







目录
1.10 Seq2Seq模型用于多标签分类(Multi-label Classification)
1.11 Seq2Seq模型用于物体检测(Object Detection)
2.5 多头注意力(Multi-Head Attention):
2.7 Layer Normalization与Batch Normalization的区别
2.8 为何使用Layer Normalization而不是Batch Normalization:
3.1 Auto-regressive Decoder的工作原理:
4.1 Auto-regressive Decoder (AT):
4.2 Non-Auto-regressive Decoder (NAT):
5 Cross Attention 机制:连接 Encoder 和 Decoder 的桥梁
5.3 Cross Attention 在 Decoder 中的作用
5.4 实际案例:语音识别中的 Cross Attention
7.3 Pointer Network 和 Copy Mechanism
8.4 Location-aware Attention(位置感知注意力)
9.2 Greedy Decoding vs. Beam Search
11 为什么Cross Entropy无法直接优化BLEU Score?
13 训练与评估指标的不一致 (Exposure Bias),如何解决?
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“拓展内容(第10讲)”章节的拓展部分笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
本章节资源链接:
【機器學習2021】Transformer (上)- YouTube
【機器學習2021】Transformer (下) - YouTube
我在之前吴恩达老师的“2021吴恩达学习笔记deeplearning.ai《深度学习专项课程》篇”中“第五课:序列模型”也记录过Transformer相关的笔记,感兴趣的可以参考一下。

此外,我还记录了Transformer架构的Tensorflow实现:
Pytorch版本的实现可以参加:
PyTorch Transformer 英中翻译超详细教程 - 知乎
那么接下来让我们来听一下李宏毅老师是如何讲解Transformer的。
1 Seq2Seq简介——能够广泛地应用于各类任务
1.1 Transformer模型简介
- Transformer 是一种基于self-attention机制的序列到序列(Seq2Seq)模型。与传统的RNN或LSTM模型相比,Transformer能够通过全局依赖关系进行并行处理,提高了训练速度和效果。
- 其核心特点是可以处理不同长度的输入和输出序列,而不需要预先定义输出的长度。
- 在很多自然语言处理任务中,Transformer与BERT等模型有密切联系,因其强大的表示学习能力。
在正式进入Transformer 讲解之前,我们有必要了解一下序列到序列(Seq2Seq)模型。
1.2 Seq2Seq任务的应用:输出长度由机器决定
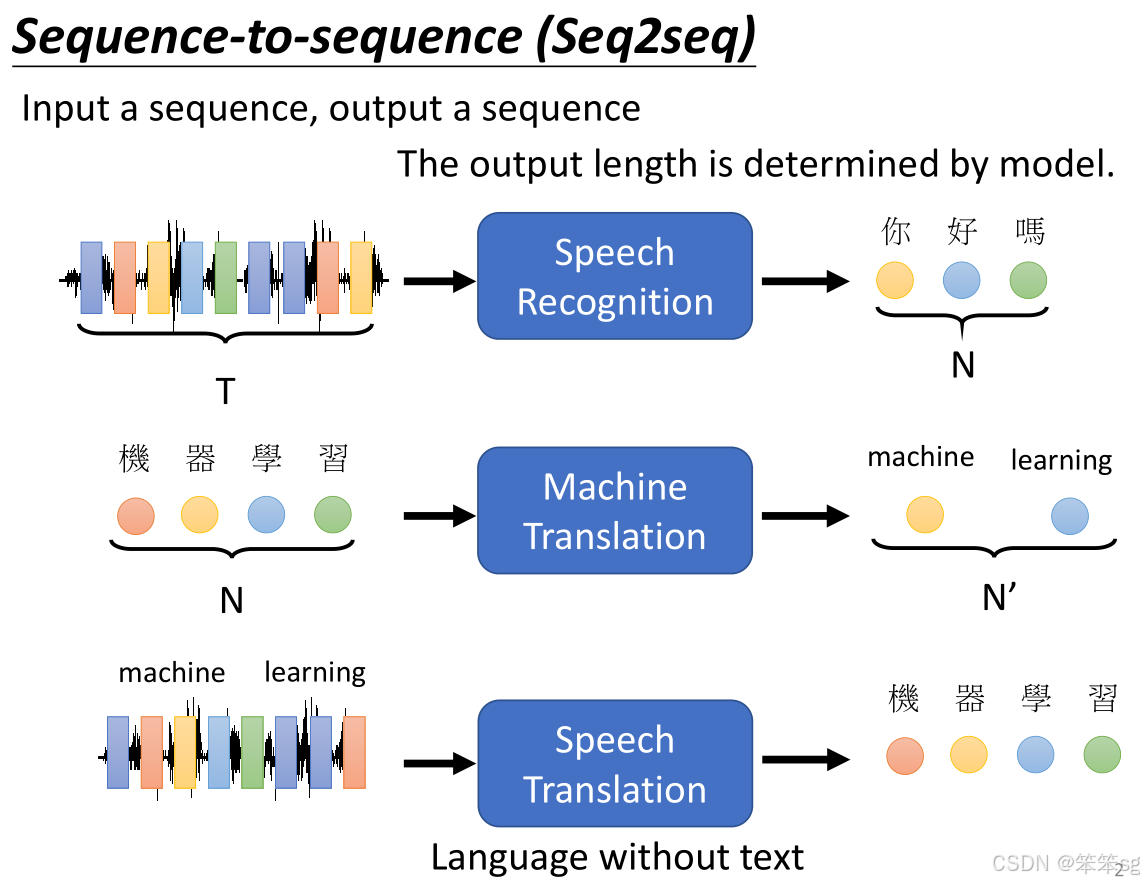
- 在Seq2Seq模型中,输入序列与输出序列的长度不固定,输出的长度是由模型在处理输入序列时动态决定的。
- 语音识别:输入是音频信号,输出是对应的文本。音频信号的长度(T)与文本长度(N)之间没有固定关系,机器需要通过学习从音频信号中推断出合适的文本输出长度。
- 机器翻译:输入是某种语言的句子,输出是目标语言的翻译。输入句子的长度(N)与翻译句子的长度(N')之间也没有直接关系,模型需要决定输出的准确长度。
1.3 语音翻译的创新任务
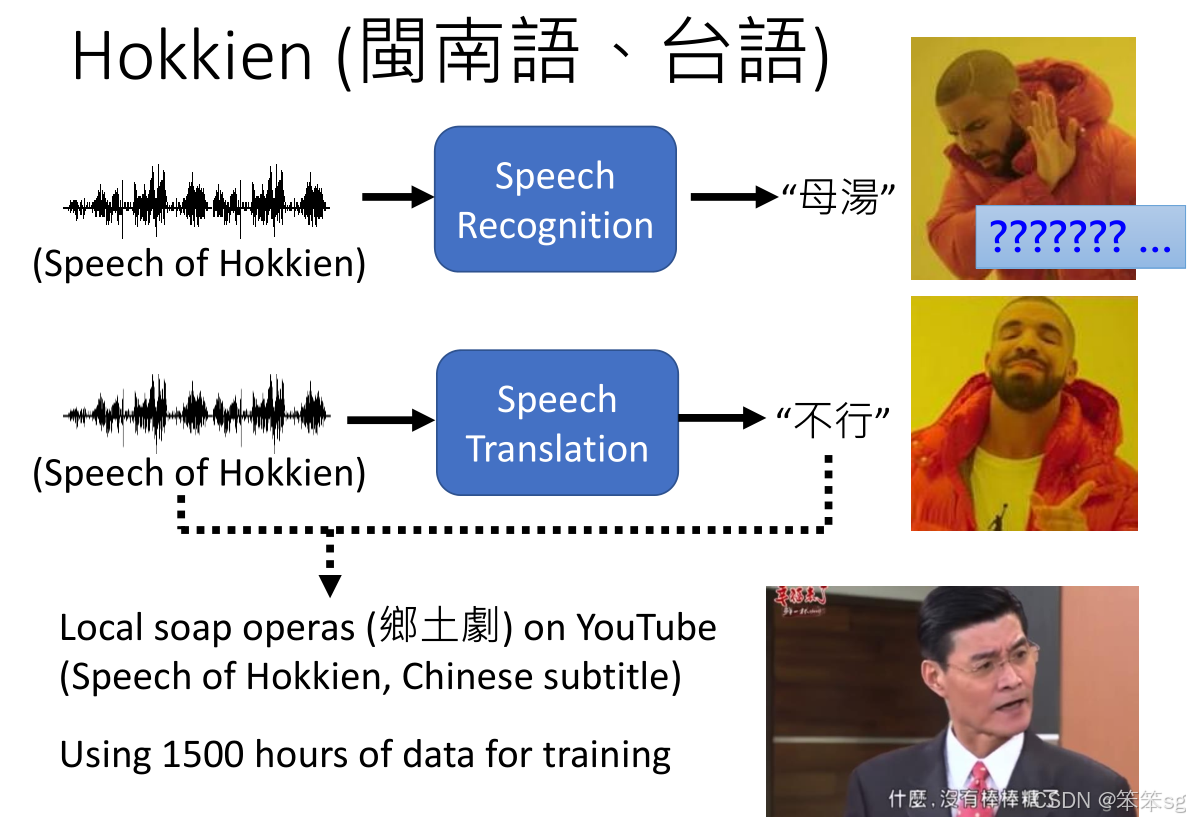

- 语音翻译(Speech Translation)是一个更具挑战性的任务。与传统的语音识别加机器翻译模型不同,语音翻译直接将语音信号转换为目标语言的文本,这在一些没有书面文字的语言中尤为重要。那这样子做到底行不行呢?不如先“硬train一发”
- 事实证明是可以的
- 台语语音翻译是一个很好的例子。虽然台语有一些书写系统(如台罗拼音),但它并不普及。对于没有书写系统的语言,直接进行语音翻译而非语音识别+翻译是一个更好的解决方案。
- 数据收集:通过收集大量的台语视频(如乡土剧)并结合其字幕,可以创建台语音频与中文文本之间的对应关系,为训练语音翻译系统提供数据。
1.4 实践案例:台语语音翻译

- 实验数据:通过1500小时的乡土剧资料,训练了一个语音翻译系统,能够将台语的音频信号直接转换为中文文本。
- 成功案例:模型能够准确地处理一些台语句子,将其翻译为相应的中文文本。例如,模型可以将台语音频“XXXX”正确翻译为“你的身体撑不住”。
- 错误案例:模型在一些复杂的句子中出现翻译错误,如对台语句子“XXXX”翻译为“我有帮厂长拜托”,而实际上应该是“我拜托厂长”。这说明在处理语言结构(如倒装语法)时,模型还存在一定的困难。
1.5 台语语音合成概述
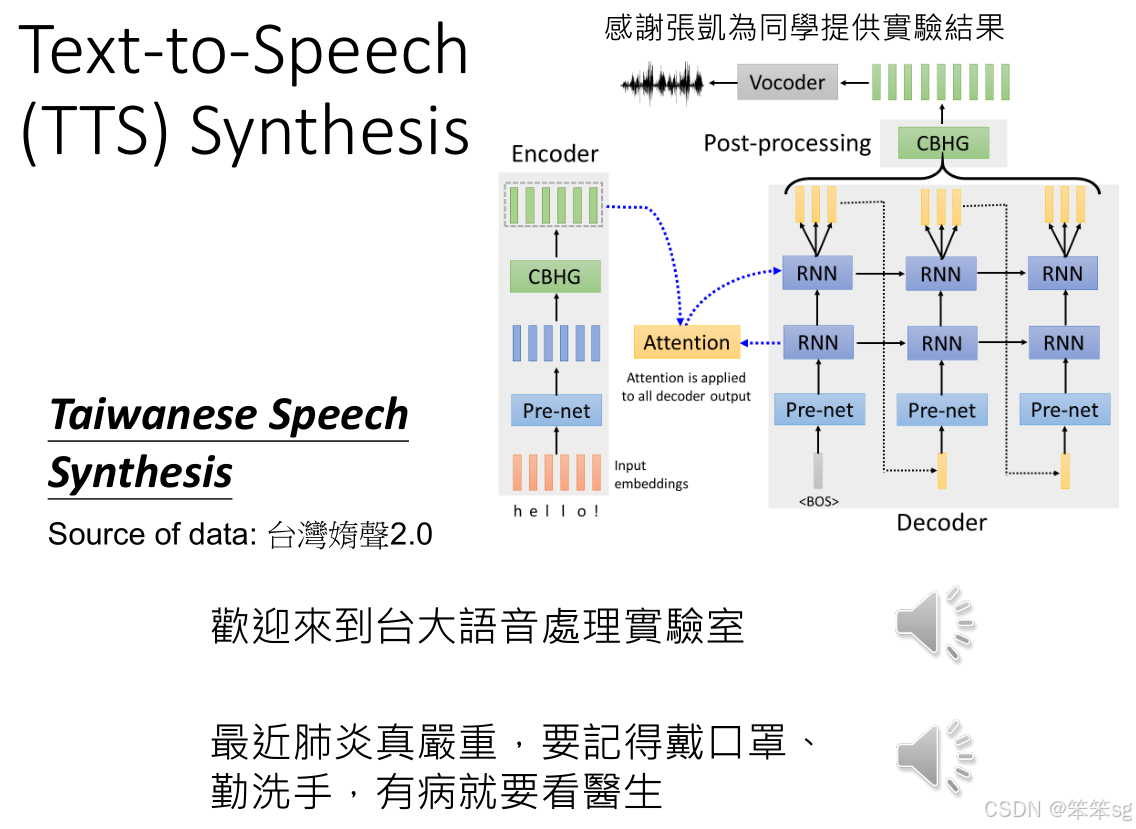
- 台语语音合成是将中文文本转换为台语音频的过程。和语音识别相反,语音合成是从文字生成声音信号,这需要将文本的语言结构映射到实际的音频波形上。
- 在这个例子中,输入的文本(如中文句子)经过两个阶段的转换,最终输出台语的声音信号。
1.6 Seq2Seq模型在聊天机器人中的应用
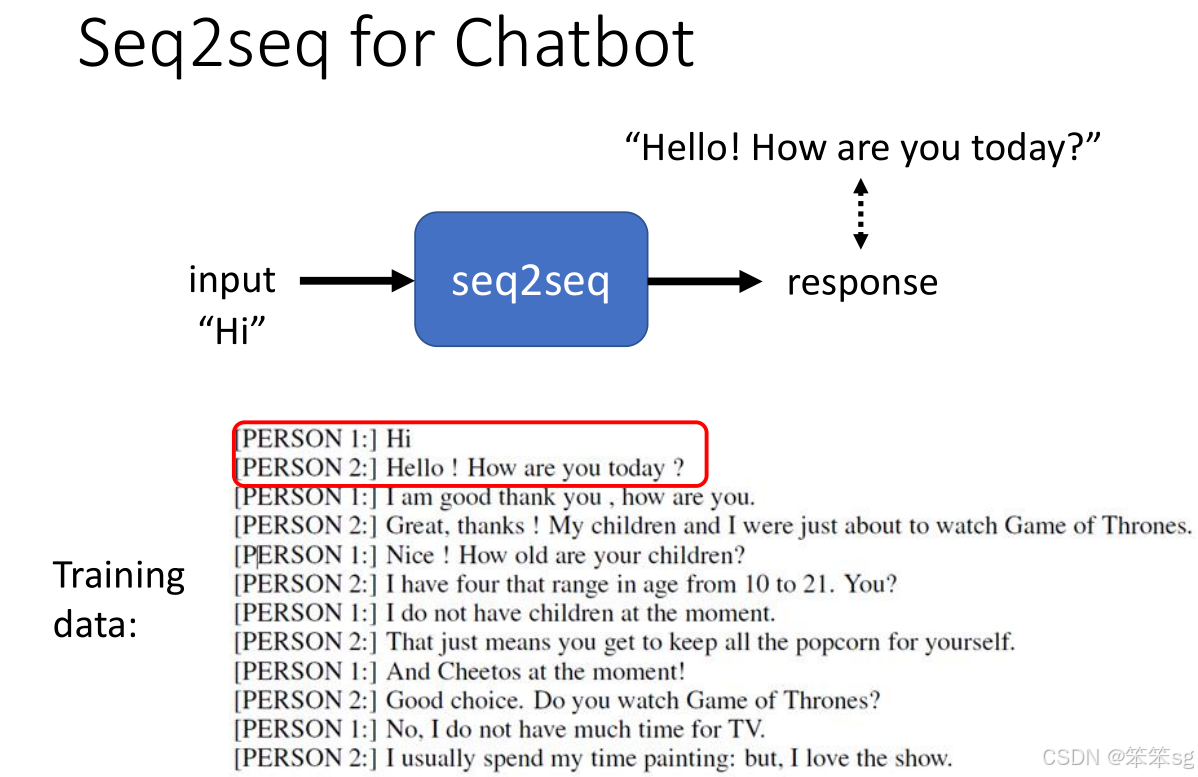
- Seq2Seq模型可以用来训练聊天机器人。在这种任务中,输入是一个对话的句子(如“Hi”),输出是机器人要回应的句子(如“Hello, how are you today?”)。
- 通过收集大量对话数据(如电视剧或电影台词),模型学会根据输入生成适当的输出。
1.7 Seq2Seq模型在自然语言处理中的广泛应用
- Seq2Seq不仅可以用来做聊天机器人,还可以应用到许多NLP任务中:
- 翻译(Translation):例如,输入英文句子,输出相应的德文句子。
- 摘要(Summarization):输入长文章,输出该文章的简短摘要。
- 情感分析(Sentiment Analysis):输入一段文本,判断其情感是正面的还是负面的。
- 情感分析的例子:你可以使用Seq2Seq模型来判断一篇文章是正面还是负面评论,通过将“文本+问题”(例如“这篇文章是正面还是负面?”)输入到模型,模型给出回答。
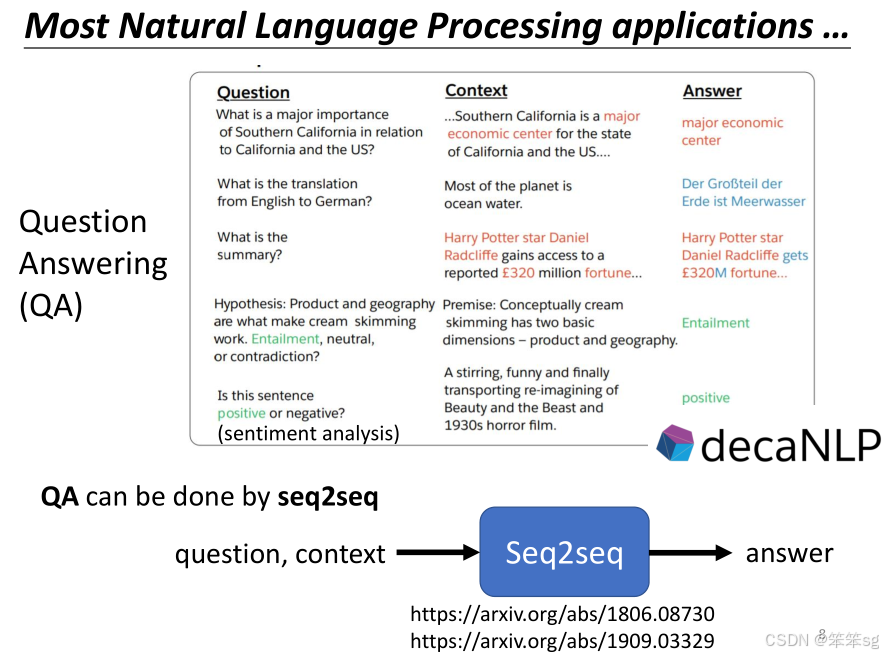
- 许多NLP任务可以转换为问答任务,例如:
- 问题:可以翻译下面这句话为德文么?
- 输入文本:英语句子
- 输出:翻译后的德文
- 对于其他任务,比如自动摘要,实际上也可以看成是一个“问题-答案”模式,只是问题是“这篇文章的摘要是什么?”。
1.8 为特定任务定制模型
- 虽然Seq2Seq是一个非常通用的模型,但对于许多NLP任务和语音任务来说,特定的定制化模型可能会带来更好的效果。例如,语音识别任务中,虽然可以使用Seq2Seq模型,但Google Pixel 4中使用的却是RNN Transducer模型,这个模型更适合语音识别任务的特点。
- 在实际应用中,针对不同任务设计和优化专门的模型往往能够取得更好的效果,尽管Seq2Seq模型的通用性很强。
1.9 Seq2Seq模型用于文法剖析
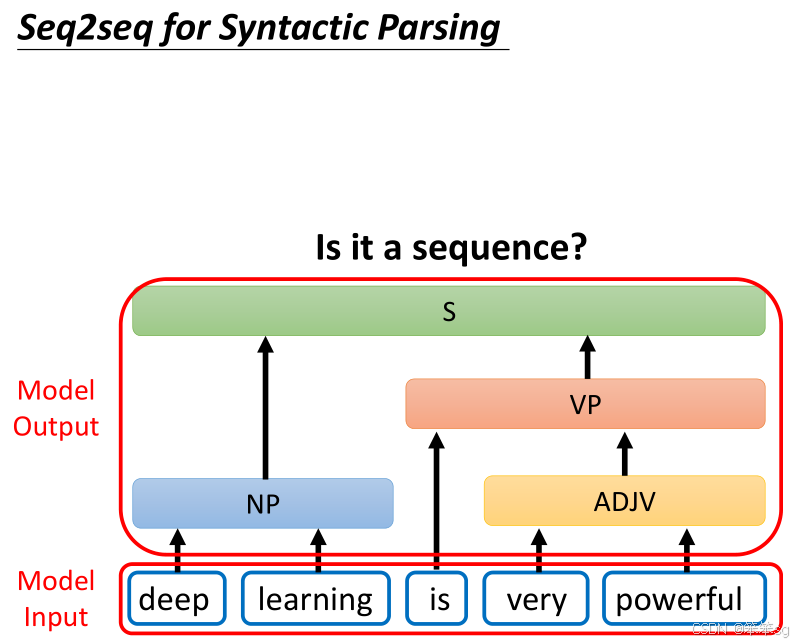
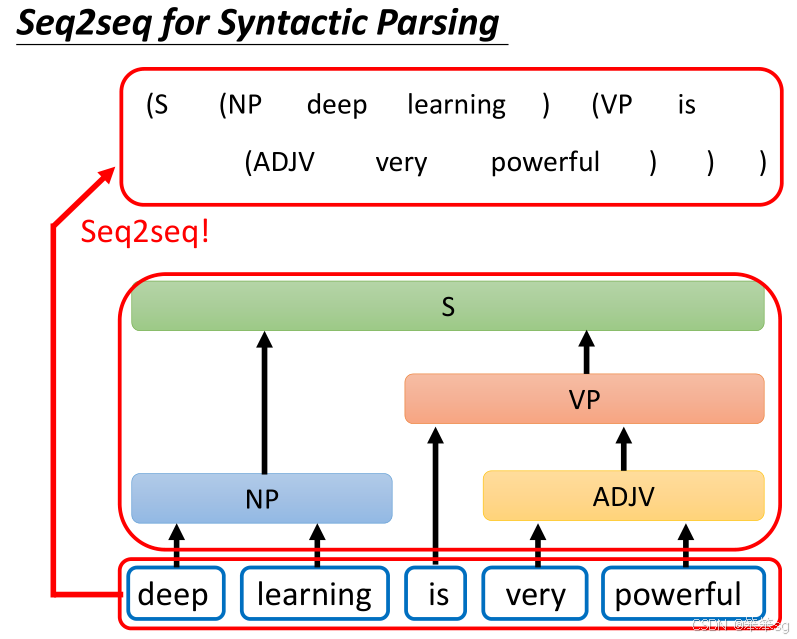
- 事实上,Seq2Seq模型甚至可以应用于文法剖析任务。例如,给机器一段句子,如“deep learning is very powerful”,任务是产生一个文法剖析树,展示句子的结构关系。
- 这种树状结构可以通过转换为特定的序列,利用Seq2Seq模型进行处理,甚至能像翻译一样,从输入的句子生成一个“文法树序列”作为输出。
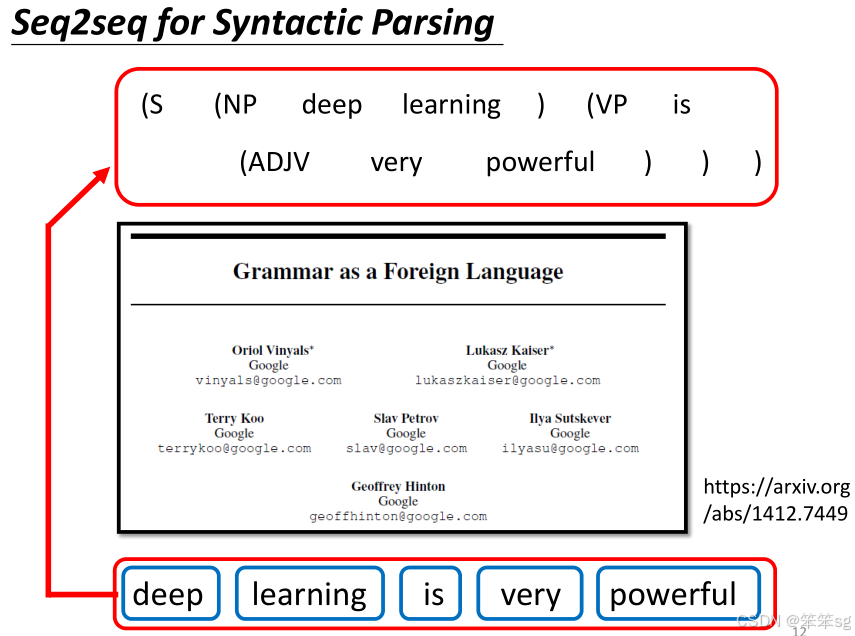
1.10 Seq2Seq模型用于多标签分类(Multi-label Classification)
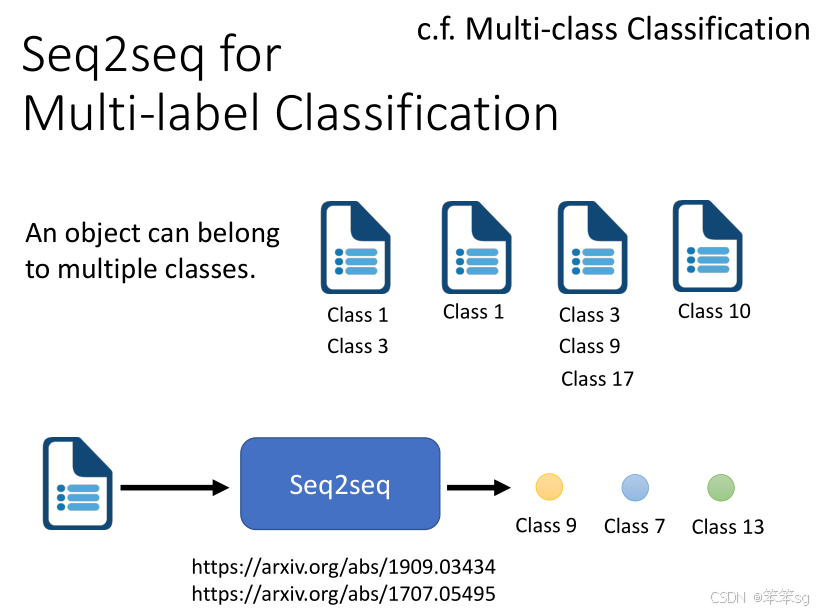
- 在多标签分类问题中,输入一篇文章,模型输出多个标签。Seq2Seq可以处理此问题:输入文章后,模型能够决定输出多少个标签(而不是单纯的选择一个标签)。
- 与传统的多类分类不同,多标签分类允许一个实例同时属于多个类别,Seq2Seq模型能够灵活处理这种情况。
- 直接输入模型一篇文章(或其他信息),让它帮我们确定该文章属于多少类别,具体是哪些。
1.11 Seq2Seq模型用于物体检测(Object Detection)
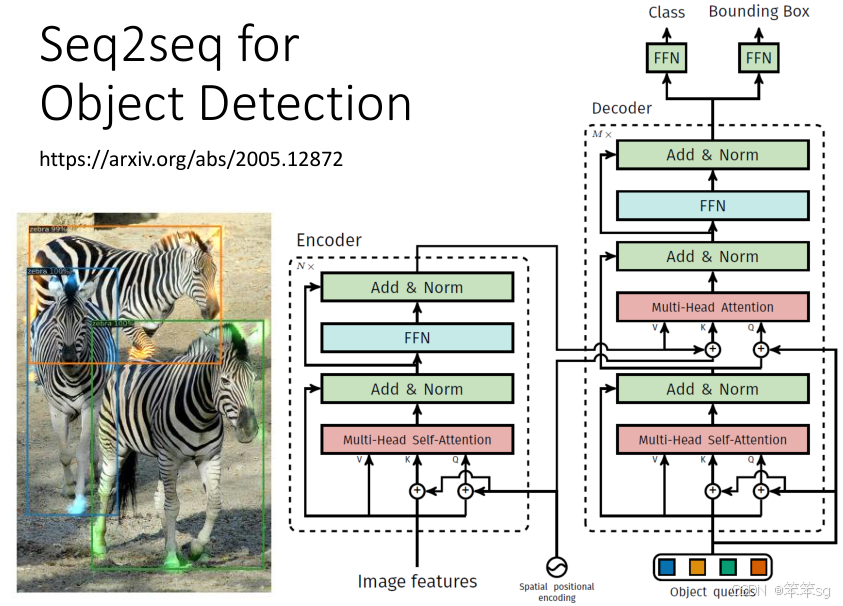
虽然物体检测任务通常和Seq2Seq模型的应用看起来不相关,但其实可以将物体检测问题转换为Seq2Seq模型来解决。通过给定图像和期望的目标(比如物体框的位置),Seq2Seq模型可以生成相应的物体检测框。
1.12 Seq2Seq模型的设计

- Seq2Seq模型最早的应用可以追溯到2014年,当时它被用在机器翻译任务中。随着时间的推移,Seq2Seq模型的应用范围不断扩大,包括NLP和语音任务中的许多问题。
- Seq2Seq模型的核心由编码器(Encoder)和解码器(Decoder)组成。编码器负责处理输入序列,并将其转换为一个固定长度的表示,解码器则从这个表示生成输出序列。
- 在现代Seq2Seq模型中,Transformer架构成为了主流。Transformer模型的优势在于它使用了自注意力机制(Self-Attention)来处理长距离依赖问题,同时可以并行运算,极大提升了效率和效果。
好了,上面写了那么多,就是为了告诉你Seq2Seq模型是一种非常强大的工具,而Transformer又是当前Seq2Seq模型所使用的主流架构,下面就让我们了解一下Transformer中的Encoder和Decoder吧!
2 Encoder
2.1 Encoder的任务
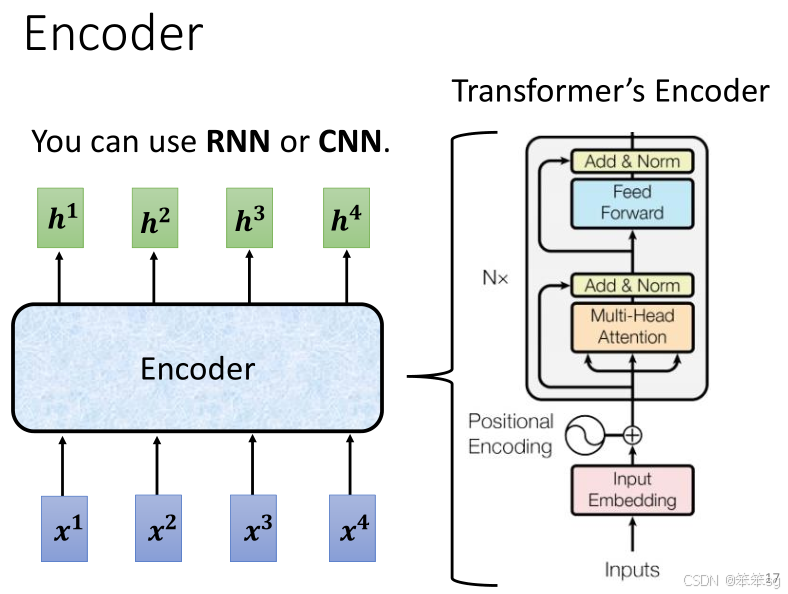
Encoder的目标是将一个输入序列(向量)映射为一个输出序列。简单地说,输入一组向量,输出另一组相同长度的向量。
2.2 Transformer Encoder架构:
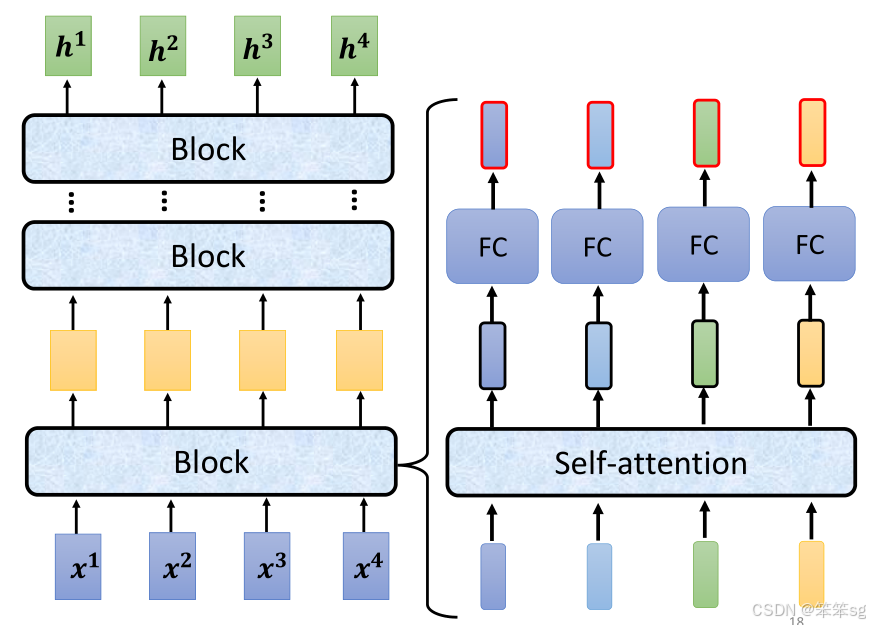
Transformer的Encoder基于Self-Attention机制,并通过多个block(模块)进行堆叠。每个block由多个层(Layer)组成,不同于一般的神经网络层,block中包含了多个重要组件。
2.3 每个block包含的步骤:

1)Self-Attention:
每个输入向量都会根据整个序列的信息进行加权处理,生成新的向量输出。这里考虑了所有输入之间的相互关系。
2)Feedforward Network:
Self-Attention的输出会传递到一个全连接层(Feedforward Network),再生成一个新的向量。
3)Residual Connection:
在每个操作后,输入向量会直接加到输出向量上,形成残差连接。这有助于缓解梯度消失问题,并促进信息流的传递。
4)Layer Normalization:
不仅仅在Self-Attention和Feedforward后使用了Layer Normalization,这也是一种确保模型稳定性的技术。它在每一层的输出后进行规范化,减小内部协方差偏移,提高模型训练的效率和稳定性。
5)Self-Attention与Residual Connection的结合:
在Self-Attention和Feedforward的输出后,我们会添加Residual Connection(即将输入与输出相加),再经过Layer Normalization。
这种结构重复堆叠多次,最终得到整个Transformer Encoder的输出。
2.4 Positional Encoding:
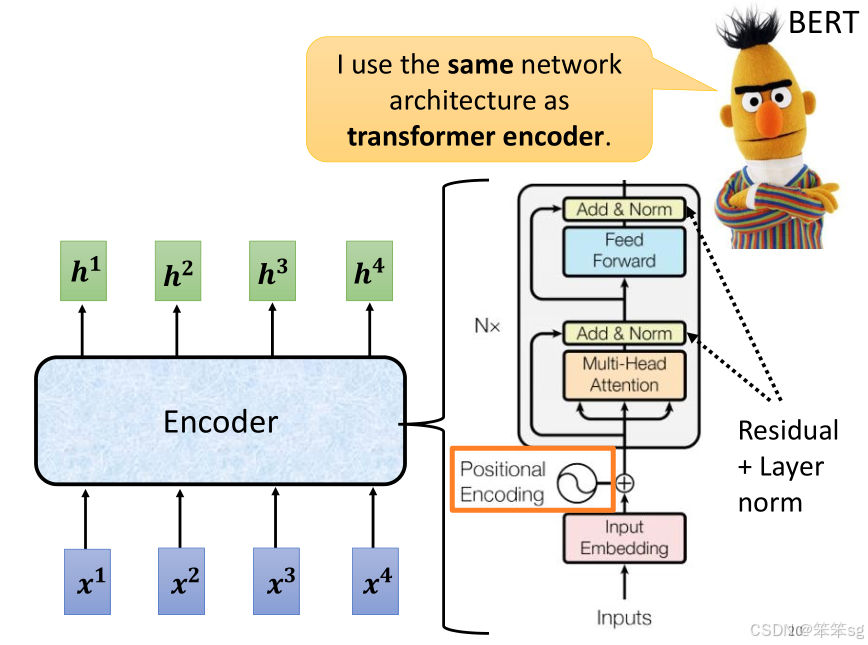
由于Transformer模型本身不具备处理序列顺序的能力(不像RNN或CNN),需要通过Positional Encoding在输入序列中加入位置信息,以让模型知道序列中的元素位置。
2.5 多头注意力(Multi-Head Attention):
在Self-Attention部分,Transformer引入了Multi-Head Attention,允许模型在不同的子空间中并行学习输入序列的多种关系,从而捕获更多的信息。
2.6 设计考量与改进:
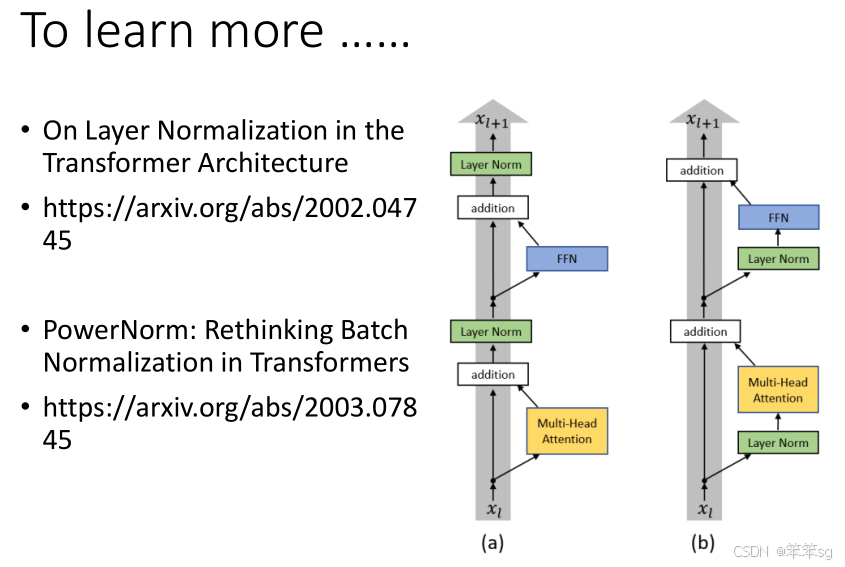
Transformer的设计并不是最优的,尽管它在许多任务上表现优秀。设计中的一些选择(比如Residual Connection的顺序、Layer Normalization的位置)并不是绝对最佳的。后续的研究已经提出了一些替代方案,像是将Layer Normalization的位置交换、使用其他归一化方法等,甚至提出了Power Normalization作为可能的改进。
2.7 Layer Normalization与Batch Normalization的区别
Layer Normalization 和 Batch Normalization 都是用来提高神经网络训练稳定性的技术,但它们的实现方式和使用场景有显著的不同。让我通过一个通俗易懂的例子来帮助你理解它们的区别。
Batch Normalization (批量归一化)
想象你在餐厅里点了很多道菜,每道菜上都配有不同的调料。这些菜在上菜时,服务员会根据所有菜肴的整体味道来调整调料,比如平衡盐和糖的比例,确保每道菜的味道符合标准。
- Batch Normalization 就像这种方法,它会利用整个“批次”(Batch)的数据来计算每个特征的均值和方差,然后用这个批次的统计信息来规范化每个样本。这样,可以确保每道菜(样本)都有一个标准的调料比例。
例子:
假设你有一个批次的10个图片,每个图片的像素是一个特征。在Batch Normalization中,你会计算所有图片在某个像素位置的均值和方差(跨整个批次的所有图片),然后用这个均值和方差对每个图片进行标准化。这样,在同一个批次内的图片具有相似的标准化信息。
特点:
- 在训练时,BN需要计算每个批次的均值和方差,这会依赖于批次大小。
- Batch Normalization 适合用于处理批量数据,但不适用于变长的序列或单个样本的预测。
Layer Normalization (层归一化)
想象你在做一项烹饪挑战比赛,每个参赛者独立准备菜肴。比赛规定,你要根据每个菜肴自己的要求来调整调料比例,而不是基于其他参赛者的菜肴。在这种情况下,你只能根据每道菜本身的味道来决定使用多少盐和糖,而不管其他菜肴的情况。
- Layer Normalization 就是这种做法,它是在每个样本内进行归一化,基于每个样本的特征来计算均值和方差,而不是跨样本(批次)计算。
例子:
假设你有一个单一的图片(一个样本),每个像素值是一个特征。在Layer Normalization中,你会计算这个图片的所有像素(特征)的均值和方差,然后用这个均值和方差来标准化图片的每个像素值。这样,每个图片内部的像素值被归一化,使得该图片内的各个特征在同一尺度上。
特点:
- Layer Normalization 不依赖于批次大小,而是依赖于单个样本的内部信息。它对每个样本独立进行归一化,适合于处理变长的序列或单个样本的情况。
2.8 为何使用Layer Normalization而不是Batch Normalization:
- Layer Normalization 可以独立地对每个样本进行归一化,适应变长序列和独立样本处理。
- 它对批次大小不敏感,避免了 Batch Normalization 在小批次或单样本推理时的性能不稳定问题。
- 更好地适应了 Self-Attention 机制和 Transformer 的设计需求。
- 在推理阶段,能够保持一致性和稳定性。
想象一下你和朋友们在一家餐厅里就餐:
-
Batch Normalization 就像是你和朋友们一起点菜,大家都在同一张大桌子上吃饭。在点菜的时候,服务员需要根据每个人点的菜的整体情况来推荐菜肴,比如根据大家的喜好(即均值和标准差),来判断哪些菜适合大家。这里,餐桌上的每个人的口味都是基于所有人的口味来决定的,假设你们每个人的需求相对一致。如果有某个朋友非常挑食,或者是吃的菜特别特殊,那么推荐的菜可能就不那么适合你们其他人。
这种方式类似于 Batch Normalization:它通过整个“餐桌”(即一个批次的样本)来计算均值和标准差,这样它需要保证所有人的口味差不多,否则整体推荐会受到影响。在推理阶段,只有你一个人在吃饭,服务员会根据你过去吃的菜的推荐来提供菜肴(使用训练时收集到的统计信息),但这时的推荐可能不如预期,因为它依赖于训练时的多个人数据。
-
Layer Normalization 则像是每个人点菜时,服务员独立考虑每个人的口味和需求。每个人都有自己独特的偏好,服务员会根据你的个人需求来推荐菜肴,而不需要依赖于别人点的菜。这就像是 Layer Normalization:它只关心你自己,计算你自己在餐桌上的需求(即每个人自己的均值和标准差),不管其他人喜欢什么。这样即使你一个人吃饭,服务员依然能够根据你的需求提供恰当的推荐。
3 Decoder
3.1 Auto-regressive Decoder的工作原理:
- 你提到的 auto-regressive decoder 是基于生成一个词接着生成下一个词的方式。它在 语音辨识 中的任务是,将输入的语音信号转换为对应的文字。其原理与 机器翻译 相似,只不过输入和输出的内容不同。
- 语音辨识的例子:
- 输入:一段声音(例如,“机器学习”)。
- 通过 Encoder 处理后,输出的是一系列的向量。
- Decoder 的任务就是根据这些向量生成最终的文字输出。
3.2 Decoder的具体操作:
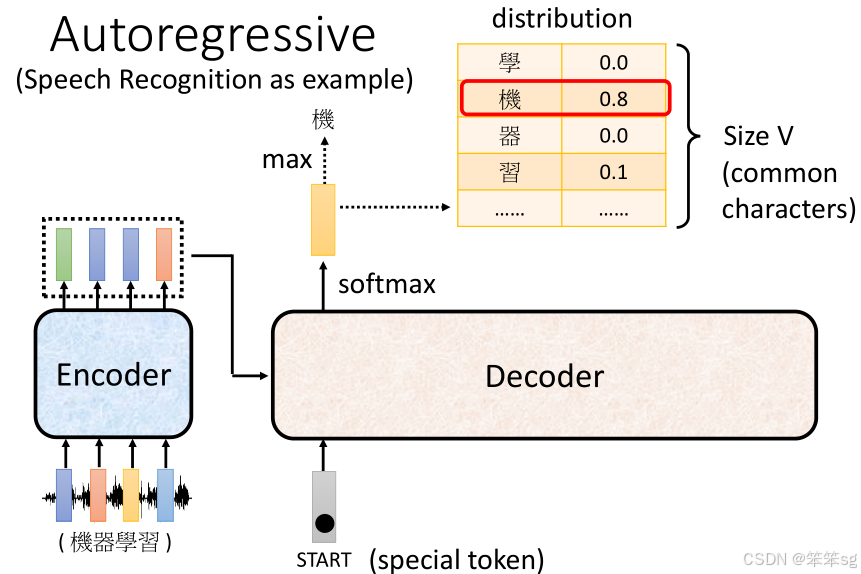
- Decoder接收输入:首先,Decoder会接收到一个特殊符号(BOS,begin of sentence),代表开始生成文字。
- 生成向量:Decoder基于这个输入符号,通过计算得到一个长向量,向量的长度与 vocabulary size(词汇表的大小)相同。这个向量是一个概率分布,表示每个可能输出词汇的概率。
- 比如在中文语音识别中,输出的词汇可能是常见的3000个汉字,每个字对应一个概率值。
- Decoder生成的向量会经过 softmax,从而输出概率分布。
- 逐步生成输出:第一个输出的字符会是概率最大的那个(比如“机”)。然后,Decoder会将这个字符作为下一轮输入,再根据这个输入生成第二个字符(例如“器”),这个过程会持续进行,直到生成完整的句子。
3.3 关键问题:Error Propagation:
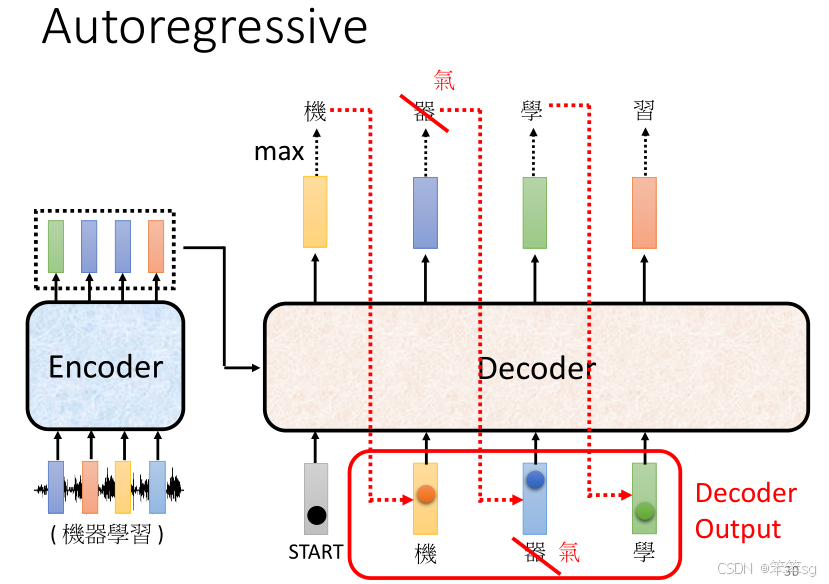
- 你提到 Error Propagation,即当Decoder生成错误的输出时,这个错误会影响到后续的输出。例如,假设Decoder错误地将“器”识别为“天气”的“气”,那么后续的预测可能也会受到影响,产生错误的句子。
- 这个问题在 auto-regressive decoder 中是一个挑战,因为每一步的预测都依赖于前一步的输出。
3.4 Decoder的内部结构:
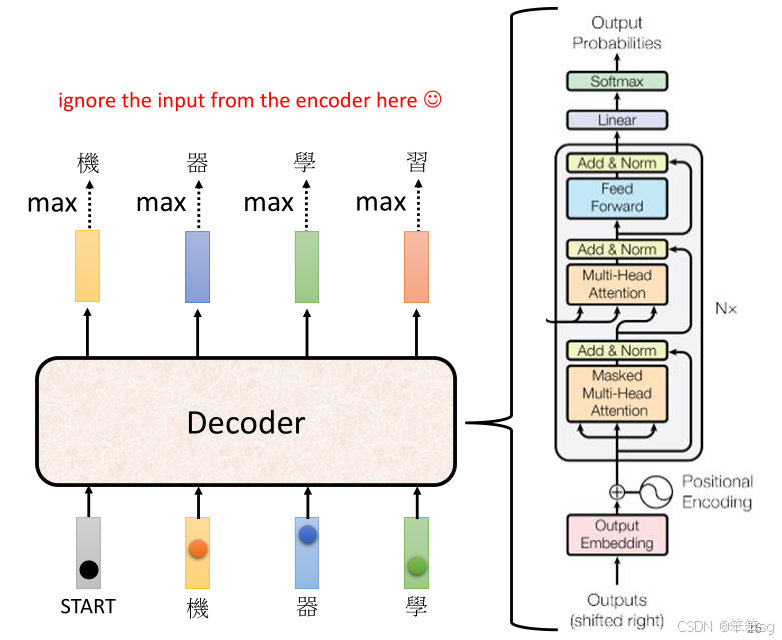
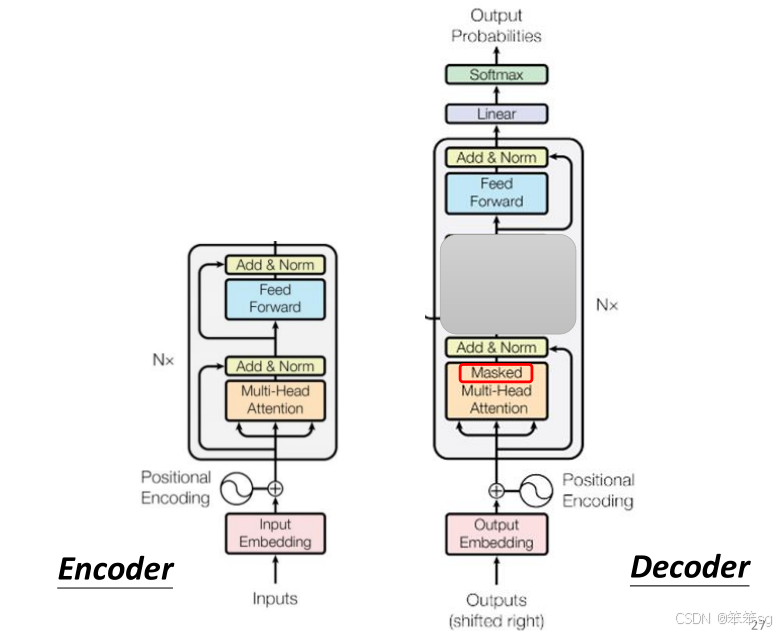
- 我们不妨先把Encoder到Decoder的输入部分遮住然后进行观察。
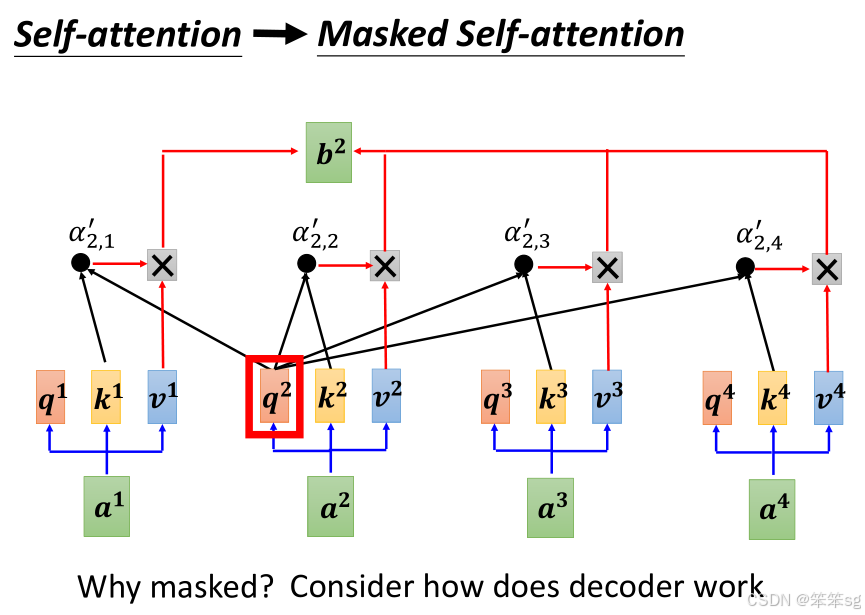
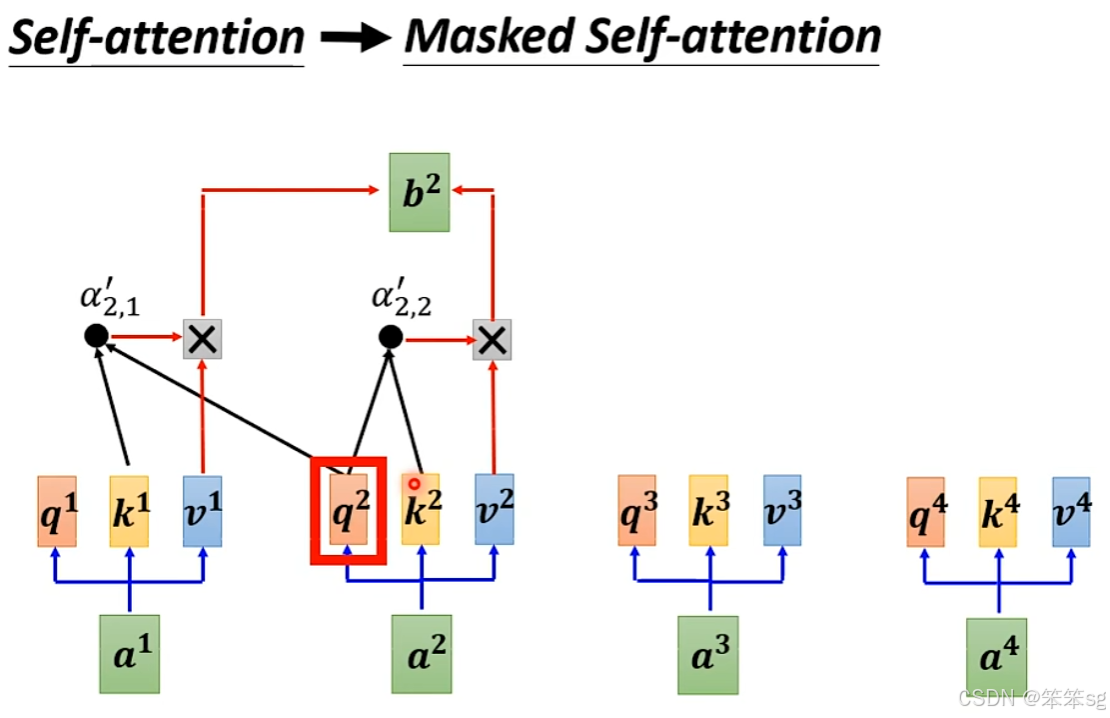
- 你会发现,Decoder和Encoder有很多相似之处,都是由 multi-head attention 和 feedforward networks 组成。不同之处在于,Decoder中间有一个额外的部分——Masked Multi-Head Attention,这是为了确保Decoder在生成每个词时,只能看到当前词和之前的词,不能看到之后的词。
- Masked Attention:在Decoder中,我们对每个token的attention进行了mask处理,确保当我们生成b2时,只能考虑a1和a2的信息,而不能看到a3、a4等后续的token。
3.5 Masked Self-Attention的作用:
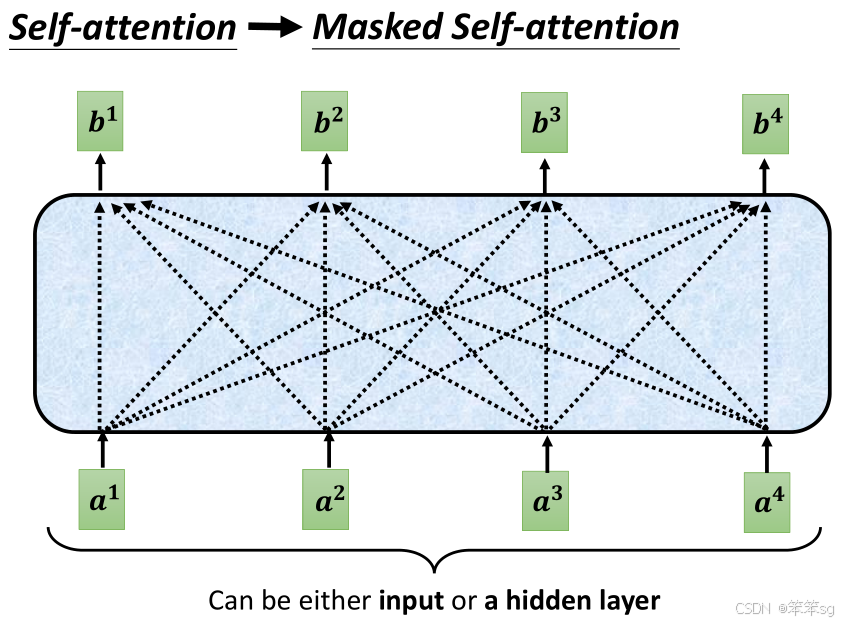
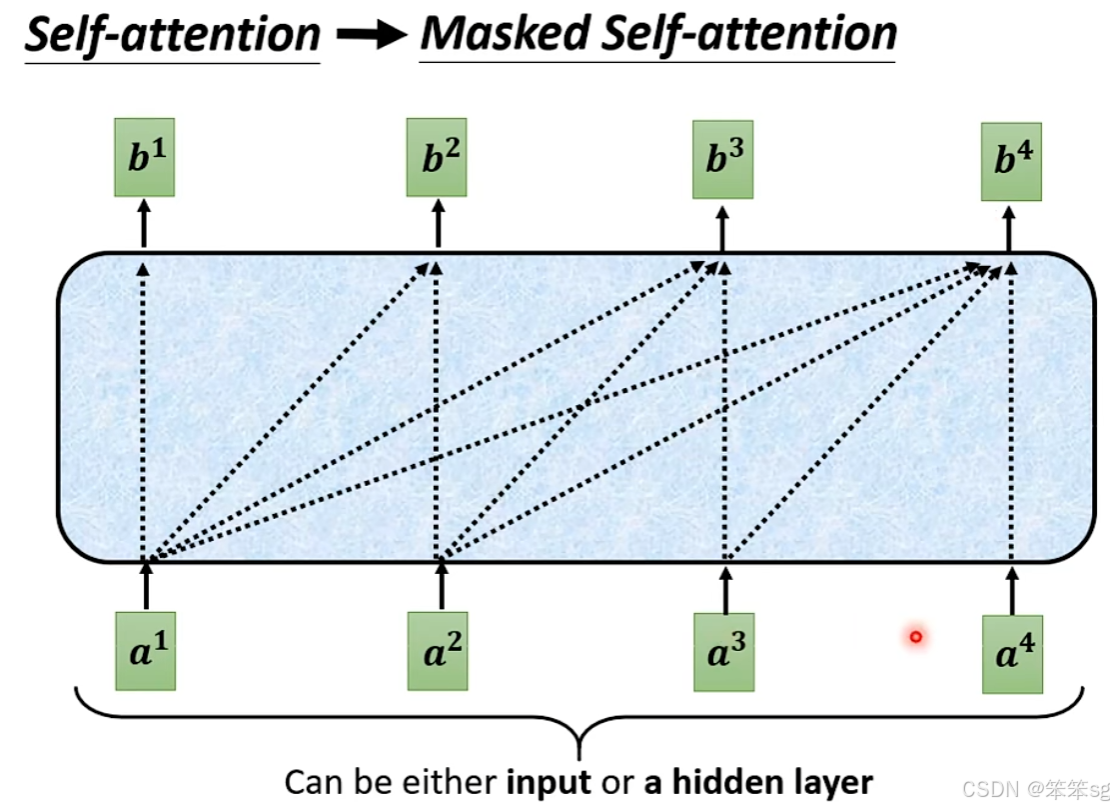
- 在 Transformer Decoder 中,Masked Self-Attention 是为了防止“泄露”未来信息。
- 举个例子,当我们生成第一个词时,我们可以考虑整个输入序列,但从第二个词开始,我们只能看到已经生成的词和输入序列的部分信息。也就是,当前的输出只能依赖于前面的词,无法看到后面的词。这确保了生成过程是 auto-regressive,每次只生成一个词。
3.6 输出序列长度的不确定性
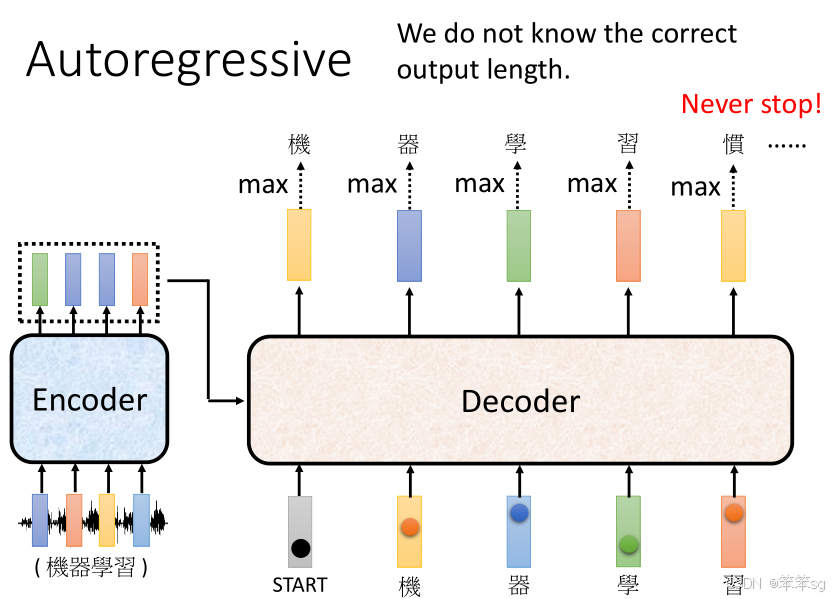
- Decoder 无法直接从输入序列的长度来决定输出序列的长度。
- 例如,在语音识别或机器翻译中,输入的长度(例如语音信号的向量序列)和输出的长度(例如翻译后的文本或语音识别结果的字符数量)并不总是成比例的。甚至有时,输出序列的长度可能长于输入序列,也可能短于输入序列。
- 例子:输入一段语音,可能输出的文字数量不确定,不是每次输入4个音频特征向量,就一定输出4个文字。
3.7 如何决定何时停止输出——引入“结束符号”(END)
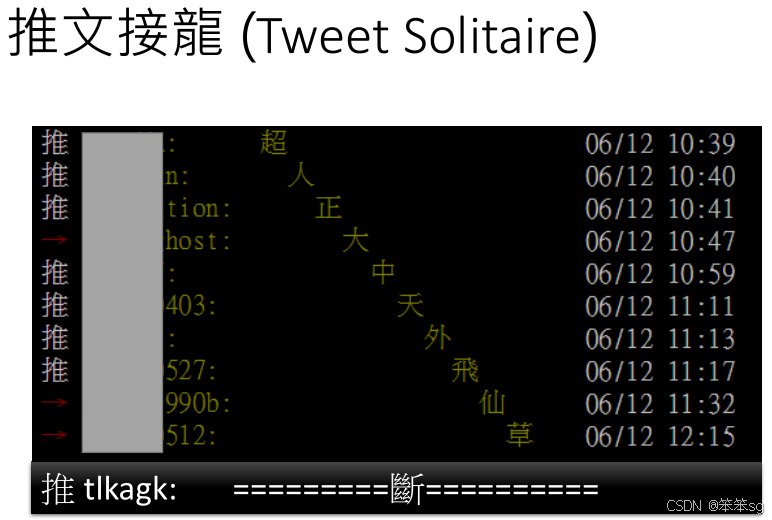
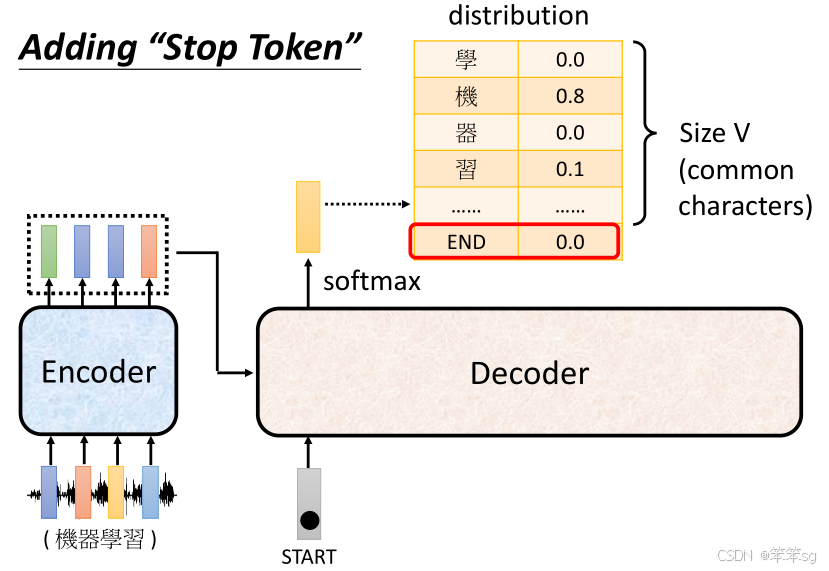
- 因为Decoder是逐步生成输出的,它会不断生成新的词,并将它们作为输入直到达到某个停止条件。在实际应用中,模型并不自然知道什么时候应该停止。
- 比如,生成文本时,Decoder会不停地生成新的词,直到最终会输出一个结束符号。
- 为了让生成过程停止,我们需要引入一个特殊的符号(END符号),表示生成的序列已经结束。
- 这个结束符号的作用就像你提到的 推文接龙,其中接龙会在某个节点上停止,类似的,Decoder也会在输出 END符号时停止生成。
- 举例:假设Decoder在产生了一些词后,输出了“机器学习”,然后它会继续接着生成,直到它输出一个特殊符号“END”表示整个序列的生成结束。
- 当Decoder的输出概率分布中,“END”符号的概率最大时,生成过程就会停止。
3.8 如何学习到“何时停止”:

- Decoder通过学习,理解何时应该输出 END 符号。当它生成了一个完整的语音识别结果或翻译句子时,END 符号就成为了最有可能输出的项,表示序列的结束。
- 比如,在语音辨识中,当Decoder生成了所有的文字后,继续生成的可能性会越来越小,直到它输出 END 符号,表示没有更多内容需要生成。
4 AT与NAT
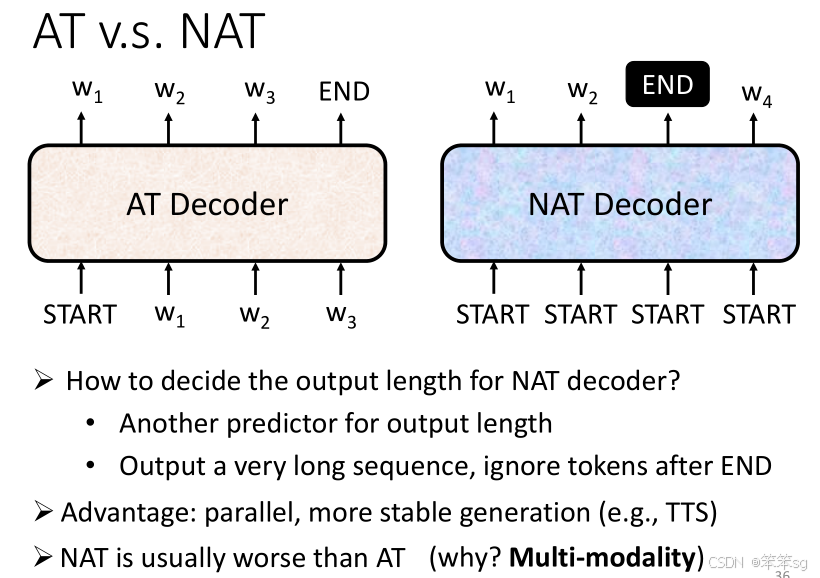
4.1 Auto-regressive Decoder (AT):
- 工作原理:AT的Decoder逐步生成输出,每次根据前一次的输出生成下一个词。例如:
- 输入 begin 符号。
- 生成第一个词 w₁。
- 将 w₁ 作为输入,生成下一个词 w₂。
- 一直重复,直到生成完整的序列。
- 特点:每次生成一个输出,依赖于之前的输出,逐步推进。这种方式会产生序列长短不一的输出。
- 缺点:生成过程是逐步的,计算时间较长,尤其是当输出的序列较长时。
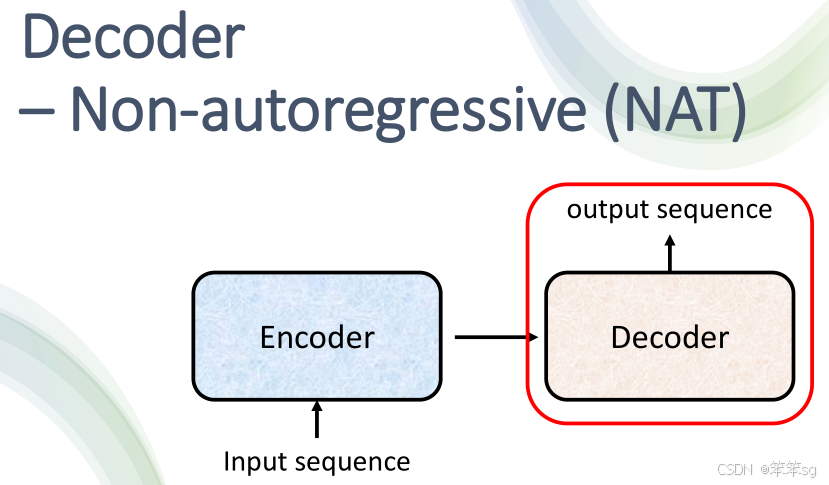
4.2 Non-Auto-regressive Decoder (NAT):
- 工作原理:NAT的Decoder在一次生成中,直接生成整个输出序列。例如:
- 输入一批 begin 符号(例如 4 个 begin 符号),一次性生成整个句子(例如4个中文字符)。
- 如何决定输出长度:NAT的Decoder输出长度的控制有两种方式:
- 使用一个额外的 classifier,它根据 Encoder 的输出决定Decoder的输出长度。比如,如果 classifier 输出4,则Decoder就生成4个中文字符。
- 假设一个最大输出长度(例如300个字符),给定固定数量的 begin 符号(例如300个 begin),然后根据 END 符号的位置决定实际的输出长度。
- 特点:
- 在一个步骤内生成整个输出序列,而不是逐步生成。
- 速度较快,因为不需要逐个生成词,可以并行化处理。
- 输出长度可以通过外部控制(如 classifier)进行调整。
4.3 NAT 的优势:
- 平行化:因为一次性生成整个序列,NAT可以并行化计算,而不像AT需要逐步生成。
- 输出长度的控制:通过 classifier,可以直接控制输出的长度。例如,在语音合成中,可以通过调整 classifier 的输出值来加快或减慢语音生成的速度。
4.4 NAT 的应用与问题:
- 语音合成:NAT模型在语音合成中应用广泛。比如 FastSpeech 就是一个基于NAT的语音合成模型,而 Tacotron 是基于AT的语音合成模型。
- 灵活性:NAT的模型可以通过改变 classifier 输出的数值来控制生成语音的快慢,从而获得更多的控制力。
- 性能问题:虽然NAT在速度上具有优势,但其性能通常不如AT。很多研究试图改进NAT的性能,使其更接近AT的效果。这通常需要引入很多技巧和策略。
4.5 为什么NAT是热门的研究主题:
- 平行化和控制输出长度的优势使得NAT成为当前研究的热点。尤其是在有了 Transformer 和 self-attention 机制之后,NAT的潜力得到了更大的发挥。
- 尽管如此,NAT的性能依然较AT差,而且优化NAT的性能通常需要很多技巧和细致的调优。

5 Cross Attention 机制:连接 Encoder 和 Decoder 的桥梁
5.1 Cross Attention 的概念
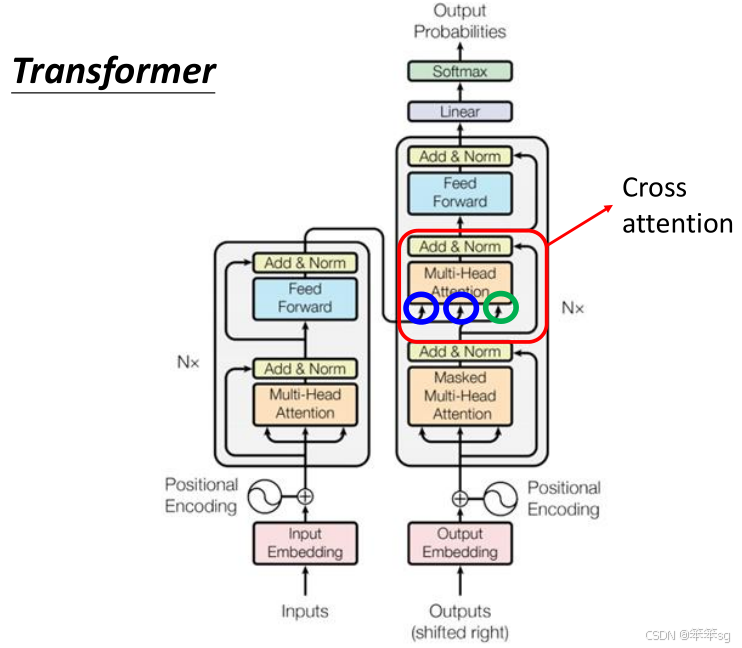
- Cross Attention 是连接 Encoder 和 Decoder 的核心机制。在 Transformer 中,Encoder 和 Decoder 通过 Cross Attention 进行信息交换,使得 Decoder 能够根据 Encoder 的输出生成序列。
- Cross Attention 的关键在于 Decoder 生成的 Query (Q) 与 Encoder 输出的 Key (K) 和 Value (V) 之间的交互。
- Q 来自 Decoder,K 和 V 来自 Encoder。通过计算 Q 和 K 的匹配程度 (Attention 分数),Decoder 可以聚焦于 Encoder 输出中最相关的信息,生成更精确的输出。
5.2 Cross Attention 的运作过程
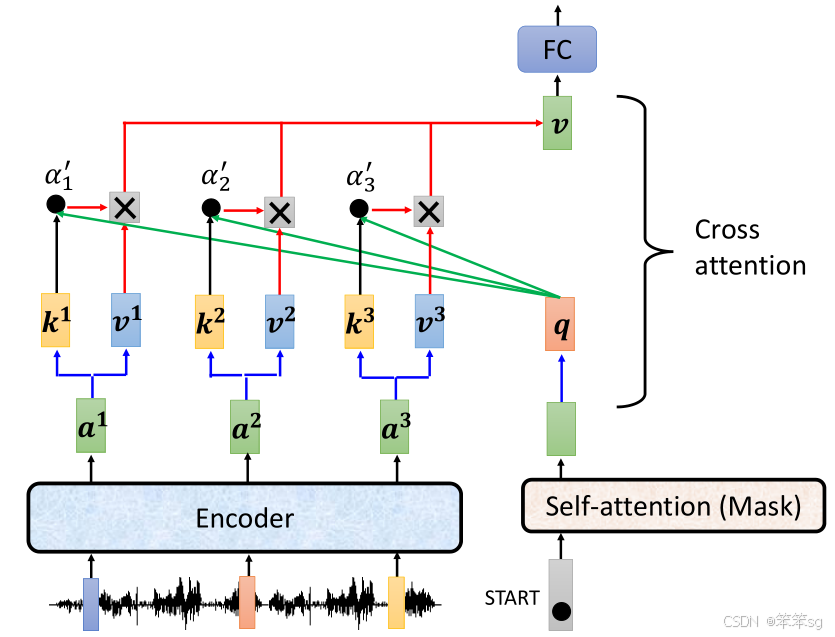
- Encoder 输入:Encoder 接收输入序列,将其转化为一组向量表示(例如 a1,a2,a3)。
- Decoder 输入:Decoder 输入一个特殊的 begin token,然后通过 Self Attention 生成一个向量。
- Q 的生成:Decoder 的 Self Attention 输出向量会经过一个线性变换,生成 Query (Q)。
- K 和 V 的生成:Encoder 输出的向量经过线性变换,分别生成 Key (K) 和 Value (V)。
- Attention 计算:
- 将 Q 与 K 进行点积,计算匹配度(Attention 分数)。
- 使用 softmax 归一化分数,得到 Alpha 权重。
- 将 Alpha 与 V 进行加权平均,得到加权后的信息
。
- 这一步完成后,Decoder 得到的信息将被传递给 Fully Connected Network 进行进一步处理。
5.3 Cross Attention 在 Decoder 中的作用
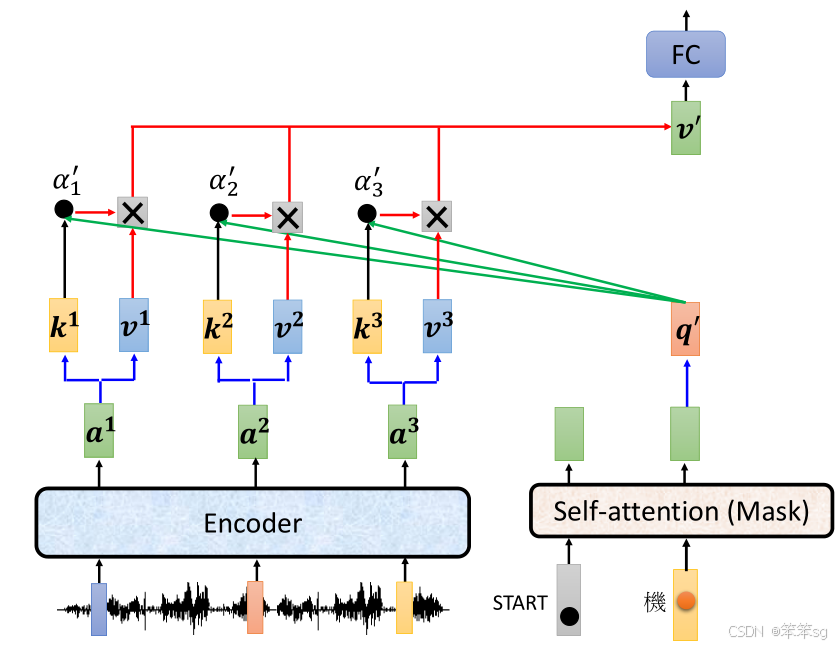
- 生成每个词的输入:在每次生成词时,Decoder 会使用 Cross Attention 来查找 Encoder 输出中与当前生成词相关的部分。例如,当生成一个词时,Decoder 会聚焦于 Encoder 输出中与当前词最相关的部分。
- 输出生成:通过 Cross Attention,Decoder 可以综合 Encoder 中的信息,逐步生成目标序列。
5.4 实际案例:语音识别中的 Cross Attention
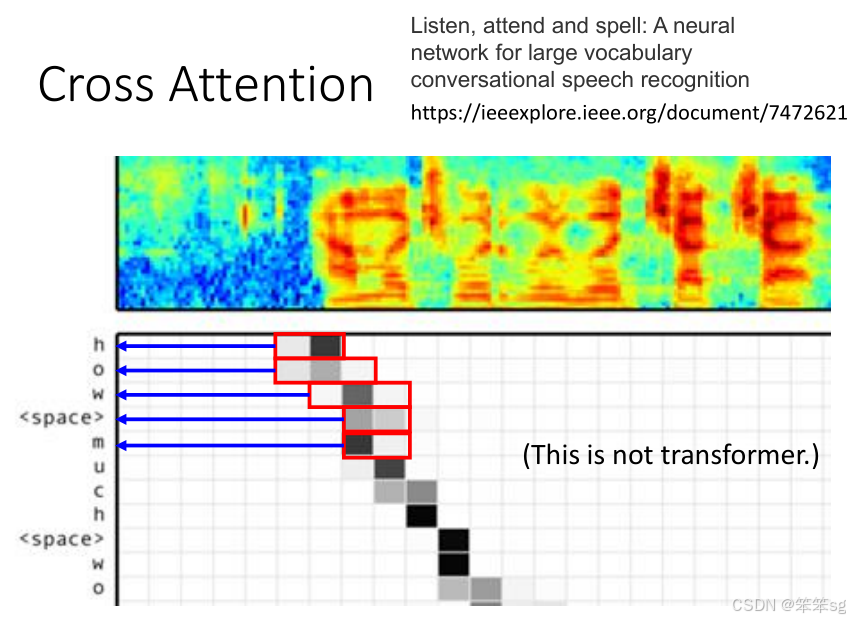
- 在语音识别任务中,使用 Sequence-to-Sequence 模型可以将语音信号转化为文本。这里,Encoder 接收音频信号的向量表示,而 Decoder 则逐个字母地生成输出(例如 "h", "o", "w")。
- Listen, Attend and Spell 是一个经典的语音识别模型,它使用了 Cross Attention 来结合音频信号和生成的文本。
- Attention 分数:每个输出字母生成时,Decoder 会通过 Cross Attention 将自己聚焦于 Encoder 的输出部分。例如,当生成字母 "H" 时,Decoder 会关注 Encoder 中与 "H" 相关的音频信号部分,生成字母 "H";接着生成 "O",并再次通过 Cross Attention 聚焦于相关部分。
5.5 Cross Attention 的可扩展性
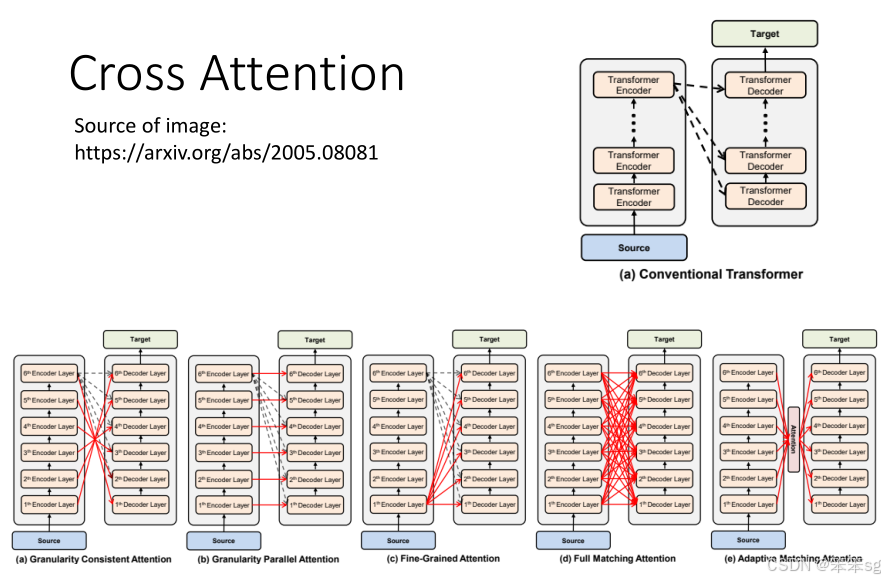
- 多层 Encoder 和 Decoder:虽然在原始的Transformer模型中,多层Decoder中每层都只使用 Encoder 最后一层的输出作为信息来源,但也可以探索更复杂的连接方式。研究者已经提出了不同的 Cross Attention 策略,允许 Decoder 的每一层使用 Encoder 的不同层输出。
- 例如,某些研究尝试让 Decoder 的每一层分别关注 Encoder 中不同层的输出,甚至不依赖于 Encoder 最后一层。
5.6 Encoder和Decoder的输入各是什么?
-
Encoder的输出:Encoder处理输入序列(如一句话),并生成一系列的上下文向量,这些向量包含了输入序列的语义信息。
-
Decoder的输入:通常Decoder的输入会包含:
- 开始标记(Begin token):通常是一个特殊的标记(比如
<s>或[START]),表示序列的开始。这个标记会作为Decoder的第一个输入。 - 已经生成的词:对于生成任务,Decoder会逐步生成输出序列中的每个单词。在生成每个新单词时,Decoder会将前一步生成的单词作为输入。比如,第一步是
<s>,第二步是输出的第一个单词,第三步是输出的第一个和第二个单词作为输入,依此类推。
- 开始标记(Begin token):通常是一个特殊的标记(比如
6 训练
好了,上面我们讲的那些都是Transformer在推理时做的一些事情,那么Transformer训练时具体是如何做的呢?
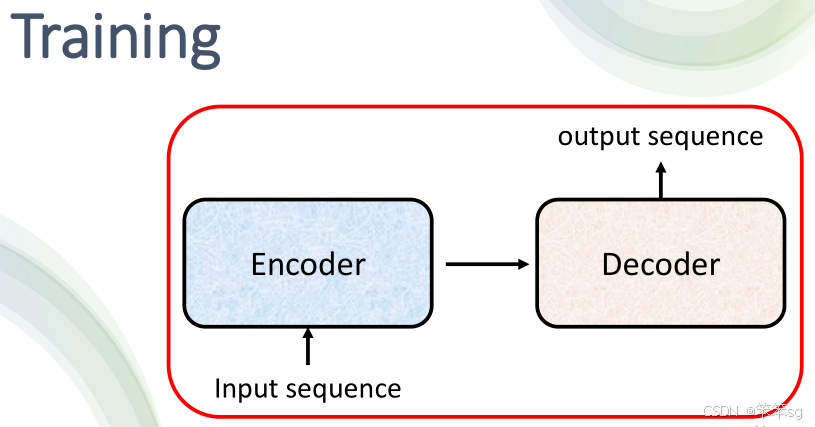
6.1 训练阶段
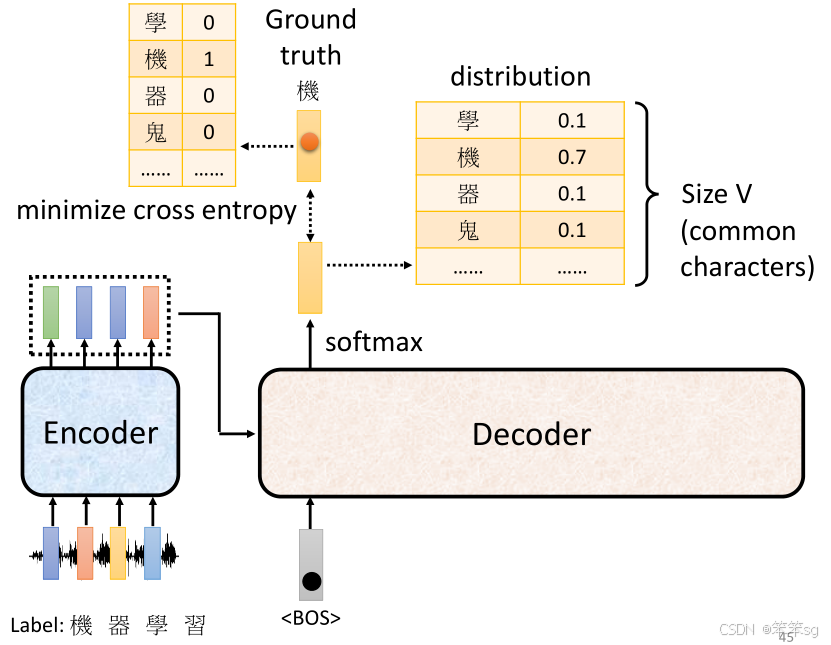
在训练阶段,我们给Decoder提供正确答案,这就是所谓的“Teacher Forcing”技术。具体来说:
-
输入:我们将正确的目标序列作为Decoder的输入。例如,在语音识别任务中,给定声音信号,假设正确的输出是“机器学习”,我们将这四个字的one-hot向量作为Decoder的输入。这样Decoder会逐步生成“机器学习”中的每一个字。
-
输出:Decoder的目标是生成与正确答案尽量匹配的概率分布。例如,如果Decoder当前输出的是“机”,那么我们希望它的概率分布集中在“机”这个字上,其他字的概率接近零。这通过计算Decoder输出的概率分布与正确的one-hot向量之间的cross-entropy loss来衡量。
-
Loss计算:每次输出都会有一个cross-entropy loss(交叉熵损失),这是衡量预测分布与真实标签分布之间差异的标准。最终,训练目标是最小化所有时间步的交叉熵损失的总和,使得模型输出尽可能接近正确的标签。
6.2 Teacher Forcing
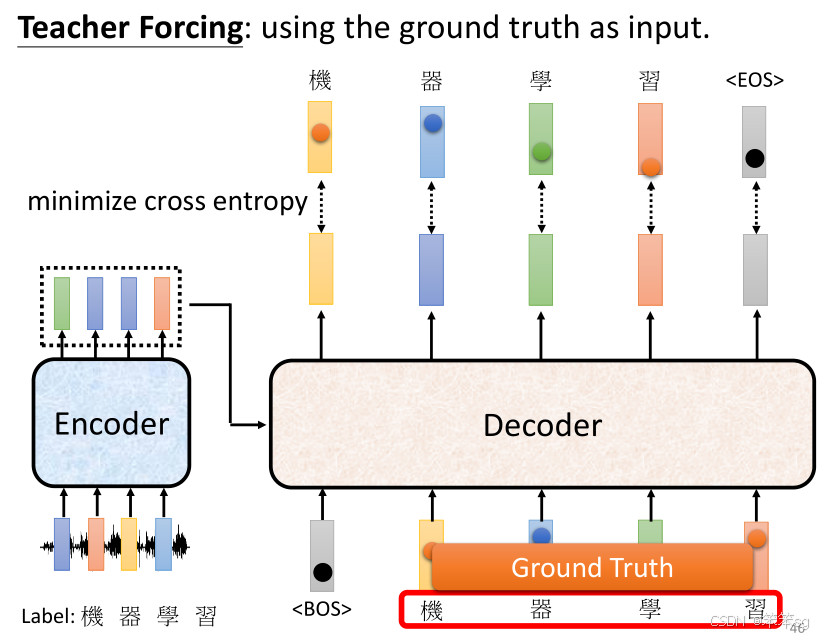
“Teacher Forcing”是指在训练时,Decoder的每一步输入是前一步的正确答案,而不是模型自己生成的答案。简单来说,假设在生成第一个字时我们输入begin,生成第二个字时输入的是第一个正确的字(比如机),生成第三个字时输入的是第二个正确字(比如器),如此类推。
-
优点:Teacher Forcing能加速训练过程,因为每一步的预测都是基于正确的历史信息,可以减少错误积累。
-
缺点:在测试阶段,模型并不能接收到真实的目标序列,而是依赖自己生成的部分输入。如果模型在测试时生成的词汇与正确词汇差距较大,这种积累的错误可能会导致后续预测也变得不准确。这就引出了训练和测试阶段的“mismatch”。
6.3 测试阶段的问题
在测试阶段,模型并不会再有正确答案作为输入,它只能基于自己的输出进行预测。例如,在生成第一个字时,输入是begin,但生成后,第二步的输入就变成了模型自己预测的第一个字,而不是实际的正确字。
这就带来了训练阶段与测试阶段的差异,即exposure bias(暴露偏差),模型在训练时依赖于正确答案,而在测试时依赖自己的输出,这种差异可能导致性能下降。
6.4 解决办法
为了解决这种问题,通常有以下几种方法:
-
Scheduled Sampling:在训练过程中,不是每次都给Decoder提供正确的答案,而是按一定的概率让Decoder自己生成输入。这可以逐步让模型适应在测试时使用自己的输出。
-
Reinforcement Learning(RL):使用强化学习来训练模型,通过奖励机制调整模型生成的序列。这个方法在一些任务中(如机器翻译)得到应用,但通常需要额外的训练成本。
-
Beam Search:在测试阶段使用beam search等解码策略,通过生成多个候选序列并选择最优的输出。这能够减轻模型在逐步生成过程中因错误预测导致的连锁反应。
-
Teacher Forcing与Sampling结合:在训练阶段使用teacher forcing,逐步过渡到使用自己的输出,直到模型能够在没有真实标签的情况下生成合理的输出。
7 复制机制(Copy Mechanism)
7.1 复制机制的原理
复制机制的基本思想是,Decoder不仅可以生成新的词汇,还能够从输入序列中复制部分信息。具体来说,对于每个时间步,模型都会在两个选择之间做出决定:
- 生成一个新的词汇(通过模型的输出分布)。
- 复制输入中的某个词汇(基于输入序列中的某些位置)。
在很多实际任务中,生成模型不仅要产生新的词汇,还要能够直接引用或复制输入中的词汇。这个机制可以通过Pointer Network(指针网络)和后来的Copy Network实现。
7.2 应用场景
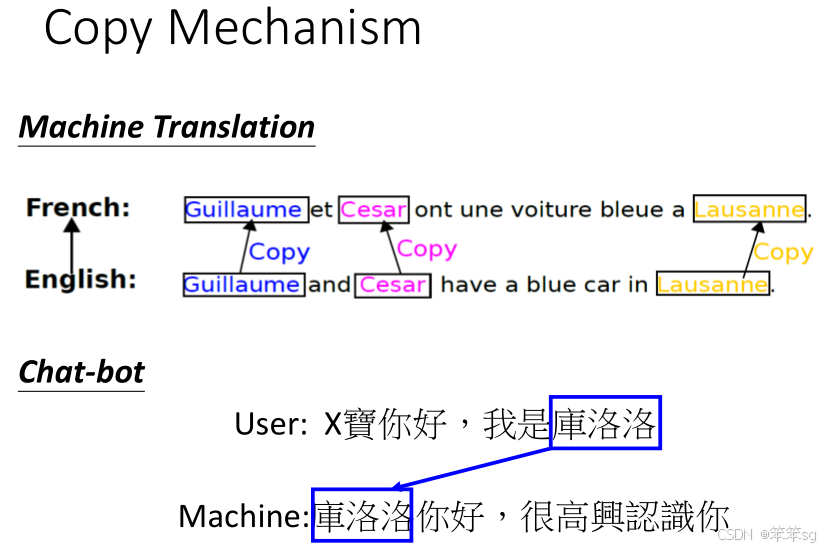
复制机制在以下几种任务中尤为重要:
-
对话生成(Dialogue Generation):在对话生成中,模型需要从用户的输入中复制特定的名称、地点或其他实体。例如,假设用户输入“你好,我是库洛洛”,模型的任务是生成“库洛洛你好,很高兴认识你”。此时,模型不需要创造“库洛洛”这个词,而是应该能够从输入中直接复制它。
-
文本摘要(Text Summarization):在文本摘要任务中,模型需要从长篇文章中提取关键信息并生成简短的摘要。在这种任务中,许多重要词汇和句子往往可以直接复制,而不需要重新生成。比如,在一篇新闻文章中,模型可能会直接复制文章中的标题或某些关键句子作为摘要的一部分。
-
机器翻译(Machine Translation):在翻译任务中,尤其是对于一些低资源语言对,模型可能会遇到一些不常见的词汇,复制输入语言中的词汇可能比生成新词更有效。
7.3 Pointer Network 和 Copy Mechanism
最早引入复制机制的模型是Pointer Network。Pointer Network允许模型在解码时选择输入序列中的某个位置,并将其“复制”到输出中。这种机制特别适用于任务中存在部分重复内容的情况,例如序列排序、图形结构数据等。
随后,Copy Mechanism被引入到Seq2Seq模型中,结合了Pointer Network和传统的Seq2Seq结构。Copy Mechanism通过为每个输出位置引入一个复制概率(copy probability)来决定是生成一个新词,还是复制输入中的某个词。
7.4 如何实现Copy Mechanism?
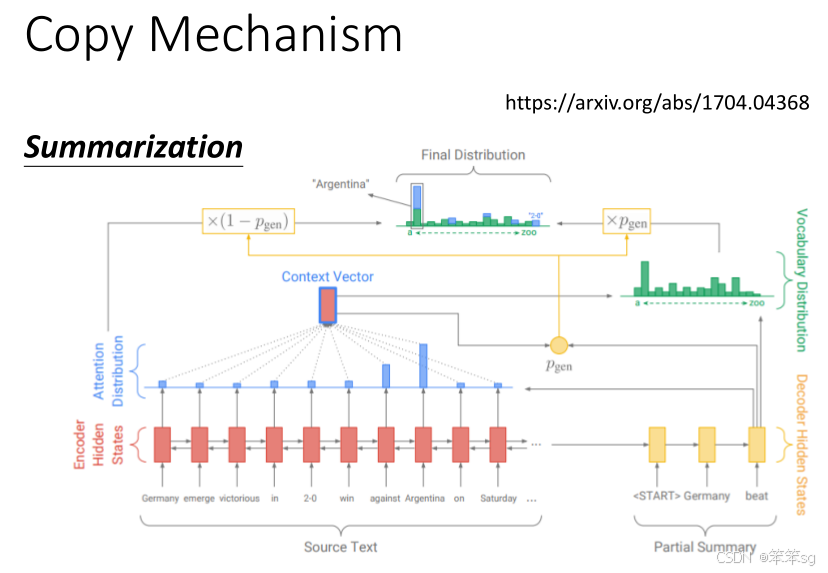
Copy Mechanism通常会通过以下几步来实现:
-
生成概率(Generation Probability):传统的Seq2Seq模型为Decoder的每个时间步生成一个词汇的概率分布。
-
复制概率(Copy Probability):在复制机制中,模型同时生成一个“复制概率”,表示当前词汇是否应该从输入中复制。复制概率通常通过一个额外的神经网络层来计算,结合了输入和Decoder的上下文信息。
-
最终输出:最终的输出概率是由生成概率和复制概率加权得到的。如果复制概率高,模型会从输入中选择一个词汇;如果生成概率高,模型会生成一个新的词汇。
这种机制可以通过引入一个注意力机制(Attention Mechanism)来帮助模型选择输入序列中的哪个部分进行复制。
7.4 Copy Mechanism的优点
-
减少生成错误:特别在对话生成中,模型如果没有复制机制,可能会创造出不相关或无法理解的词汇,而复制机制可以避免这个问题。
-
提高准确性:在像文本摘要、机器翻译等任务中,复制机制可以帮助模型保留输入中的重要信息,避免遗漏。
-
提高训练效率:在某些任务中(比如文章摘要或实体识别),模型直接从输入中复制词汇可以减少需要生成新词的复杂度,从而提高训练效率。
7.5 挑战与解决方案
尽管复制机制在许多任务中表现优秀,但也面临一些挑战:
-
长期依赖问题:模型可能难以记住输入序列中长距离的依赖关系,导致复制的准确性下降。
-
训练数据不平衡:如果训练数据中,生成的新词和复制的词汇不平衡,可能会导致模型偏向某一类输出,影响生成质量。
为了解决这些问题,通常会结合其他技术,如强化学习(Reinforcement Learning)来进一步优化复制策略,或者使用更复杂的双向注意力机制来增强模型的上下文理解能力。

8 guided attention(引导注意力机制)
8.1 Seq2Seq模型在语音合成中的问题

在你提到的例子中,机器在语音合成时能够正确地合成多次“发财”这个词,但在合成单次“发财”时却遗漏了“发”字,只有“财”。这类错误通常是由于训练数据的稀缺性或模型未能完全学习到如何处理某些边缘情况导致的。虽然Seq2Seq模型非常强大,但它还是容易在某些特定的情境下出错,尤其是当输入序列很短或训练数据中缺乏这些极端案例时,模型可能会“遗忘”部分信息或没有正确地生成全部输出。
8.2 为什么会出现这种错误?
这种情况往往与以下几个因素有关:
-
训练数据分布问题:如果在训练数据中,类似“发财”这种较短的句子出现的频率很低,模型就可能没有学会如何处理它。尤其是对于非常短的序列,模型可能更倾向于生成重复的模式,或者在生成时忽略某些输入信息。
-
模型理解能力的局限性:Seq2Seq模型,尤其是没有加入专门机制的模型,可能并没有足够的能力来理解每个输入的细节。例如,在语音合成任务中,模型可能会在生成过程中依赖“模式化”的输出,而不是精确地反映输入的每一个部分。
8.3 如何解决这个问题?
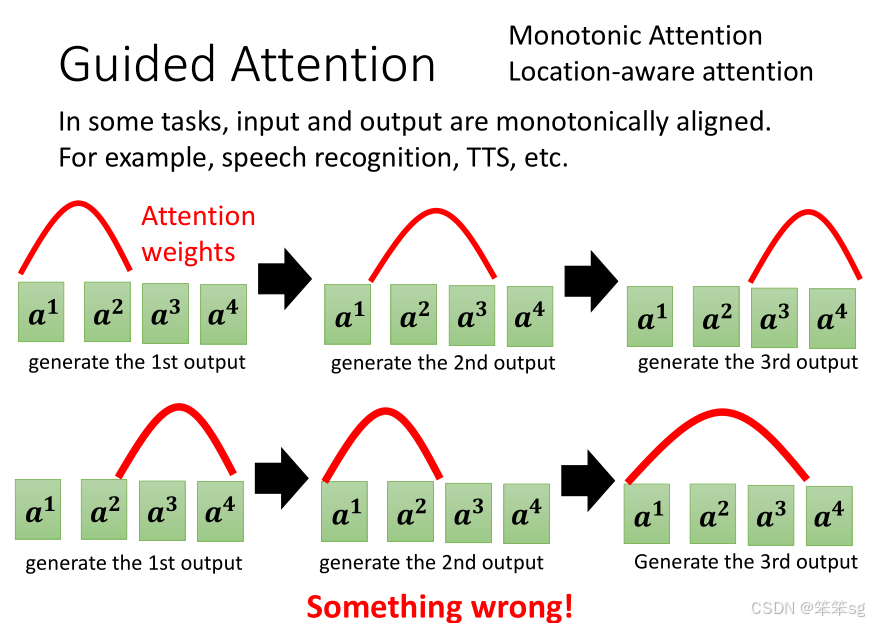
为了避免模型出现这种低级错误,尤其是在需要精确生成输入内容的任务中(如语音合成、语音识别等),我们可以引入guided attention来控制模型的注意力机制,使其能够正确地关注输入的各个部分。
-
Attention机制的作用:在Seq2Seq模型中,Attention机制允许Decoder在每个时间步动态地选择输入序列中的某个位置,以便生成当前输出的最相关部分。这种机制是Seq2Seq模型的核心,使其可以处理长距离的依赖关系。
-
问题的所在:但是,标准的Attention机制并不总是能够确保模型在生成时按顺序关注输入序列的每个部分。特别是在语音合成(TTS)任务中,模型可能会在生成声音时出现“注意力错乱”的情况——例如,模型在合成时忽视了输入序列的某个部分。
-
Guided Attention的解决方案:Guided Attention通过强制模型在生成过程中遵循一个固定的注意力顺序,来避免这种问题。在语音合成中,我们可以强制模型从左到右地关注输入句子的每个部分,确保它在生成每个音素时,依照输入的顺序生成声音。
8.4 Location-aware Attention(位置感知注意力)
这种机制有时被称为Location-aware Attention,它会在训练过程中引导模型的注意力,以确保在生成过程中模型不会“跳跃”或“乱序”地访问输入序列。这种方法常用于语音合成任务中,因为语音合成要求模型生成的音频与输入文本一一对应。
例如,在语音合成中,Location-aware Attention会确保每个字或词的发音都对应到输入文本中的正确位置,而不会让模型随机选择输入序列中的某个位置进行“跳跃”,从而避免产生不准确的音频输出。
实现这种Guided Attention的方法包括:
-
限制Attention权重:在训练时,对注意力权重施加约束,使其只关注输入序列中的特定位置。比如,可以使用正则化方法来迫使注意力机制在生成时遵循某种“顺序”模式。
-
位置编码(Positional Encoding):通过对输入序列进行位置编码,确保模型理解每个元素的位置,尤其是在生成时,可以更好地捕捉到顺序关系。这在Transformer模型中尤其重要。
-
强化学习(Reinforcement Learning):通过强化学习的方法,可以进一步调节Attention机制的表现,确保它在不同任务中能够得到适当的引导。
9 Beam Search(集束搜索)
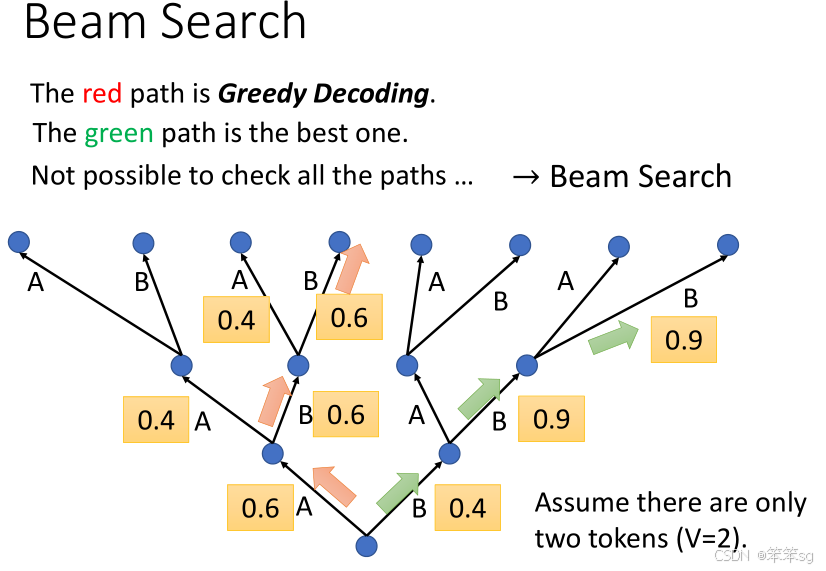
9.1 Beam Search的基本原理
在序列到序列(Seq2Seq)模型中,Decoder每一步都会选择一个输出词汇(token)。Greedy Decoding(贪心解码)是最简单的方法,就是每一步选择概率最大的词汇作为输出。但Greedy解码虽然简单,但可能会错过一些潜在的更好路径,因为它总是选择当前最优的词汇,而没有考虑未来可能的后果。
Beam Search的核心思想是,在每一步生成过程中,不只考虑当前最优的选择,而是保留多个候选项(即多个路径)。具体来说,Beam Search会在每一步的k个最有可能的输出中继续生成下一个输出,直到达到终止条件。这里的k称为“beam width”(宽度),表示每次保留的候选路径的数量。
举个例子:
假设你有两个可能的输出A和B,每个输出都有一个概率分数。Greedy解码会选择最大概率的输出,而Beam Search会保留多个候选(比如,k=2时,会保留两个最优的输出候选)。这种方式可以避免单一选择带来的问题。
9.2 Greedy Decoding vs. Beam Search
-
Greedy Decoding:每一步都选择分数最高的词汇输出。这种方式简单,但可能导致生成的序列不够多样化,尤其是在生成长序列时,容易陷入局部最优,错过全局最优。
-
Beam Search:每一步都保留多个最优路径,综合考虑未来的生成结果,能够探索更多的可能性。尽管它可能增加计算开销,但通常能得到比Greedy解码更好的结果,尤其是在复杂的生成任务中。
9.3 Beam Search的优缺点
优点:
- 更全面的探索:通过保留多个路径,Beam Search可以避免Greedy解码中的局部最优解,能够生成更多样化的输出。
- 适用于确定性任务:对于一些答案比较明确的任务,比如语音识别、机器翻译等,Beam Search能有效地找到最优的输出序列。
缺点:
- 计算开销大:随着beam width的增大,Beam Search需要的计算量和内存消耗也会显著增加,尤其是在长序列生成时,计算开销会非常高。
- 可能导致重复或死循环:如你所提到的,在一些生成任务中,Beam Search可能会导致生成的文本重复或进入死循环,尤其是在某些文本生成任务中,模型可能会过度依赖高频词汇,产生冗余的输出。
- 对创造性任务不一定有效:对于需要更多创造力的任务,比如句子补全(sentence completion)或文本生成,Beam Search的效果并不总是最佳。因为它更倾向于优化准确性和确定性,而对于这些任务来说,加入一些随机性可能能产生更加多样化和富有创造性的结果。
9.4 Beam Search的改进
-
Randomness(随机性):对于一些创意性较强的任务,比如生成文章、故事等,加入一定的随机性可能更有利。例如,使用温度控制(temperature sampling)或Top-k sampling等技术,可以使生成的文本更具多样性,避免模型总是选择最常见的输出。
-
Length Normalization:为了避免Beam Search倾向于生成较短的序列,可以使用长度归一化(length normalization)来调整生成的序列长度,避免因为序列短而不自然地结束。
-
Diverse Beam Search:一种新的方法,通过引入多样性损失函数,旨在生成更多样化的候选路径,避免模型生成过于单一的文本。
9.5 应用场景
-
需要明确答案的任务:对于一些确定性任务,比如语音识别,或者机器翻译等,Beam Search通常能取得较好的效果,因为这些任务的目标是生成唯一的正确答案。Beam Search能够有效探索生成序列的多个路径,找到最优解。
-
需要创造性和多样性的任务:对于一些创造性任务,如文本生成、句子补全,单纯使用Beam Search可能会导致模型过于保守,生成单一的文本。此时,可以考虑引入随机性或Top-k采样,让模型有更多的探索空间,生成更加丰富和多样的内容。
10 TTS中的随机性:为什么加入噪声?
在很多机器学习任务中,尤其是训练阶段,噪声(noise)或随机性的加入是为了避免过拟合和增强模型的鲁棒性。常见的做法如Dropout或数据增强,这些技术可以使模型在面对未见过的样本时表现更好。然而,在TTS测试阶段加入噪声,也能起到不错的效果。

对于语音合成任务来说,特别是在使用深度神经网络(如基于Sequence-to-Sequence模型的TTS系统)时,测试时加入一定的噪声或随机性,能够帮助模型生成更自然、流畅的声音。直观地讲,声音合成的过程不仅仅是字面上的“发音”,它还需要考虑语调、情感和细微的发音差异。
10.1 为什么在测试时加入噪声能帮助TTS?
-
模拟自然语音的变化: 人类的语音充满了细微的变化和自然的波动。即使是同一个词汇,人在不同情境下、不同情感下说出来的声音都会有微小差别。这种差异正是使语音听起来有生命、有个性、且不死板的原因。
如果你让TTS模型在没有任何噪声的情况下生成语音,生成的语音会显得非常机械化、重复,甚至可能缺乏语调变化和情感色彩。因此,加入适量的噪声可以模拟这种自然变化,使得生成的语音更加丰富和生动。
-
防止过于刻板的输出: 没有噪声的生成往往导致过于一致的输出,这种一致性可能让生成的语音听起来更像机器人。通过适当的噪声,模型可以避免每次都生成相同的声音,从而增加语音的多样性。这也使得每次生成的语音听起来不那么死板,能够更好地适应不同的语境。
-
帮助模型探索更自然的输出: 在TTS的训练过程中,模型学习到的是一组非常强烈的特征和规则,指示它应该如何产生合成语音。但这种训练也可能导致它在测试时局限于某些“固定的”模式。在测试时加入噪声,可以促使模型探索更多样化的输出,找到那些可能更接近真实语音的方式。
10.2 TTS中的Decoder和随机性
在TTS中,Decoder的角色非常重要,因为它负责将文本序列转换为语音序列。而且,TTS的模型通常是基于Sequence-to-Sequence架构的,这种架构将每个输入的文本映射到对应的音频信号。这个过程中,Decoder的输出不仅仅是一个简单的符号,它还涉及到如何生成自然流畅的语音。
10.3 为什么对TTS任务引入随机性能够提高质量?
-
语音中的细节与变化:语音合成中的细节,如语气、停顿、音调变化,都不是单纯按照最优路径生成的。这些细节对于让机器的语音听起来更像人类的语音至关重要。
-
语调和情感:如你所提到的,语音合成的过程中加入一些噪声或随机性,可以帮助模型在情感表达和语调的变化上做得更好,避免过于生硬的“机械感”。这种随机性使得语音的情感色彩和语气变化更加自然。
-
避免机器重复性:如果Decoder始终选择“最优”路径,模型可能会陷入一种“固定模式”,始终生成同样的语音输出,而不是应变于不同情境。这种过度确定性会导致听起来非常刻板、不生动。适当引入随机性能打破这种局限,让语音输出更具人性化。
11 为什么Cross Entropy无法直接优化BLEU Score?
训练过程中使用的是Cross Entropy作为损失函数(Loss),但评估时使用的是BLEU Score。这两者并不是完全对应的优化目标,Cross Entropy优化的是每一个单独的词的概率分布,而BLEU Score是基于整个句子对比的评价指标。这意味着,虽然我们在训练时最小化了Cross Entropy,但是这不一定能最大化BLEU Score。
- Cross Entropy: 是基于每个词预测的对数似然(log-likelihood),通过最大化每个词的正确性来最小化损失。
- BLEU Score: 是一个基于n-gram(例如2-gram,3-gram等)的匹配度,衡量生成文本与参考文本之间的相似度。
尽管Cross Entropy能有效地训练出一个词语级别准确的模型,但它并不一定能优化句子层面的质量(即BLEU Score),这就是为什么训练时需要用Cross Entropy,而评估时要用BLEU Score。
12 能否在训练时直接优化BLEU Score?
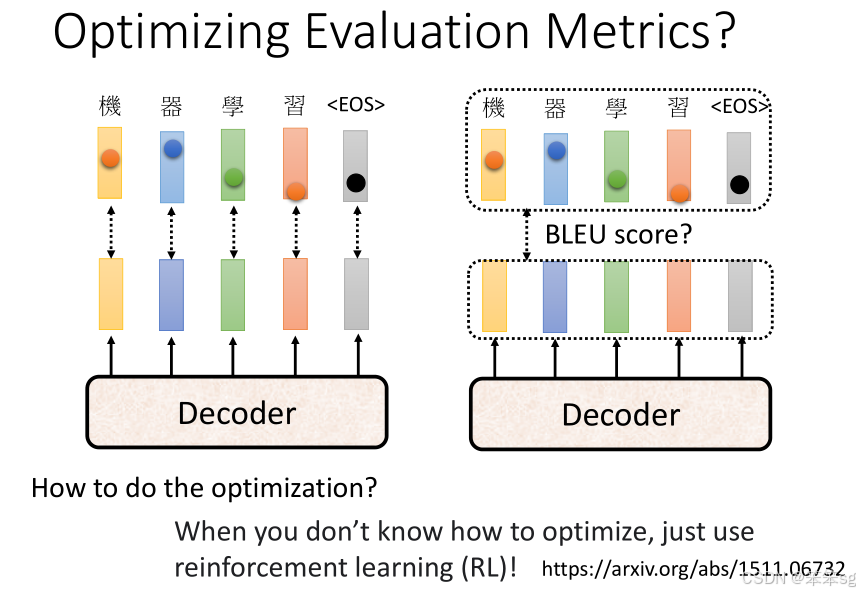
理论上,我们可以尝试通过强化学习(Reinforcement Learning, RL)来优化BLEU Score。你可以将生成任务视为一个强化学习问题,在这种框架下:
- Agent(模型的Decoder)在每一步生成一个词,并根据最终生成的句子得到一个奖励(Reward)。
- 这个奖励可以基于BLEU Score进行计算,鼓励模型生成更符合参考答案的句子。
然而,直接使用BLEU Score作为损失函数来训练模型有一个问题:BLEU Score是一个离散的指标,并且不可微分(non-differentiable),所以不能直接用于标准的梯度下降算法。为了解决这个问题,一些方法如Policy Gradient和REINFORCE被提出,它们通过蒙特卡洛采样估计奖励并进行优化,但这种方法的训练通常较为复杂。
13 训练与评估指标的不一致 (Exposure Bias),如何解决?
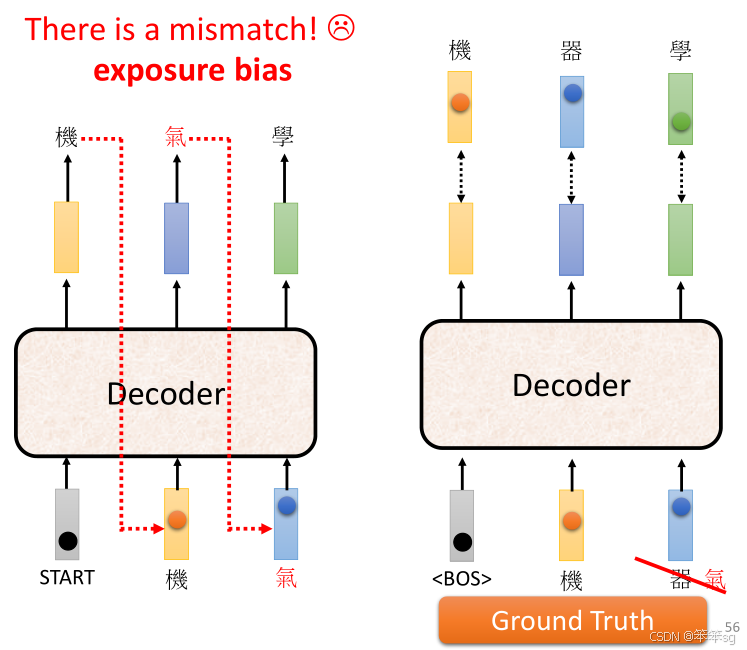
在训练过程中,模型每次都会看到正确的词语,而在测试时,模型的输入可能包含错误的输出。这种不一致性导致了Exposure Bias问题,具体来说,就是在测试时,Decoder会看到自己错误生成的词汇,并基于这些错误继续生成后续的内容,形成恶性循环。这个问题常常会导致在实际应用中,模型表现不好。
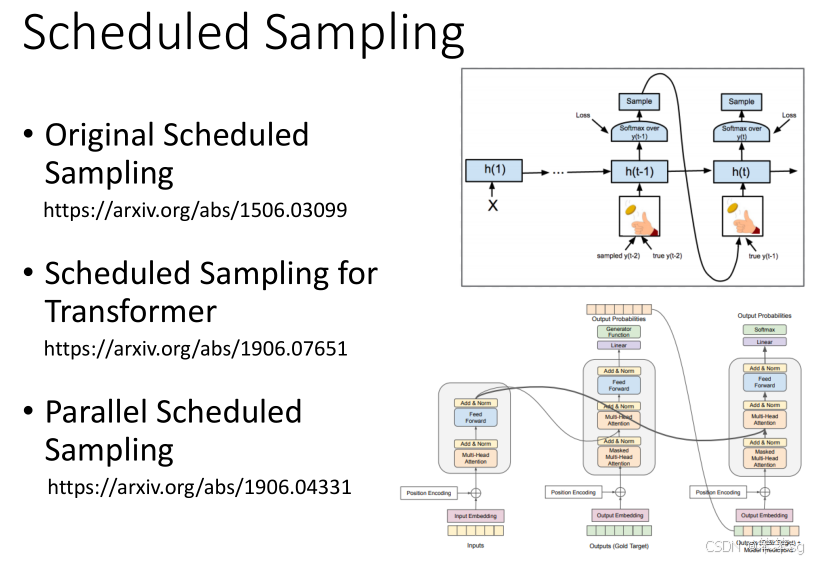
解决方案之一就是采用Scheduled Sampling。这是一种在训练阶段逐步引入错误信息的策略,目的是让模型在训练时不仅看到正确的序列,也能学会处理一些错误的序列,从而更好地应对测试时的错误输入。(即每次给模型提供的输入不完全是正确的,而是通过模型当前的输出加上一些“随机性”,让模型逐渐适应生成错误序列的情况。)
14 总结
李宏毅老师对Transformer的讲解主要集中于宏观的框架上以及训练时的一些tips,但对于具体的注意力机制以及q、k、v之类的含义可能没有进行解释。如果想要深入了解可以参见我“0 完整章节内容”提到的笔记。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









