






GloRIA的核心就是注意力
提出了一种不依赖于预训练对象检测模型来提取子区域图像特征的方法。这种方法是通过学习注意力机制,根据每个子区域对于给定单词(可能是图像的标签或描述中的词汇)的重要性进行加权。通过这种方式,系统能够对比注意力加权后的图像表示和对应的单词嵌入,进而学习到注意力权重。这样,注意力权重就成为了模型中局部特征表示的一部分,有助于更好地捕捉医学图像中的关键信息。
-
文章公式
-
主要介绍
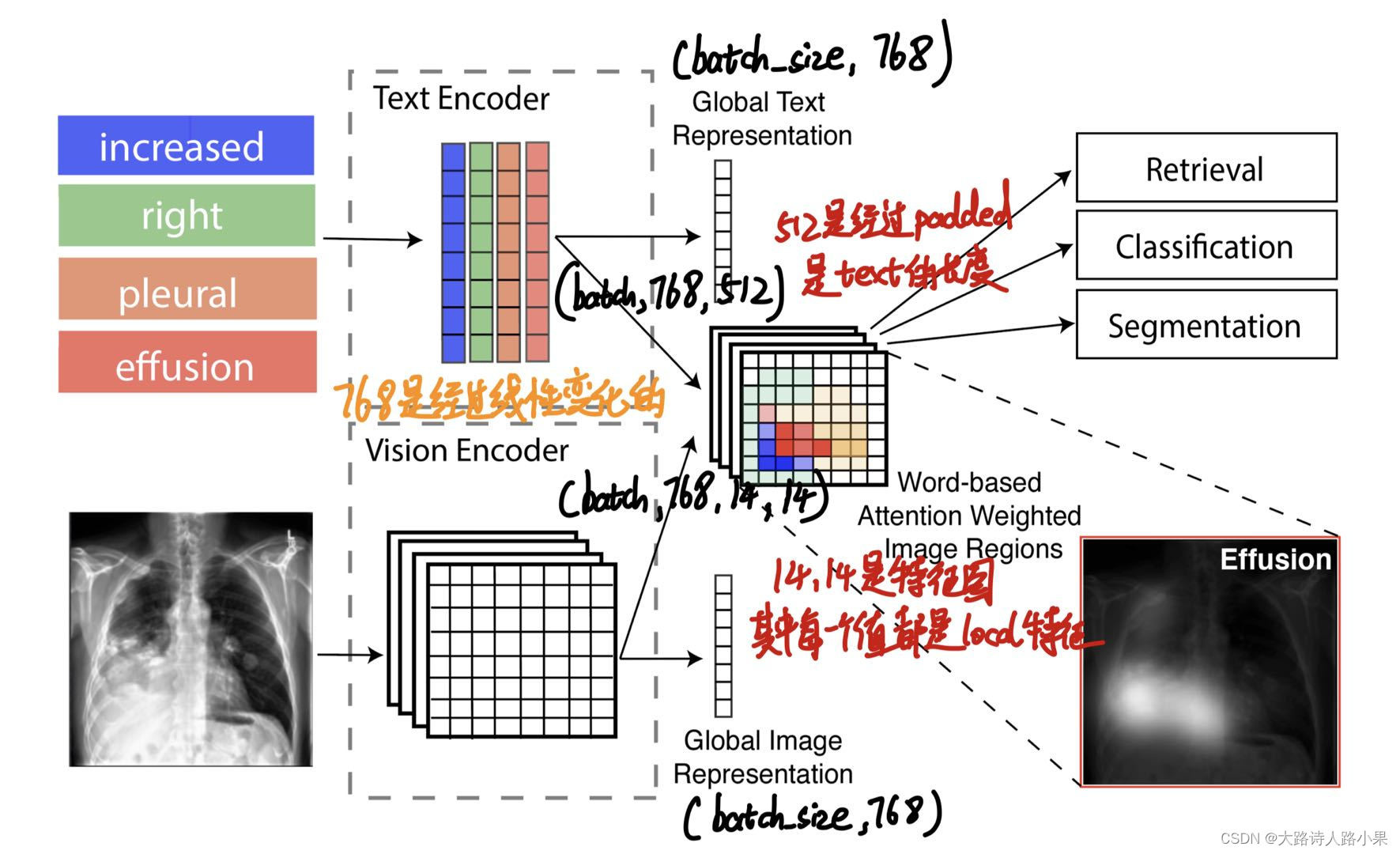
记录一下feature map的生成过程
def calc_loss(self, img_emb_l, img_emb_g, text_emb_l, text_emb_g, sents):
l_loss0, l_loss1, attn_maps = self._calc_local_loss(
img_emb_l, text_emb_l, sents
)
def _calc_local_loss(self, img_emb_l, text_emb_l, sents):
cap_lens = [
len([w for w in sent if not w.startswith("[")]) + 1 for sent in sents
]
l_loss0, l_loss1, attn_maps = self.local_loss(
img_emb_l,
text_emb_l,
cap_lens,
temp1=self.temp1,
temp2=self.temp2,
temp3=self.temp3,
)
return l_loss0, l_loss1, attn_maps
def local_loss(
img_features, words_emb, cap_lens, temp1=4.0, temp2=5.0, temp3=10.0, agg="sum"
):
batch_size = img_features.shape[0]
att_maps = []
similarities = []
# cap_lens = cap_lens.data.tolist()
for i in range(words_emb.shape[0]):
# Get the i-th text description
words_num = cap_lens[i] # 25
# TODO: remove [SEP]
# word = words_emb[i, :, 1:words_num+1].unsqueeze(0).contiguous() # [1, 768, 25]
word = words_emb[i, :, :words_num].unsqueeze(0).contiguous() # [1, 768, 25]
word = word.repeat(batch_size, 1, 1) # [48, 768, 25]
context = img_features # [48, 768, 19, 19]
weiContext, attn = attention_fn(
word, context, temp1
) # [48, 768, 25], [48, 25, 19, 19]
att_maps.append(
attn[i].unsqueeze(0).contiguous()
) # add attention for curr index [25, 19, 19]
word = word.transpose(1, 2).contiguous() # [48, 25, 768]
weiContext = weiContext.transpose(1, 2).contiguous() # [48, 25, 768]
word = word.view(batch_size * words_num, -1) # [1200, 768]
weiContext = weiContext.view(batch_size * words_num, -1) # [1200, 768]
row_sim = cosine_similarity(word, weiContext)
row_sim = row_sim.view(batch_size, words_num) # [48, 25]
row_sim.mul_(temp2).exp_()
if agg == "sum":
row_sim = row_sim.sum(dim=1, keepdim=True) # [48, 1]
else:
row_sim = row_sim.mean(dim=1, keepdim=True) # [48, 1]
row_sim = torch.log(row_sim)
similarities.append(row_sim)
similarities = torch.cat(similarities, 1) #
similarities = similarities * temp3
similarities1 = similarities.transpose(0, 1) # [48, 48]
labels = Variable(torch.LongTensor(range(batch_size))).to(similarities.device)
loss0 = nn.CrossEntropyLoss()(similarities, labels) # labels: arange(batch_size)
loss1 = nn.CrossEntropyLoss()(similarities1, labels)
return loss0, loss1, att_maps
def attention_fn(query, context, temp1):
"""
query: batch x ndf x queryL
context: batch x ndf x ih x iw (sourceL=ihxiw)
mask: batch_size x sourceL
"""
batch_size, queryL = query.size(0), query.size(2)
# 由于我的图片数量,在这里进行了更改,将ih和iw进行更改
# ih, iw = context.size(2), context.size(3)
ih, iw = context.size(3), context.size(4)
sourceL = ih * iw * 4
# --> batch x sourceL x ndf
# context = context.view(batch_size, -1, sourceL)
context=context.permute(0,2,1,3,4).view(batch_size,768,4,-1).contiguous().view(batch_size,768,-1).contiguous()
contextT = torch.transpose(context, 1, 2).contiguous()
# Get attention
# (batch x sourceL x ndf)(batch x ndf x queryL)
# -->batch x sourceL x queryL
attn = torch.bmm(contextT, query)
# --> batch*sourceL x queryL
attn = attn.view(batch_size * sourceL, queryL)
attn = nn.Softmax(dim=-1)(attn)
# --> batch x sourceL x queryL
attn = attn.view(batch_size, sourceL, queryL)
# --> batch*queryL x sourceL
attn = torch.transpose(attn, 1, 2).contiguous()
attn = attn.view(batch_size * queryL, sourceL)
attn = attn * temp1
attn = nn.Softmax(dim=-1)(attn)
attn = attn.view(batch_size, queryL, sourceL)
# --> batch x sourceL x queryL
attnT = torch.transpose(attn, 1, 2).contiguous()
# (batch x ndf x sourceL)(batch x sourceL x queryL)
# --> batch x ndf x queryL
weightedContext = torch.bmm(context, attnT)
return weightedContext, attn.view(batch_size,queryL,4,-1).contiguous().view(batch_size,queryL,4,ih,iw).contiguous()
这样就得到attention map
然后就是和原来的图片进行匹配
def plot_attn_maps(self, attn_maps, imgs, sents, epoch_idx=0, batch_idx=0):
img_set, _ = utils.Mybuild_attention_images(
imgs,
attn_maps,
max_word_num=self.cfg.data.text.word_num,
nvis=self.cfg.train.nvis,
rand_vis=self.cfg.train.rand_vis,
sentences=sents,
)
if img_set is not None:
# Convert the data type of img_set to uint8
img_set_uint8 = img_set.astype(np.uint8)
im = Image.fromarray(img_set_uint8)
fullpath = (
f"{self.cfg.output_dir}/"
f"attention_maps_epoch{epoch_idx}_"
f"{batch_idx}.png"
)
im.save(fullpath)
def Mybuild_attention_images(
real_imgs, # [batch_size, 4, 3, 3136, 3136]
attn_maps, # List of [1, number_word, 4, 14, 14] for each item in batch
max_word_num=None,
nvis=8,
rand_vis=False,
sentences=None,
):
nvis=5
batch_size, num_imgs, _, img_h, img_w = real_imgs.shape
_, _, _, att_sze, _ = attn_maps[0].shape # Assuming attn_maps are uniform in size
# Adjustments for handling sentences and selecting visualizations
word_counts = [len(sent) + 1 for sent in sentences]
max_word_num = max(word_counts)
loop_idx = np.random.choice(batch_size, size=min(nvis, batch_size), replace=False) if rand_vis else np.arange(min(nvis, batch_size))
# Determine visualization size based on attention size
vis_size = att_sze * 16 if att_sze in [17, 19] else min(img_h, img_w)
text_canvas = np.ones([batch_size * FONT_MAX, (max_word_num + 2) * (vis_size + 2), 3], dtype=np.uint8) * 255
# Upsample real images to uniform size
real_imgs_upsampled = nn.functional.interpolate(real_imgs.view(-1, 3, img_h, img_w), size=(vis_size, vis_size), mode='bilinear', align_corners=False)
real_imgs_upsampled = real_imgs_upsampled.view(batch_size, num_imgs, 3, vis_size, vis_size)
real_imgs_upsampled = (real_imgs_upsampled + 1) / 2.0 # Normalize to [0, 1]
# Prepare canvas for drawing attention maps
img_set = []
for i in loop_idx:
print(f"这个是第{i}张图片")
# Process each image and its attention map in the selected batch
img_group = real_imgs_upsampled[i] # [4, 3, vis_size, vis_size]
attn_group = [attn_maps[i][0, :, j] for j in range(num_imgs)] # List of [number_word, 14, 14] for each image
# Process and visualize each image and attention map
row_imgs, row_attentions = [], []
for img, attn_map in zip(img_group, attn_group):
img_np = img.permute(1, 2, 0).cpu().numpy() # Convert to numpy [vis_size, vis_size, 3]
row_imgs.extend([img_np, np.zeros((vis_size, 2, 3))]) # Image and padding
# Process each word's attention map for this image
attn_visualizations = []
for word_attn in attn_map:
# Upscale and visualize attention map
word_attn_upscaled = skimage.transform.resize(word_attn.cpu().detach().numpy(), (vis_size, vis_size), mode='constant')
attn_visualizations.append(word_attn_upscaled)
# Mean attention map across words for this image
mean_attn = np.mean(attn_visualizations, axis=0)
# Ensure mean_attn has a third dimension for RGB channels, duplicating the grayscale values across 3 channels
mean_attn_rgb = np.stack([mean_attn]*3, axis=-1) # Duplicate grayscale values across 3 channels
row_attentions.extend([mean_attn_rgb, np.zeros((vis_size, 2, 3))]) # Attention and padding with correct shape
# Combine image and attention rows
row_imgs_merged = np.concatenate(row_imgs, axis=1) # Merge images horizontally
row_attentions_merged = np.concatenate(row_attentions, axis=1) # Merge attentions horizontally
# Merge images and attention visualizations vertically
full_row = np.concatenate([row_imgs_merged, row_attentions_merged], axis=0)
img_set.append(full_row)
if img_set:
img_set = np.concatenate(img_set, axis=0) # Concatenate all rows vertically
return img_set, sentences
return None, None
-
计算公式:
-
计算公式

注意力计算

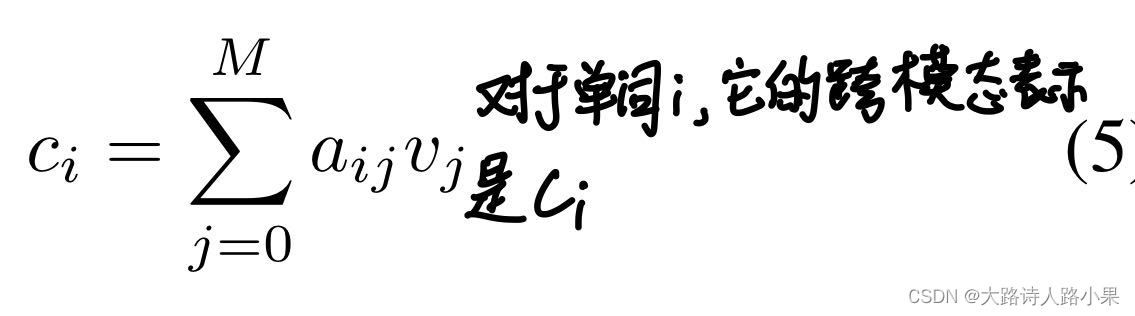














 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









