







目录
2.1.1 基于响应的知识(Response-based Knowledge)
2.1.2 基于特征的知识(Feature-based Knowledge)
2.1.3. 基于关系的知识(Relation-based Knowledge)
2.2.1 离线蒸馏(Offline Distillation)
2.2.2 在线蒸馏(Online Distillation)
0 前言:
随着大规模机器学习和深度学习模型的普及,类似 GPT-3 这样的大模型变得越来越常见。GPT-3 是一个包含 1750 亿参数的模型,训练数据量达到了 570 GB 的文本。然而,虽然训练大模型能够提升当前技术的性能上限,但将这样笨重的模型部署到边缘设备上却并非易事。
此外,数据科学建模工作的大部分重点往往是训练一个大型模型或不同模型的集成,以便在独立的验证集上表现良好。然而,这些验证集通常无法代表真实世界的数据分布。
训练目标与测试目标之间的这种差异,导致了机器学习模型在精心策划的验证数据集上能取得较高的准确率,但在面对真实世界的测试数据时,往往无法达到性能、延迟和吞吐量的预期要求。
知识蒸馏是一种有效的解决方案,它通过捕获并“蒸馏”复杂机器学习模型或模型集成中的知识,将其转移到一个更小的单模型中,从而显著降低部署难度,并且不会造成明显的性能损失。
在本篇博客中,我将:
- 详细描述知识蒸馏的概念、其基本原理、训练方案以及相关算法;
- 深入探讨知识蒸馏在图像、文本和音频领域的深度学习应用。
1 什么是知识蒸馏?
知识蒸馏指的是将大型复杂模型或模型集中的知识转移到一个更小的单一模型中的过程,这种小模型可以在真实世界的约束条件下实际部署。本质上,知识蒸馏是一种模型压缩方法,由 Bucilua 等人在 2006 年首次成功提出。
知识蒸馏通常用于与复杂架构相关的神经网络模型,这些模型包括多个层和大量参数。因此,随着过去十年深度学习的兴起,以及其在语音识别、图像识别和自然语言处理等多领域的成功,知识蒸馏技术在实际应用中变得越来越重要。
部署大型深度神经网络模型的挑战在于,边缘设备通常具有有限的内存和计算能力。为了解决这一问题,研究者们首先提出了一种模型压缩方法,即通过将大型模型的知识转移到较小模型的训练中来实现模型的缩小,而不显著损失性能。这种从大模型学习小模型的过程,后来由 Hinton 等人正式定义为“知识蒸馏”框架。
如下图所示,在知识蒸馏过程中,一个较小的“学生”模型通过学习模仿较大的“教师”模型,并利用教师模型的知识来获得与之相近甚至更高的准确率。在下一节中,我将深入探讨知识蒸馏框架及其底层架构和机制。

2 深入探讨知识蒸馏
知识蒸馏系统由三个主要组成部分构成:知识、蒸馏算法和教师-学生架构。
2.1 知识
在神经网络中,知识通常是指学习到的权重和偏置。同时,大型深度神经网络中还存在丰富多样的知识来源。典型的知识蒸馏方法使用模型输出(logits)作为教师知识的来源,而其他方法则关注中间层的权重或激活值。此外,还有其他类型的相关知识,例如不同类型激活值和神经元之间的关系,或教师模型本身的参数。
这些不同形式的知识可分为以下三类:
- 基于响应的知识(Response-based knowledge)
- 基于特征的知识(Feature-based knowledge)
- 基于关系的知识(Relation-based knowledge)
下图展示了教师模型中这三种不同类型的知识。在接下来的部分中,我将详细讨论这些不同的知识来源。
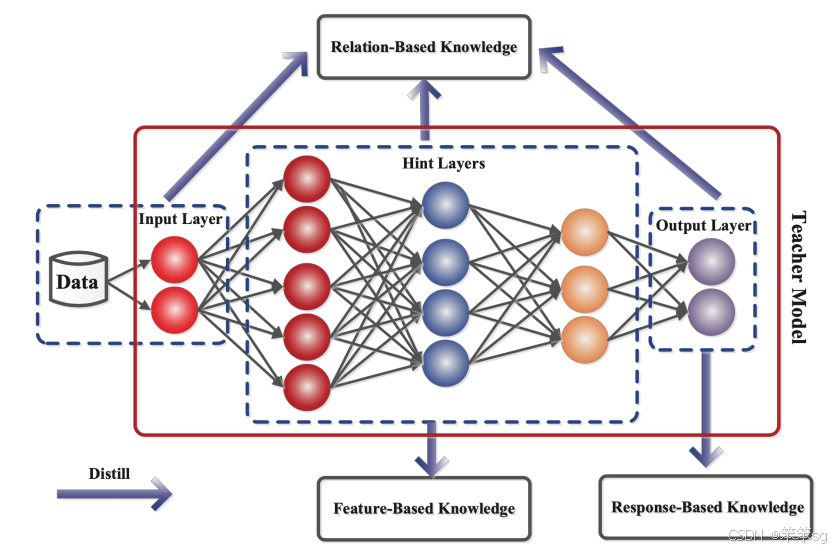
2.1.1 基于响应的知识(Response-based Knowledge)
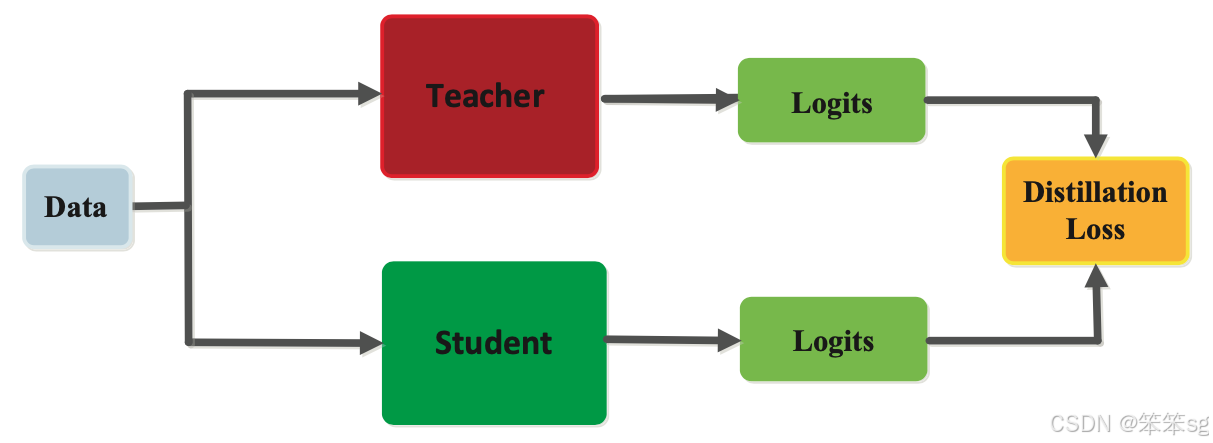
如上图所示,基于响应的知识主要关注教师模型的最终输出层。这种方法的假设是,学生模型可以通过模仿教师模型的预测来学习知识。如下图所示,这可以通过一种被称为蒸馏损失(distillation loss)的损失函数实现,该损失函数捕获学生模型和教师模型的输出(logits)之间的差异。随着训练过程中蒸馏损失的逐渐减小,学生模型将逐渐更好地做出与教师模型相同的预测。
在计算机视觉任务(例如图像分类)中,软目标(soft targets) 是基于响应的知识的主要形式。软目标表示输出类别上的概率分布,通常通过 softmax 函数计算得到。每个软目标对知识的贡献通过一个名为温度(temperature) 的参数来调节。基于软目标的响应型知识蒸馏通常用于监督学习的场景中。
2.1.2 基于特征的知识(Feature-based Knowledge)
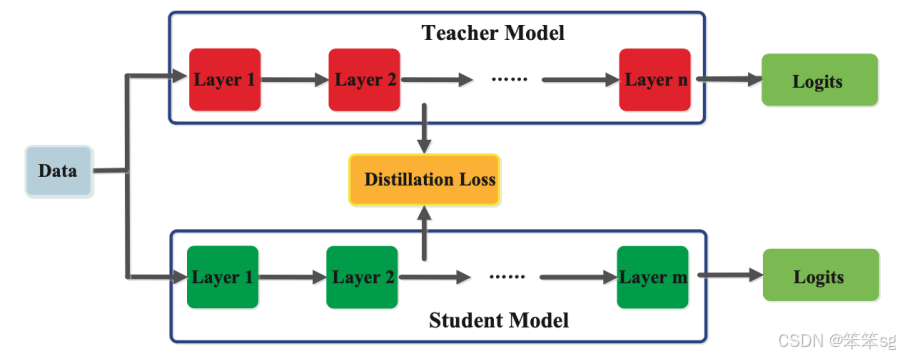
训练好的教师模型还可以在其中间层中捕获关于数据的知识,这一点对于深度神经网络尤为重要。中间层会学习区分特定的特征,而这些知识可以用来训练学生模型。如下图所示,目标是让学生模型学习与教师模型相同的特征激活。通过蒸馏损失函数可以实现这一目标,该函数通过最小化教师模型和学生模型之间的特征激活差异来进行优化。
2.1.3. 基于关系的知识(Relation-based Knowledge)
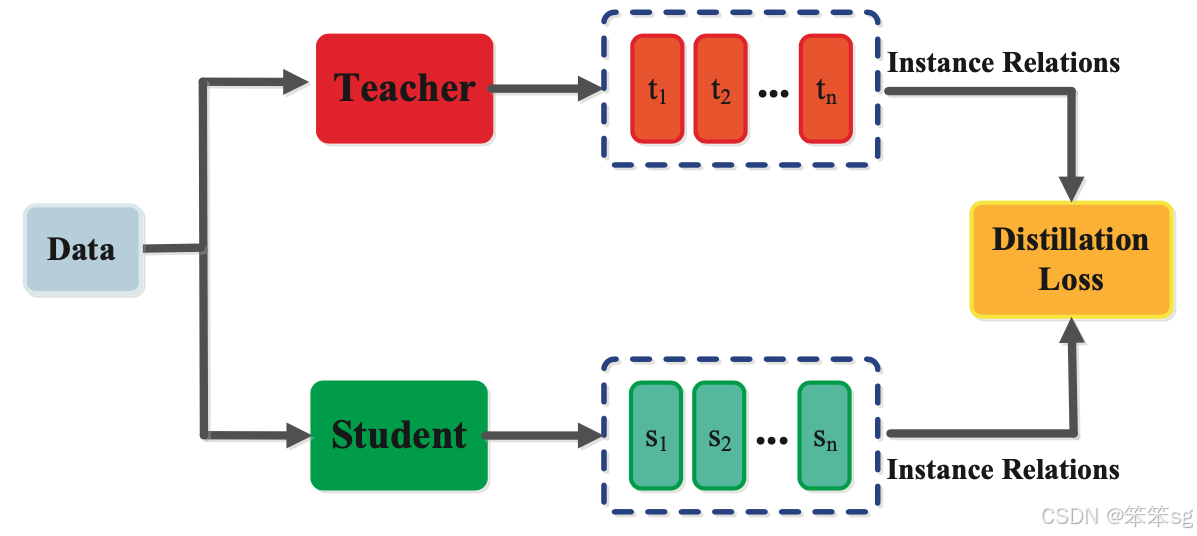
除了神经网络输出层和中间层中表示的知识外,还可以利用捕获特征图之间关系的知识来训练学生模型。这种形式的知识被称为基于关系的知识(Relation-based Knowledge),如下图所示。
这种关系可以通过以下方式建模:
- 特征图之间的相关性
- 图结构(graphs)
- 相似性矩阵
- 特征嵌入(feature embeddings)
- 基于特征表示的概率分布
基于关系的知识通过分析和利用这些特征间的关系,进一步提升学生模型的学习效果。
2.2 训练
训练学生模型和教师模型的方法主要分为三类:离线蒸馏、在线蒸馏和自蒸馏。蒸馏训练方法的分类取决于教师模型是否与学生模型同时更新,如下图所示。
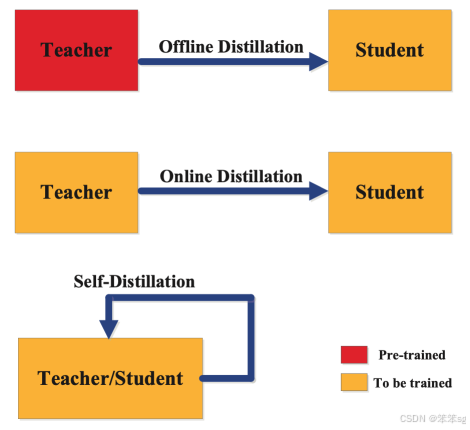
2.2.1 离线蒸馏(Offline Distillation)
离线蒸馏是最常见的方法,其中使用一个预训练的教师模型来指导学生模型。在这种方式中,教师模型首先在训练数据集上进行预训练,然后将教师模型中的知识蒸馏到学生模型中进行训练。
随着深度学习的快速发展,各种预训练的神经网络模型已经被广泛开放,可根据具体应用场景选择作为教师模型。离线蒸馏是深度学习中一种成熟且易于实现的技术。
2.2.2 在线蒸馏(Online Distillation)
在离线蒸馏中,预训练的教师模型通常是一个高容量的深度神经网络。然而,在某些情况下,可能无法获得适用于离线蒸馏的预训练模型。为了解决这一局限性,可以使用在线蒸馏,在这种方法中,教师模型和学生模型在一个端到端的训练过程中同时更新。在线蒸馏可以通过并行计算实现,因此是一种高效的方法。
2.2.3 自蒸馏(Self-distillation)
如上图所示,在自蒸馏中,教师模型和学生模型使用相同的模型。例如,可以利用深层神经网络的深层激活值来训练浅层网络。这可以视为在线蒸馏的一种特殊情况,并可以通过多种方式实现。例如,教师模型在早期训练轮次的知识可以转移到其后期训练轮次中,用于训练学生模型。
2.3 架构
学生-教师网络架构的设计对于高效的知识获取和蒸馏至关重要。通常,复杂的教师模型和简单的学生模型之间存在模型容量差距。通过优化知识传递,可以通过高效的学生-教师架构缩小这种结构差距。
由于深度神经网络的层数和宽度,知识传递并非易事。最常见的知识传递架构包括以下学生模型类型:
- 教师模型的浅层版本:层数更少,每层的神经元数量也更少。
- 教师模型的量化版本:通过降低数值精度来减少计算需求。
- 使用高效基本操作的小型网络:例如采用轻量级操作以减少计算复杂度。
- 优化了全局网络架构的小型网络:对网络整体结构进行优化以提高效率。
- 与教师模型相同的模型:直接使用与教师相同的架构进行学习。
除了上述方法,近年来的技术进步(如神经架构搜索(Neural Architecture Search, NAS))也可以用于在给定教师模型的情况下设计最优的学生模型架构。
3 知识蒸馏的算法
在本节中,将重点介绍学生模型从教师模型中获取知识的训练算法。
3.1 对抗蒸馏
对抗学习最初是在生成对抗网络(GANs)的背景下提出的,用于训练生成器模型以生成尽可能接近真实数据分布的合成数据样本,以及判别器模型以区分真实数据与合成数据样本。该概念已被应用于知识蒸馏,使学生模型和教师模型能够更好地学习真实数据分布的表示。
为实现学习真实数据分布的目标,可以通过以下方式实现对抗学习:
- 生成器模型:训练一个生成器模型以获得合成训练数据,直接使用或增强原始训练数据集。
- 判别器模型:通过判别器模型区分学生和教师模型的样本(基于logits或特征图),从而帮助学生更好地模仿教师模型。
- 在线蒸馏:在对抗学习中,学生和教师模型可以共同优化以实现在线蒸馏。
3.2 多教师蒸馏
在多教师蒸馏中,学生模型从多个教师模型中获取知识(如下图所示)。利用教师模型的集合可以为学生模型提供多样化的知识,这比从单一教师模型获取知识更有益。
来自多个教师的知识可以通过对所有模型的响应进行平均来结合。通常,传递的知识类型基于logits或特征表示。多个教师可以传递不同类型的知识,如第2.1节所述。

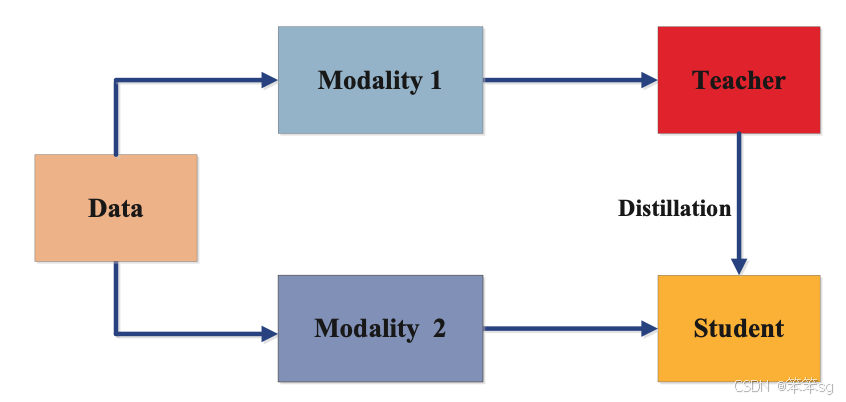
3.3 跨模态蒸馏
如下图所示,跨模态蒸馏的训练方案中,教师模型在一种模态上接受训练,其知识被蒸馏到需要其他模态知识的学生模型中。这种情况适用于特定模态在训练或测试期间缺乏数据或标签的场景,因而需要跨模态知识传递。
跨模态蒸馏最常见于视觉领域。例如,一个在标注图像数据上训练的教师模型,其知识可被用于训练输入域未标注的学生模型(如光流、文本或音频)。在这种情况下,教师模型从图像中学习的特征可用于对学生模型的监督训练。跨模态蒸馏广泛应用于视觉问答、图像描述生成等任务。
3.4 其他蒸馏算法
除了上述算法外,还有以下几种用于知识蒸馏的算法:
- 基于图的蒸馏:通过图结构捕捉数据间的关系,而非仅传递教师模型的单个实例知识。图可以用于知识转移或控制教师知识的传递。图中的每个顶点表示一个自监督教师模型,该模型可基于响应或特征知识(如logits或特征图)。
- 基于注意力的蒸馏:通过注意力图从特征嵌入中转移知识。
- 无数据蒸馏:在缺乏训练数据集(由于隐私、安全或保密性原因)的情况下,使用合成数据进行蒸馏。合成数据通常从预训练教师模型的特征表示生成,或通过GAN生成。
- 量化蒸馏:将知识从高精度教师模型(如32位浮点)传递到低精度学生模型(如8位)。
- 终身蒸馏:基于持续学习、终身学习和元学习机制,将已学到的知识积累并应用于未来学习。
- 基于神经架构搜索的蒸馏:用于识别适合的学生模型架构,从而优化从教师模型中学习的过程。
4 知识蒸馏的应用
知识蒸馏已经成功地应用于多个机器学习和深度学习的领域,如图像识别、自然语言处理(NLP)和语音识别等。在本节中,我将重点介绍知识蒸馏技术的现有应用以及未来的潜力。
4.1 视觉领域
知识蒸馏在计算机视觉领域的应用非常广泛。最先进的计算机视觉模型越来越多地基于深度神经网络,这些模型可以通过模型压缩来提高部署效率。知识蒸馏已成功应用于以下用例:
- 图像分类
- 人脸识别
- 图像分割
- 动作识别
- 目标检测
- 车道检测
- 行人检测
- 面部地标检测
- 姿势估计
- 视频字幕生成
- 图像检索
- 阴影检测
- 文本到图像合成
- 视频分类
- 视觉问答等。
知识蒸馏还可用于某些特定用例,例如跨分辨率的人脸识别。在这种情况下,通过高分辨率人脸教师模型和低分辨率人脸学生模型的架构,可以提高模型的性能和延迟。由于知识蒸馏能够利用多种不同的知识形式,包括跨模态数据、多领域、多任务以及低分辨率数据,因此可以训练出多种蒸馏后的学生模型,适用于特定的视觉识别任务。
4.2 自然语言处理(NLP)
知识蒸馏在NLP应用中的重要性尤其突出,特别是考虑到大型深度神经网络(如语言模型或翻译模型)的普及。最先进的语言模型包含数十亿个参数,例如,GPT-3包含1750亿个参数,而之前的最先进语言模型BERT(基础版本)只有1.1亿个参数。
因此,知识蒸馏在NLP中非常流行,用于获得快速、轻量且训练更便宜的模型。除了语言建模之外,知识蒸馏还广泛应用于以下NLP任务:
- 神经机器翻译
- 文本生成
- 问答系统
- 文档检索
- 文本识别。
通过知识蒸馏,可以获得高效且轻量的NLP模型,这些模型可以在较低的内存和计算要求下进行部署。学生-教师训练也可用于解决多语言NLP问题,其中不同的多语言模型之间可以相互转移和共享知识。
案例研究:DistilBERT
DistilBERT是一个较小、更快速、更便宜且更轻的BERT模型。在这个项目中,作者预训练了一个较小的BERT模型,并可以针对多种NLP任务进行微调,且保持相当强的准确性。知识蒸馏在预训练阶段应用,得到的蒸馏版BERT模型比原版小40%(6600万个参数对比1.1亿个参数),推理速度提高60%(GLUE情感分析任务上,推理时间为410秒对比668秒),同时模型性能保持在原BERT模型的97%左右。在DistilBERT中,学生模型具有与BERT相同的架构,并通过一种新的三重损失(结合语言建模损失、蒸馏损失和余弦距离损失)获得。
4.3 语音领域
最先进的语音识别模型也基于深度神经网络。现代自动语音识别(ASR)模型采用端到端训练,并基于包括卷积层、序列到序列模型与注意力机制,以及最近的变换器(Transformer)架构。对于实时设备端语音识别,获取更小、更快的模型以提高性能变得至关重要。
知识蒸馏在语音领域的应用包括:
- 语音识别
- 口语语言识别
- 音频分类
- 说话人识别
- 声学事件检测
- 语音合成
- 语音增强
- 噪声鲁棒的ASR
- 多语言ASR
- 口音识别。
案例研究:Amazon Alexa的声学建模
Parthasarathi和Strom(2019)利用学生-教师训练,在100万小时的未标记语音数据中生成软标签,其中训练数据集仅包含7000小时的标记语音。教师模型生成所有输出类别的概率分布。学生模型也生成相同特征向量下的输出类别概率分布,目标函数优化这两个分布之间的交叉熵损失。在这个案例中,知识蒸馏帮助简化了在大规模语音数据集上的目标标签生成过程。
5 结论
现代深度学习应用通常依赖于庞大的神经网络,这些网络具有大容量、大内存占用和较慢的推理延迟。将此类模型部署到生产环境中是一个巨大的挑战。知识蒸馏是一种优雅的机制,可以训练出一个较小、轻量、更快且更便宜的学生模型,这个学生模型是从一个大型复杂的教师模型中推导出来的。自从Hinton及其同事在2015年提出知识蒸馏的概念以来,知识蒸馏方案在获得高效和轻量级的生产用模型方面得到了广泛采用。知识蒸馏是一种复杂的技术,涉及不同类型的知识、训练方案、架构和算法。知识蒸馏已经在计算机视觉、自然语言处理、语音等多个领域取得了巨大的成功。
6 参考文献:
- Knowledge Distillation: Principles, Algorithms, Applications
- Distilling the Knowledge in a Neural Network. Hinton G, Vinyals O, Dean J (2015) NIPS Deep Learning and Representation Learning Workshop. https://arxiv.org/abs/1503.02531
- Model Compression. Bucilua C, Caruana R, Niculescu-Mizil A (2006) Model compression | Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining
- Knowledge distillation: a survey. You J, Yu B, Maybank SJ, Tao D (2021) https://arxiv.org/abs/2006.05525
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (2019) Sanh V, Debut L, Chammond J, Wolf T. https://arxiv.org/abs/1910.01108v4
- Lessons from building acoustic models with a million hours of speech (2019) Parthasarathi SHK, Strom N. https://arxiv.org/abs/1904.01624


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









