






网络结构模型:搭建的是一个3层全连接Dense网络,3072--512--256--3,顺序模型
optimizer选择 SGD 随机梯度下降(自定义学习率) , LOSS FUNCTION 选择 cross entropy交叉熵。
数据集3000个,划分 训验比 为 3:1
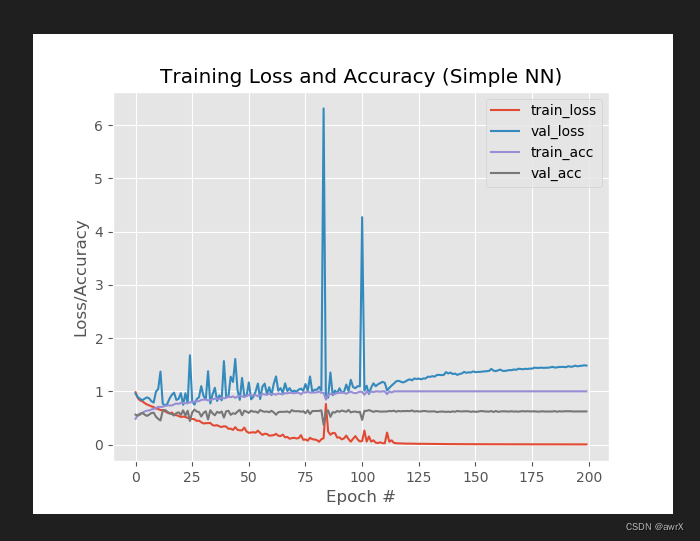
模型为普通神经网络模型,即Dense层(全连接层)神经元,初步选用 lr=0.01,epoch =200,batch_size=32;
可以发现,模型 在训练到200轮的时候发现红线train-loss趋于0,而在验证集上val_loss还很大,则模型 已经过拟合了
从训练集 精度为1,而模型在验证集上分类精度只有0.6,看出 模型过拟合了。
(1)学习率对结果的影响
当模型过拟合时,通常可以调整 学习率 和 批大小 这两个超参数。可以优先缩小 1/10 倍学习率

可以发现,用小学习率 训练200次时,模型过拟合现象有所改善。为了更好观察,可设置epochs =2000,训练2000轮。更好地 观察 模型是否在训练集上过拟合。
很可惜,扩大训练轮数,发现 lr=0.001时模型在训练集上acc=1,loss=0(完美),在验证集上loss发散,acc = 0.6。。。模型明显过拟合

(2)批大小对结果的影响
进一步,调整批大小的超参数,设置 batch_size =16,观察

仍然不难预测到模型过拟合,分析可能是 小批次 在 该学习率下效果不好,二者不适配,非最优对应解。 过拟合的模型是没有任何用的,因为只在训练集上表现良好,没有预测的能力。
此外,还可以从减少层数(优化小型网络深度),改变网络每层输出单元的个数(output)来降低过拟合。
抑制过拟合方法
1. 添加dropout
全连接神经元过多造成过拟合,随机杀死部分神经元,添加的 dropout 将被引入前一层的输出中,随机从上一层输出的特征图中丢弃特征

epoch =200 难以充分分析是否过拟合, 可以考虑更多的训练轮数,但遗憾的是 模型仍然过拟合,但相比最初 lr=0.01 时,验证集的 loss发散更小, acc 也有提高

2.初始化权重参数
DENSE层的 Initializer 方法 的 API:

越小的初始化参数 sted标准差越小,会使模型过拟合风险越小 ,即 val 集和train 集的 loss接近
model.add(Dense(256,
activation="relu",
kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None)))
model.add(Dense(256,
activation="relu",
kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.01, seed=None)))
3.目标函数正则化
使 目标 函数= 原损失函数 loss + 正则项
对 L2 正则化(平方项权重系数w),选择不同的惩罚力度lamuda,观察 不同lamuda值 对 模型的 影响
lamuda =0.01 ,TruncatedNormal .std= 0.05

由于添加 L2正则项 ,会使 目标函数初始值很大,所以 前150 个 训练轮次的参考意义不大。
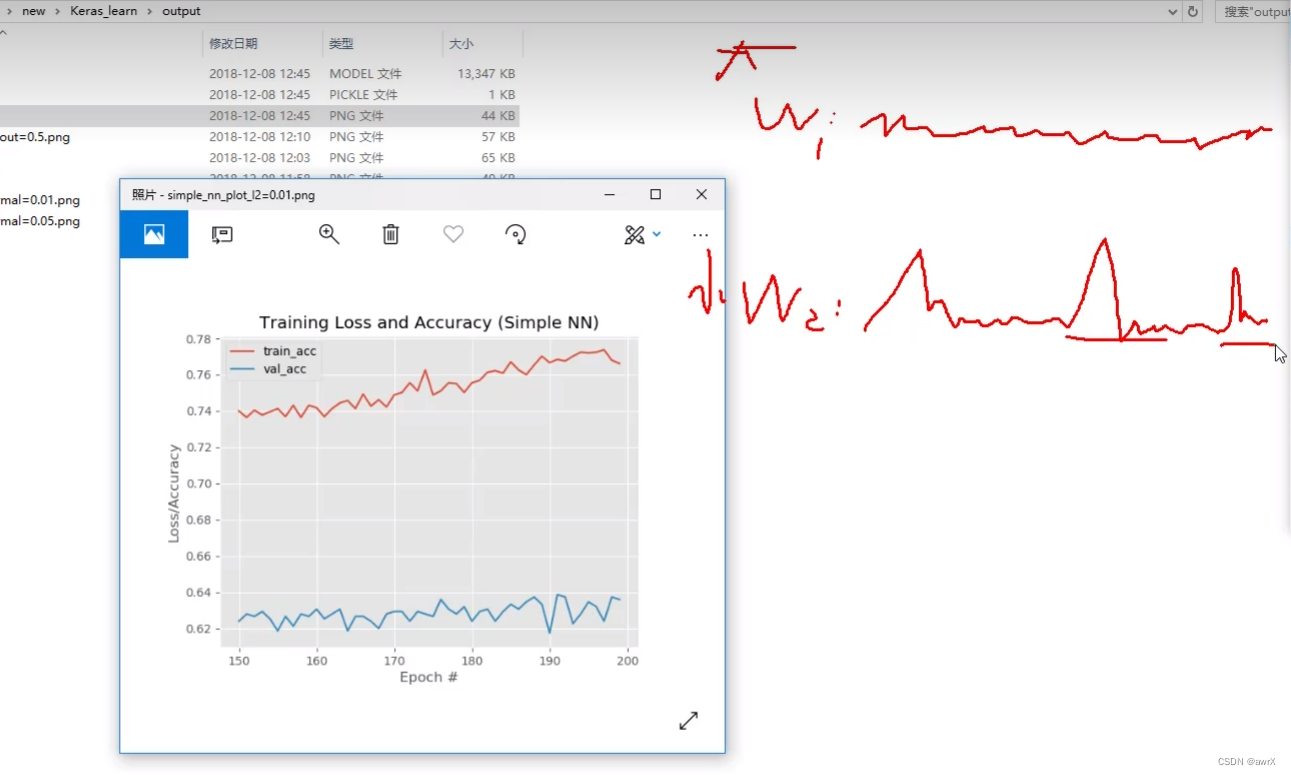
故取值时 ,把 N取150个点后的值方便观察 , 且 由于loss取值区间 比 acc取值区间【0,1】要大很多,所以 只观察 模型在 后50个训练轮次上 训练集和验证集 的准确率(每个轮次迭代3000个数据)
较小的正则化惩罚:l2 = 0.01

l2 = 0.05,train acc和 val acc二者更接近
 w
w
惩罚力度小,则输出结果不太稳定,容易造成过拟合现象(w2):
保存上述生成的模型
model.save(args["model"])# 调用了当时自定义的argparse工具包里的方法predict.py:
在运行(U)里的 编辑配置中 可以选择 重新设置形参; 把dog 的图片导入
在图片上预测其输出类别,并打印类别判断的概率


混淆矩阵中:绿色 True 代表我们预测正确,橙色 False代表我们预测错误
Positive 代表我们预测的是Positive类。故TP 代表预测正确的 Positive类 的 数目 。

在多分类混淆矩阵的问题中 ,绿色的对角线 是模型预测正确的情况。 橙色部分是预测错误的部分。希望模型绿色部分的值尽可能大,橙色部分的值尽可能小,代表模型的分类效果越好。


accuracy precision Recall分别对应 解决了 1 2 3 这 3 个问题
猫狗熊猫 3 分类问题,则得到一个 3*3的矩阵 ,其中 召回率 = 该类对应的对角线元素(绿色)/该列所有元素和 , 精确率 = 该类对应的对角线元素(绿色)/该行所有元素和

在某些领域,比如医学领域不希望遗漏掉任何一位患者,所以我们会认为 Recall 更重要 ,于是 在计算F1 时会把 beta 取值为 2。 在某些领域,若认为 Precision精确率更重要,就会把 beta 取值为 【0,1】的值















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









