数据集标签数量不均衡如何设计loss均衡数量 1. 思路出发点: 对于哪些数量分布比值较少的标签提供更多的loss注意力比重,如何提高训练注意力比重,也就是说,让模型的梯度更多的倾向于有利于数据标签分布较少的数据训练,对于loss来说就是扩大这个标签的loss 2.公式 这里面PI就是疾病的分布,它实际上对于log函数,PI的取值是0-1,之和为1,也就是对于数据集小的标签来说,负值越大,在logits里面对于与实际target的差距也就越大,对于loss来说也就越需要进行优化。 3. 注意这个logits是分类之前也就是sigmoid(使用多标签分类任务)之前使用的







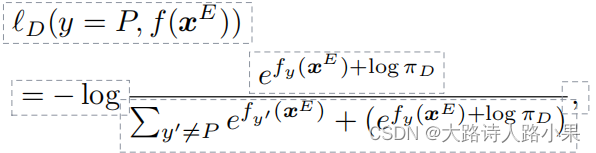














 1324
1324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






