







LSTM如何解决梯度消失问题
一、传统RNN的梯度消失困境
在标准RNN中,隐藏状态更新公式为:
h
t
=
tanh
(
W
h
h
h
t
−
1
+
W
x
h
x
t
+
b
h
)
h_t = \tanh(W_{hh}h_{t-1} + W_{xh}x_t + b_h)
ht=tanh(Whhht−1+Wxhxt+bh)
梯度计算通过链式法则展开:
∂
h
t
∂
h
t
−
1
=
W
h
h
T
⋅
diag
(
tanh
′
(
.
.
.
)
)
\frac{\partial h_t}{\partial h_{t-1}} = W_{hh}^T \cdot \text{diag}(\tanh'(...))
∂ht−1∂ht=WhhT⋅diag(tanh′(...))
- 关键问题:每个时间步的梯度包含权重矩阵 W h h W_{hh} Whh的连乘和激活函数导数 tanh ′ \tanh' tanh′的连乘
- 双衰减效应:当序列较长时,梯度呈指数级衰减(消失)或爆炸
二、LSTM的三大核心设计
1. 细胞状态(Cell State)的引入
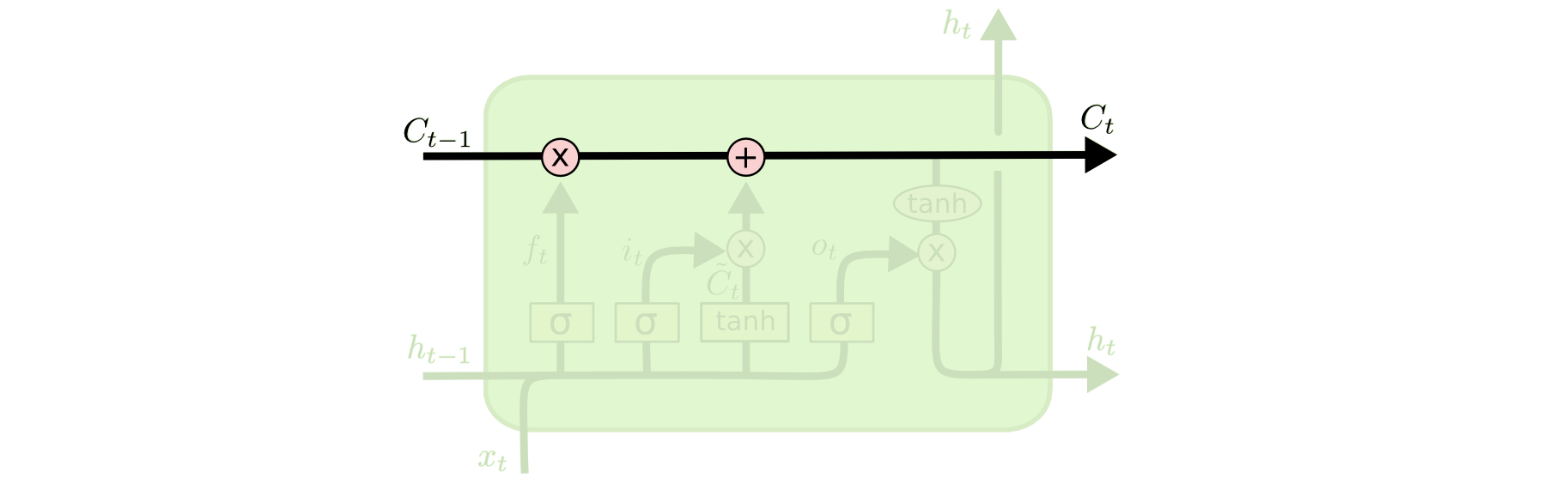
- 物理意义:构建一条"信息高速公路",允许梯度直接流动
- 数学形式:
C t = f t ⊙ C t − 1 + i t ⊙ C ~ t C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t Ct=ft⊙Ct−1+it⊙C~t- 线性更新(加法操作)避免了激活函数的导数衰减
2. 门控机制(Gating Mechanism)
| 门控类型 | 数学公式 | 梯度保护作用 |
|---|---|---|
| 遗忘门 | f t = σ ( W f [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f[h_{t-1},x_t] + b_f) ft=σ(Wf[ht−1,xt]+bf) | 控制历史信息衰减率 |
| 输入门 | i t = σ ( W i [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i[h_{t-1},x_t] + b_i) it=σ(Wi[ht−1,xt]+bi) | 调节新信息注入强度 |
| 输出门 | o t = σ ( W o [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o[h_{t-1},x_t] + b_o) ot=σ(Wo[ht−1,xt]+bo) | 管理对外输出的信息量 |
门控的梯度特性:
- Sigmoid导数的有界性(0~0.25)防止梯度爆炸
- 门控值(0~1)作为调节因子,允许梯度选择性通过
3. 梯度传播路径分离
- 细胞状态路径:
∂ C t ∂ C t − 1 = f t + ∂ ( i t ⊙ C ~ t ) ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} = f_t + \frac{\partial (i_t \odot \tilde{C}_t)}{\partial C_{t-1}} ∂Ct−1∂Ct=ft+∂Ct−1∂(it⊙C~t)
在理想情况下( f t ≈ 1 f_t \approx 1 ft≈1),梯度可无损传递 - 隐藏状态路径:
h t = o t ⊙ tanh ( C t ) h_t = o_t \odot \tanh(C_t) ht=ot⊙tanh(Ct)
短路径依赖减少梯度计算深度
三、关键机制数学证明
1. 细胞状态的梯度流
考虑时间步
t
t
t到
t
−
k
t-k
t−k的梯度:
∂
C
t
∂
C
t
−
k
=
∏
i
=
1
k
(
f
t
−
i
+
1
+
∂
(
i
t
−
i
+
1
⊙
C
~
t
−
i
+
1
)
∂
C
t
−
i
)
\frac{\partial C_t}{\partial C_{t-k}} = \prod_{i=1}^k \left( f_{t-i+1} + \frac{\partial (i_{t-i+1} \odot \tilde{C}_{t-i+1})}{\partial C_{t-i}} \right)
∂Ct−k∂Ct=i=1∏k(ft−i+1+∂Ct−i∂(it−i+1⊙C~t−i+1))
- 当遗忘门 f t f_t ft接近1时,梯度近似保持恒定
- 即使其他项存在衰减,整体梯度仍可保持有界
2. 与RNN的对比分析
| 模型 | 梯度传播项 | 典型衰减系数(10步后) |
|---|---|---|
| RNN | ( W h h ⋅ tanh ′ ) k (W_{hh} \cdot \tanh')^k (Whh⋅tanh′)k | ( 0.9 ) 10 ≈ 0.35 (0.9)^{10} \approx 0.35 (0.9)10≈0.35 |
| LSTM | ∏ f t \prod f_t ∏ft | ( 0.95 ) 10 ≈ 0.60 (0.95)^{10} \approx 0.60 (0.95)10≈0.60 |
假设每个时间步 f t = 0.95 f_t = 0.95 ft=0.95,激活导数平均0.9
五、LSTM的局限性
虽然显著缓解梯度消失,但并未完全消除问题:
- 极端长序列(>1000步)仍可能发生梯度衰减
- 初始化敏感性:门控参数需要合理初始化(Xavier初始化)
- 计算代价:参数量是RNN的4倍,增加训练成本
六、工程实践
- 梯度裁剪:设置阈值
max_grad_norm=5.0防止梯度爆炸 - 门偏置初始化:将遗忘门偏置初始化为1.0(增强长程记忆)
torch.nn.init.constant_(lstm.bias_ih_l0[hidden_size:2*hidden_size], 1.0)

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









