







今天这篇文章将详细讲解下,如何在Ubuntu上安装Ollama,想了解MacOS和Windows上如何安装的可以去看我之前的文章(手把手教你本地部署DeepSeek R1,让你AI性能原地起飞)

本篇全部安装均是基于我本地电脑安装的ubuntu系统上部署的,刚好之前有台老旧的Windows电脑,重新把该电脑安装成了ubuntu22系统,再利用内网穿透工具把家里宽带映射到公网实现访问,之后我也将出一篇专栏和大家分享家用电脑如何安装ubuntu系统以及ubuntu安装全部基础软件的教程,实现家里台式电脑的二次利用!
Ollama介绍
Ollama 是一个由 AI 研究实验室开发的开源人工智能模型,专注于为用户提供高效、灵活的自然语言处理能力。它基于先进的大规模语言模型架构,能够执行多种任务,包括文本生成、对话交互、问答系统等。Ollama 的设计旨在简化模型的使用和部署,支持多种语言和领域特定的应用场景。
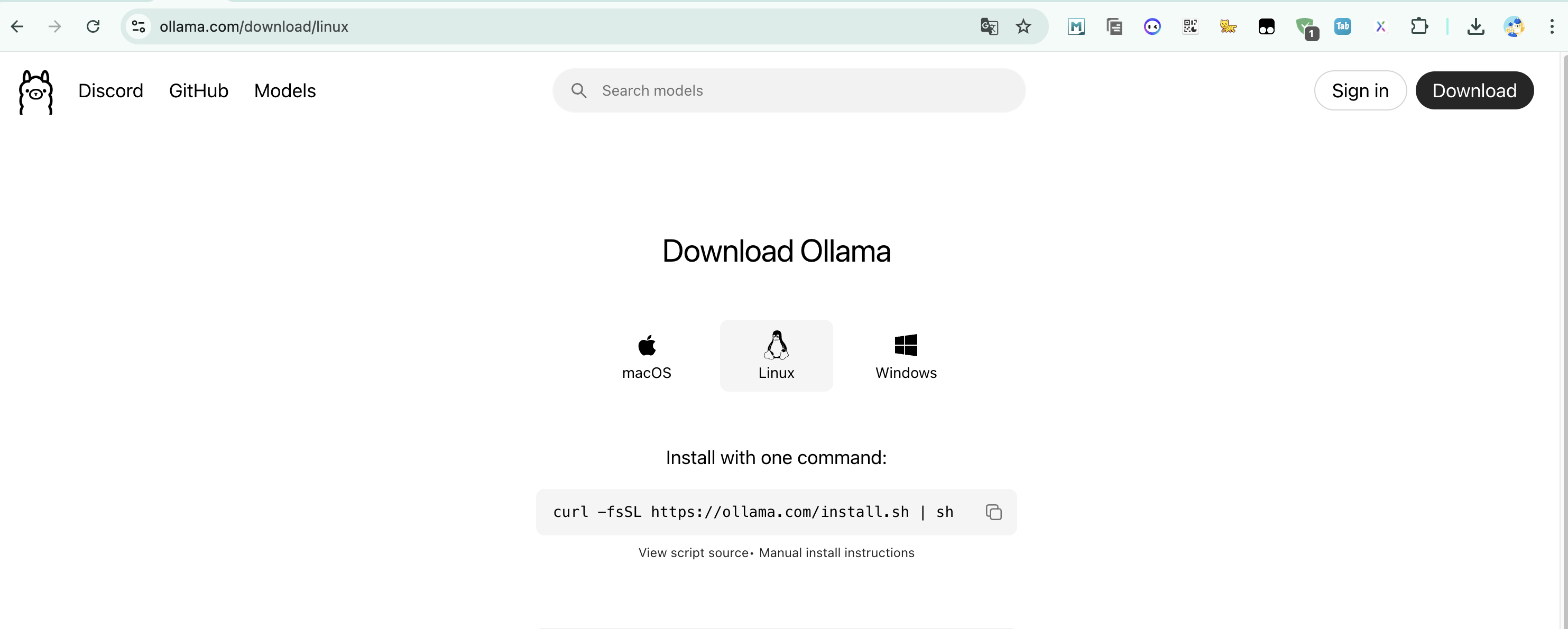
官网地址:
地址:Download Ollama on macOS,目前macOS和Windows都可直接通过页面下载,Linux需要通过命令下载
主要特点:
- 开源与可定制:Ollama 作为开源项目,允许开发者自由修改和优化模型,以适应特定需求。
- 轻量级与高效:相较于其他一些大型模型,Ollama 在计算资源和内存使用上更为高效,适合在资源受限的环境中运行。
- 多语言支持:支持包括中文在内的多种语言,能够处理跨语言任务。
- 灵活的 API 接口:提供易于集成的 API,方便开发者将 Ollama 集成到现有系统中。
- 社区驱动:拥有活跃的开发者社区,持续贡献新功能和改进。
优势:
- 性能优越:在保持模型轻量的同时,仍能提供高质量的输出。
- 易于部署:支持多种平台和设备,方便快速部署。
- 持续更新:随着社区的贡献和技术进步,模型不断优化和改进。如果你对 AI 模型的开发和应用感兴趣,Ollama 是一个值得探索的选择。
安装Ollama(两种方式)
一、使用快捷命令自动安装【国内用户不推荐】
以下命令是官网推荐的安装方式
curl -fsSL https://ollama.com/install.sh | sh
虽然该方式安装便捷,不过国内下载有点慢,不推荐使用,博主已亲自试过了,安装了10分钟都还没完成10%

二、通过下载压缩包方式手动安装
1、下载安装包
方法一:使用github地址
下载命令如下
wget https://gh.llkk.cc/https://github.com/ollama/ollama/releases/latest/download/ollama-linux-amd64.tgz
因为github.com正常是无法访问了,这里我使用了虾壳加速(虾壳 - GitHub下载加速网站 GitHub Proxy加速器),把正常github地址拷贝进去就可以得到加速后地址
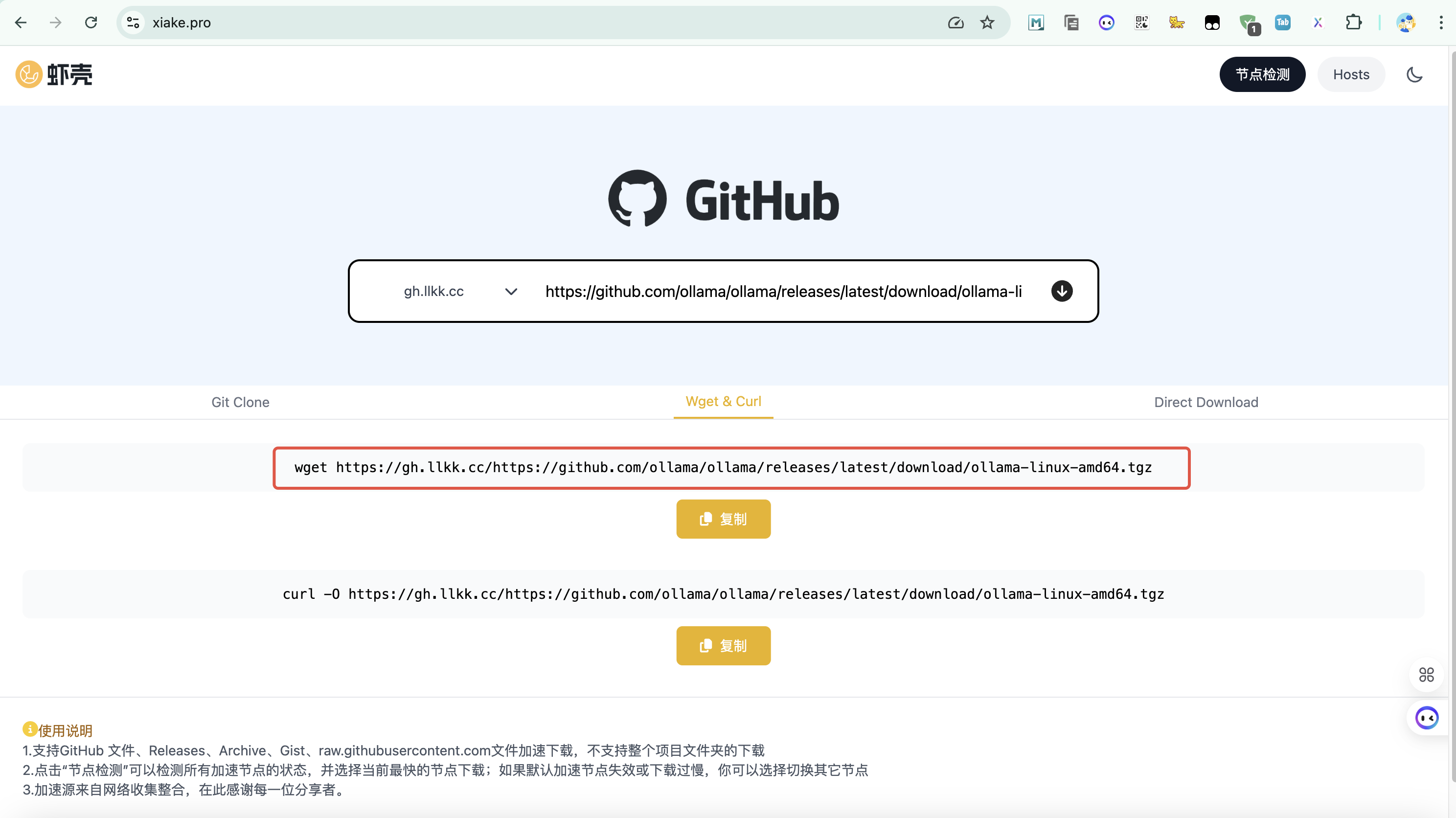
实测了下,下载速度还是挺快的

方法二:使用我的个人服务器地址
如果方法一下载速度还是很慢话可以使用个人地址,按以下方式去获取,为防止恶意下载占用流量,这里不直接展示
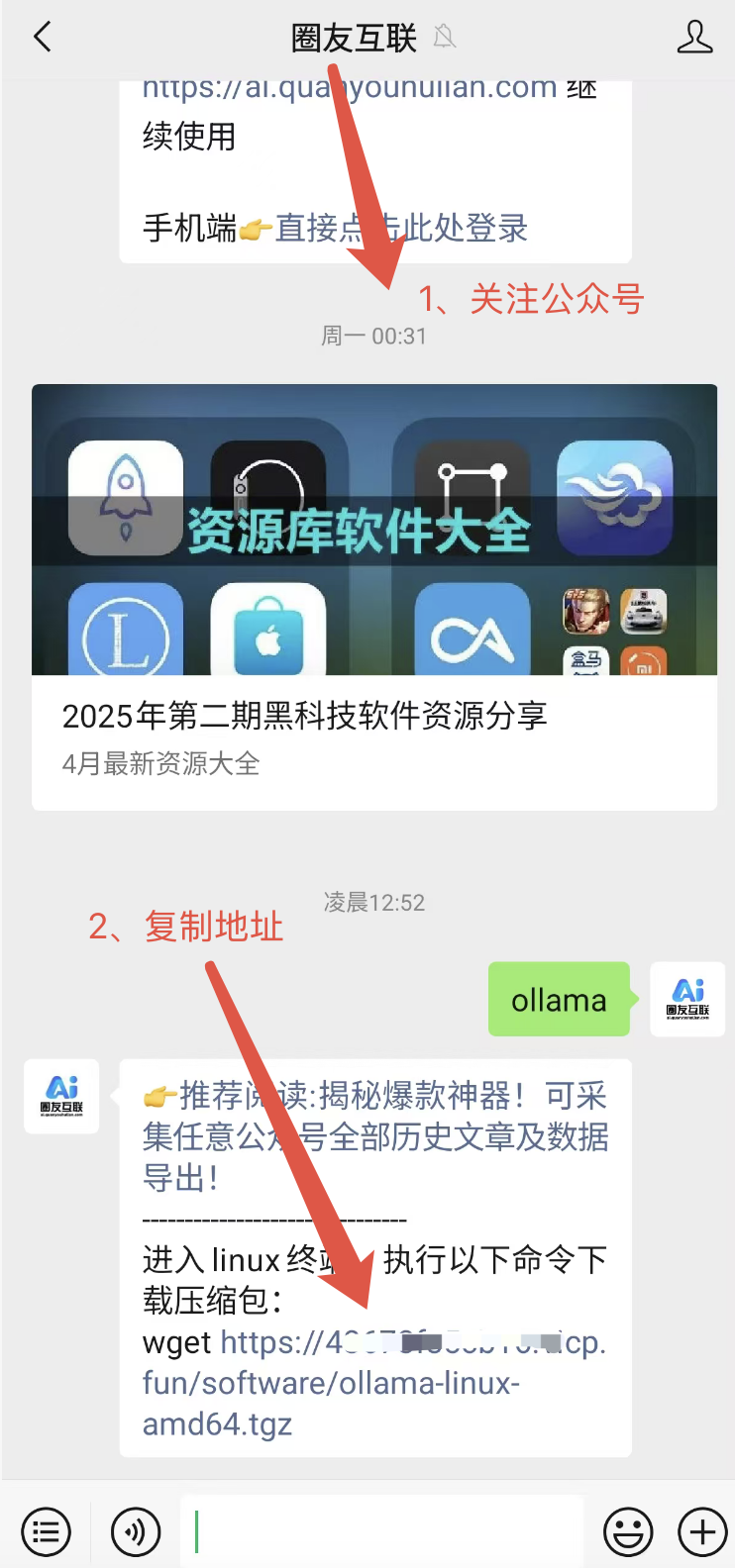
一般5分钟左右可以下载完成,速度也还是挺快的
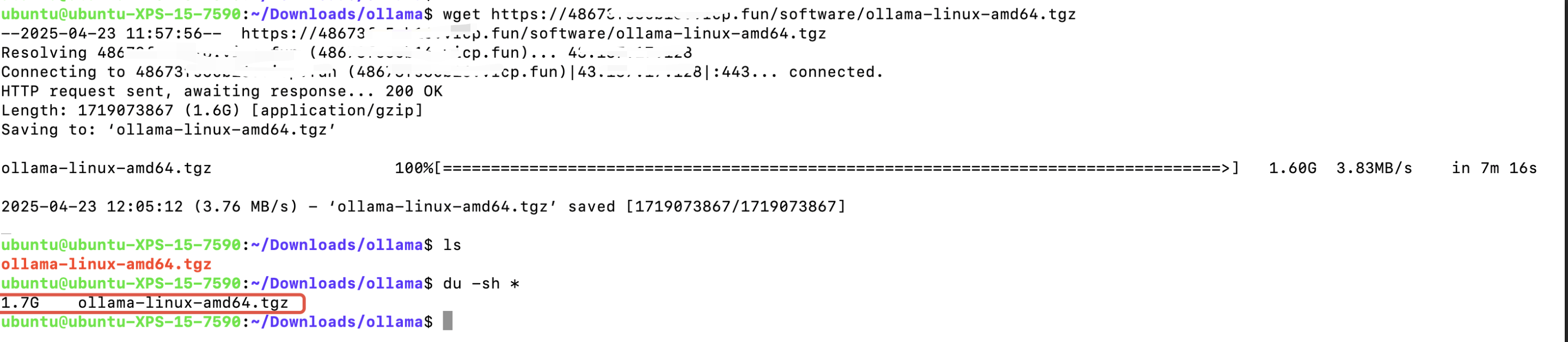
2、解压压缩包
这里我们使用以下命令将ollama-linux-amd64.tgz解压到/usr目录下
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
该命令大概需要20秒左右解压完,稍微等待下,解压完成后会再/usr/bin/目录下多出个ollama命令

3、将ollama添加为启动服务
这里我们在/etc/systemd/system目录下添加个ollama.service
sudo vim /etc/systemd/system/ollama.service
输入i,添加内容如下(注意:这里User和Group填写你自己当前用户的):
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ubuntu
Group=ubuntu
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
[Install]
WantedBy=multi-user.target
复制进去后,再输入wq!保存下,可以看到已成功创建了ollama.service并添加了以下内容
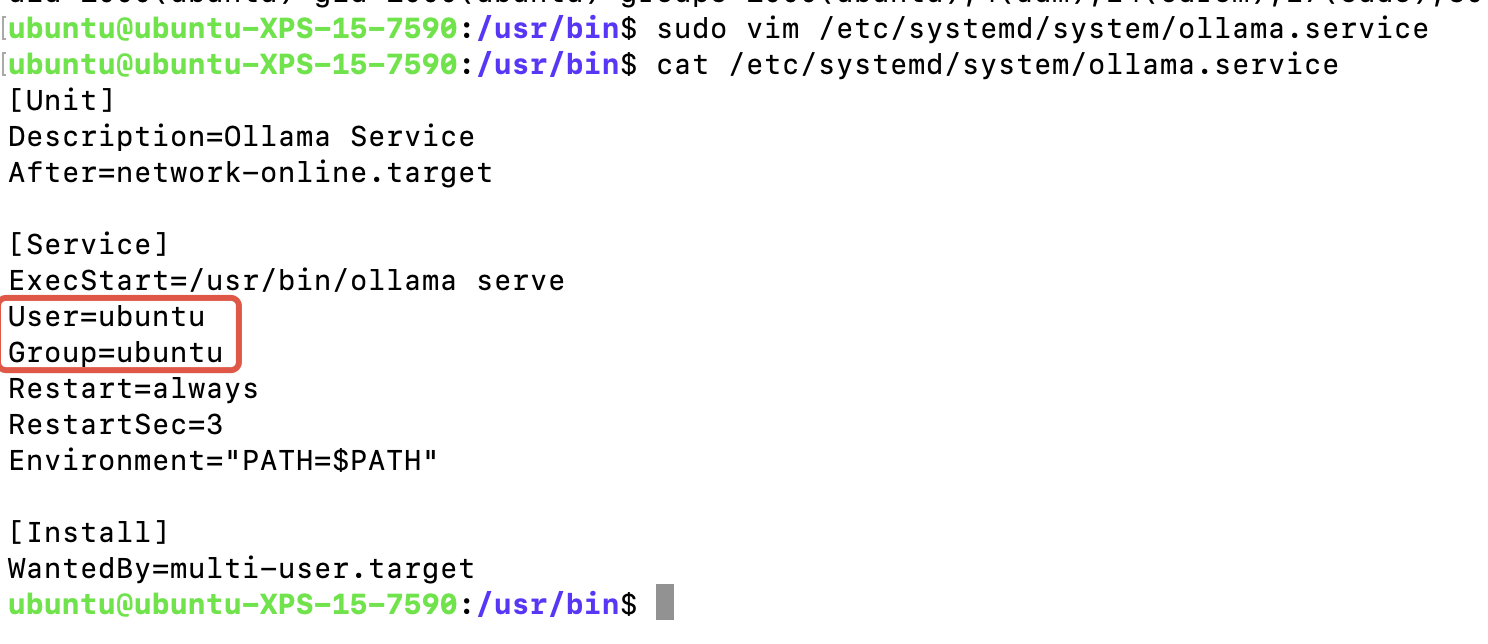
不知道自己的User和Group是什么的可以输入id直接查到
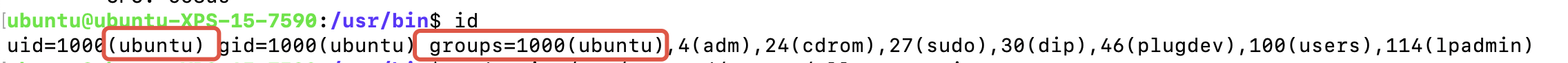
4、加载配置并创建Ollama软链接
输入以下命令加载ollama.service配置并创建软链接
sudo systemctl daemon-reload
sudo systemctl enable ollama
详细操作如下

5、启动Ollama
输入以下命令启动ollama
sudo systemctl start ollama
6、查看Ollama启动状态
输入以下命令查看启动状态
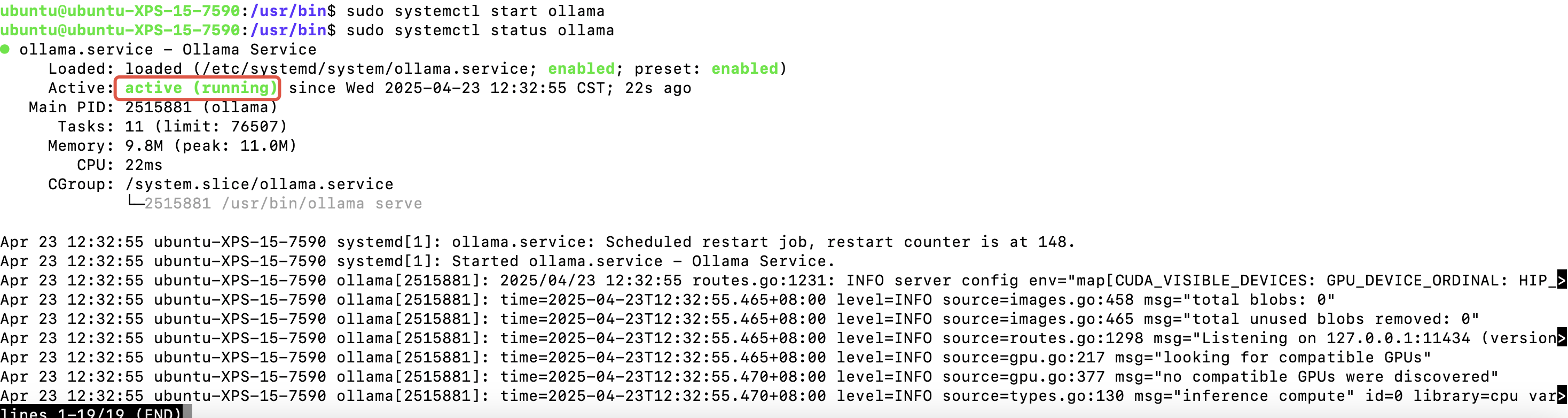
sudo systemctl status ollama
出现running表示启动成功
安装LLM模型
一、模型选择
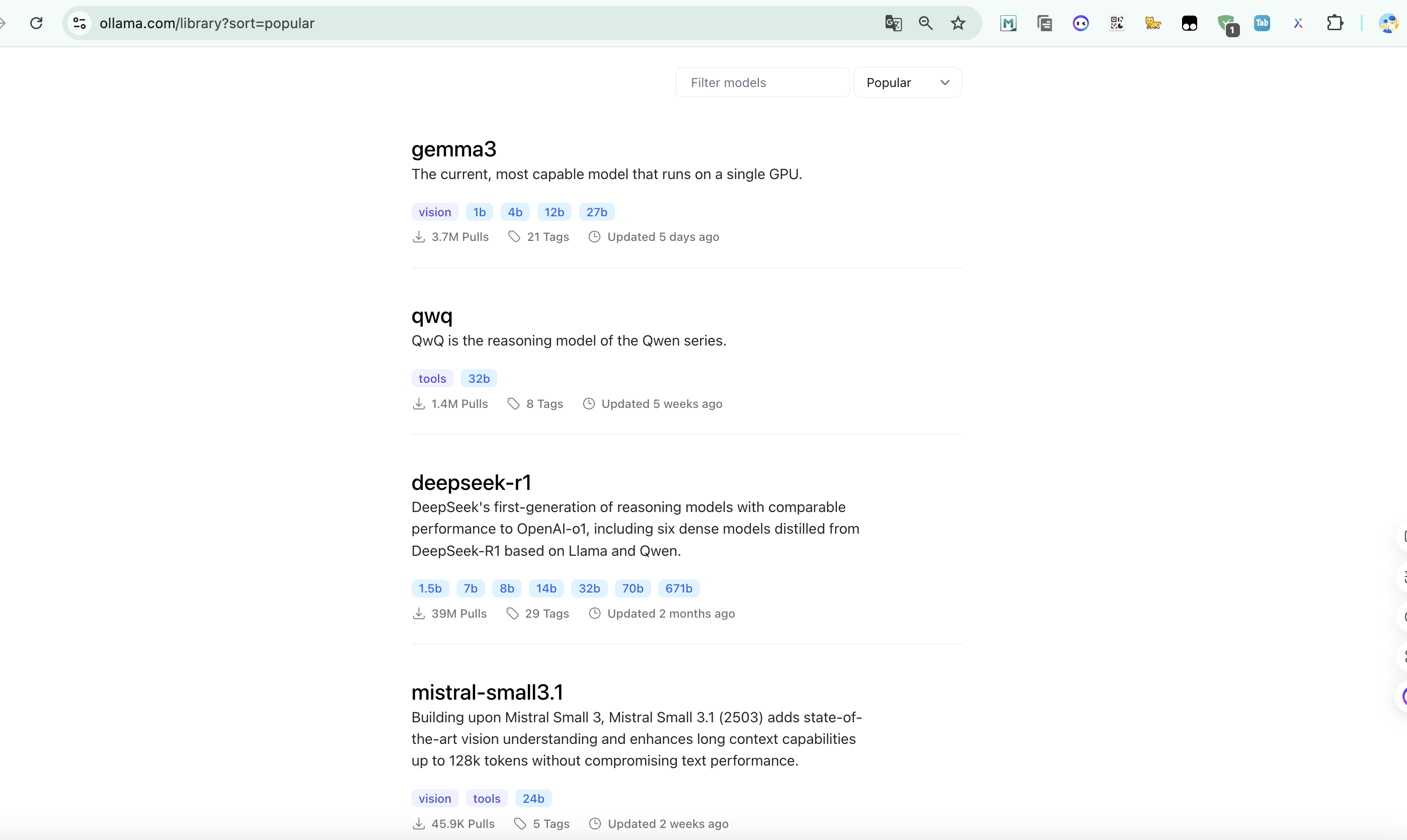
1、官网查看模型列表
这里我们去到ollama官网地址:library,这里自动按当前流行程度做好了排序
2、查找和自己电脑匹配版本
这里我们先看下自己电脑GPU型号
lspci | grep -i vga
执行命令后就显示出了型号,以我的当前系统为例:

🌈
型号:
- Intel UHD Graphics 630(CoffeeLake-H GT2 架构)
- 这是 Intel 第 8/9 代酷睿处理器的集成显卡(非独立显卡)。
性能定位:
- 适合日常办公、视频播放和轻度图形处理。
- 不支持 CUDA/NVIDIA 驱动,无法直接运行需要 GPU 加速的大模型(如 Ollama 的
<font style="color:rgb(36, 41, 47);">--gpu</font>模式)。
可运行的模型类型
- 仅限 CPU 模式:
我当前设备没有 NVIDIA 独立显卡,只能通过 CPU 和内存运行模型。
推荐模型:
bash复制代码ollama pull phi3:3.8b # 3.8B 参数(最低需求)
ollama pull deepseek-llm:7b-q4 # 7B 量化版(需 8GB+ 内存)
注意事项
- 内存要求:
- 7B 模型需 8GB+ 内存(建议 16GB)。
- 如果内存不足,会频繁卡顿或崩溃。
- 速度:
- 纯 CPU 推理速度较慢(生成文本可能需要数秒/词)。
测试方法
拉取模型并运行
ollama pull phi3:3.8b
ollama run phi3:3.8b
如果流畅运行,再尝试更大的模型(如 <font style="color:rgb(36, 41, 47);">deepseek-llm:7b-q4</font>)。
3、模型推荐
由于我电脑没有GPU,所以这里首先把参数在12b以上的全部排除
从Ollama官网受欢迎程度可以看出,支持12b以下的最受欢迎的几个模型分别是:
- **Gemma 3:**Gemma 是谷歌基于 Gemini 技术推出的轻量级模型系列。Gemma 3 模型是多模态模型,可处理文本和图像,并具有 128K 上下文窗口,支持 140 多种语言。它们有 1B、4B、12B 和 27B 四种参数大小,在问题解答、总结和推理等任务中表现出色,其紧凑的设计允许在资源有限的设备上部署。
- deepseek-r1:DeepSeek 的第一代推理模型,在数学、代码和推理任务方面的性能与 OpenAI-o1 不相上下。
- llama3.2:Meta Llama 3.2 多语种大型语言模型(LLMs)集合是一个经过预训练和指令调整的生成模型集合,有 1B 和 3B 两种大小(文本输入/文本输出)。Llama 3.2 经指令调整的纯文本模型针对多语言对话用例进行了优化,包括代理检索和摘要任务。在常见的行业基准测试中,它们的表现优于许多现有的开源和封闭聊天模型。
- qwen2.5:Qwen2.5 是 Qwen 大型语言模型的最新系列。Qwen2.5 发布了一系列基本语言模型和指令调整模型,参数规模从 0.5 亿到 720 亿不等。
以上4款模型都不错,所以我这里决定通用模型部署:Gemma 3:12b,推理模型部署:deepseek-r1:7b
tips:这里选择参数有个技巧,在没有GPU的情况下,如果内存低于16G,就选择7b参数以下模型,如果内存大于16G并且CPU核心数在16个以上就可以部署12b模型了,使用以下命令可以查看CPU核数和内存大小
nproc
free -h
可以看到我这里CPU是满足要求的,所以可以部署Gemma 3:12b版本,如果cpu不够就选择7b以下版本

二、模型安装
上一步,我们已经选好了模型Gemma-3和deepseek-r1,接下来就是安装了
1、拉取模型
使用以下命令拉取
ollama pull gemma3:12b-it-qat
下载速度还是很快的,一般2分钟左右就能下载完成

2、运行模型测试
使用以下命令可以运行模型
ollama run gemma3:12b-it-qat
直接输入消息可以进行测试,12b已经测试过,我这配置有点慢,建议安装4b参数版,使用ctrl+D可以退出运行

3、其他模型安装
谷歌的**gemma3**安装:
ollama pull gemma3:4b
DeepSeek的**deepseek-r1**安装:
ollama pull deepseek-r1:7b
Meta的**llama-3.2**安装:
ollama pull llama3.2:3b
阿里的**qwen2.5**安装:
ollama pull qwen2.5:7b
4、已安装模型查看
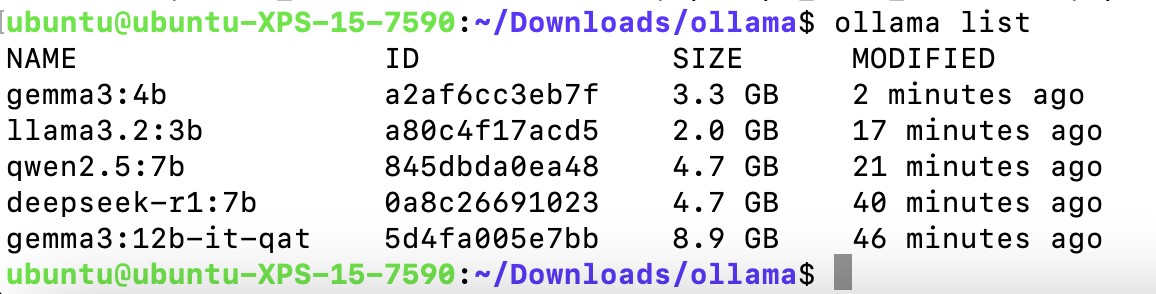
使用以下命令查看已经安装的模型
ollama list
5、其他ollama常用命令
| 命令 | 说明 |
|---|---|
ollama list | 查看已安装的模型 |
ollama ps | 查看正在运行的模型 |
ollama stop <model> | 停止某个模型 |
ollama rm <model> | 删除某个模型 |
使用Ollama的API进行访问
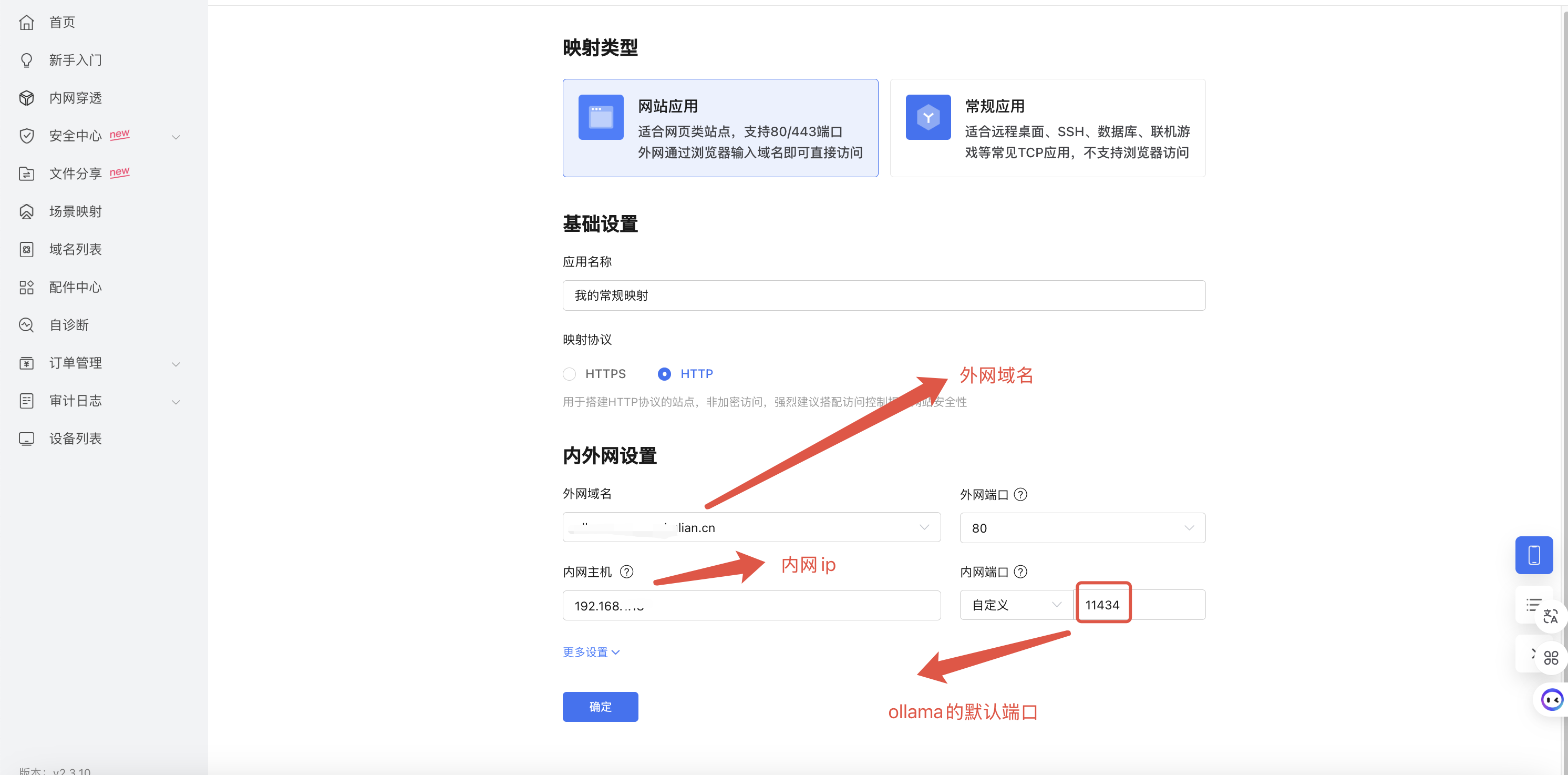
一、域名映射出内网ip地址
因为我这台服务器是部署在家里,所以要映射出公网以便可以随地访问!
映射公网有两种方式,一种是使用像花生壳(贝锐花生壳管理)这样的内网穿透工具,另外一种是使用开源内网穿透工具:FRP(这个后面会专门出一期详细讲下如何搭建)。
为了方便,我这里直接使用了花生壳,它对每个用户都可以免费映射出一条端口(ps:该端口带宽只有1M)
二、常见问题
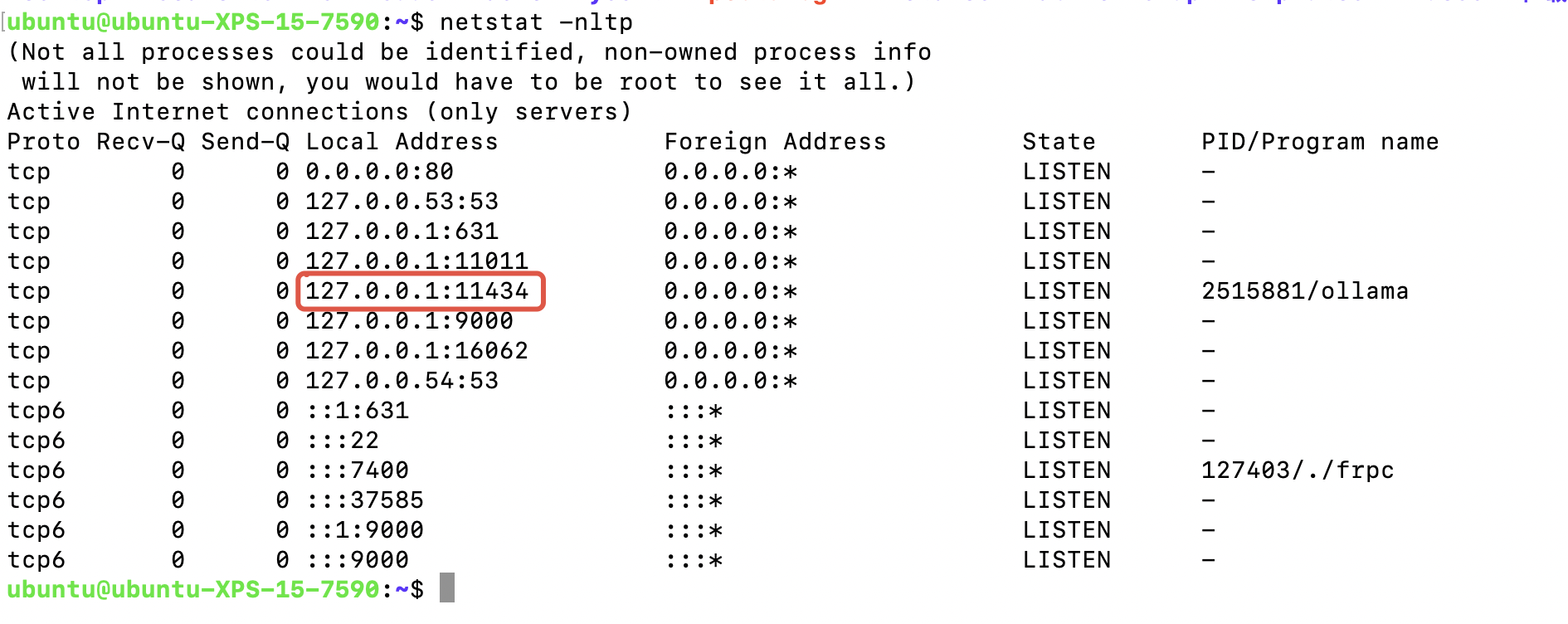
查看端口是否开通了外网访问
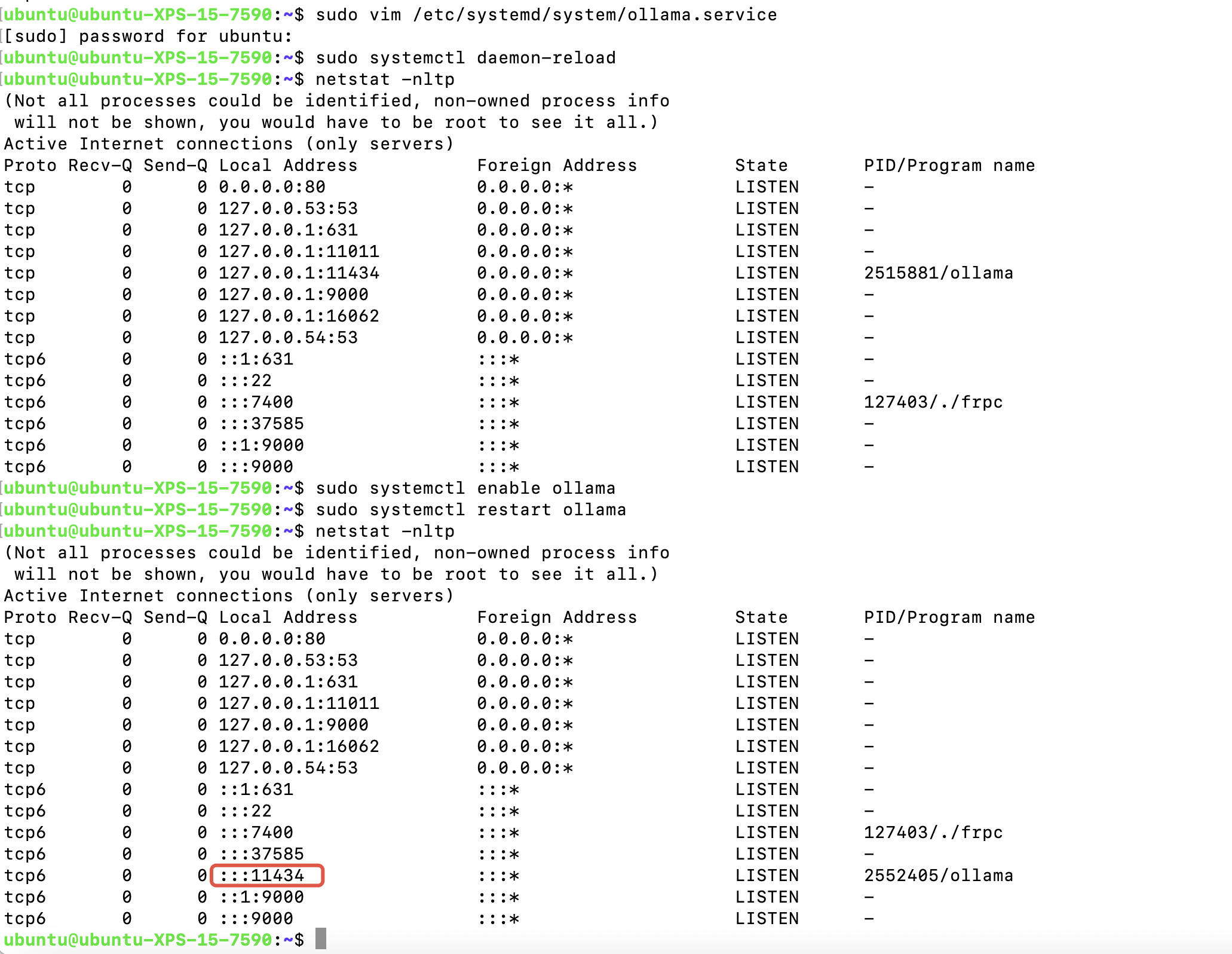
netstat -nltp
这里可以看到11434只允许127.0.0.1本地访问,这里我们要改下ollama的配置文件
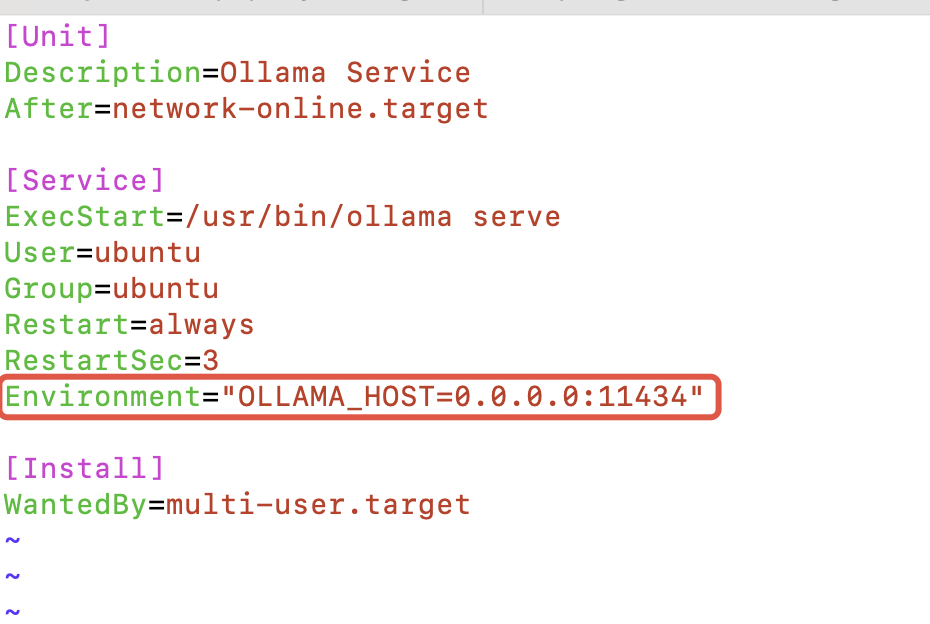
编辑以下配置文件
sudo vim /etc/systemd/system/ollama.service
这里改下Enviroment为如图所示
改完后去重启下ollama
sudo systemctl restart ollama
再重新输入命令:netstat -nltp,可以看到已经没有固定127.0.0.1了
三、测试外网访问API
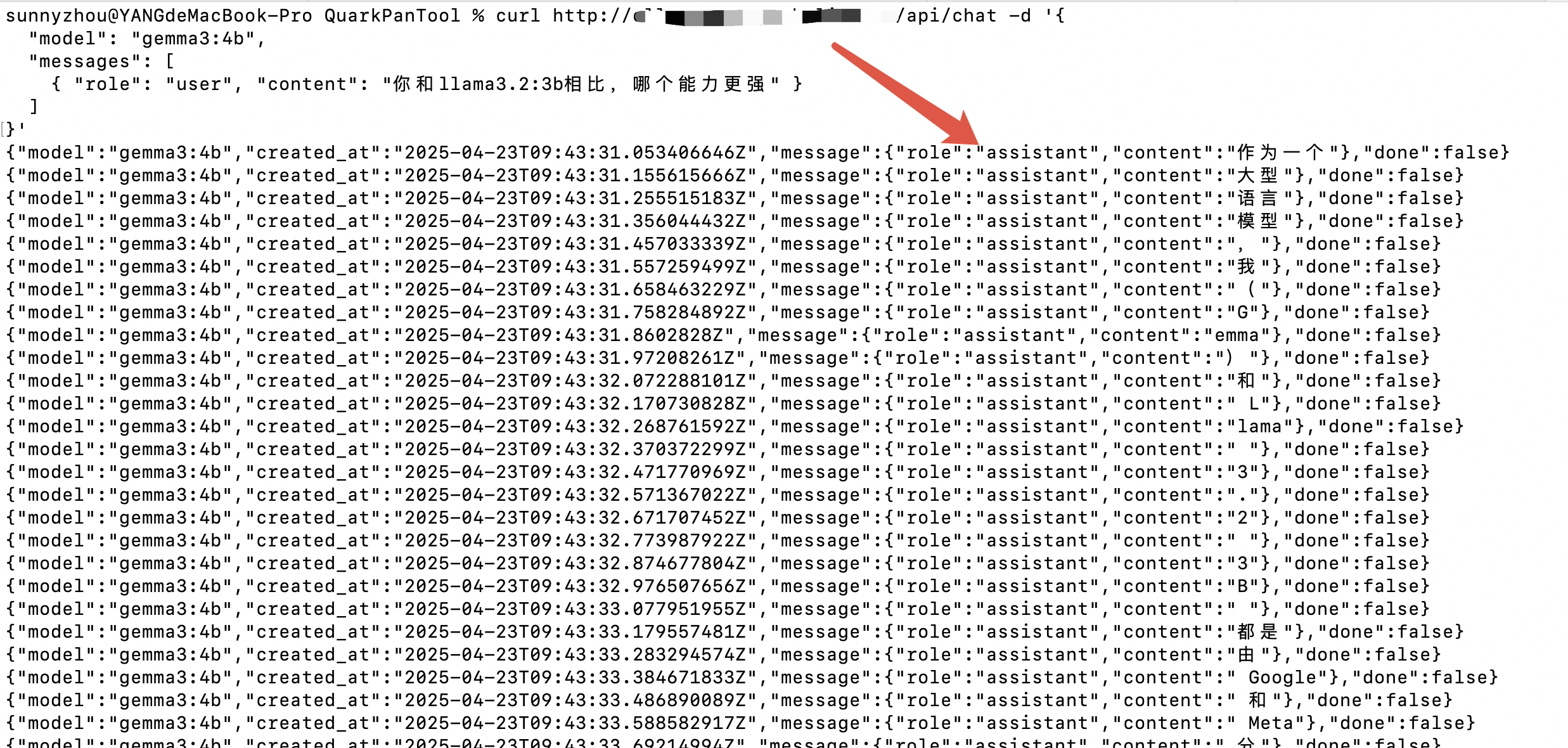
接下来,我们就可以测试下该外网映射出来的API地址是否可以正常访问了
curl http://{改成你自己的外网域名地址}/api/chat -d '{
"model": "llama3.2:3b",
"messages": [
{ "role": "user", "content": "你和llama3.2:3b相比,哪个能力更强" }
]
}'
如果成功按以下响应返回了说明API生效了
使用套壳WEB客户端连通API接口
一、安装Chatbox客户端
像上面那样使用命令端响应得到的结果不美观,这么我们可以使用一些支持API的客户端,推荐使用Chatbox(官网地址:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载),它支持直接配置Ollama API地址
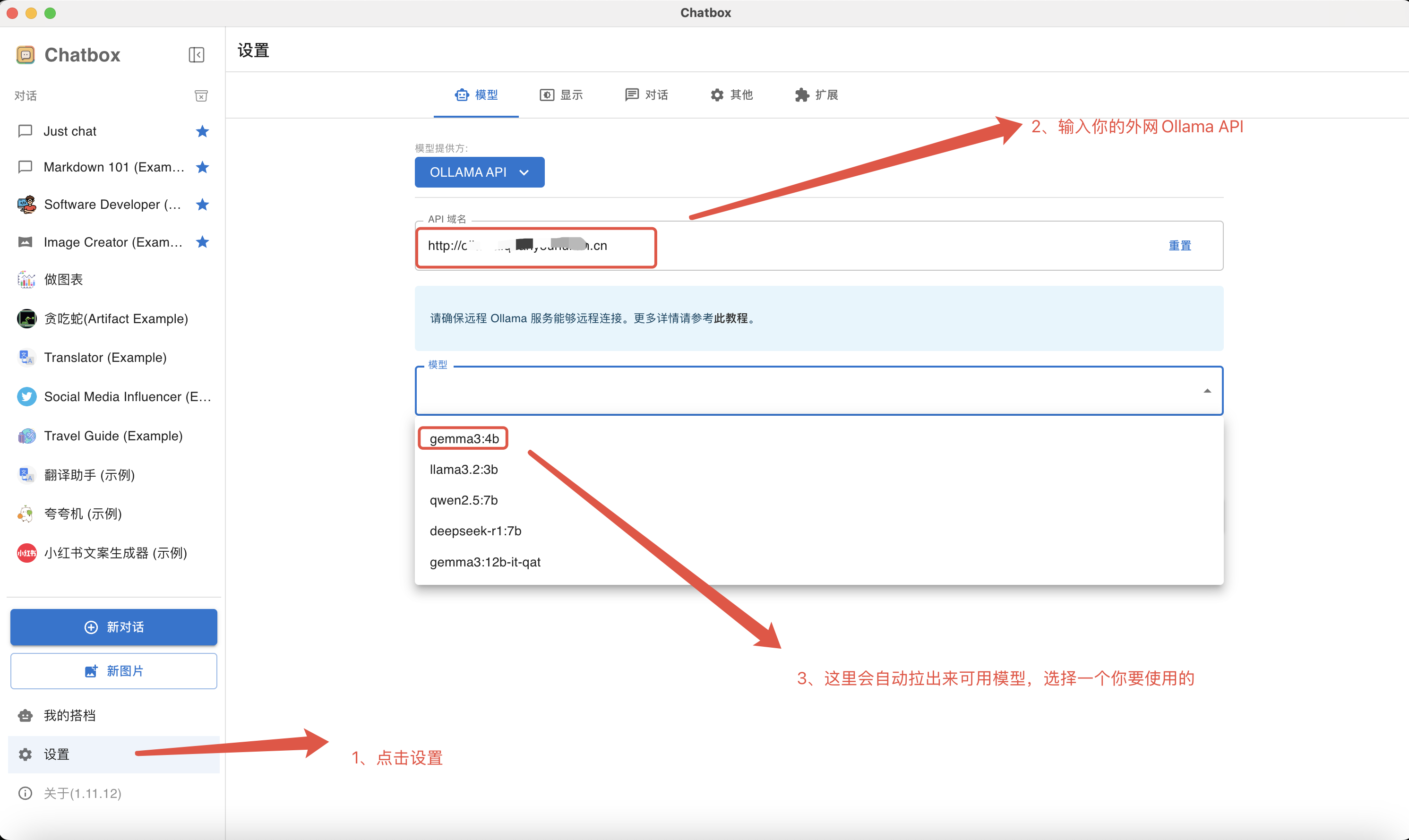
二、配置Ollama API
客户端下载安装完成后,在设置里配置好上一步映射出来的API地址,点击保存即可
三、测试对话
接下来,我们再测试下Gemma的多模态能力,实测下,效果还是不错的,响应速度也快!完美!
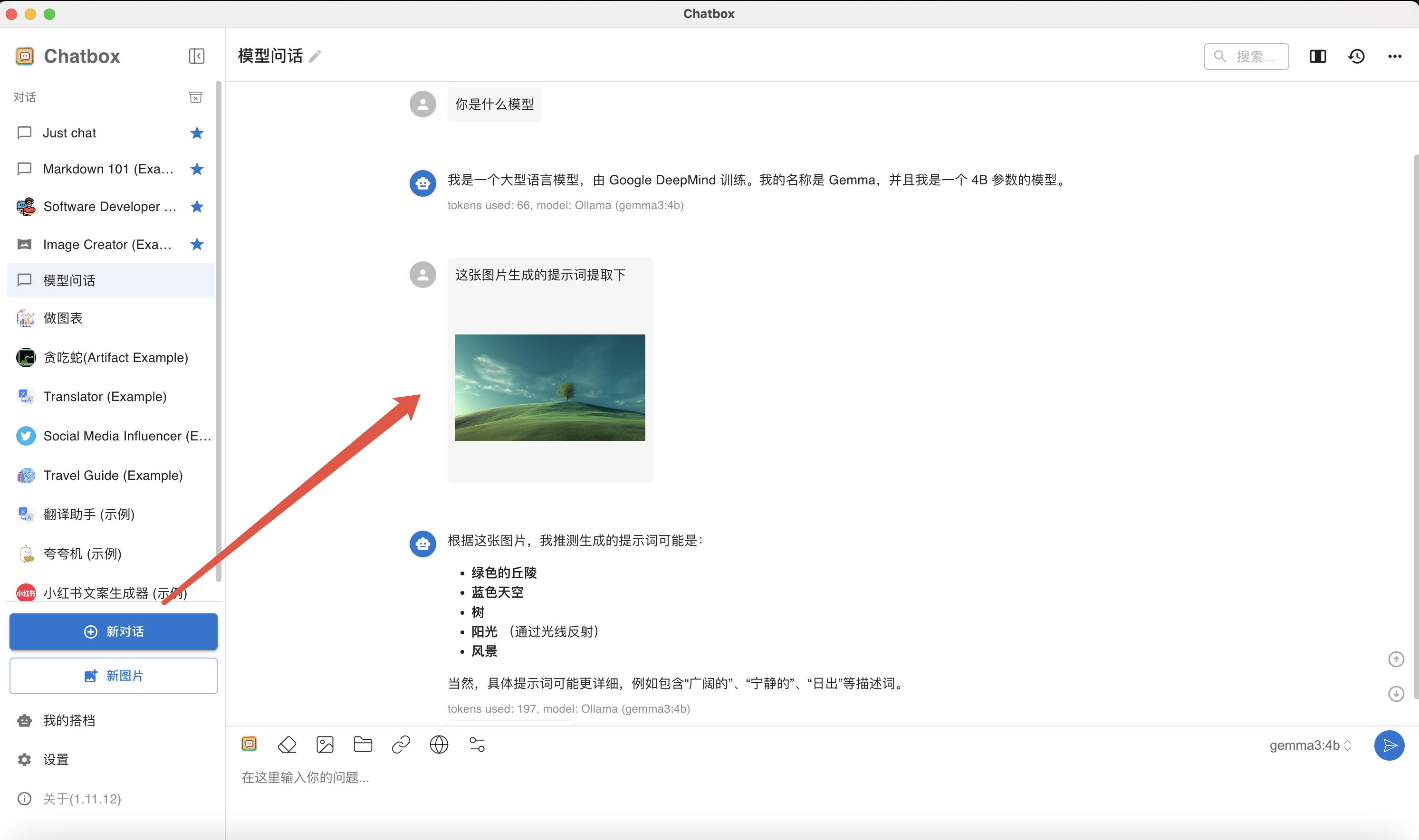
总结
本文详细讲解了ubuntu系统下如何安装ollama,以及如何把ollama的API端口映射出来外网调用,想自建大模型的朋友们快去试下吧,赶紧把家里的旧电脑二次利用起来了!

















 2381
2381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









