化能力:
- 词嵌入的优势:即使标注训练集中的某些词没有出现,经过大规模语料库训练的词嵌入仍能提供足够的语义信息。这使得模型能够处理未见过的词语,提高了分类器的泛化能力。
3.24 词嵌入除偏(Debiasing Word Embeddings)
在本章节中,我们将讨论如何减少或消除词嵌入中的偏见,特别是性别、种族等方面的偏见。随着机器学习和人工智能在社会中的应用越来越广泛,确保算法不带有非预期的偏见变得非常重要,因为这些偏见可能影响从大学录取到刑事判决等多个领域的决策。词嵌入是深度学习中常用的表示方式,但它们会从训练数据中学习到偏见,并可能将这些偏见映射到词汇中。
一个例子:
如果Man对应Computer Programmer,那么Woman会对应什么呢?这篇论文:Bolukbasi T, Chang K W, Zou J, et al. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings[J]. 2016.)的作者Tolga Bolukbasi、Kai-Wei Chang、James Zou、Venkatesh Saligrama和 Adam Kalai发现了一个十分可怕的结果,就是说一个已经完成学习的词嵌入可能会输出Man:Computer Programmer,同时输出Woman:Homemaker,那个结果看起来是错的,并且它执行了一个十分不良的性别歧视。如果算法输出的是Man:Computer Programmer,同时Woman:Computer Programmer这样子会更合理。同时他们也发现如果Father:Doctor,那么Mother应该对应什么呢?一个十分不幸的结果是,有些完成学习的词嵌入会输出Mother:Nurse。
Bolukbasi等人(2016年)提出了一种方法来消除词嵌入中的性别偏见。具体方法包括以下几个步骤:
-
识别偏见趋势:首先要辨别出训练好的词嵌入中与性别偏见相关的趋势。这可以通过对性别相关的词汇(如“man”和“woman”)进行向量平均,识别出性别偏见的方向。
-
中和偏见:对于性别中立的词汇(如“doctor”和“babysitter”),我们需要通过数学方法(例如通过奇异值分解或PCA)来减少它们在性别偏见方向上的分量,确保它们在性别维度上保持中立。
-
均衡词对:对于一些本身包含性别含义的词对(如“grandmother”和“grandfather”),我们希望它们与其他性别中立词的距离相同。通过均衡步骤,可以调整这些词对的词向量,使它们在性别维度上达到相等的相似度。
公式的推导有点复杂,感兴趣的请参见原文。
3.25 基础模型(Basic Models)
1. Seq2Seq 模型简介
- 目标:将一个输入序列(如法语句子)转换为一个目标序列(如英语句子)。
- 工作原理:
- 编码器(Encoder):使用 RNN(GRU 或 LSTM)处理输入序列,将其转化为一个固定长度的向量,代表输入序列的语义信息。
- 解码器(Decoder):接收编码器的输出,逐步生成目标序列的每个词,直到句子结束。
- 生成过程中,解码器将前一次输出作为下一步的输入,类似语言模型生成文本的方式。
2. 机器翻译中的应用
- 示例:
- 输入:法语句子 “Jane visite l’Afrique en septembre.”
- 输出:英语句子 “Jane is visiting Africa in September.”
- 关键技术:
- 编码器负责将整个法语句子编码为语义向量。
- 解码器逐词生成英语句子,利用目标语言的上下文关系。
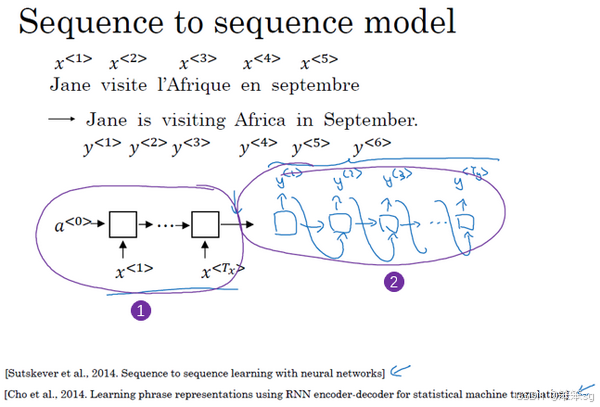
3. 图像描述(Image Captioning)模型
- 目标:为图像生成自然语言描述。
- 实现方法:
- 使用预训练卷积神经网络(如 AlexNet)提取图像特征。
- 将提取的特征向量输入到 RNN 中,作为序列生成的初始状态。
- RNN 输出单词序列,构成对图像的描述。
- 示例:
- 输入:一张猫的图片。
- 输出:“A cat sitting on a chair.”
- 优势:
- 这种模型在生成简短描述时表现优秀。
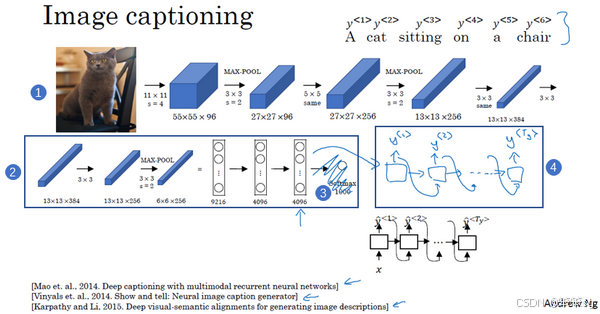
4. Seq2Seq 和图像描述模型的共同点与区别
- 共同点:
- 都采用编码器-解码器结构。
- 输出序列逐步生成,依赖上下文信息。
- 区别:
- 输入类型:Seq2Seq 模型的输入是文本序列,而图像描述模型的输入是图像特征向量。
- 生成目标:Seq2Seq 模型关注翻译的准确性;图像描述模型关注描述的贴切性。
3.26 条件语言模型及搜索算法
1. 机器翻译与条件语言模型
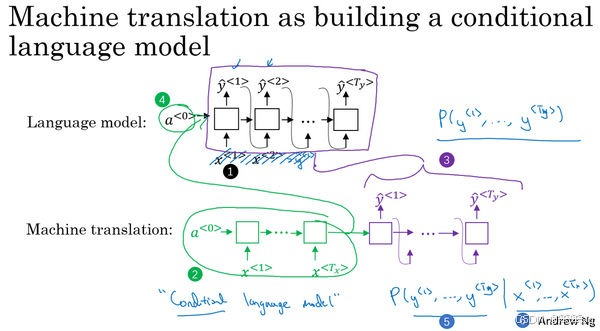
-
条件语言模型:与传统语言模型不同,它根据输入句子(如法语)生成目标语言句子(如英语)。输出的句子概率不仅取决于目标语言的语法规律,还取决于输入语言的内容。
- 例如,法语句子 “Jane visite l’Afrique en septembre.” 的翻译可能是:
- 高质量翻译:Jane is visiting Africa in September.(较优)
- 可接受翻译:Jane is going to be visiting Africa in September.(冗长)
- 差翻译:Her African friend welcomed Jane in September.(错误理解)
- 例如,法语句子 “Jane visite l’Afrique en septembre.” 的翻译可能是:
-
目标:生成一个目标句子,使条件概率 P(y|x) 最大化,其中 x 是输入句子,y 是目标句子。
-
可以看到机器翻译模型与语言模型的不同之处就在于:后者总是以零向量(上图编号4所示)开始,而前者则是以输入的整个序列x作为开始;后者输出任意句子,而前者输出以x为输入前提下概率最大的y。
2. 搜索算法:贪心搜索的局限性
- 贪心搜索(Greedy Search):
- 每次选择当前最可能的单词(概率最大)。
- 逐步生成句子。
- 问题:
- 贪心策略可能导致局部最优,错失全局最优句子。
- 示例:
- 局部最优:Jane is going to be visiting Africa in September. (“going”在前几个词中较常见)
- 全局最优:Jane is visiting Africa in September.(完整表达更好)
- 原因:仅依据单词的局部概率进行选择,无法保证整个句子的概率最大化。

3. 为什么需要更高级的搜索算法?
- 可能的句子组合数量巨大:
- 假设目标句子长度为 10,词典大小为 10,000,则可能的句子组合数量为
,难以穷举所有组合。
- 假设目标句子长度为 10,词典大小为 10,000,则可能的句子组合数量为
- 目标:
- 寻找一个接近全局最优解的句子,使得 P(y|x) 最大化。
- 使用近似搜索算法(如集束搜索)来找到高质量的目标句子。
3.27 集束搜索(Beam Search)算法
1)目标:
集束搜索是一种在机器翻译和语音识别等任务中常用的搜索算法。它的目标是从输入序列(如法语句子)中生成条件概率最大的输出序列(如英语翻译),而不是随机生成句子或逐个单词贪心选择。
2)关键参数:
- 集束宽(Beam Width, B):表示算法同时保留多少个可能的部分句子。在贪心搜索中,集束宽为1;在集束搜索中,通常设置为大于1的值,比如3或10。
3)算法步骤:
- 初始化:输入句子通过编码网络,解码器的第一个单词从词汇表中选出概率最高的B个候选词。
- 递归生成:
- 针对每个部分句子,解码器继续生成下一个单词的概率分布。
- 计算部分句子的总概率(当前总概率 × 下一个单词的条件概率)。
- 从所有候选中选出概率最高的B个部分句子并保存。
- 终止条件:遇到句尾符号,或达到最大句长。
4)效率优化:
- 每步只需评估集束宽(B)个部分句子,计算出其扩展的可能性,极大减少计算量。
- 通过共享神经网络的权重,不需要为每个候选句子初始化独立的模型。
5)优点:
- 同时评估多个候选,避免贪心搜索可能产生的局部最优问题。
- 更高的灵活性,能够捕获全句更优的结构。
6)局限性:
- 算法的结果依赖于集束宽的大小,较小的集束宽可能漏掉优质句子,而过大的集束宽会增加计算开销。
- 不保证找到绝对最优解,仅是近似最优解。
7)具体例子:
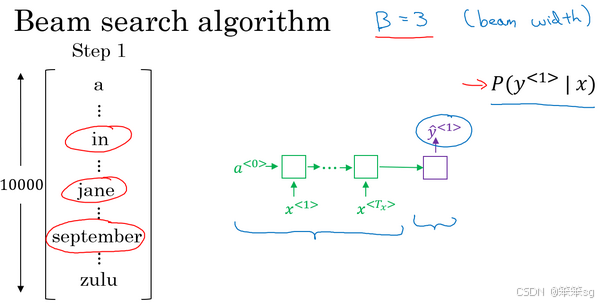
Stage1:在这个例子中我把这个集束宽设成3,这样就意味着集束搜索不会只考虑一个可能结果,而是一次会考虑3个,比如对第一个单词有不同选择的可能性,最后找到in、jane、september,是英语输出的第一个单词的最可能的三个选项,然后集束搜索算法会把结果存到计算机内存里以便后面尝试用这三个词。如果集束宽设的不一样,如果集束宽这个参数是10的话,那么我们跟踪的不仅仅3个,而是10个第一个单词的最可能的选择。所以要明白,为了执行集束搜索的第一步,你需要输入法语句子到编码网络,然后会解码这个网络,这个softmax层(上图编号3所示)会输出10,000个概率值,得到这10,000个输出的概率值,取前三个存起来。
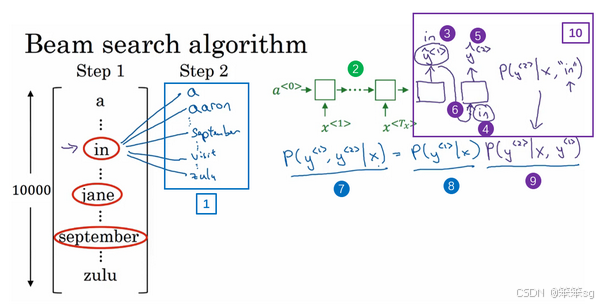
Stage2:让我们看看集束搜索算法的第二步,已经选出了in、jane、september作为第一个单词三个最可能的选择,集束算法接下来会针对每个第一个单词考虑第二个单词是什么,单词in后面的第二个单词可能是a或者是aaron,我就是从词汇表里把这些词列了出来,或者是列表里某个位置,september,可能是列表里的 visit,一直到字母z,最后一个单词是zulu(上图编号1所示)。
为了评估第二个词的概率值,我们用这个神经网络的部分,绿色是编码部分(上图编号2所示),而对于解码部分,当决定单词in后面是什么,别忘了解码器的第一个输出,我把
设为单词in(上图编号3所示),然后把它喂回来,这里就是单词in(上图编号4所示),因为它的目的是努力找出第一个单词是in的情况下,第二个单词是什么。这个输出就是
(上图编号5所示),有了这个连接(上图编号6所示),就是这里的第一个单词in(上图编号4所示)作为输入,这样这个网络就可以用来评估第二个单词的概率了,在给定法语句子和翻译结果的第一个单词in的情况下。
注意,在第二步里我们更关心的是要找到最可能的第一个和第二个单词对,所以不仅仅是第二个单词有最大的概率,而是第一个、第二个单词对有最大的概率(上图编号7所示)。按照条件概率的准则,这个可以表示成第一个单词的概率(上图编号8所示)乘以第二个单词的概率(上图编号9所示),这个可以从这个网络部分里得到(上图编号10所示),对于已经选择的in、jane、september这三个单词,你可以先保存这个概率值(上图编号8所示),然后再乘以第二个概率值(上图编号9所示)就得到了第一个和第二个单词对的概率(上图编号7所示)。
现在你已经知道在第一个单词是in的情况下如何评估第二个单词的概率,现在第一个单词是jane,道理一样,句子可能是"jane a"、"jane aaron",等等到"jane is"、"jane visits"等等(上图编号1所示)。你会用这个新的网络部分(上图编号2所示),我在这里画一条线,代表从,即jane,
连接jane(上图编号3所示),那么这个网络部分就可以告诉你给定输入和第一个词是jane下,第二个单词的概率了(上图编号4所示),和上面一样,你可以乘以
得到
。
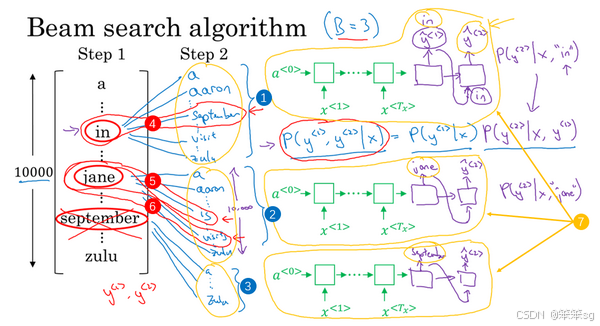
针对第二个单词所有10,000个不同的选择,最后对于单词september也一样,从单词a到单词zulu,用这个网络部分,我把它画在这里。来看看如果第一个单词是september,第二个单词最可能是什么。所以对于集束搜索的第二步,由于我们一直用的集束宽为3,并且词汇表里有10,000个单词,那么最终我们会有3乘以10,000也就是30,000个可能的结果,因为这里(上图编号1所示)是10,000,这里(上图编号2所示)是10,000,这里(上图编号3所示)是10,000,就是集束宽乘以词汇表大小,你要做的就是评估这30,000个选择。按照第一个词和第二个词的概率,然后选出前三个,这样又减少了这30,000个可能性,又变成了3个,减少到集束宽的大小。假如这30,000个选择里最可能的是“in September”(上图编号4所示)和“jane is”(上图编号5所示),以及“jane visits”(上图编号6所示),画的有点乱,但这就是这30,000个选择里最可能的三个结果,集束搜索算法会保存这些结果,然后用于下一次集束搜索。
注意一件事情,如果集束搜索找到了第一个和第二个单词对最可能的三个选择是“in September”或者“jane is”或者“jane visits”,这就意味着我们去掉了september作为英语翻译结果的第一个单词的选择,所以我们的第一个单词现在减少到了两个可能结果,但是我们的集束宽是3,所以还是有,
对的三个选择。
在我们进入集束搜索的第三步之前,我还想提醒一下因为我们的集束宽等于3,每一步我们都复制3个,同样的这种网络来评估部分句子和最后的结果,由于集束宽等于3,我们有三个网络副本(上图编号7所示),每个网络的第一个单词不同,而这三个网络可以高效地评估第二个单词所有的30,000个选择。所以不需要初始化30,000个网络副本,只需要使用3个网络的副本就可以快速的评估softmax的输出,即的10,000个结果。
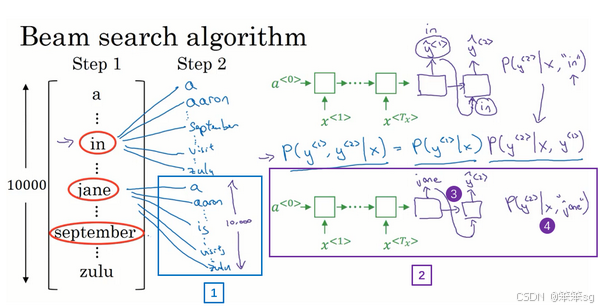
Stage3:让我们快速解释一下集束搜索的下一步,前面说过前两个单词最可能的选择是“in September”和“jane is”以及“jane visits”,对于每一对单词我们应该保存起来,给定输入x,即法语句子x作为的情况下,和
的概率值和前面一样,现在我们考虑第三个单词是什么,可以是“in September a”,可以是“in September aaron”,一直到“in September zulu”。为了评估第三个单词可能的选择,我们用这个网络部分,第一单词是in(上图编号1所示),第二个单词是september(上图编号2所示),所以这个网络部分可以用来评估第三个单词的概率,在给定输入的法语句子x和给定的英语输出的前两个单词“in September”情况下(上图编号3所示)。对于第二个片段来说也一样,就像这样一样(上图编号4所示),对于“jane visits”也一样,然后集束搜索还是会挑选出针对前三个词的三个最可能的选择,可能是“in september jane”(上图编号5所示),“Jane is visiting”也很有可能(上图编号6所示),也很可能是“Jane visits Africa”(上图编号7所示)。
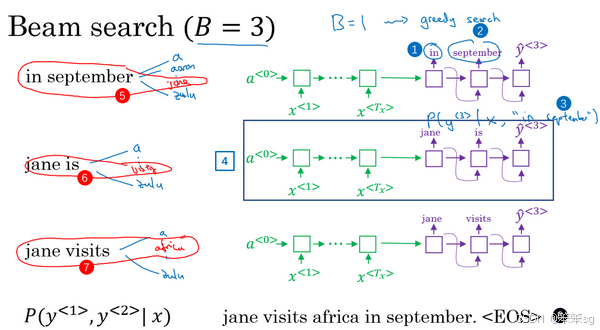
然后继续,接着进行集束搜索的第四步,再加一个单词继续,最终这个过程的输出一次增加一个单词,集束搜索最终会找到“Jane visits africa in september”这个句子,终止在句尾符号(上图编号8所示),用这种符号的系统非常常见,它们会发现这是最有可能输出的一个英语句子。
8)贪心搜索与集束搜索的对比:
- 贪心搜索:逐词选择概率最高的单词,可能导致不连贯的句子结构。
- 集束搜索:同时保留多个部分句子,能够避免局部选择造成的整体效果欠佳问题。
3.28 改进集束搜索(Refinements to Beam Search)
1)数值稳定性问题
前面讲到束搜索就是最大化这个概率,这个乘积就是,可以表示成:
这些概率通常小于1,因此其乘积会变得非常小,可能会导致数值下溢(numerical underflow),即计算结果变得过小,以至于无法精确表示。这是因为浮点数在计算机中的表示精度有限。
为了解决这一问题,我们通常不直接计算概率的乘积,而是计算概率的对数和。由于对数函数是单调递增的,最大化概率的乘积和最大化对数和会得到相同的结果。这样,算法变得更加稳定,减少了数值下溢和舍入误差的问题。
2)目标函数的改进——归一化的对数似然目标函数
在机器翻译等任务中,长句子的概率往往较低,因为它们包含更多的单词,每个单词的概率都是小于1的。当我们计算一个句子的整体概率时,这些小于1的概率乘积会迅速变得非常小。由于这种现象,基本的束搜索倾向于生成较短的翻译,因为短句子的概率计算结果较大。
为了改善这一点,可以对目标函数进行长度归一化。具体来说,可以将目标函数除以翻译结果的单词数,这样就计算了每个单词对数概率的平均值。这样做会减少对较长句子的惩罚,从而避免生成过于简短的翻译。
3)探索性方法
如下图编号1所示:在实际应用中,我们可能会使用一个柔和的方法来进行长度归一化,即通过将句子长度的指数作为调整因子(例如,指数设为0.7)。如果指数为1,这相当于完全按长度进行归一化;如果为0,归一化效果就会消失,恢复到原来的算法。这个指数是一个超参数,可以调整以优化性能。虽然这种方法没有严格的理论支持,但实践中通常能取得较好的效果。

4)如何运行改进后的束搜索算法
当运行束搜索时,我们会记录多种不同长度的句子,并对它们进行评分。通过选择得分最高的句子,我们得到最终的输出结果。具体来说,束搜索会在每一步考虑多个可能的候选句子,并基于归一化的对数概率目标函数选择最佳的句子。
5)如何选择束宽B
束宽(B)决定了每一步搜索时考虑的候选句子的数量。较大的束宽会考虑更多的可能性,可能会找到更好的句子,但也会增加计算成本和内存占用。较小的束宽会减少计算开销,但可能错过一些较好的选择。
- 束宽较大:考虑更多可能性,计算开销较大,但可能会得到更好的结果。
- 束宽较小:计算更快,内存占用小,但结果可能不如束宽大的情况好。
在实际应用中,通常会将束宽设置为10左右。在一些研究中,为了压榨性能,束宽可以设置为1000甚至更大。然而,束宽越大,性能的提升就越有限,尤其是在一定范围内,增加束宽的效果会变得不明显。
值得注意的是,不同于BFS和DFS得到的都是精确解,束搜索得到的不一定是精确解,大多数情况下都是近似最优解。
3.29 集束搜索的误差分析
集束搜索(Beam Search)是一种近似的启发式搜索算法,用于序列生成任务,如机器翻译。它通过维持一组候选解并在每一步选择最有可能的候选来生成翻译结果。然而,集束搜索并不总能找到最优的翻译,因为它仅记录前B个最可能的候选,而不是所有可能的情况,因此可能导致选择错误的句子。
在误差分析过程中,我们需要区分集束搜索和RNN模型的潜在错误来源。以下是分析过程的主要步骤和思路:
1)分析错误来源:
- RNN模型的错误:如果RNN模型输出的翻译概率较低,而集束搜索选择了该翻译,可能是模型本身的问题(如预测结果不准确)。
- 集束搜索的错误:如果集束搜索选择了一个较低概率的翻译(即候选翻译的对数概率较低),而正确的翻译的概率应该更高,则是集束搜索在选择时犯了错误。
2)误差分析过程:
- 在开发集中遍历每个翻译错误,比较集束搜索的输出和人工翻译的输出的概率。
- 如果集束搜索选择的翻译的概率低于正确翻译,则可以归结为集束搜索出错;如果模型赋予正确翻译较低的概率,则可能是RNN模型的问题。
- 通过这种分析,可以找出造成错误的主要原因(看比例),从而决定是否调整集束宽度(B)或对RNN模型进行优化。
3)具体例子:
我们来用这个例子说明: “Jane visite l'Afrique en septembre”。假如说,在你的机器翻译的dev集中,也就是开发集(development set),人工是这样翻译的: Jane visits Africa in September,我会将这个标记为。这是一个十分不错的人工翻译结果,不过假如说,当你在已经完成学习的RNN模型,也就是已完成学习的翻译模型中运行束搜索算法时,它输出了这个翻译结果:Jane visited Africa last September,我们将它标记为
。这是一个十分糟糕的翻译,它实际上改变了句子的原意,因此这不是个好翻译。
如果你能够找出造成这个错误,这个不太好的翻译的原因,是两个部分中的哪一个,不是很好吗? RNN (循环神经网络)是更可能是出错的原因呢,还是束搜索算法更可能是出错的原因呢?
下面进行详细的分析:

4)改进措施:
- 如果发现集束搜索出错较多,则可以尝试增大束宽来获得更多候选翻译,改善结果。
- 如果RNN模型出错较多,则可以考虑增加正则化、扩充训练数据或调整网络结构来提高模型的性能。
3.30 Bleu 得分
BLEU(Bilingual Evaluation Understudy)得分是一种用于自动评估机器翻译质量的指标。它的核心思想是通过比较机器翻译输出与人工翻译的参考之间的相似度来评估翻译的质量。BLEU得分的基本过程包括以下几个关键步骤:
-
精确度(Precision):首先,计算机器翻译中每个单词、二元词组(bigram)、三元词组(trigram)等n-gram与参考翻译中的n-gram的匹配情况。每个匹配的n-gram被赋予一个分数,但为了避免过多的重复,采用了“截取计数”策略,即每个n-gram的得分上限为它在参考翻译中出现的最大次数。
-
改良后的精确度(Modified Precision):在普通的精确度计算中,机器翻译可能重复出现某些词汇,这可能导致误导性较高的评分。改良后的精确度通过限制每个n-gram的计数为它在参考翻译中出现的最大次数,从而更公平地衡量翻译质量。
-
简短惩罚(Brevity Penalty, BP):为了避免机器翻译生成的翻译过于简短而导致高精确度,BLEU得分引入了简短惩罚。当机器翻译输出的句子比参考翻译短时,BLEU得分会相应减少,以此惩罚短翻译,鼓励更完整的输出。
-
BLEU得分的计算:最终的BLEU得分是通过将多个n-gram(如一元词组、二元词组、三元词组等)的精确度进行加权平均,并结合简短惩罚因素计算得出的。BLEU得分越接近1,表示机器翻译与参考翻译越相似。
计算公式:
BLEU得分考虑多个n-gram(单词序列),包括一元词组(unigrams)、二元词组(bigrams)、三元词组(trigrams)等。具体计算步骤如下:
Step1:n-gram精确度
-
n-gram的精确度: 对于每个n-gram(可以是1-gram,2-gram,3-gram,…),计算机器翻译输出中出现的n-gram与参考翻译中出现的n-gram的匹配情况。
对于每个n-gram,计算其修改后的精确度(modified precision),即:
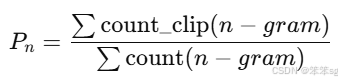
- 其中,count_clip(n−gram)是该n-gram在参考翻译中出现的最大次数(截断计数),count(n−gram)是该n-gram在机器翻译输出中出现的次数。
Step2:简短惩罚
简短惩罚用于惩罚机器翻译输出过短的情况,避免机器输出过短的翻译得分过高。
简短惩罚的公式如下:
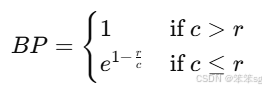
其中:
- c是机器翻译输出的长度(即翻译后的词数)。
- r是参考翻译的长度(通常是参考翻译的平均长度)。
- 当机器翻译的长度大于参考翻译时,BP=1;当机器翻译的长度小于或等于参考翻译时,BP会小于1,表示惩罚。
Step3:最终的BLEU得分
将n-gram的加权平均精确度与简短惩罚结合,最终的BLEU得分计算公式为:
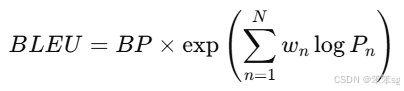
其中:
- N是使用的n-gram的最大值(通常是1到4)。
- Pn是第n个n-gram的精确度。
是n-gram的权重,通常设置为均等(例如,w1=w2=w3=w4=0.25)。
BLEU得分的主要应用是评估机器翻译系统的输出,尤其适用于多种有效翻译可能的情况。它也广泛用于图像描述、文本生成等任务,但不适用于语音识别,因为语音识别通常有一个唯一的正确答案。通过自动化的BLEU得分计算,可以加速机器翻译和其他生成文本系统的开发和优化。
3.31 注意力模型直观理解总结
1)背景(为什么需要注意力机制):
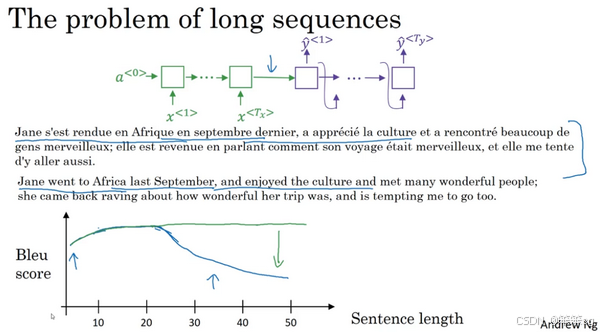
传统的 编码-解码架构 在处理长句子时存在问题,因为编码器需要记忆整句信息,而长句子的记忆往往会导致翻译性能下降。这种方法对于短句效果尚可,但随着句子长度增加,BLEU分数显著下降。
而我们在翻译时,当前单词的翻译结果应该和它临近的单词关系较大,所以应该有侧重点,不然和它不相关的单词可能会对它的翻译造成不利影响。和LSTM的忘记门和更新门功能类似,我们翻译时可能会需要“忘记”一些离当前单词很远的信息,从而突出临近的信息。而这种功能是传统的encoder-decoder网络结构无法学习的,即使它用了很多层。有相关实验发现,把源句子倒置后再输入encoder-decoder网络,取得了更好的效果,原因就是因为有些语言源句子中的字与翻译出的字的位置相差很大。比如:
![]()
其中area应翻译成zone。
2)核心思想:
注意力机制(Attention Mechanism)通过模拟人类翻译过程,允许模型在每一步生成目标语言词汇时专注于源语言句子的相关部分,而不是试图记住整个句子。
3)注意力模型的工作流程:
-
双向RNN编码器:对输入句子中的每个单词,计算它的特征集。这些特征不仅包含该单词本身的信息,还结合了上下文的含义。
-
解码器的生成过程:
- 解码器每一步生成目标语言的一个词(如 "Jane")。
- 生成某个词时,解码器通过注意力机制计算一组 注意力权重:
- 这些权重指示当前生成的目标词与源语言句子中每个词的相关性。
- 例如,生成 “Jane” 时,模型可能关注法语句子的第一个词及其附近的词。
-
上下文向量(Context Vector):
- 每次生成一个目标词时,通过加权源语言句子的特征表示,形成一个上下文向量
。
- 上下文向量结合解码器的隐藏状态,共同决定目标词的生成。
- 每次生成一个目标词时,通过加权源语言句子的特征表示,形成一个上下文向量
-
逐步翻译:
- 解码器在每个时间步都会更新隐藏状态,并生成新的注意力权重,用于下一词的翻译。
- 生成一个目标词后,该词也会作为输入,帮助生成下一目标词,直到完成翻译。
4)注意力机制的优势:
- 动态关注:模型根据上下文动态调整对输入句子的关注区域,避免了长句子记忆问题。
- BLEU分数提升:对于长句子的翻译表现显著提高,BLEU分数曲线变得更加平稳。
- 可解释性:注意力权重提供了模型在生成每个目标词时所关注的源语言单词,便于理解翻译过程。
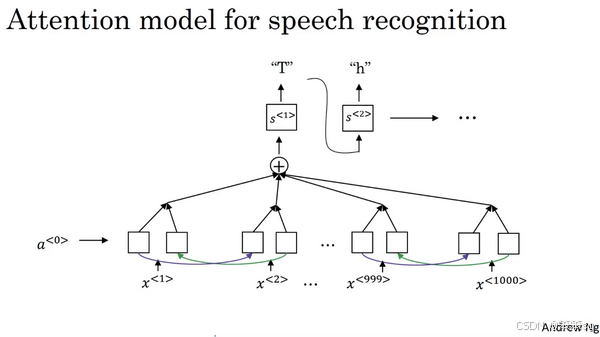
3.32 注意力模型(Attention Model) 详解
注意力模型源于Dimitri, Bahdanau, Camcrun Cho, Yoshe Bengio(2014)
Neural Machine Translation by Jointly Learning to Align and Translate
虽然这个模型源于机器翻译,但它也推广到了其他应用领域。我认为在深度学习领域,这个是个非常有影响力的,非常具有开创性的论文。
这篇论文中的attention框图为:
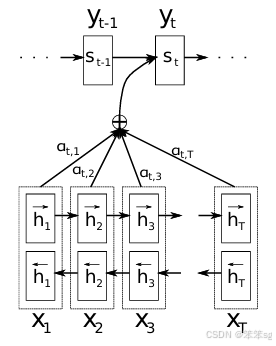
从上图可知,Decoder中每一时刻的输出是由好几个变量共同决定的,其中包含了Encoder中每一时刻的隐藏状态向量,和上一时刻的输出
,以及当前时刻Decoder中的隐藏状态向量
,于是就有如下公式:
如何得到:
![]()
那么,这个和传统的 RNN Encoder-Decoder 有何区别呢?
区别其实就在于,在这里,我们不再使用固定的语义编码向量,而是使用一个动态的语义编码向量 ,它是由Encoder中每一时刻的隐藏状态向量计算得到的。
现在我们知道了是如何得到的,那么我们还有一些疑问,
和
是如何得到的呢?
如何得到:
![]()
如何得到:
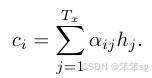
其中,代表Encoder中每一时刻的隐藏状态向量,那么,
代表什么呢?这也就是我们今天要说的Attention的作用。
如何得到:
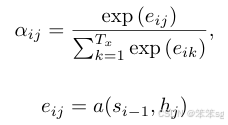
至此,我们便晓得了注意力模型的整个流程。
为了便于大家理解,可惜看一下下面的网络架构图,非常直观:
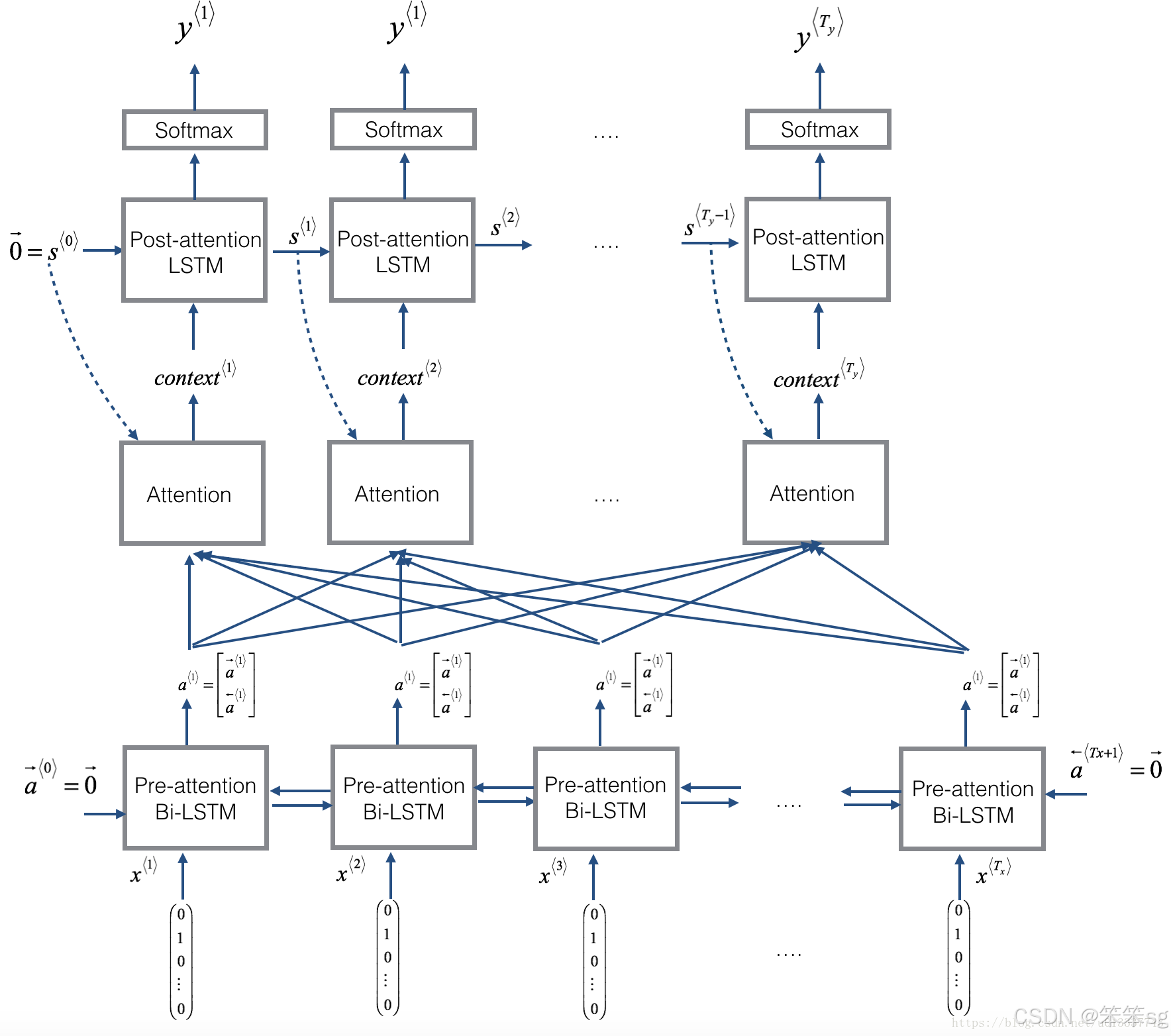
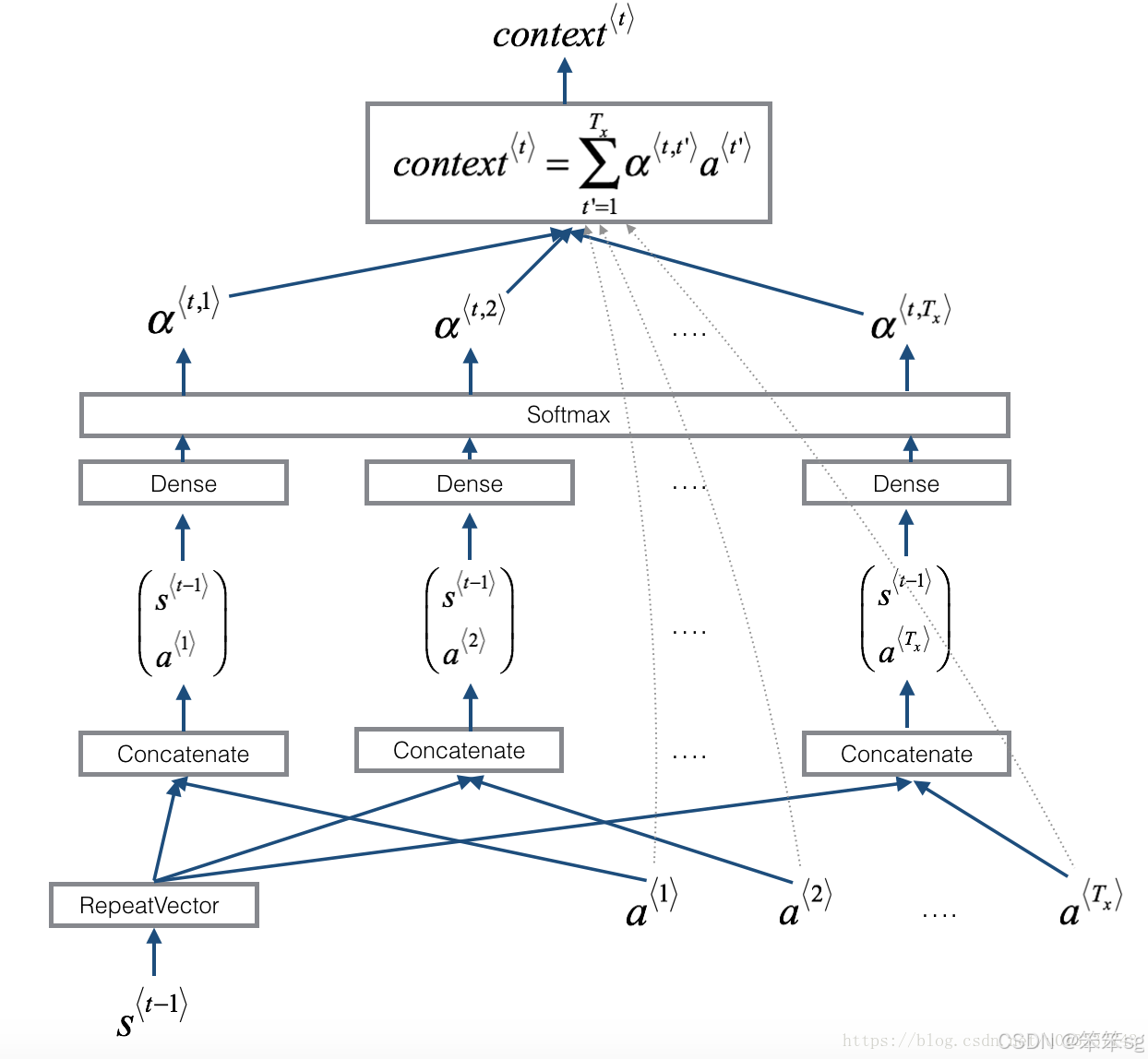
实验结果(注意力模型真的表现得较为优越么?)
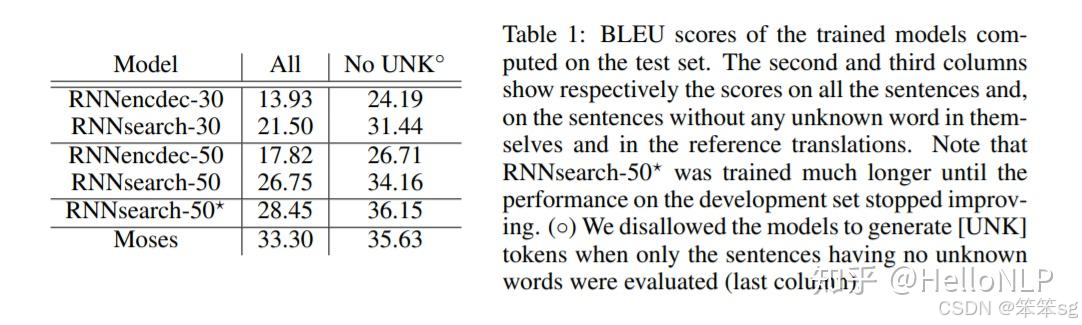
从上表得知,RNNsearch均比RNNencdec的效果要好。其中,RNNsearch是加入了Bahdanau Attention的RNN Encoder-Decoder,RNNencdec是未加入的。
可视化的注意力权重:
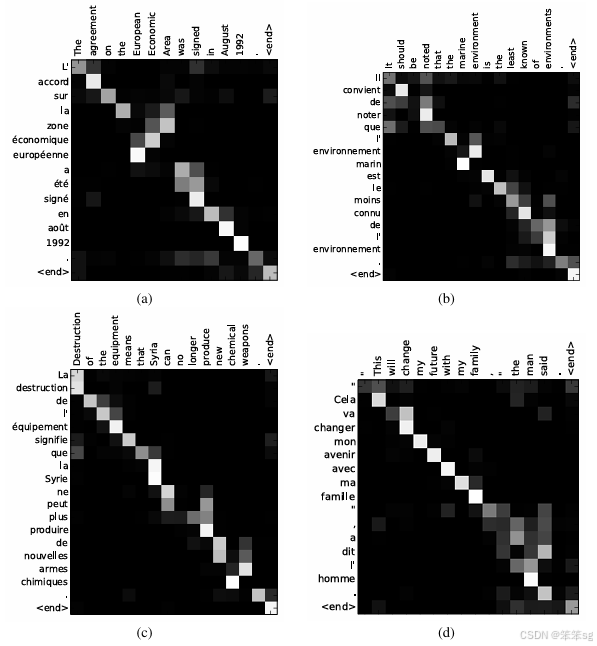
上面的4个图都是在RNNsearch-50上的结果。x轴和y轴分别是输入的英语和输出的法语,以及每一个输出的法语单词在所有输入英文单词上的注意力数值。
例如,在(a)图中,法语单词 "accord" 的注意力基本上都集中在输入英文单词 "agreement" 上;法语单词 "été" 的注意力大部分集中在输入英文单词 "was" 和 "signed" 上。
3.33 语音识别模型的发展
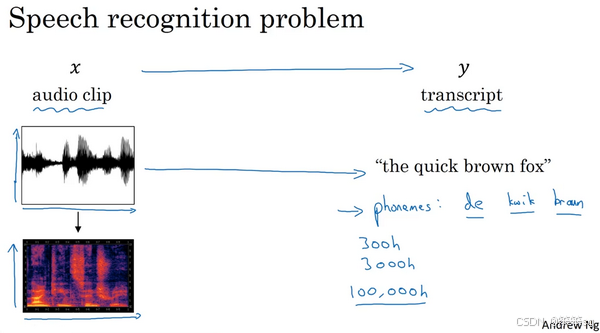
1. 语音识别的目标
- 输入:音频片段(原始波形或声谱图)。
- 输出:文本描述(如“the quick brown fox”)。
2. 音频数据的预处理
- 将音频波形转换为声谱图,提取时间-频率上的声波能量信息,类似于人耳感知声音的方式。
- 这是一种常见的预处理步骤,优化模型对音频的处理效果。
3. 传统方法 vs. End-to-End方法
- 传统方法:
- 使用音位(phonemes)作为声音的基本单元,将音频分解成音位表示。
- 需要人工设计和领域知识(语音学家定义的音位规则)。
- End-to-End方法:
- 无需人工设计的中间表示(如音位)。
- 使用深度学习模型直接将音频映射到文本。
- 优势:在大规模数据集(数千小时甚至数万小时)支持下,模型表现显著提升。
4. 主要语音识别模型
- 注意力模型(Attention-based Models):
- 利用注意力机制对输入音频的每个时间帧分配权重,生成文本输出。
- 模型根据输入和输出之间的对齐关系,自动关注相关部分。
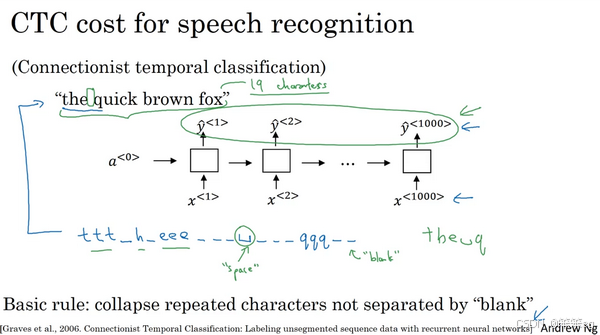
- CTC损失模型(Connectionist Temporal Classification, CTC):
- 适用于输入时间步多于输出时间步的情况。
- 核心思想:
- 允许神经网络输出重复字符和空白符(blank characters)。
- 通过折叠重复字符和移除空白符,将长序列映射为目标文本。
- 例如,输出“t_h_ee_”会折叠为“the”。
- 优势:能强制神经网络输出与输入长度一致的序列,同时最终输出长度短得多。
3.33 触发字检测(Trigger Word Detection)
1. 触发字检测的概念

- 触发字检测系统通过语音唤醒设备,例如:
- Amazon Echo:唤醒词“Alexa”。
- 百度 DuerOS:唤醒词“小度你好”。
- Apple Siri:唤醒词“Hey Siri”。
- Google Home:唤醒词“Okay Google”。
- 该系统能够监听语音输入,检测到特定触发词后启动设备或执行特定任务。
2. 触发字检测的实现步骤
- 输入预处理:
- 从音频片段提取声谱图特征(spectrogram features)。
- 转化为特征向量序列。
- 模型架构:
- 使用 RNN(如 LSTM 或 GRU)处理特征序列,预测每个时间步是否包含触发字。
- 目标标签设计:
- 输入音频片段时:
- 在触发字被检测到之前,目标标签为 0。
- 在触发字被检测到的时间点及之后,目标标签设为 1。
- 如果触发字再次出现,则重复上述过程。
- 输入音频片段时:
3. 不平衡训练数据的问题
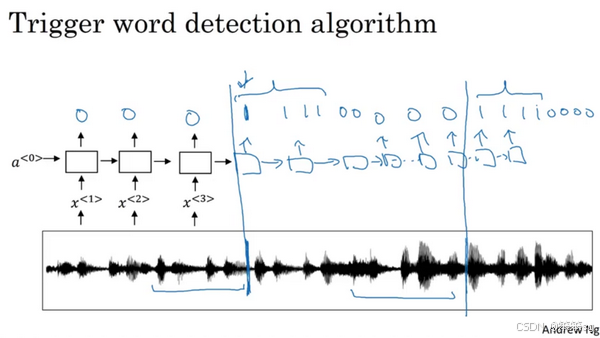
- 标签 0 的数量显著多于标签 1,导致训练数据严重不平衡。
- 改进方法:
- 在触发字结束后,目标标签保持 1 一段固定时间。
- 提高标签 1 的比例,从而缓解数据不平衡问题。
3.34 《深度学习专项》新增的课程——Transformer
这节课是《深度学习专项》新增的课程,内容比较简短。估计是因为Transformer太火了,不得不在教材里加上这些新内容。这节课讲得并不是很清楚,建议参见下面2篇文章,这个博主会用更易懂的逻辑把这节课讲一遍。(讲的真的非常清楚)
吴恩达《深度学习专项》笔记(十七):Transformer - 知乎
Attention Is All You Need (Transformer) 论文精读 - 知乎
同时可以参见该笔记的4.6~4.10章节,我对本人在阅读上述2篇文章中提出的一些疑问进行了回答,希望能对大家有所帮助。
3.35 完结撒花

4 补充知识点
4.1 GRU(门控循环单元)之所以能够选择性地更新或保持记忆的原因是什么?
GRU(门控循环单元)之所以能够选择性地更新或保持记忆,并且根据输入序列的前部分(比如“cat”或者“cats”)来决定后续输出(比如“was”或“were”),是通过其内部的门控机制来实现的。GRU具有两大重要的门:重置门(reset gate)和更新门(update gate),它们控制着信息如何流动、如何保留或者如何更新。
让我们一步步通俗地解释:
1. 记忆细胞的作用
在GRU中,记忆细胞(也可以理解为“隐藏状态”)存储了网络在时间步中学到的知识。它有能力保存历史信息,直到某个时间步决定是否更新。
例如,在处理句子时,前面的“cat”会存储在记忆细胞中。记忆细胞中存储的信息有助于理解句子的主语是单数(即“cat”)还是复数(即“cats”),从而影响后面的动词形式(例如,“was”或“were”)。
2. 重置门:决定忘记多少信息
重置门(reset gate)的作用是控制“遗忘”的程度。当处理一个新的输入时,重置门决定了当前时间步的候选记忆值应该保留多少历史信息。例如,在句子中,如果某个词对当前输出不重要,重置门会“重置”一部分记忆细胞,抑制不重要的信息。
在你的例子中,重置门的作用可能并不那么显著,因为“cat”和“cats”这类信息是需要长期记忆的,而重置门的作用更多是在不重要的时刻帮助“忘记”不相关的部分。
3. 更新门:决定何时更新记忆
更新门(update gate)是GRU的核心机制,它决定了什么时候更新记忆细胞的信息,什么时候保持现有的记忆不变。它在0到1之间变化:
- 当更新门接近1时,表示记忆细胞应该更新,当前的输入(比如“cat”或“cats”)将对记忆细胞产生较大的影响。
- 当更新门接近0时,表示记忆细胞保持不变,意味着之前的信息会继续保持,直到网络认为有必要更新。
4. 如何根据“cat”或“cats”选择性地更新记忆
回到你的例子,“cat”和“cats”影响的是动词的形式(“was”还是“were”)。GRU的工作原理是:
- 当网络看到“cat”时,更新门会决定将记忆细胞的值保持为一个表示单数的状态(记住“cat”是单数)。
- 当网络看到“cats”时,更新门可能会更新记忆细胞,表示它识别出“cats”是复数,因此记忆细胞中储存的是复数的知识。
在这个过程中,更新门的输出会根据当前的输入(比如“cat”或“cats”)决定是否更新记忆。如果当前的输入对输出(如动词的形式)至关重要,更新门会允许记忆细胞更新,保存与当前输入相关的必要信息。
5. 输出决定:基于记忆产生最终输出
在每个时间步,GRU都会根据当前时间步的记忆细胞(它已经被更新或保持)生成当前的输出。最终的输出(比如“was”或“were”)不仅依赖于当前时间步的输入,还依赖于记忆细胞中储存的信息。
- 如果记忆细胞已经被更新为与单数“cat”相关的状态,网络最终会输出“was”。
- 如果记忆细胞已经被更新为与复数“cats”相关的状态,网络会输出“were”。
4.2 GRU如何做到的选择性地更新记忆细胞?也即如何识别哪些词更具备更新价值?
具体来讲,为啥碰到cat的时候就更新记忆细胞的值,碰到别的就不更新,那我如何得知哪部分信息是重要的,要更新?哪部分不重要,不需要更新呢?
其实,在训练过程中,GRU通过不断调整门控参数(包括更新门)来学习如何选择性地更新记忆。它并不是一开始就知道“cat”这个词在句子中的作用,而是通过反向传播和误差最小化的过程逐渐学到哪些信息是重要的,哪些不重要。
-
目标输出与预测输出之间的误差:比如在一个句子中,输入“cat”时,GRU预测的是“was”,如果预测错误(比如预测了“were”),模型就会计算出误差。这个误差通过反向传播影响网络中的权重,尤其是影响更新门的权重。
-
动态学习:随着训练的进行,GRU会学习到,当遇到“cat”时,更新门需要接近1,以便记住“cat”的单数信息;而遇到其他不重要的词时,更新门可以接近0,这样保持当前记忆不变。
4.3 双向RNN为何要等到整个序列全部输入后才能运作?
双向 RNN 包括两个独立的 RNN:
- 前向 RNN 从序列的起始开始,依次处理到序列末尾。
- 后向 RNN 从序列的末尾开始,依次处理到序列起始。
两者的隐藏状态在每一个时间步通过拼接或加权组合(例如拼接为 )形成完整的上下文向量。这种设计需要同时掌握序列的过去信息和未来信息,因此需要等待整个序列输入完成后,后向 RNN 才能正确地从序列末尾开始计算。
4.4 “BLEU” 名字的由来
“BLEU”得分的名字是“Bilingual Evaluation Understudy”的缩写。这个名字的由来和它的功能紧密相关,下面是详细的解释:
-
Bilingual(双语的):BLEU得分最初是为评估机器翻译(machine translation, MT)系统而设计的,而机器翻译涉及的正是从一种语言(如法语)翻译到另一种语言(如英语)。因此,“Bilingual”指的是两种语言之间的转换。
-
Evaluation(评估):BLEU的核心功能就是评估机器翻译的质量。通过计算机器翻译输出与参考翻译之间的相似度,BLEU提供了一个评估指标。
-
Understudy(候补演员):这个部分是比较特别的。候补演员(Understudy)在戏剧中是指那些学习并准备替代主角的演员,通常是为了在主角缺席时能够迅速替换其角色。在BLEU的背景下,这个词用来比喻BLEU得分作为“候补”评估工具,它替代了人类评估员对机器翻译的人工评估。通过自动化的计算,BLEU能够在没有人工评估的情况下,对机器翻译的结果进行快速评分。
总结来说,BLEU得分的名字反映了它的核心功能:作为一种自动化的评估工具,用来替代人工评估,衡量机器翻译的质量,特别是在双语翻译的情境下。
4.5 注意力模型中用于得到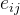 的a函数是如何确定的?
的a函数是如何确定的?
首先要明确和哪些信息有关:
1. 输入信息
- 上一时间步的隐藏状态
:
- 表示解码器在生成当前目标词之前的状态。
- 它包含了目标句子生成到当前时的上下文信息。
- 输入特征
:
- 表示输入句子在时间步 t′ 的特征(由双向 RNN 或其他模型生成)。
- 包括输入句子的内容信息。
这两个量直观上与当前时间步对输入的关注点直接相关。
2. a函数如何确定?

4.6 CNN可以并行么?为什么?
我们在学习CNN原理的时候,卷积核是在图像上不停滑动进行计算的,因此我们就会有一种错觉,CNN的卷积等操作是串行进行的,其实不然。在每个卷积核的滑动过程中,计算可以独立完成,因为卷积核只依赖于其当前的感受野(局部区域)。这种局部独立性使得不同的输出位置的计算是完全独立的,因此可以并行进行。
其实,在学习序列模型前,我们使用的绝大多数神经网络(如全连接网络)都是可以并行进行的。
在CNN中并行化的具体场景主要有:
以下是 CNN 中并行化的主要环节:
a. 卷积层的并行性
- 不同位置的卷积:
- 卷积操作计算的是一个输入特征图和卷积核之间的点积(通过滑动窗口),每个位置的计算是独立的。
- 在硬件(如 GPU)上,可以并行计算不同位置的卷积值。
- 多个卷积核的并行性:
- 如果有多个卷积核(输出通道数 > 1),每个卷积核的计算也是独立的。
- GPU 上可以同时为多个卷积核分配线程,从而实现并行化。
b. 池化层的并行性
- 池化操作(如最大池化或平均池化)也是对局部区域的独立计算,可以并行进行。
- 每个池化区域的计算互不依赖,易于在 GPU 上并行化。
c. 批处理(Batch)的并行性
- CNN 通常对一个 mini-batch 的数据进行训练。
- 每张图片的前向传播和反向传播可以独立计算,因此批次中的数据可以并行处理。
d. 全连接层的并行性
- 全连接层中的每个神经元的输出是输入向量的加权求和,计算是相互独立的,也可以并行化。
注意:CNN 的层与层之间存在依赖关系(每层需要上一层的输出作为输入),这部分是串行的,限制了跨层的并行化。
4.7 独热编码经过词嵌入生成的表示,和经过词嵌入又经过自注意力生成的表示有何不同?
- 词嵌入通过将每个词映射到一个密集的向量空间来捕捉一定的语义信息,但没有考虑到具体上下文中词之间的相互关系,也即同一个词在不同上下文中的表示是相同的;
- 通过自注意力,模型能够结合整个输入序列的信息,产生更加丰富、灵活的词表示,使得同一个词在不同上下文中的表示可以有所不同。
4.8 多头注意力表示多次利用自注意力机制,生成多个表示,就和CNN里N个卷积核能生成N个特征一样,你认同这种说法么?为什么?
认同。它们都通过并行处理多个独立的表示来捕捉不同的信息或特征。
在CNN中,每个卷积核(filter)关注输入数据的不同部分的不同特征。例如:第一个卷积核可能会专门学习图像中的垂直边缘;第二个卷积核可能会专门学习图像中的水平边缘;第三个卷积核可能会学习某种特定的纹理或形状。
而在多头注意力中,第一个头可能会在句子中关注主语和谓语之间的关系,而另一个头可能会关注动词和宾语之间的关系,第三个可能会关注同义词之间的相似性。
4.9 “自注意力,顾名思义,就是对句子自己使用注意力机制”。如何理解这句话?
自注意力机制(Self-Attention)是指,在处理一个输入序列(比如句子)时,每个词都会根据序列中其他词的位置和信息来重新调整自己的表示。简而言之,每个词在计算自己的表示时,都会“注意”到句子中其他词的内容,从而更好地理解上下文。
4.10 Transformer是在什么背景下提出的?之前的传统注意力模型不好使么?
传统注意力模型是基于RNN的,但所有基于RNN的模型都面临着同样一个问题:RNN本轮的输入状态取决于上一轮的输出状态,这使RNN的计算必须串行执行。因此,RNN的训练通常比较缓慢。
既然注意力机制能够无视序列的先后顺序,捕捉序列间的关系,为什么不只用这种机制来构造一个适用于并行计算的模型呢?在这一背景下,抛弃RNN,只使用注意力机制的Transformer横空出世了。这一架构规避了RNN的使用,完全使用注意力机制来捕捉输入输出序列之间的依赖关系。这种架构不仅训练得更快了,表现还更强了。
4.11 自注意力和之前的传统注意力有啥区别呢?
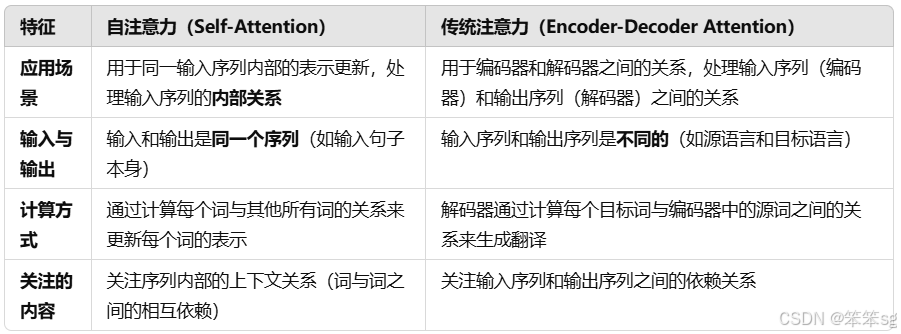
4.12 如何通俗理解公式中的Q、K、V?各自什么含义?
在3.34提到的两篇文章中,那个博主已经讲的很好了,吴恩达课中举得例子也很生动形象,这里再简单回顾一下,例子就不说了。
比如我们要把“简访问非洲”翻译成英文,其中第三个字“问”有很多意思,比如询问、慰问等。自注意力的目的就是为每个词生成一个新的表示A,反映它在句子中的意思。因此第三个字“问”的query 是:哪个字和“问”字组词了?当然,在这个句子里,我们人类可以很轻松地知道答案,“问”和“访”组成了“访问”这个词。每个字的key可以认为是字的固有属性,比如是名词还是动词。每个字的value就可以认为是这个字的词嵌入。
我们要做的就是凭借手中已有的q去获取和q最为相近的k指向的值v。
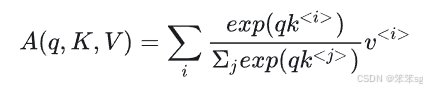
q:query;
k:key;
v:value。
但大多数情况下,我们都不能直观看到哪个k和q最为相近,怎么办呢?
计算k和q之间的匹配度来作为权重得到w(还要经过一个softmax),w乘上v得到一个临时值t,所有的临时值t加起来便得到了一个近似值r(这个r虽然不一定等于“和q最为相近的k对应的v”,但也大差不大了)
那么如何得知哪个k和q最为相近呢?答案是计算这两者之间的相似度(比如向量内积),注意力其实就是这个含义,就是相似度(权重)。
为了直观理解,可以看下面这幅图:
![]()
扩展到多个查询,上述公式就变化为如下公式:
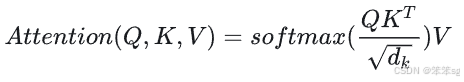
4.13 softmax的图像可以绘制出来么?
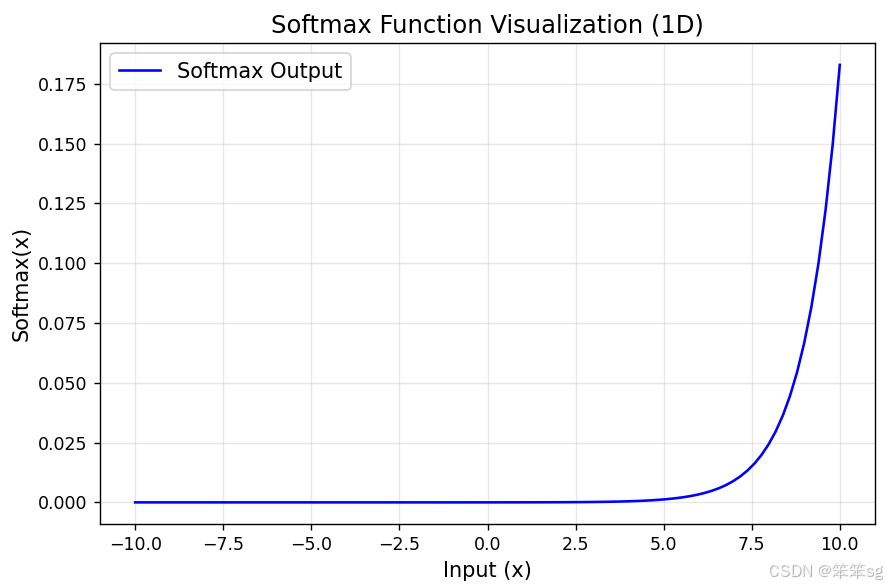
你可能会好奇,softmax涉及到多个自变量,图像是可以绘制出来的吗?
答案是不能直接画出,Softmax 本质上是一种归一化方法,通常用于将一个实数向量转换为一个概率分布,因此它本身并不直接用于绘制图像。
但是我们可以在给定输入、输出的情况下特定绘制出来。
例如,当x = np.linspace(-10, 10, 100)时,图像大致长下面这个样子:
当x = np.linspace(0, 1)时,图像大致长下面这个样子:

因此,我们不能直接绘制出softmax的图像,只能绘制出这种对应关系。
4.14 Q、K、V的计算公式中,分母为啥要有一个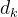 用于缩放呢?
用于缩放呢?
首先我们注意一下括号内计算完毕要进入softmax计算各自的加权权重(和为1),也即分母的设置和softmax有关,这是因为,softmax在绝对值较大的区域梯度较小,梯度下降的速度比较慢。
为什么这样子说呢?让我们来看一下它的梯度公式:


所以我们需要除以一个和相关的量能够防止点乘的值过大。
4.15 除了点乘来计算注意力,还有哪种办法?
点乘注意力是最常见的一种计算相似度的方法,尤其是在Transformer模型中。除了这个之外,还有加性注意力,加性注意力使用的是一种不同的方式来计算相似度。它通过将查询向量 Q 和键向量 K 通过一个小型的前馈神经网络(通常是一个单层网络)计算出它们的相似度。
它不是直接计算点乘,而是计算查询和键之间的非线性相似度。
为啥不用加性用点乘呢?这是因为加性较慢。
为什么加性注意力的计算较慢:
加性注意力需要通过一个前馈神经网络来计算相似度,这个网络的计算过程相对较为复杂,而且不像点乘那样能够通过并行化加速运算。因此,加性注意力通常比点乘注意力要慢,尤其是在处理大规模数据时,性能会受到影响。
4.16 每个单词的query, key, value是怎么得来的?
下面的红框这块是怎么来的呢?
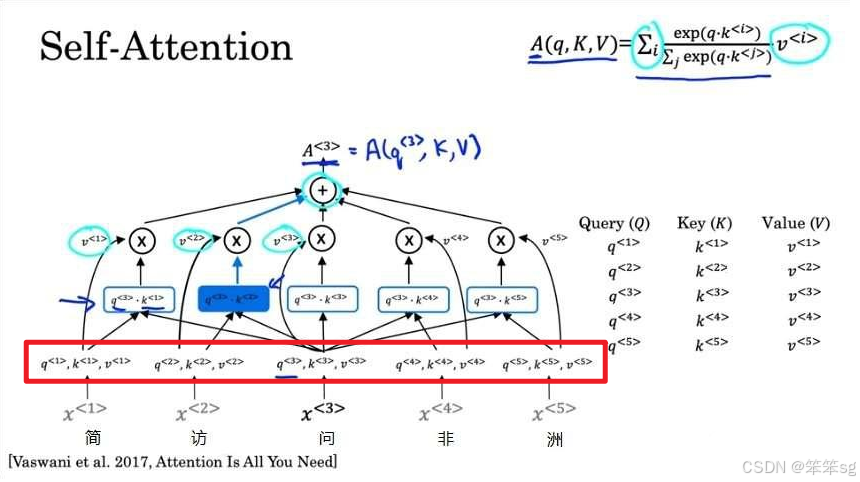
你可能会想,这应该和很多权重矩阵W一样,刚开始都是随机初始化的,后续就通过反向传播不断训练更新。
恭喜你,猜对了。
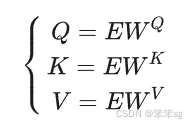
其中,E是词嵌入矩阵,也就是每个单词的词嵌入的数组;是可学习的参数矩阵。
其各自的形状如下:
E: ,其中n代表(词典长度),输入序列首先根据词典被编码为m个one-hot向量(m为序列长度,token总数),d_{model}代表词嵌入的维度。
:
:
4.17 多头注意力机制。
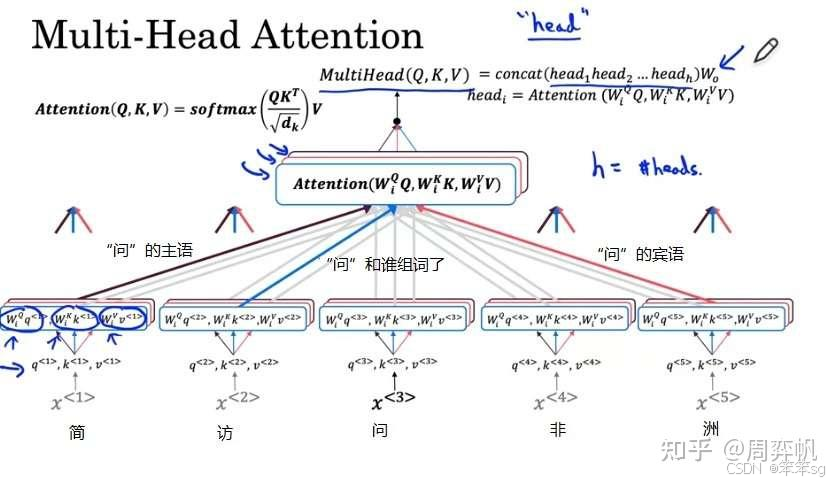
之前我们已经在4.8介绍过了,实质上和CNN的多个卷积核一致。
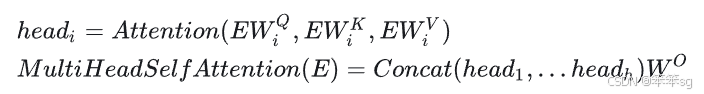
多头注意力模块的输入和输出向量的长度相同,主要是为了确保信息传递的连贯性、简化模型设计,并且支持残差连接。通过每个头的计算后拼接和线性变换,最终输出的维度可以与输入的维度一致。
:
, h是多头自注意力的“头”数
在论文中,Transfomer的默认参数配置如下:
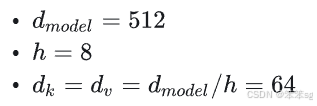
4.18 为啥transformers可以并行,传统的注意力模型不可以。
传统的:计算每个词的表示时,要顺序得出。每个词的表示要依赖于前一个词的计算结果。
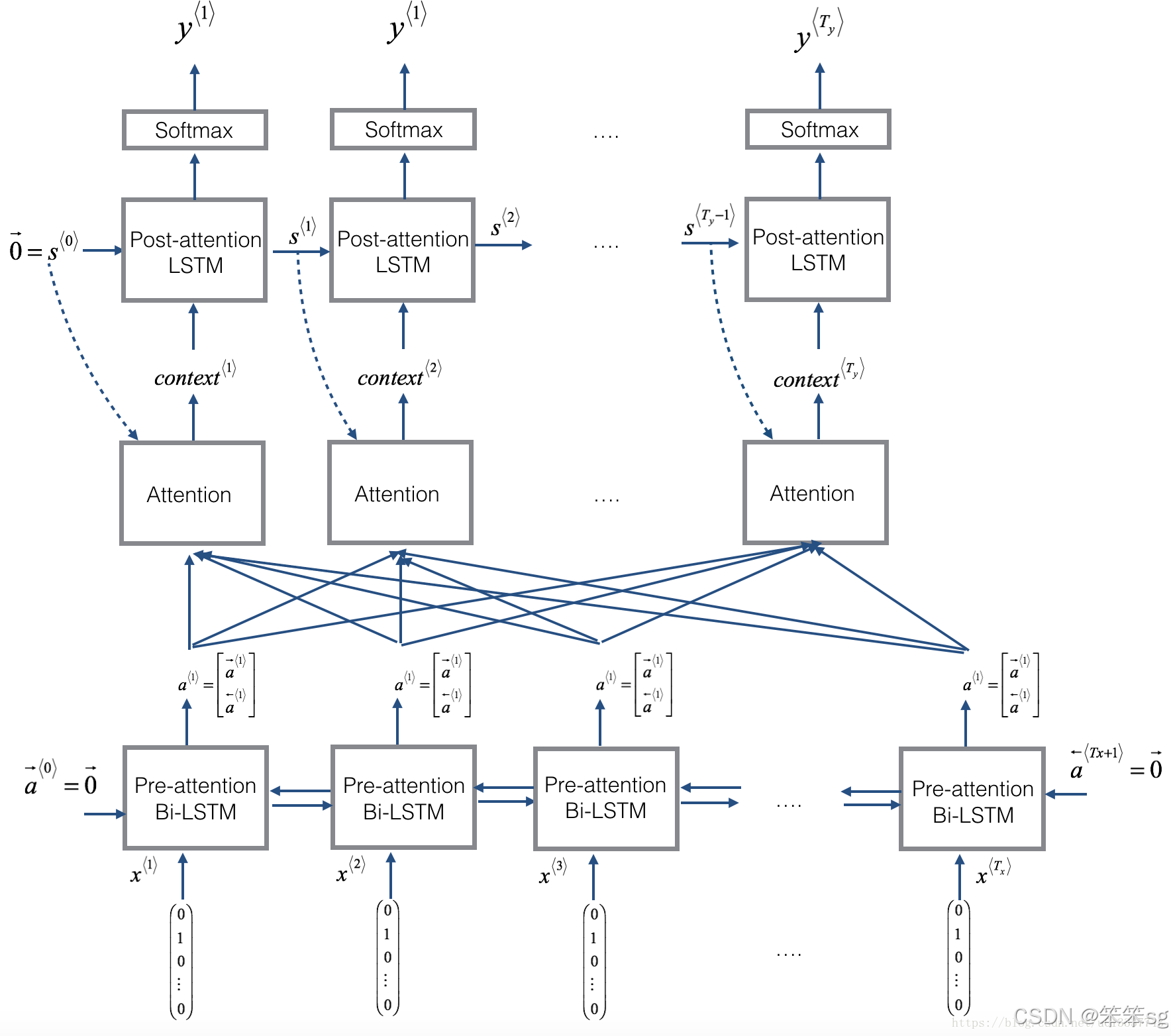
Transformer:计算每个词的表示时,都会根据 所有词 的表示来更新它。每个词的表示不再依赖于前一个词的计算结果,而是通过注意力机制从输入序列的其他所有词中获取信息。
4.19 Transformer 默认会并行地输出结果。而在推理时,序列必须得串行生成,为什么?
- 训练时:Transformer 可以并行地处理整个输入序列(因为已有整个完整的序列),因为每个位置的计算是独立的。
- 推理时:生成每个词时需要依赖于之前已经生成的词(因为没有整个完整的序列),因此推理是 串行的。
4.20 解码器中,数据还会经过一个多头注意力层。这个层比较特别,它的K,V来自z,Q来自上一层的输出。为什么会有这样的设计呢?
如图,下图红框部分。
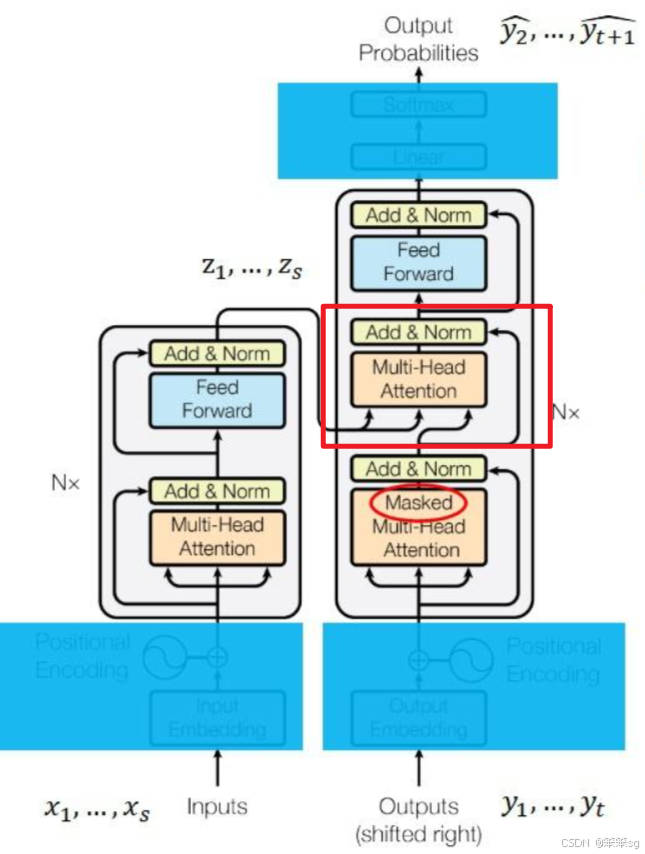
这种设计来自于早期的注意力模型。如下图所示,在早期的注意力模型中,每一个输出单词都会与每一个输入单词求一个注意力,以找到每一个输出单词最相关的某几个输入单词。用注意力公式来表达的话,Q就是输出单词,K, V就是输入单词。
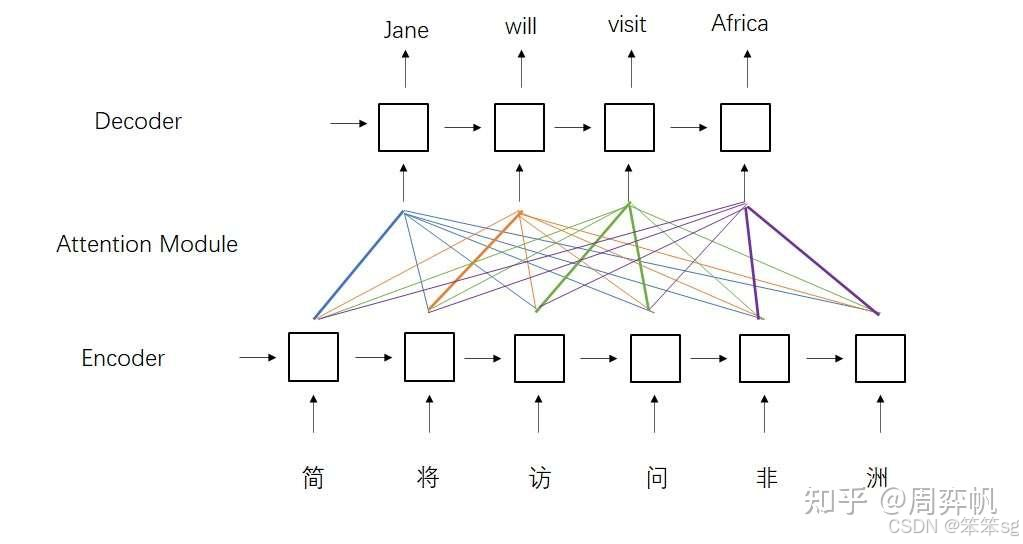
4.21 为什么解码器的多头自注意力层前面有一个masked?
解码器中的多头自注意力层前面有一个 masked(遮掩)机制,主要是为了确保 因果性(causality)或 自回归性,即在生成输出序列时,每个位置的预测只能依赖于该位置之前生成的词,而不能看到后续的词。这是为了避免 信息泄漏,确保每个词的生成过程符合实际的生成顺序。

4.22 如何实现 Masked Attention?
在 Transformer 中,遮掩通常是通过将 未来位置的注意力权重设置为负无穷大 (因为要经过softmax,负无穷进入softmax里出来的话是一个非常非常小的数,接近于0,这代表当前位置的token不关注权重几乎为0的后续token)来实现的,这意味着对于后续位置,模型无法获取任何信息。具体来说,当计算注意力时,我们通常使用一个 遮掩矩阵(mask matrix),该矩阵用来标记哪些位置可以被访问,哪些不能。
假设我们有一个输入序列,正在生成第 i 个词,那么 Masked Attention 会遮掩掉从第 i+1到最后一个词的位置,确保模型在计算注意力时 不看未来的词。
4.23 解码器的嵌入层和输出线性层的权重,编码器的嵌入层的权重,三者有何关联?
- 在Transformer中,解码器的嵌入层和输出线性层是共享权重的——输出线性层表示的线性变换是嵌入层的逆变换,其目的是把网络输出的嵌入再转换回one-hot向量。
- 如果某任务的输入和输出是同一种语言,那么编码器的嵌入层和解码器的嵌入层也可以共享权重。
4.24 Transformer中为啥需要用到位置编码?
之前我们提到Transformer的出现是为了解决传统注意力模型不能并行计算的缺点,但相应的,既然Transformer可以并行计算,它也因此需要一种额外的编码——位置编码。因为 Transformer 不像 RNN 那样天然包含顺序信息。通过位置编码,Transformer 可以区分序列中每个词或元素的位置,从而处理输入的顺序依赖关系。
假设你有一句话:
"我爱自然语言处理"
这句话的词向量表示如下(假设每个词用一个向量表示,向量维度为 4):

- 如果没有位置编码,这些词向量被输入到模型中时,没有任何信息表明 “我” 是第一个词,“爱” 是第二个词。
- 换句话说,模型无法区分 "我爱自然语言处理" 和 "自然语言处理我爱",因为词向量本身不包含顺序信息。
4.25 Transformer中如何引入位置编码?
嵌入层的输出是一个向量数组,即词嵌入向量的序列。设数组的位置叫pos,向量的某一维叫i。我们为每一个向量里的每一个数添加一个实数编码,这种编码方式要满足以下性质:
- 对于同一个pos不同的i,即对于一个词嵌入向量的不同元素,它们的编码要各不相同。
- 对于向量的同一个维度处,不同pos的编码不同。且pos间要满足相对关系,即
要满足这两种性质的话,我们可以轻松地设计一种编码函数:
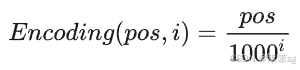
即对于每一个位置i,用小数点后的3个十进制数位来表示不同的pos。pos之间也满足相对关系。
但是,这种编码不利于网络的学习。我们更希望所有编码都差不多大小,且都位于0~1之间。为此,Transformer使用了三角函数作为编码函数。这种位置编码(Positional Encoding, PE)的公式如下:

还是这个例子:
"我爱自然语言处理"


实际效果举例:
假设我们有两句话:
- "我爱自然语言处理"
- "自然语言处理我爱"
在没有位置编码的情况下,Transformer 可能会将两句话视为完全相同的输入,因为它们的词向量排列的顺序对模型没有意义。
引入位置编码后:
- 第一句话中,第一个词的编码是 x1+PE(1),表示“我”在第一个位置。
- 第二句话中,第一个词的编码是 x3+PE(1),表示“自然语言”在第一个位置。
由于位置编码不同,Transformer 可以区分出这两种句子顺序,并学到它们的语义差异。
我们验证了性质1,那么这个公式满足性质2么?
注意,下面验证的过程中,由于频率w从1逐渐接近于0,因此可以默认cos(w)=1,性质2并非绝对相等,而是近似成立。



本文作者也尝试了用可学习的函数作为位置编码函数。实验表明,二者的表现相当。作者还是使用了三角函数作为最终的编码函数,这是因为三角函数能够外推到任意长度的输入序列,而可学习的位置编码只能适应训练时的序列长度。
5 实战演练
5.1 第五课——Week1:
5.2 第五课——Week2:
5.3 第五课——Week3:
5.4 第五课——Week4:
6 参考文献
- NLP发展历程 - 知乎
- 芝麻街全员恶人?从Google到百度的NLP起名之道(非技术向科普) - 知乎
- NLP发展之路I - 从词袋模型到Transformer - 知乎
- NLP发展之路II - 从BERT到ChatGPT - 知乎
- 万字长文带你了解NLP预训练模型的前世今生 - 知乎
- 一文梳理NLP主要模型发展脉络 - 知乎
- 00 预训练语言模型的前世今生(全文 24854 个词) - B站-水论文的程序猿 - 博客园
- NLP的发展历程 - 知乎
- 【深度学习】GRU的结构图及公式_gru公式-CSDN博客
- [论文解读]Neural machine translation by jointly learning to align and translate_neural machine translation by jointlylearning to a-CSDN博客
- 【论文解读】Bahdanau Attention - 知乎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









