






全身病灶定位的文章
我在《 An end-to-end multi-task system of automatic lesion detection and anatomical localization in whole-body bone scintigraphy by deep learning 》这个文章中,发现这个工作和这个病灶非常类似。
同时发现对于 (lesion detection)领域,Sadik(2006,2008,2009)都有研究,这是一个连续的工作,因此,我从Sadik 的文章入手,虽然Sadik的文章是从bone scan,但是和PET-CT的影像很像。
2006, Sadik,”A new computer-based decision-support system for the
interpretation of bone scans“
-
Sadik:
-
- 2006年,sadik对病灶的定位方法是thresholding algorithm,对器官的定位方法是也是阈值,将图片使用这些处理之后,提取量化特征,这些量化特征被输入神经网络,进行分类。
- 2008年,sadik改进了分割模型,使用了active-shape model模型,同时对分割的流程改进了,将骨骼分成4个类别进行区分,针对每一个区域进行迭代优化,使用了更大的数据集,使用了更大神经元个数。(输入神经炎里面的特征依然是量化结果的特征)
- 2009年,sadik对自己的CAD系统进行跟踪测试,证明了CAD系统的有效性。
ChatCAD:
-
- 2023年,ChatCAD,将医学信息初步与大预言模型进行结合。试图做出符合医疗需求的CAD模型,将CAD的概念和大预言模型的概念进行结合,进行诊断辅助。将疾病种类分类,疾病分割向量,caption输入进入大预言模型中,进行文本输出。
- 2024年,ChatCAD+, 加入了retrieve的过程,但同时也丢弃了其他网络CAD的信息,是图生文RAG版本,同时还具有chain-thought,跟上了图生文部分的主要思潮。(缺乏点临床关注度,技术性探索文章)
Raphael Sexauer:
-
- 2018年,在文章Comparing TNM Staging Completeness and Processing Time of Text‐Based Reports versus Fully Segmented and Annotated PET/CT Data of Non‐Small‐Cell Lung Cancer." 中,医生探究了,分割模型和文本模型的时间效益,证明了分割模型也许在临床使用效果更好。
Classification (Natural Language Processing Algorithm):
-
- 2024年,J. Martijn Nobel通过使用自然语言,对文本进行分类Natural Language Processing Algorithm Used for Staging Pulmonary Oncology from Free-Text Radiological Reports: “Including PET-CT and Validation Towards Clinical Use”使用语言模型逻辑,对文本报告进行分类。
Bradshaw (from findings to impression):
-
- 2024年,Bradshaw(Tyler J. Bradshaw 1)使用PET的findings文本信息,输入进入语言模型,输出impression的诊断结果,这个问题不同于CT,MRI,X-ray这样的任务,它的词汇和内容更加复杂,最终结果表明PEGASUS语言模型的结果效果最好。(有两篇文章,一张是arxiv,一个是journal of imaging)
- 仅仅进行图生文实际上没有医疗有效性,不符合医生的需要,同时在临床上看,仅仅生成文本报告不仅缺乏很多病理的分期信息,不是特别结构化,同时仅仅分析文本报告,而忽略分割模型,反而会导致医生分析时间的增加。
对于 CLIP 的文章,实际上,可以追溯到 VLP ,这样的多模态背景。对于文本定位的任务,比重很重要。在视觉和语言表征学习中,Grounding通常也表示,匹配,定位,关联的意思。
同时,我也注意到了一个问题,那就是为什么要做CLIP,为什么要alignment,我注意到了transformer结构,也就是注意力问题。实际上,信息的交互需要联系在一起,K,Q,V之间之所以有价值,就是特征向量相似。也就是,多模态里面alignment要做的就是通过对齐,加强交互能力。
-
大语言模型的开始
-
-
BERT (Google AI Language)
-
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
-
-
-
GPT1 (Open AI)
-
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
-
-
-
GPT3 (Open AI)
-
- Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.
-
-
-
RoBERTa (Facebook)
-
- Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
-
-
-
XLNet (Google AI Brain Team)
-
- Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems, pp. 5754–5764, 2019.
-
-
-
T5 (Google AI Brain Team)
-
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text
transformer. arXiv preprint arXiv:1910.10683, 2019.
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text
VLP, 领域,特征对齐------多模态领域------开山文章
-
-
-
(1) LXMERT:
-
UNC chapel hill, (HaoTan, MohitBansal)的文章, 是two-stream的架构,三个encoder,objection relationship encoder, language encoder, cross-modal encoder三个都是encoder

-
UNC chapel hill, (HaoTan, MohitBansal)的文章, 是two-stream的架构,三个encoder,objection relationship encoder, language encoder, cross-modal encoder三个都是encoder
-
-
(2) VL-T5, VL-BERT
-
UNC chapel hill (HaoTan, MohitBansal)学校的文章 Unifying Vision-and-Language Tasks via Text Generation,应该是在VLP领域,属于属于single-stream结构。应该是,第一个使用single model,parameter的模型,处理多模态数据,使用encoder-decoder结构。

-
UNC chapel hill (HaoTan, MohitBansal)学校的文章 Unifying Vision-and-Language Tasks via Text Generation,应该是在VLP领域,属于属于single-stream结构。应该是,第一个使用single model,parameter的模型,处理多模态数据,使用encoder-decoder结构。
-
-
(3) VisualBERT
-
Li, Liunian Harold, et al. “Visualbert: A simple and performant baseline for vision and language.” arXiv preprint arXiv:1908.03557 (2019).属于属于single-stream结构。

-
Li, Liunian Harold, et al. “Visualbert: A simple and performant baseline for vision and language.” arXiv preprint arXiv:1908.03557 (2019).属于属于single-stream结构。
-
-
(4) ViLBERT
-
Lu, Jiasen, et al. “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.” Advances in neural information processing systems 32 (2019).属于属于two-stream结构,有三个encoder,两个bert结构的encoder,一个co-encoder,不限长度输入。
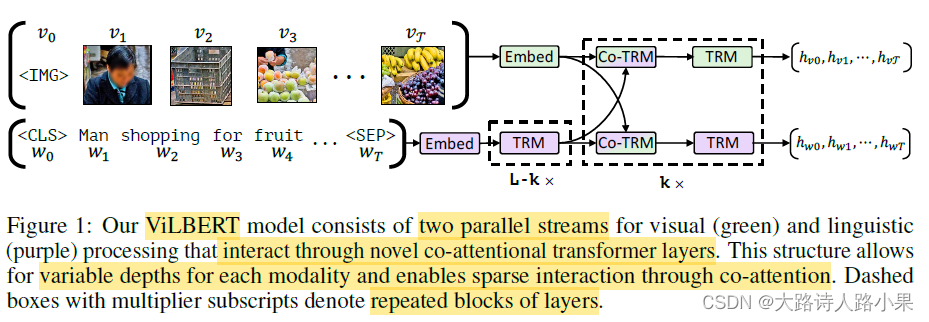
-
Lu, Jiasen, et al. “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.” Advances in neural information processing systems 32 (2019).属于属于two-stream结构,有三个encoder,两个bert结构的encoder,一个co-encoder,不限长度输入。
-
-
(5) UNITER
-
Chen, Yen-Chun, et al. “Uniter: Universal image-text representation learning.” European conference on computer vision. Cham: Springer International Publishing, 2020. 有两个 embedder

-
Chen, Yen-Chun, et al. “Uniter: Universal image-text representation learning.” European conference on computer vision. Cham: Springer International Publishing, 2020. 有两个 embedder
-
-
(6) VideoBERT (Google AI Research)
- Sun, Chen, et al. “Videobert: A joint model for video and language representation learning.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
-
-
(7) VLBERT (Google AI Research)
-
Su, Weijie, et al. “Vl-bert: Pre-training of generic visual-linguistic representations.” arXiv preprint arXiv:1908.08530 (2019).作者的结论是无论是single-stream还是two-stream,任务的表现结果的可以很好,可能是训练的任务,或者数据有作用而不是所谓的结构。

-
Su, Weijie, et al. “Vl-bert: Pre-training of generic visual-linguistic representations.” arXiv preprint arXiv:1908.08530 (2019).作者的结论是无论是single-stream还是two-stream,任务的表现结果的可以很好,可能是训练的任务,或者数据有作用而不是所谓的结构。
-
-
(7) OScar:
- Li, Xiujun, et al. “Oscar: Object-semantics aligned pre-training for vision-language tasks.” Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16. Springer International Publishing, 2020.。这个文章实际上,就是用对齐的技术,之不过是用tag标签进行的对齐。它的作用实际上就是CLIP的特征对其技术。这个原因可以通过t-SNE图观察到。
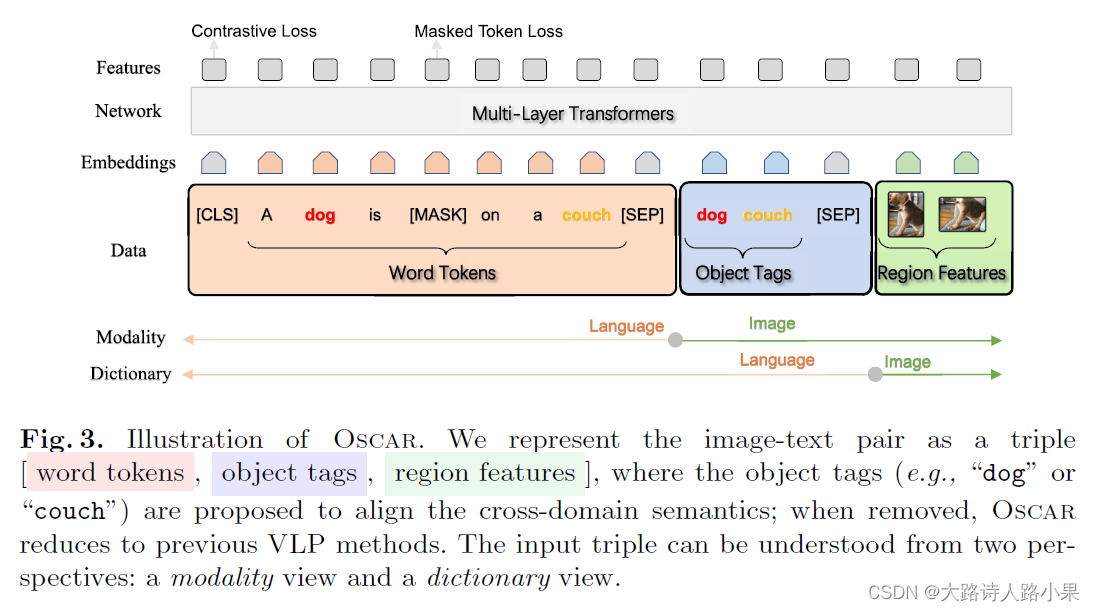
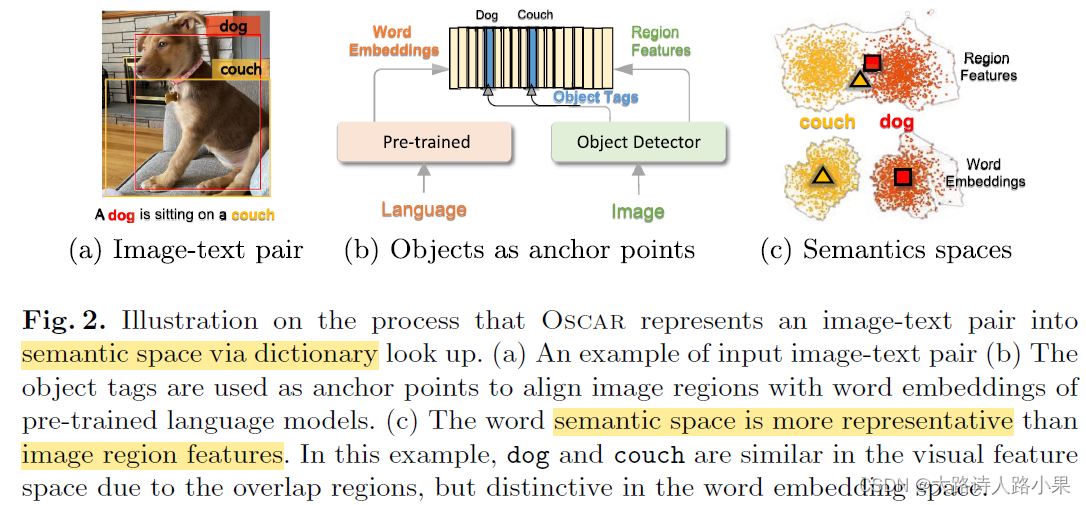
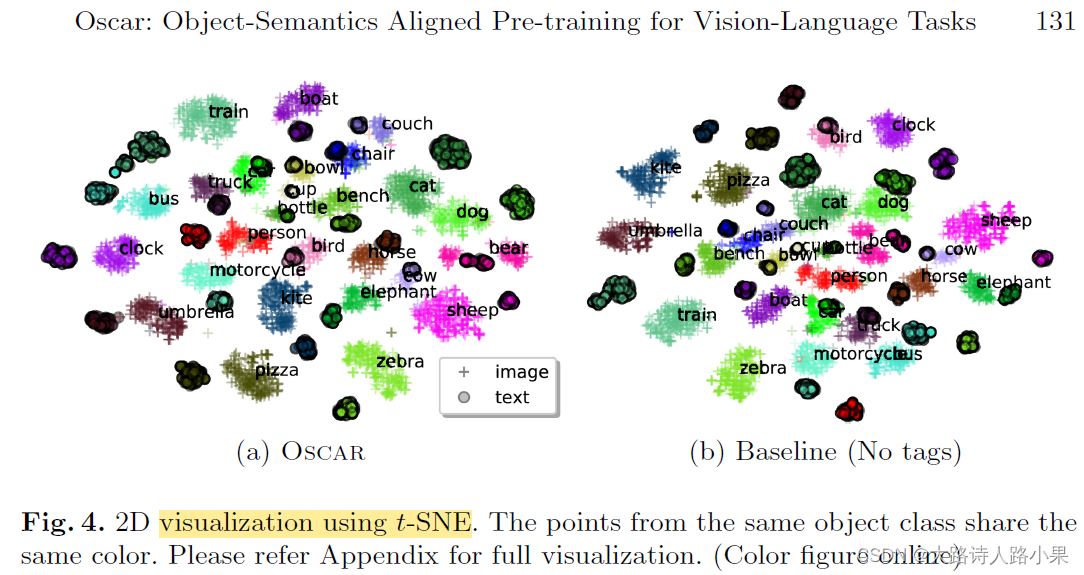
-
-
转折点 CLIP,ALBEF, BLIP : 随着研究的深入,研究者发现特征对齐,是非常重要的
-
-
CLIP
- Radford 使用的是,two-stream的结构,两个都是encoder,做的 ITC (Image-text contrastive learning)
-
-
ALBEF
- 使用的是,two-stream的结构,对齐后面还 fusion 融合,使用cross attention,在 MTM 和 ITM 任务上使用。
医学 VLP 的多模态文章:
-
-
-
GLoRIA:
-
- Wang sha
-
-
-
AFLoC:
-
- Wang shanshan, Zhang Kang 的文章Multi-modal vision-language model for generalizable annotation-free pathological lesions localization and clinical diagnosis这个文章使用比 GLoRIA 更多的,全局,局部,信息内容,目标内容是定位。更加符合我们的的目的,但同样是没有segmentation的信息,画出来的heatmap依然是模糊的,同时还是依然在2D图片上
-
-
-
MdeKILP:
-
- Xie Weidi的文章,Xie Weidi对医学语言大模型上的文章有很多,类似的其中一个是MedKLIP: Medical Knowledge Enhanced Language-Image Pre-Training是一个自监督的VLP任务,加入了domain-knowledge放入,文本语义实体中,在两种模态上使用基于transformer的fusion module
-















 1894
1894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









