






TCN、TCN-GRU、TCN-GRU-Attention、TCN-BiGRU、TCN-BiGRU-Attention)在结构原理上既有相似之处,也存在一些关键的不同点。以下是对这些模型的异同点以及它们之间优劣性的对比:
| 代码获取戳此:TCN合集(TCN-GRU、TCN--GRU--Attention、TCN-Bigru等) |
相同点
- TCN基础:所有模型都以时序卷积网络(Temporal Convolutional Network, TCN)为基础,利用因果卷积和空洞卷积(膨胀卷积)来处理时间序列数据,以捕捉长期依赖关系。
- 序列处理:这些模型都适用于处理序列数据,如时间序列预测、自然语言处理等任务。
异同点
- 结构扩展:
- TCN:基本的时序卷积网络结构,用于捕捉序列中的长期依赖关系。
- TCN-GRU/TCN-BiGRU:在TCN基础上,结合了门控循环单元(GRU)或双向门控循环单元(BiGRU)。这些RNN变体能够进一步增强模型对序列信息的处理能力,尤其是BiGRU能够捕捉双向的上下文信息。
- TCN-GRU-Attention/TCN-BiGRU-Attention:在TCN-GRU/TCN-BiGRU的基础上,引入了注意力机制(Attention)。注意力机制允许模型在处理序列数据时,对不同位置的信息进行适当的加权,从而更好地捕捉序列中的关键信息。
- 模型复杂度:
- 从TCN到TCN-GRU/TCN-BiGRU,再到TCN-GRU-Attention/TCN-BiGRU-Attention,模型的复杂度逐渐增加。这是因为RNN变体和注意力机制的引入增加了模型的参数数量和计算量。
- 性能:
- 在处理复杂时间序列数据时,TCN-GRU/TCN-BiGRU和TCN-GRU-Attention/TCN-BiGRU-Attention通常能够取得比TCN更好的性能,因为它们能够捕捉更丰富的序列信息和关键特征。
- 特别是TCN-GRU-Attention/TCN-BiGRU-Attention,通过引入注意力机制,模型能够更准确地识别序列中的关键信息,从而进一步提高性能。
优劣性对比
- TCN:
- 优点:结构简单,计算效率高,适用于处理长序列数据。
- 缺点:在处理复杂时间序列数据时,可能无法充分捕捉序列中的关键信息和长期依赖关系。
- TCN-GRU/TCN-BiGRU:
- 优点:结合了TCN和RNN变体的优点,能够同时捕捉序列中的局部特征和长期依赖关系,提高了模型的性能。
- 缺点:模型复杂度较高,需要更多的计算资源。此外,由于RNN变体的存在,模型可能更容易受到梯度消失或梯度爆炸问题的影响。
- TCN-GRU-Attention/TCN-BiGRU-Attention:
- 优点:在TCN-GRU/TCN-BiGRU的基础上引入了注意力机制,能够更准确地识别序列中的关键信息,进一步提高模型的性能。
- 缺点:模型复杂度最高,需要最多的计算资源。此外,注意力机制的引入可能使模型在训练过程中更容易出现过拟合问题。
总结
在选择这些模型时,需要根据具体任务的需求和数据的特点进行权衡。对于简单的序列处理任务,可以选择结构简单的TCN;对于复杂的时间序列预测或自然语言处理任务,可以选择性能更好的TCN-GRU/TCN-BiGRU或TCN-GRU-Attention/TCN-BiGRU-Attention模型。同时,还需要注意模型的复杂度和计算资源需求,以确保在实际应用中能够取得良好的性能。
TCN、TCN-GRU、TCN--GRU--Attention、TCN-Bigru、TCN-BiGRU-Attention
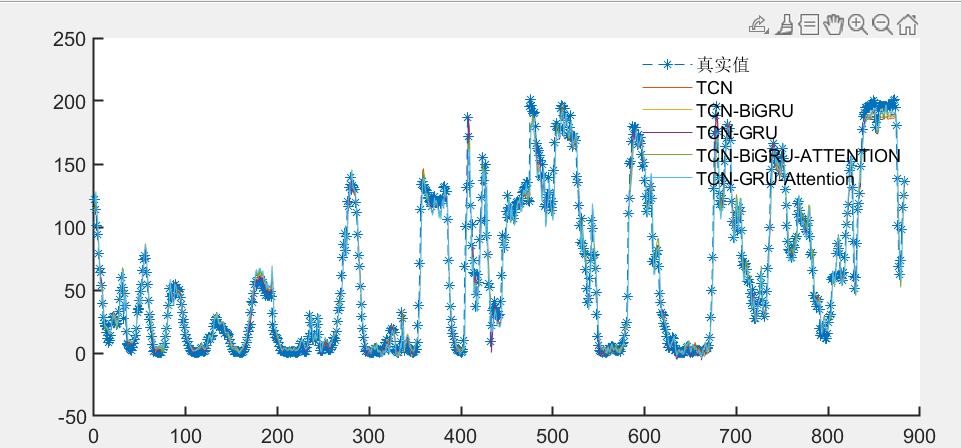
基于风电数据集进行预测效果对比:
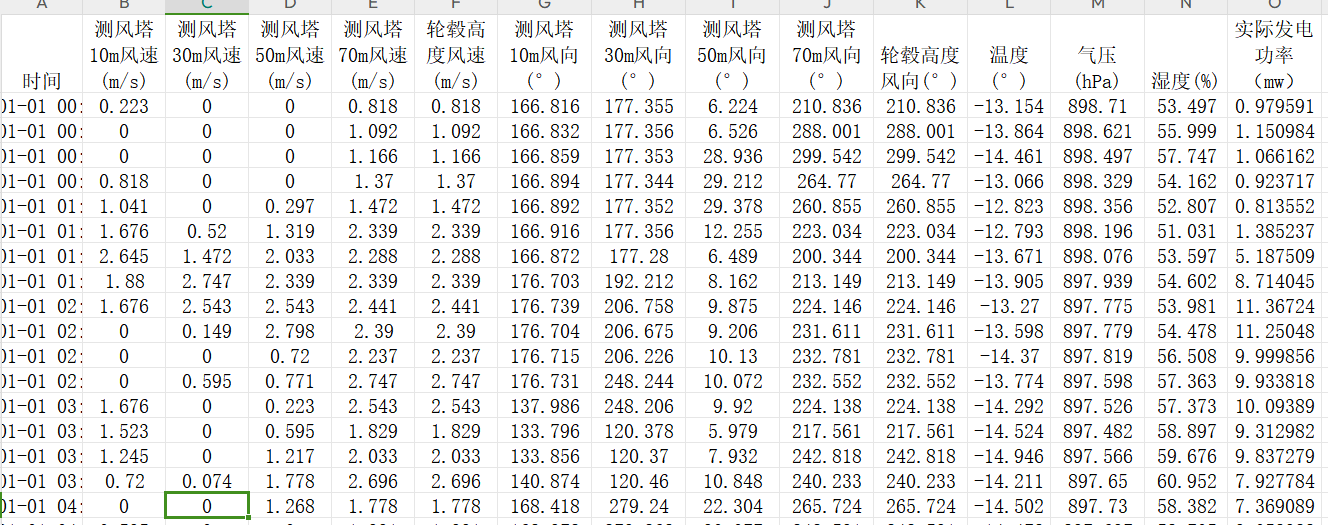
效果对比:
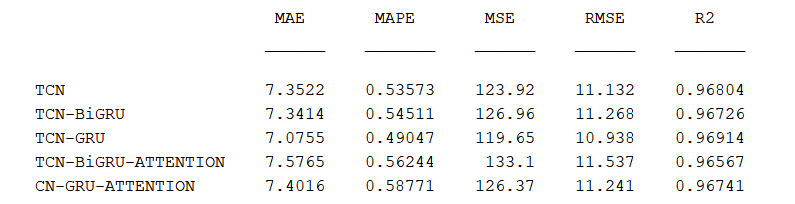
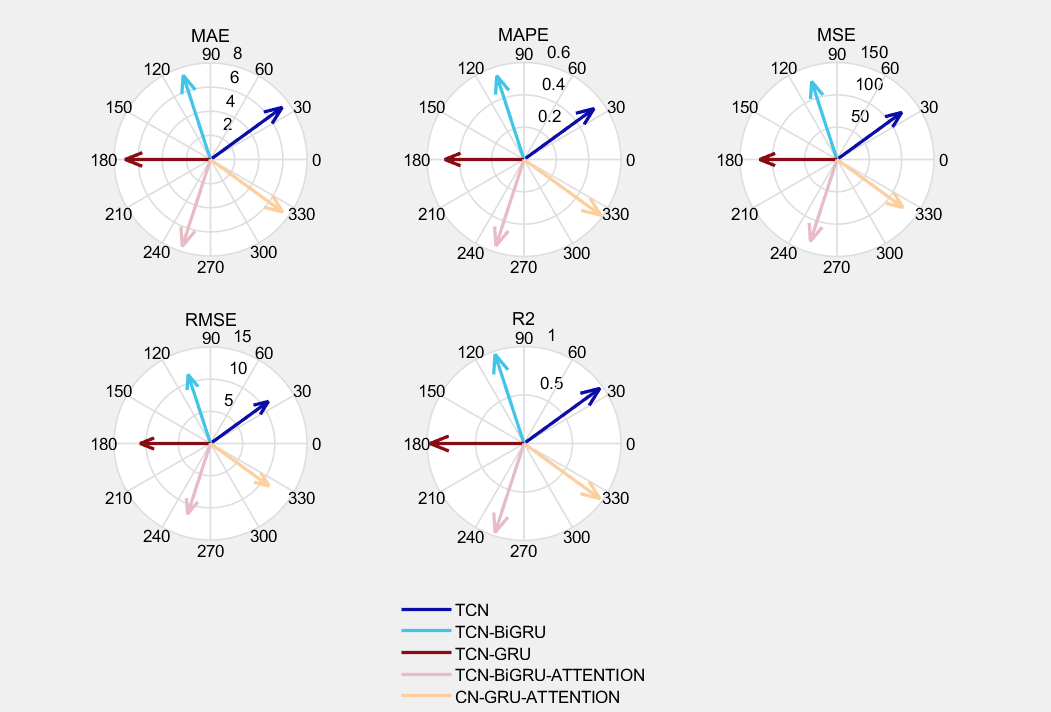
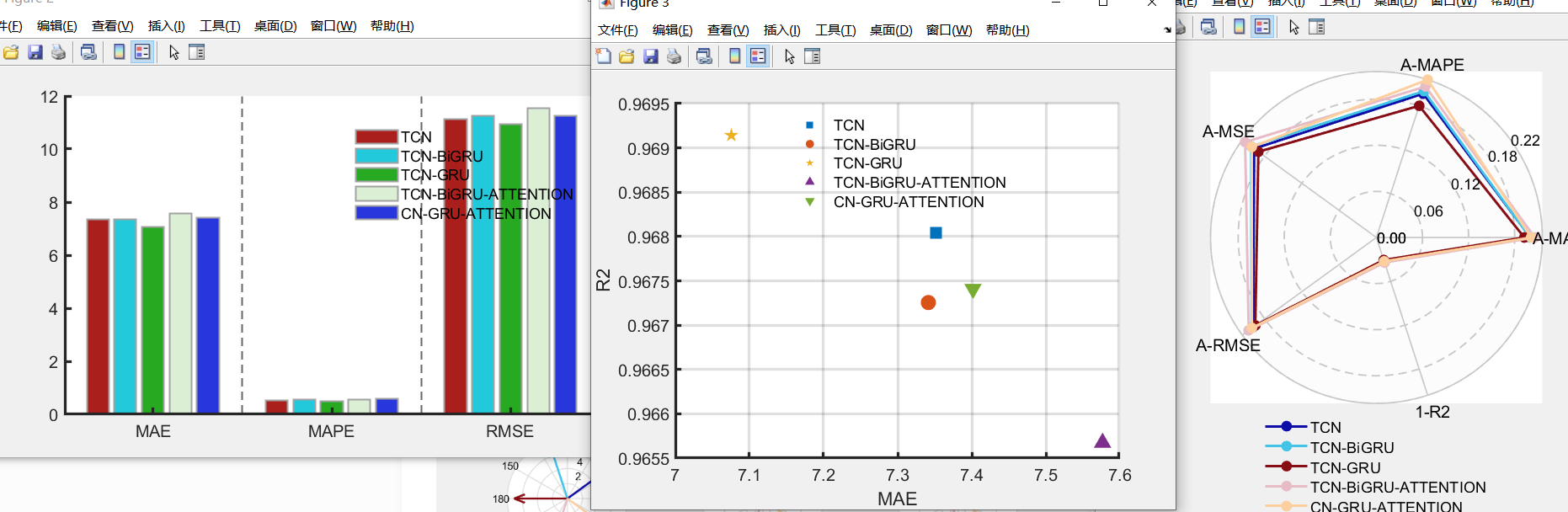















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









