







论文精读-ReTransformer: ReRAM-based Processing-in-Memory Architecture for Transformer Acceleration
优点:
1、基于新型存储器ReRAM实现Transformer模型加速,并设计了一个新的PIM结构ReTransformer,其分为三种类型的功能组件,处理子阵列、缓冲子阵列、内存子阵列。
2、使用矩阵分解解决缩放点积中的数据依赖,减少了中间结果频繁重写,降低了计算延迟。
3、实现了低功耗混合softmax函数,通过在新型存储器ReRAM上实现选择和比较操作,并利用函数变形+查找表得到softmax结果,降低了计算功耗。
4、通过矩阵拆分,将输入数据流分割成更小的部分,以实现更细粒度的流水线设计。这种方法相较于传统的层流水设计,显著提升了crossbar的利用率和加速器的计算性能。
概述
Transformer已经成为一种流行的深度神经网络(DNN)模型,用于神经语言处理(NLP)应用,并在神经机器翻译、实体识别等方面表现出优异的性能。然而,其在自回归解码器中的规模化点积注意机制在推理过程中带来了性能瓶颈。Transformer也是计算和内存密集型的,需要硬件加速解决方案。尽管研究人员已经成功地应用了基于基于ReRAM的内存中处理(Processing-in-Memory, PIM)来加速卷积神经网络(cnn)和递归神经网络(rnn),但Transformer中缩放点积注意力的独特计算过程使得这些设计难以直接应用。此外,如何处理矩阵-矩阵乘法(MatMul)中的中间结果以及如何在Transformer的更细粒度上设计管道仍未得到解决。在这项工作中,我们提出了ReTransformer -一种基于ReRAM的变压器加速PIM架构。ReTransformer不仅可以使用基于ReRAM的PIM加速Transformer的缩放点积注意力,而且可以使用所提出的矩阵分解技术避免编写中间结果,从而消除一些数据依赖性。此外,我们提出了一种新的用于多头自关注的子矩阵管道设计。实验结果表明,与GPU和Pipelayer相比,ReTransformer的计算效率分别提高了23.21倍和3.25倍。相应的整体功耗分别降低1086倍和2.82倍。
背景介绍
一个杰出的基于自注意的模型transformer[28]显著减少了远程依赖关系之间的路径长度,从而在许多转导任务中实现了最先进的性能。
然而,由于NLP序列的复杂性,已经为简单性进行了优化的Transformer模型仍然需要大量的计算资源。例如,[28]中提出的原始Transformer模型是许多设计的支柱[1,30,34],它有65M参数。再举一个例子,流行的预训练模型BERT[6]有108M参数。ALBERT[16]提出对参数进行修剪,将总参数数减少到12M,精度下降2.2%。结构级的优化也被开发出来,比如用平均注意力模型[34]代替顺序模型,探索非自回归解码器[9],在相邻层[30]之间共享权重。然而,结构调整要么会导致模型中固有词依赖关系的丧失,要么会导致更复杂的训练过程。而且,这些加速方法没有考虑硬件特征。
为了在不牺牲精度的情况下提高Transformer推理性能,移动和嵌入式系统开始采用节能的特定领域硬件加速器。一个主要的性能瓶颈——在自回归解码器[30]中大量使用点积注意力,需要在加速过程中进行特殊处理。其次,频繁来回移动中间数据存储器和处理单元之间也应该减少,以提高能量效率。
加速器设计
Transformer模型分析
Transformer模型结构
核心:前馈网络(FFN),多头自注意力(MSA)
(LN+MSA,LN+MLP)
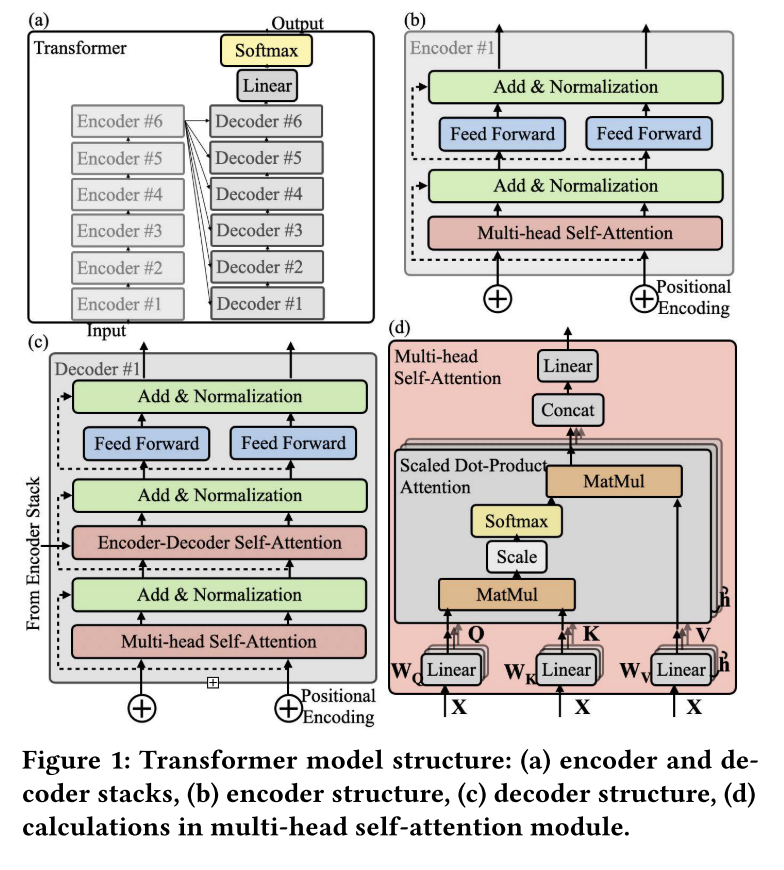
变压器由一个编码器堆栈和一个解码器堆栈组成,它们共享相似的模块结构。以[28]中的结构为例,编码器具有6个相同模块的堆栈,如图1(a)所示。每个块由两大功能模块组成:多头自注意和前馈,分别由图1(b)中的浅红色块和蓝色块所示。在这两个主要功能模块之后,都有一个残差块来添加输入和输出,并执行层范数计算,如图1(b)中的绿色块所示。多头注意层从输入嵌入或之前的编码器块中获取输入。解码器堆栈也由6个相同的块组成,但每个解码器块由三个主要功能层组成,包括两个多头自注意层和一个前馈层,如图1©所示。与编码器块相比,解码器块有一个额外的编码器-解码器自注意模块,该模块有一个输入与编码器堆栈的输出相连。
Transformer计算
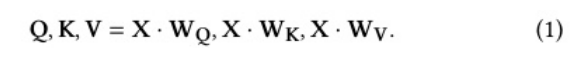
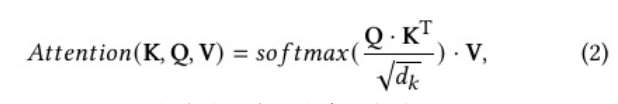
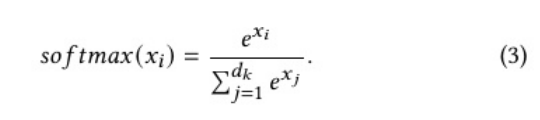

核心包括点积计算,缩放除法和softmax中的e^x指数运算。
前馈网络输出:
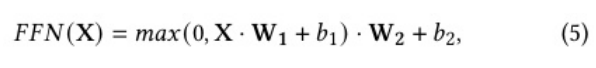
基于ReRAM的存内计算设计
1、基于ReRAM向量矩阵和矩阵矩阵乘法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4280
4280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











