






Cross-modal Memory Networks for Radiology Report Generation 精读
1. Abstract:
Medical imaging plays a significant role in clinical practice of medical diagnosis, where the text reports of the images are essential in understanding them and facilitating later treatments. By generating the reports automatically, it is beneficial to help lighten the burden of radiologists and significantly promote clinical automation, which already attracts much attention in applying artificial intelligence to medical domain. Previous studies mainly follow the encoder-decoder paradigm and focus on the aspect of text generation, with few studies considering the importance of cross-modal mappings and explicitly exploit such mappings to facilitate radiology report generation.
- 说明了以前都是Seq2Seq的研究
- 很少研究关注到了利用模态之间的交融
In this paper, we propose a cross-modal memory networks (CMN) to enhance the encoderdecoder framework for radiology report generation, where a shared memory is designed to record the alignment between images and texts so as to facilitate the interaction and generation across modalities. Experimental results illustrate the effectiveness of our proposed model,
where state-of-the-art performance is achieved on two widely used benchmark datasets, i.e., IU X-Ray and MIMIC-CXR. Further analyses also prove that our model is able to better align information from radiology images and texts so as to help generating more accurate reports in terms of clinical indicators [1]
2. Introduction:
Interpreting radiology images (e.g., chest X-ray) and writing diagnostic reports are essential operations in clinical practice and normally requires considerable manual workload. Therefore, radiology report generation, which aims to automatically generate a free-text description based on a radiograph, is highly desired to ease the burden of radiologists while maintaining the quality of health care. Recently, substantial progress has been made towards research on automated radiology report generation models.
2.1 relation study
-
(Jing et al., 2018;
-
-
Background:
- The complex structures between and within sections of the reports pose a great challenge to the automatic report generation.Specifically, the section Impression is a diagnostic summarization over the section Findings; and the appearance of normality dominates each section over that of abnormality. Existing studies rarely explore and consider this fundamental structure information.
-
-
Motivation:
-
First, we propose a
two-stage strategy that explicitly models the
relationship between Findings and
Impression.
Second, we design a novel cooperative multi-agent system that implicitly captures the imbalanced distribution between abnormality and normality.
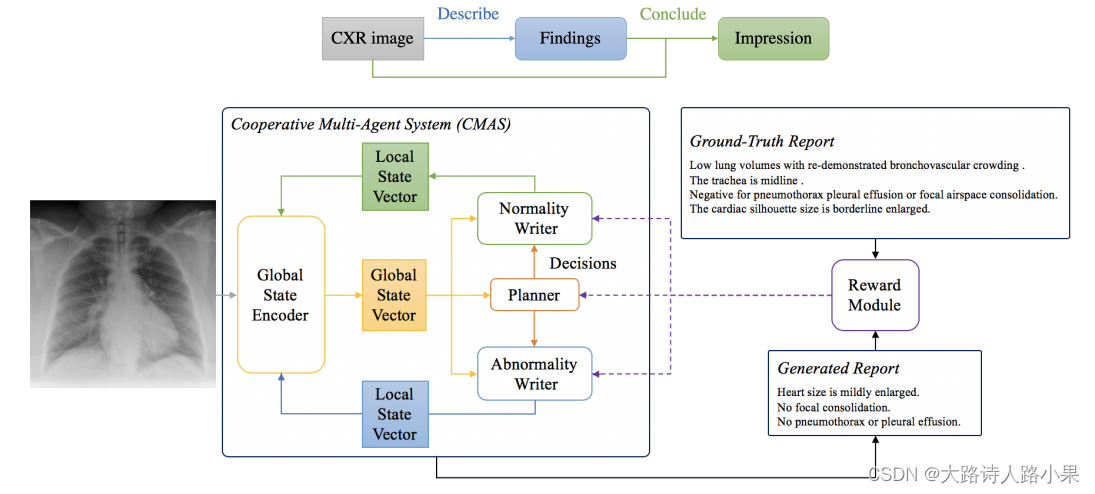
(Jing et al., 2019;
-
First, we propose a
two-stage strategy that explicitly models the
relationship between Findings and
-
-
Background:
- a complete report contains multiple heterogeneous forms of information, including findings and tags. Abnormal regions in medical images are difficult to identify. The reports are typically long, containing multiple sentences.
-
-
Motivation:
-
Build a multi-task learning framework which jointly performs the prediction of tags and the generation of paragraphs. Propose a
co-attention mechanism to
localize regions containing
abnormalities and generate
narrations for them. Develop a hierarchical LSTM model to generate long paragraphs.
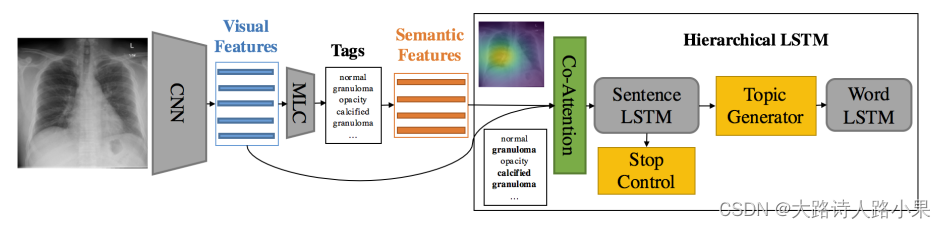
(Li et al., 2018;
-
Build a multi-task learning framework which jointly performs the prediction of tags and the generation of paragraphs. Propose a
co-attention mechanism to
localize regions containing
abnormalities and generate
narrations for them. Develop a hierarchical LSTM model to generate long paragraphs.
-
-
Motivation:
-
Hybrid Retrieval-Generation Reinforced Agent (HRGR-Agent) which reconciles traditional retrieval-based approaches populated with human
prior knowledge, with modern learning-based approaches to achieve
structured, robust, and diverse report generation. HRGR-Agent employs a hierarchical decisionmaking procedure. For each sentence, a high-level retrieval policy module chooses to either retrieve a
template sentence from an off-the-shelf
template database, or invoke a low-level generation module to generate a new sentence. HRGR-Agent is updated via reinforcement learning, guided by sentence-level and word-level rewards.
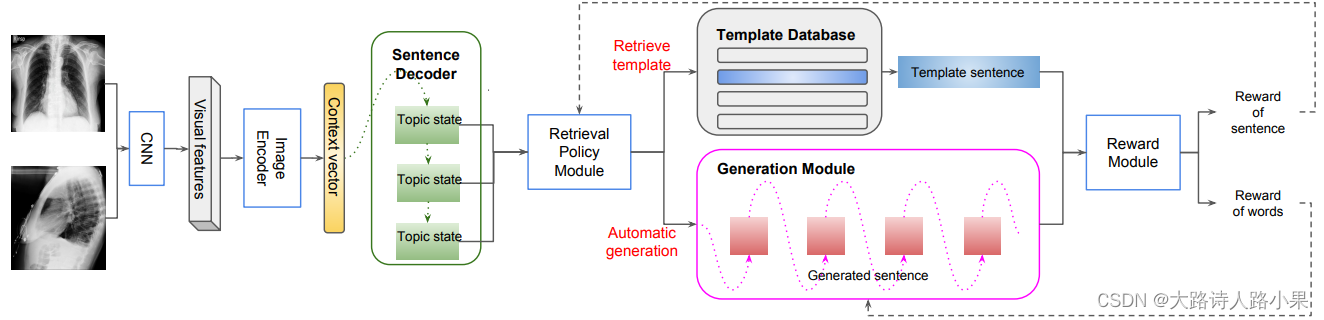
-
Hybrid Retrieval-Generation Reinforced Agent (HRGR-Agent) which reconciles traditional retrieval-based approaches populated with human
prior knowledge, with modern learning-based approaches to achieve
structured, robust, and diverse report generation. HRGR-Agent employs a hierarchical decisionmaking procedure. For each sentence, a high-level retrieval policy module chooses to either retrieve a
template sentence from an off-the-shelf
template database, or invoke a low-level generation module to generate a new sentence. HRGR-Agent is updated via reinforcement learning, guided by sentence-level and word-level rewards.
Most existing studies adopt a conventional encoder-decoder architecture, with convolutional neural networks (CNNs) as the encoder and recurrent (e.g., LSTM/GRU) or non-recurrent networks (e.g., Transformer) as the decoder following the image captioning paradigm. Although these methods have achieved remarkable performance, they are still restrained in fully employing the information across radiology images and reports, such as the mappings demonstrated in Figure 1 that aligned visual and
textual features point to the same content. The reason for the restraint comes from both the limitation of annotated correspondences between image and text for supervised learning as well as the lack of good model design to learn the correspondences. Unfortunately, few studies2 are dedicated to solving the restraint. Therefore, it is expected to have a better solution to model the alignments across modalities and further improve the generation ability, although promising results are continuously acquired by other approaches.
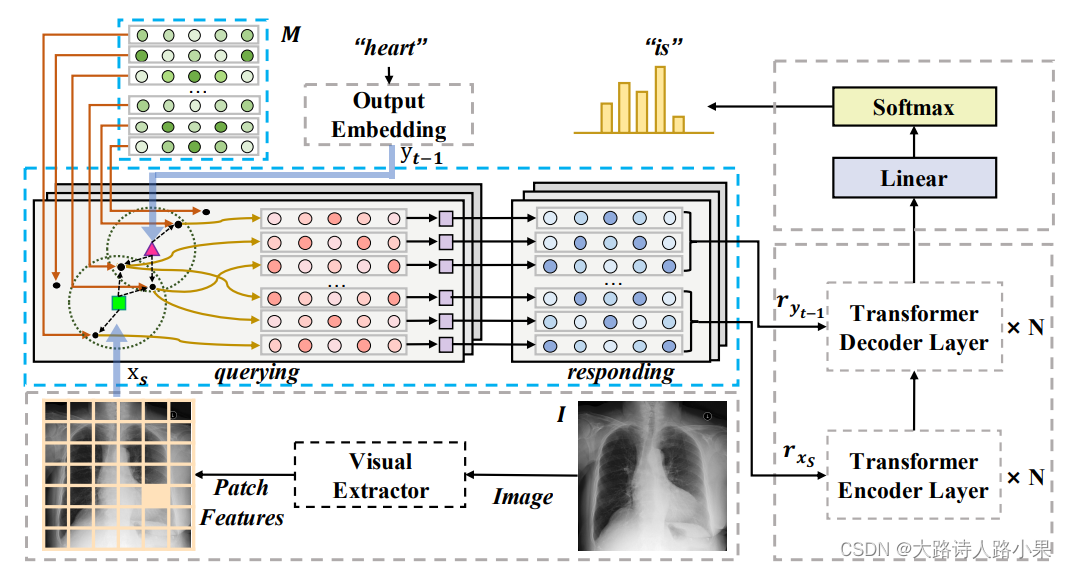
In this paper, we propose an effective yet simple approach to radiology report generation enhanced by cross-modal memory networks (CMN), which is designed to facilitate the interactions across modalities (i.e., images and texts). In detail, we use a memory matrix to store the cross-modal information and use it to perform memory querying and memory responding for the visual and textual features, where for memory querying, we extract the most related memory vectors from the matrix and compute their weights according to the input visual and textual features, and then generate responses by weighting the queried memory vectors. Afterwards, the responses corresponding to the input visual and textual features are fed into the encoder and decoder, so as to generate reports enhanced by such explicitly learned cross-modal information.
3. Method: (MEM+CMN)
3.1 跳过视觉编码器,这里就重点解读一下CMN (Cross-model memory network)
To model the alignment between image and text, existing studies tend to map between images and texts directly from their encoded representations (e.g., Jing et al. (2018) used a co-attention to do so). However, this process always suffers from the limitation that the representations across modalities are hard to be aligned, so that an intermediate medium is expected to enhance and smooth such mapping. To address the limitation, we propose to use CMN to better model the image-text alignment, so as to facilitate the report generation proces.
With using the proposed CMN, the mapping and encoding can be described in the following procedure.
使用(intermediate medium)这样的思想,应用在多模态领域非常常见,本质一样,叫法不同
To model the alignment between image and text, existing studies tend to map between images and texts directly from their encoded representations (e.g., Jing et al. (2018) used a co-attention to do so). However, this process always suffers from the limitation that the representations across modalities are hard to be aligned, so that an intermediate medium is expected to enhance and smooth such mapping. To address the limitation, we propose to use CMN to better model the image-text alignment, so as to facilitate the report generation process. With using the proposed CMN, the mapping and encoding can be described in the following procedure. Given a source sequence {x1, x2, …, xS} (features extracted from the visual extractor) from an image, we feed it to this module to obtain the memory responses of the visual features {rx1 , rx2 , …, rxS }. Similarly, given a generated
sequence {y1, y2, …, yt−1} with its embedding {y1, y2, …, yt−1}, it is also fed to the cross-modal memory networks to output the memory responses of the textual features {ry1 , ry2 , …, ryt−1 }. In doing so, the shared information of visual and textual features can be recorded in the memory so that the entire learning process is able to explicitly map between the images and texts. Specifically, the cross-modal memory networks employs a matrix to preserve information for encoding and decoding process, where each row of the matrix (i.e., a memory vector) records particular cross-modal information connecting images and texts. We denote the matrix as M = {m1, m2, …, mi , …, mN }, where N represents the number of memory vectors and mi ∈ Rd the memory vector at row i with d referring to its dimension. During the process of report generation, CMN is operated with two main steps, namely, querying and responding, whose details are described as follows.4
Memory Querying We apply multi-thread5 querying to perform this operation, where in each threadthe querying process follows the same procedure described as follows. In querying memory vectors, the first step is to ensure the input visual and textual features are in the same representation space. Therefore, we convert each memory vector in M as well as input features through linear transformation by
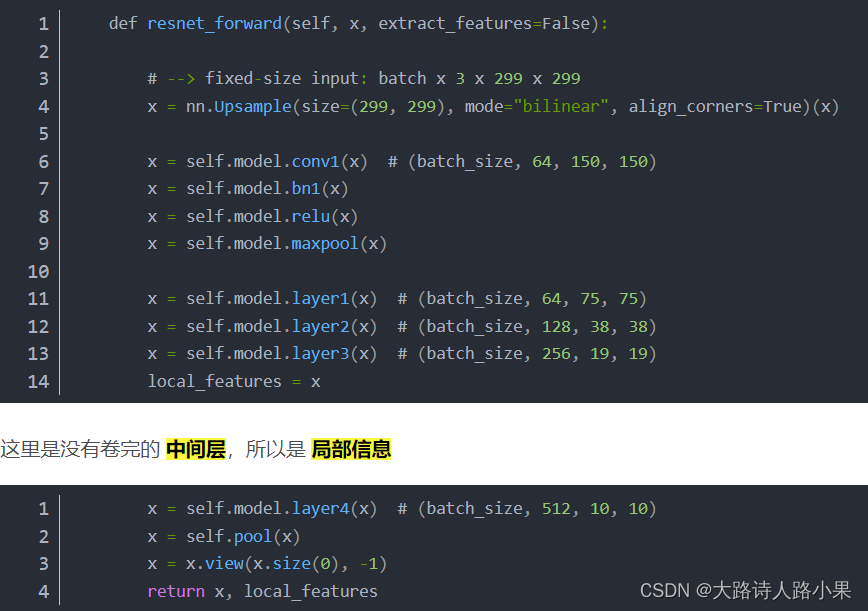
视觉编码器的输出是
def forward(self, images, targets=None, mode='train', update_opts={}):
embed()
num_images = images.shape[1]
att_feats_list = []
fc_feats_list = []
for i in range(num_images):
att_feats, fc_feats = self.visual_extractor(images[:, i])
att_feats_list.append(att_feats)
fc_feats_list.append(fc_feats)
fc_feats = torch.cat(fc_feats_list, dim=1)
att_feats = torch.cat(att_feats_list, dim=1)
embed()
if mode == 'train':
output = self.encoder_decoder(fc_feats, att_feats, targets, mode='forward')
return output
elif mode == 'sample':
output, output_probs = self.encoder_decoder(fc_feats, att_feats, mode='sample', update_opts=update_opts)
return output, output_probs
else:
raise ValueError
In [1]: fc_feats.size()
Out[1]: torch.Size([10, 8192]) 这里 8192 是 2048*4=8192
In [2]: att_feats.size()
Out[2]: torch.Size([10, 196, 2048]) 这里 196 是 7*7*4=196
这里其实是视觉编码器的提取
class CustomResNet(nn.Module):
def __init__(self, original_model):
super(CustomResNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=91, stride=28, padding=36, bias=False),
original_model.bn1,
original_model.relu,
original_model.maxpool,
original_model.layer1,
original_model.layer2,
original_model.layer3,
original_model.layer4,
)
def forward(self, x):
x = self.features(x)
return x
class MyVisualExtractor(nn.Module):
def __init__(self, args=None):
super(MyVisualExtractor, self).__init__()
self.visual_extractor = 'resnet50'
original_model = models.resnet50(pretrained=False)
original_model.load_state_dict(torch.load("/public_bme/data/breast-10-12/CausalFromText/resnet50-0676ba61.pth"))
self.model = CustomResNet(original_model)
self.avg_fnt = torch.nn.AvgPool2d(kernel_size=7, stride=1, padding=0)
def forward(self, images):
patch_feats = self.model(images)
avg_feats = self.avg_fnt(patch_feats).squeeze().reshape(-1, patch_feats.size(1))
batch_size, feat_size, _, _ = patch_feats.shape
patch_feats = patch_feats.reshape(batch_size, feat_size, -1).permute(0, 2, 1)
return patch_feats, avg_feats
这里特征的选择实际上由一曲同工之妙,基本上特征都是如此选择
这里 output = self.encoder_decoder(fc_feats, att_feats, targets, mode=‘forward’)
3.1 Encoder-Decoder 输出文本结构
The encoder-decoder in our model is built upon standard Transformer (which is a powerful architecture that achieved state-of-the-art in many tasks), where memory responses of visual and textual features are functionalized as the input of the encoder and decoder so as to enhance the generation process. In detail, as the first step, the memory responses.
这里它将 CMN 和 encoder-decode r的结构都整合到了一起
def _forward(self, fc_feats, att_feats, seq, att_masks=None):
att_feats, seq, att_masks, seq_mask = self._prepare_feature_forward(att_feats, att_masks, seq)
out = self.model(att_feats, seq, att_masks, seq_mask, memory_matrix=self.memory_matrix)
outputs = F.log_softmax(self.logit(out), dim=-1)
return outputs
-
变量解读:
-
att_feats: 自然不必多说,所有局部特征
fc_feats: 全局特征经过AvgPooling之后的结果
seq: 生成目标的文本 token_ids 表示
def _prepare_feature_forward(self, att_feats, att_masks=None, seq=None):
att_feats, att_masks = self.clip_att(att_feats, att_masks)
att_feats = pack_wrapper(self.att_embed, att_feats, att_masks)
if att_masks is None:
att_masks = att_feats.new_ones(att_feats.shape[:2], dtype=torch.long)
# Memory querying and responding for visual features
dummy_memory_matrix = self.memory_matrix.unsqueeze(0).expand(att_feats.size(0), self.memory_matrix.size(0), self.memory_matrix.size(1))
responses = self.cmn(att_feats, dummy_memory_matrix, dummy_memory_matrix)
att_feats = att_feats + responses
# Memory querying and responding for visual features
att_masks = att_masks.unsqueeze(-2)
if seq is not None:
seq = seq[:, :-1]
seq_mask = (seq.data > 0)
seq_mask[:, 0] += True
seq_mask = seq_mask.unsqueeze(-2)
seq_mask = seq_mask & subsequent_mask(seq.size(-1)).to(seq_mask)
else:
seq_mask = None
return att_feats, seq, att_masks, seq_mask
att_feats, att_masks = self.clip_att(att_feats, att_masks)
这里clip_att中clip确实剪裁的意思,而不是CLIP:😐,当然这里就是none,没有视觉的mask就是直接返回原来的样子
def clip_att(self, att_feats, att_masks):
# Clip the length of att_masks and att_feats to the maximum length
if att_masks is not None:
max_len = att_masks.data.long().sum(1).max()
att_feats = att_feats[:, :max_len].contiguous()
att_masks = att_masks[:, :max_len].contiguous()
return att_feats, att_masks
att_feats = pack_wrapper(self.att_embed, att_feats, att_masks)
这里将视觉编码的嵌入维度进行整理,让它编程transformer的维度512,(这里transformer的参数是512,8,…)
In [14]: att_masks==None
Out[14]: True
In [15]: att_feats_ = pack_wrapper(self.att_embed, att_feats, att_masks)
In [16]: att_feats.shape
Out[16]: torch.Size([10, 196, 2048])
In [17]: att_feats_.shape
Out[17]: torch.Size([10, 196, 512])
In [20]: self.att_embed
Out[20]:
Sequential(
(0): Linear(in_features=2048, out_features=512, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
)
-
if att_masks is None:
- att_masks = att_feats.new_ones(att_feats.shape[:2], dtype=torch.long)
这里,att_masks全部都改成了等大小的1矩阵
In [22]: att_feats.shape
Out[22]: torch.Size([10, 196, 512])
In [23]: att_masks is None
Out[23]: True
In [24]: att_masks_ = att_feats.new_ones(att_feats.shape[:2], dtype=torch.long)
In [25]: att_masks_.shape
Out[25]: torch.Size([10, 196])
In [26]: att_masks
In [27]: att_masks_
Out[27]:
tensor([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
...,
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]], device='cuda:0')
dummy_memory_matrix = self.memory_matrix.unsqueeze(0).expand(att_feats.size(0), self.memory_matrix.size(0), self.memory_matrix.size(1))
In [29]: dummy_memory_matrix.shape
Out[29]: torch.Size([10, 2048, 512])
responses = self.cmn(att_feats, dummy_memory_matrix, dummy_memory_matrix)
In [28]: dummy_memory_matrix = self.memory_matrix.unsqueeze(0).expand(att_feats.size(0), self.memory_matrix.size(0), self.memory_matrix.size(1))
In [29]: dummy_memory_matrix.shape
Out[29]: torch.Size([10, 2048, 512])
responses = self.cmn(att_feats, dummy_memory_matrix, dummy_memory_matrix)
In [32]: responses = self.cmn(att_feats, dummy_memory_matrix, dummy_memory_matrix)
In [33]: att_feats = att_feats + responses
In [34]: responses.shape
Out[34]: torch.Size([10, 196, 512])
att_masks = att_masks.unsqueeze(-2)
In [37]: att_masks = att_masks.unsqueeze(-2)
In [38]: att_masks.shape
Out[38]: torch.Size([10, 1, 196])
这里是生成一个seq的mask用于实现自回归特性,subsequent_mask生成一个 上三角形矩阵,其形状为[1, 237, 237]。这个矩阵用于确保解码器在生成 第i个词 时,只能利用 前i-1个词 的信息。这是通过将矩阵的上三角部分(不包括对角线)设置为无限大(或某个非常小的值,使得softmax后接近于0),从而在注意力机制的softmax步骤中忽略这些位置。
att_masks = att_masks.unsqueeze(-2)
if seq is not None:
seq = seq[:, :-1]
seq_mask = (seq.data > 0)
seq_mask[:, 0] += True
seq_mask = seq_mask.unsqueeze(-2)
seq_mask = seq_mask & subsequent_mask(seq.size(-1)).to(seq_mask)
else:
seq_mask = None
out = self.model(att_feats, seq, att_masks, seq_mask, memory_matrix=self.memory_matrix)
outputs = F.log_softmax(self.logit(out), dim=-1)
self.logit = nn.Linear(args.d_model, tgt_vocab)
这里 tgt_vocab 是自己的词汇表大小
整体的结构如下:
BaseCMN(
(att_embed): Sequential(
(0): Linear(in_features=2048, out_features=512, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
)
(cmn): MultiThreadMemory(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(model): Transformer(
(encoder): Encoder(
(layers): ModuleList(
(0-2): 3 x EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=512, out_features=512, bias=True)
(w_2): Linear(in_features=512, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0-1): 2 x SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(decoder): Decoder(
(layers): ModuleList(
(0-2): 3 x DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w_1): Linear(in_features=512, out_features=512, bias=True)
(w_2): Linear(in_features=512, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0-2): 3 x SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(src_embed): Sequential(
(0): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(tgt_embed): Sequential(
(0): Embeddings(
(lut): Embedding(995, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(cmn): MultiThreadMemory(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(logit): Linear(in_features=512, out_features=995, bias=True)
)
文本生成
这里在进行文本生成任务中,会使用core函数
def core(self, it, fc_feats_ph, att_feats_ph, memory, state, mask):
if len(state) == 0:
ys = it.unsqueeze(1)
past = [fc_feats_ph.new_zeros(self.num_layers * 2, fc_feats_ph.shape[0], 0, self.d_model),
fc_feats_ph.new_zeros(self.num_layers * 2, fc_feats_ph.shape[0], 0, self.d_model)]
else:
ys = torch.cat([state[0][0], it.unsqueeze(1)], dim=1)
past = state[1:]
out, past = self.model.decode(memory, mask, ys, subsequent_mask(ys.size(1)).to(memory.device), past=past,
memory_matrix=self.memory_matrix)
if not self.training:
self._save_attns(start=len(state) == 0)
return out[:, -1], [ys.unsqueeze(0)] + past
-
变量解读
- it 是 一个向量,长度是batch,数值全是0
In [1]: it
Out[1]: tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0], device='cuda:0')
In [2]: fc_feats_ph.shape
Out[2]: torch.Size([10, 1])
In [3]: fc_feats_ph
Out[3]:
tensor([[0.5082],
[0.2918],
[0.1748],
[0.0422],
[1.0523],
[0.2418],
[0.2571],
[0.3879],
[0.0026],
[0.5894]], device='cuda:0')
In [4]: att_feats_ph.shape
Out[4]: torch.Size([10, 196, 1])
In [5]: memory.shape
Out[5]: torch.Size([10, 196, 512])
In [6]: state.shape
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[6], line 1
----> 1 state.shape
AttributeError: 'list' object has no attribute 'shape'
In [7]: len(state)
Out[7]: 0
In [8]: mask.shape
Out[8]: torch.Size([10, 1, 196])
会进行多次执行
In [1]: it
Out[1]:
tensor([146, 773, 228, 758, 496, 876, 837, 234, 834, 202, 574, 837, 837, 11,
861, 418, 626, 916, 954, 837, 492, 492, 444, 496, 410, 146, 180, 626,
496, 837], device='cuda:0')
In [2]: it.shape
Out[2]: torch.Size([30])
In [3]: fc_feats_ph.shape #是向量,浮点数
Out[3]: torch.Size([30, 1])
In [5]: att_feats_ph.shape
Out[5]: torch.Size([30, 196, 1])
In [6]: memory.shape
Out[6]: torch.Size([30, 196, 512])
In [7]: state #省略了很多的长度
Out[7]:
[tensor([[[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0]]], device='cuda:0'),
tensor([[[[-1.0590, -1.6030, 0.3035, ..., 0.4556, 1.2639, -1.5407]],
[[-1.0590, -1.6030, 0.3035, ..., 0.4556, 1.2639, -1.5407]],
[[-1.0590, -1.6030, 0.3035, ..., 0.4556, 1.2639, -1.5407]],
[[-0.1428, -0.0878, -0.6648, ..., -0.6233, 0.0521, -1.4025]],
[[-0.1428, -0.0878, -0.6648, ..., -0.6233, 0.0521, -1.4025]]]],
device='cuda:0'),
tensor([[[[ 1.3907, -0.5194, -0.0534, ..., -0.0214, 2.4703, 0.9141],
[ 0.8428, -0.9723, -0.5478, ..., -0.3474, 1.7776, 0.8079],
[ 0.3981, 0.7206, 0.2613, ..., 0.2059, 2.2061, -0.7881],
...,
[ 0.0896, -0.6097, 0.7392, ..., 0.9244, 0.6948, -0.2523],
[ 1.0226, -0.2629, 0.8477, ..., 0.1860, 1.6491, -0.7394],
[ 1.2010, -1.3017, -0.3003, ..., -0.3985, 0.7058, -0.5023]],
[[ 0.3424, 1.1858, -2.7764, ..., -0.3866, -0.8343, 0.4509],
[-0.4560, 0.9117, -2.4733, ..., -0.4313, 0.5420, 1.1446],
[ 0.3911, 1.3216, -1.4631, ..., 0.4841, -0.1636, 0.9398],
...,
[ 0.5365, 1.4327, -0.9134, ..., -1.0899, -1.0466, 0.4137],
[ 0.6558, 0.8353, -0.8673, ..., -0.3309, 0.1281, 1.8502],
[ 1.8772, 0.2582, -0.7166, ..., 0.7787, -1.4906, 0.9986]]]],
device='cuda:0')]
In [9]: len(state)
Out[9]: 3
In [10]: mask.shape
Out[10]: torch.Size([30, 1, 196])
5. 总结:
如果回顾整个模型,那么可以说,CMN的加入是这个模型的唯一不同。如果想要去除CMN,进行Base模型的测试可以直接更改这里注释的内容,其它内容都是一样的。
Step1: 删除CMN部分的传播函数
def _prepare_feature_forward(self, att_feats, att_masks=None, seq=None):
att_feats, att_masks = self.clip_att(att_feats, att_masks)
att_feats = pack_wrapper(self.att_embed, att_feats, att_masks)
if att_masks is None:
att_masks = att_feats.new_ones(att_feats.shape[:2], dtype=torch.long)
下面就是可以直接删除,就删掉CMN的运行
# Memory querying and responding for visual features
dummy_memory_matrix = self.memory_matrix.unsqueeze(0).expand(att_feats.size(0), self.memory_matrix.size(0), self.memory_matrix.size(1))
responses = self.cmn(att_feats, dummy_memory_matrix, dummy_memory_matrix)
att_feats = att_feats + responses
# Memory querying and responding for visual features
上面就是可以直接删除,就删掉CMN的运行
att_masks = att_masks.unsqueeze(-2)
if seq is not None:
seq = seq[:, :-1]
seq_mask = (seq.data > 0)
seq_mask[:, 0] += True
seq_mask = seq_mask.unsqueeze(-2)
seq_mask = seq_mask & subsequent_mask(seq.size(-1)).to(seq_mask)
else:
seq_mask = None
return att_feats, seq, att_masks, seq_mask
Step2: 删除Transformer中CMN的定义
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, cmn):
super(Transformer, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.cmn = cmn
def forward(self, src, tgt, src_mask, tgt_mask, memory_matrix):
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask, memory_matrix=memory_matrix)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask, past=None, memory_matrix=None):
embeddings = self.tgt_embed(tgt)
这里的decode函数内的embedding直接使用就是去掉了CMN
# Memory querying and responding for textual features
dummy_memory_matrix = memory_matrix.unsqueeze(0).expand(embeddings.size(0), memory_matrix.size(0), memory_matrix.size(1))
responses = self.cmn(embeddings, dummy_memory_matrix, dummy_memory_matrix)
embeddings = embeddings + responses
# Memory querying and responding for textual features
return self.decoder(embeddings, memory, src_mask, tgt_mask, past=past)















 3248
3248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









