







声明:
本文章对链表的相关操作均采用C语言实现,涉及的操作有:单链表的创建、添加新节点、删除节点、查找节点、对链表进行排序、打印链表信息等。
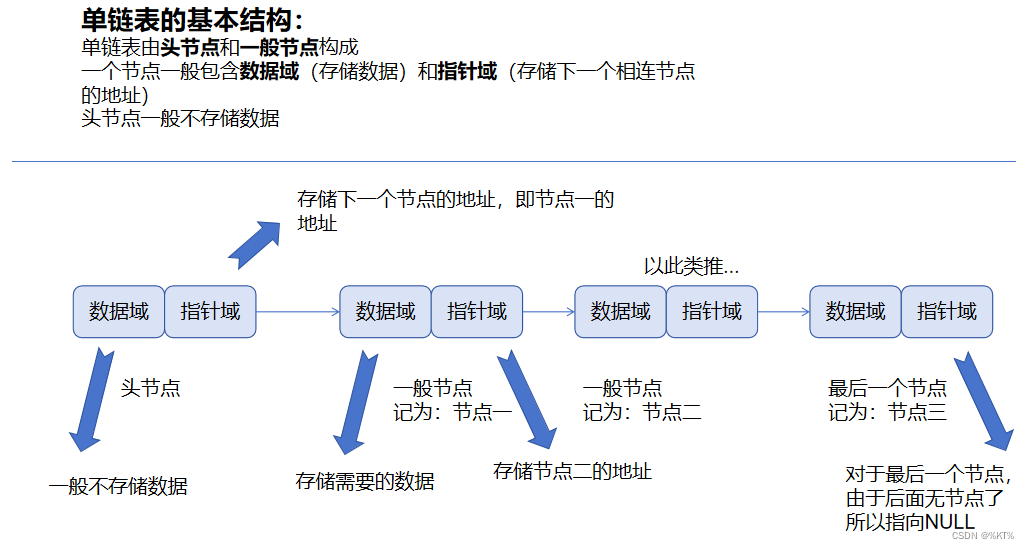
单链表的基本结构:
单链表的基本结构为下图所示:
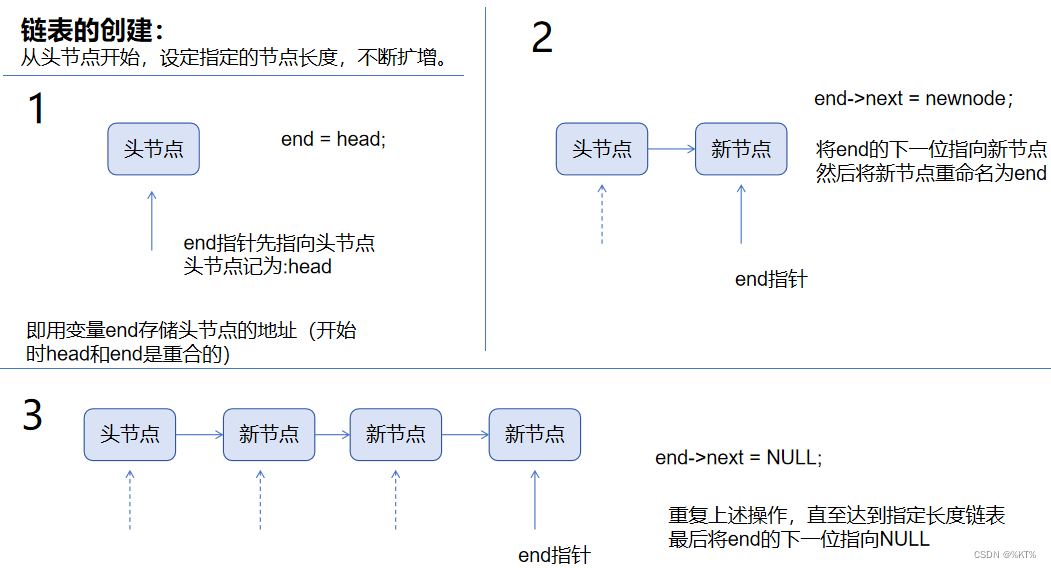
链表的创建:
这里需要说明的是:我们经常提及的将某个指针指向某个节点的含义,其实就是将该节点的地址赋值给这个指针变量,这样我们就能通过这个指针变量来获取对应节点的相关信息或者对这个节点进行操作了。
所以,在创建新节点时往往需要使用malloc的方法开辟一块内存存储新节点;
但是使用某个指针变量指向该节点时不需要在开辟内存空间。
代码示例:
注意:在代码例,head是一个节点,但end是一个指针变量,不要搞混了。
Node* createNode(int num)//创建节点函数,参数是节点的数量,注意头结点是不算在节点数量里的
{
Node* head;
Node* end;
head = (Node*)malloc(sizeof(Node));
end = head; //这里end只是一个指针变量,其存储的是head的地址,所以不需要对end进行内存的分配,换句话说,其实这里的end不是一个节点
//还是有一点迷惑性的,这里创建end变量,只是为了后续循环好不断添加节点
if (head == NULL)
{
printf("头节点内存分配失败!");
return NULL;//表示分配内存失败了
}
for (int i = 0; i < num; i++)
{
Node* newnode = (Node*)malloc(sizeof(Node));
if (newnode == NULL)
{
printf("节点内存分配失败!");
return NULL;//表示分配内存失败了
}
printf("请输入该节点的数值:");
scanf_s("%d", &newnode->data); //这里还得用scanf_s,scanf还不行,会警告,可能是编译器版本的题
end->next = newnode;
end = newnode;
}
//循环添加完成链表的创建后,要将最后一个节点的Node.next == NULL,用于链表结束的判别
end->next = NULL;
return head;
//到这里,讲一下这个函数的类型Node* createNode(int num),结构体指针类型的函数,这个函数会返回值是一个结构体的地址(在链表中就是头结点的地址),
//这样,我们就能通过头结点不断地遍历链表中的每一个节点的。
//某种意义上,这么做能达到创建一个函数,(类似python中直接返回一个数组的功能)
}向链表中添加节点:
这里采用的方法是头插法,非常好理解。
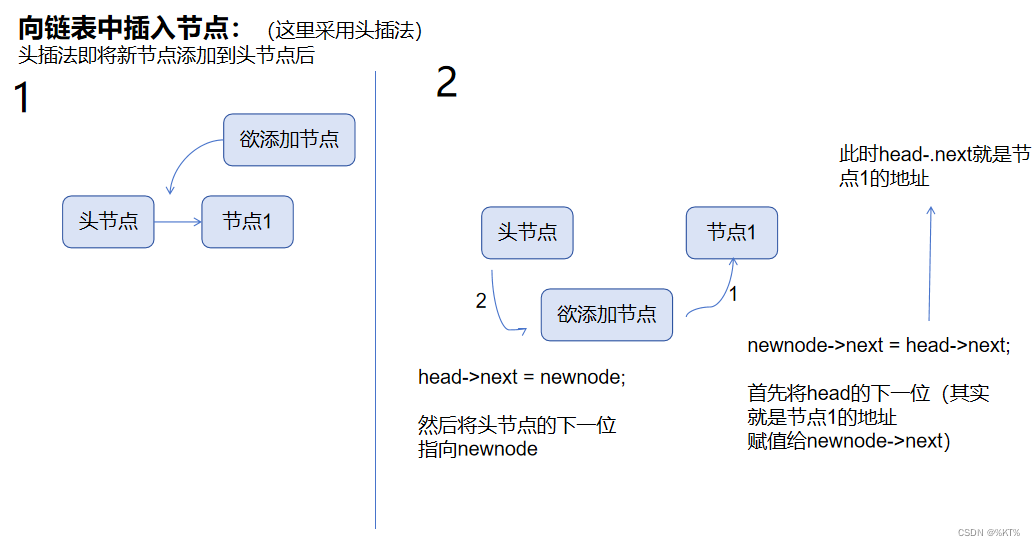
代码示例:
void addNode_From_Head(Node* head,int data)//第一个参数是链表的头结点,第二个参数是插入节点的值
{
Node* newnode = (Node*)malloc(sizeof(Node));//为新节点分配空间
newnode->data = data;
newnode->next = head->next;//将原head节点的下一个节点地址赋值(指向)给新节点的下一位
head->next = newnode;//头结点的下一位指向新插入的节点
}删除某个节点:
这里采用的是:使用双指针的方法;
好像还有其他的方法,比如可以使用二级指针的方式,但该方法可能更难理解。
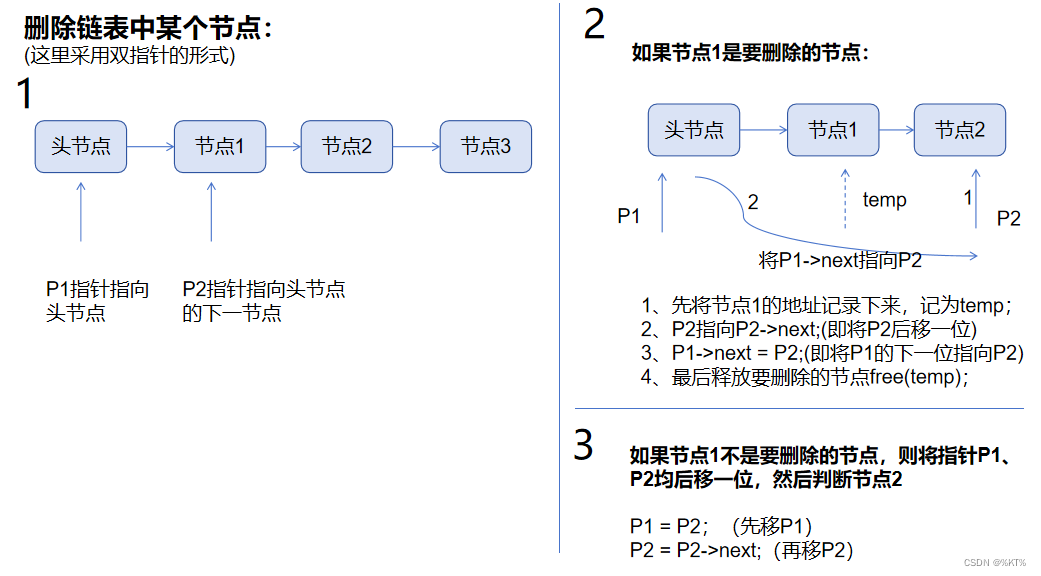
代码示例:
void deleteNode(Node*head,int data)//第一个参数是链表的头结点,第二个参数是删除节点的值,该函数会删除所有匹配的值
{
//这里采用双指针的形式,进行删除
Node* P1 = head;
Node* P2 = head->next;
while (P2!= NULL )
{
if (P2->data == data)
{
Node* AimNode = P2;
P2 = P2->next;
P1->next = P2;
free(AimNode);
}
else
{
P1 = P2;
P2 = P2->next;
}
}
}寻找目标节点:
找到目标节点后,返回结果是该节点的地址,我们可以通过该节点的地址,访问对应的数据域。
代码示例:
Node* findNode(Node* head, int data) //返回值是目标节点地址
{
while (head != NULL)
{
if (head->data == data)
{
return head;
}
else
{
head = head->next;
}
}
}链表的排序:
这里采用的方法是冒泡排序(最简单最好理解的一种排序算法,但时间复杂度是O(n^2));
为便于理解,这里对链表的操作仅仅是交换数据域,并没有真正意义上的交换节点。
void bubbleSort(Node* head) //利用冒泡排序对列表中数据进行排序
{
Node* p = head->next;
int len = 1; //计算链表的长度(不包括头节点)
while (p->next!= NULL)
{
len++;
p = p->next;
}
printf("这个链表的长度为:%d\n", len);
for (int i = 0; i < len-1; i++)
{
p = head->next; //这里需要注意,每次重新遍历后需要先讲p指针指向第一个一般节点
for (int j = 0; j < len - 1 - i; j++)
{
if (p->data > p->next->data) //这里仅仅是交换了数据域,没有交换两个节点
{
int temp = p->data;
p->data = p->next->data;
p->next->data = temp;
}
p = p->next;
}
}
}完整源码:
#include<stdio.h> //练习
#include<stdlib.h>
typedef struct Node { //定义链表的每一个节点
int data;
struct Node* next; //结构体指针类型的变量 next
}Node;
Node* createNode(int num)//创建节点函数,参数是节点的数量,注意头结点是不算在节点数量里的
{
Node* head;
Node* end;
head = (Node*)malloc(sizeof(Node));
end = head; //这里end只是一个指针变量,其存储的是head的地址,所以不需要对end进行内存的分配,换句话说,其实这里的end不是一个节点
//还是有一点迷惑性的,这里创建end变量,只是为了后续循环好不断添加节点
if (head == NULL)
{
printf("头节点内存分配失败!");
return NULL;//表示分配内存失败了
}
for (int i = 0; i < num; i++)
{
Node* newnode = (Node*)malloc(sizeof(Node));
if (newnode == NULL)
{
printf("节点内存分配失败!");
return NULL;//表示分配内存失败了
}
printf("请输入该节点的数值:");
scanf_s("%d", &newnode->data); //这里还得用scanf_s,scanf还不行,会警告,可能是编译器版本的题
end->next = newnode;
end = newnode;
}
//循环添加完成链表的创建后,要将最后一个节点的Node.next == NULL,用于链表结束的判别
end->next = NULL;
return head;
//到这里,讲一下这个函数的类型Node* createNode(int num),结构体指针类型的函数,这个函数会返回值是一个结构体的地址(在链表中就是头结点的地址),
//这样,我们就能通过头结点不断地遍历链表中的每一个节点的。
//某种意义上,这么做能达到创建一个函数,(类似python中直接返回一个数组的功能)
}
void printNode(Node* node) //打印节点的函数
{
while (node->next != NULL)
{
printf("%d ", node->next->data);
node = node->next;
}
printf("\n");
}
void freeNode(Node* head) //链表内存的释放
{
while (head != NULL)
{
Node* temp = head->next;
free(head);
head = temp;
}
}
//头插法
void addNode_From_Head(Node* head,int data)//第一个参数是链表的头结点,第二个参数是插入节点的值
{
Node* newnode = (Node*)malloc(sizeof(Node));//为新节点分配空间
newnode->data = data;
newnode->next = head->next;//将原head节点的下一个节点地址赋值(指向)给新节点的下一位
head->next = newnode;//头结点的下一位指向新插入的节点
}
Node* findNode(Node* head, int data) //返回值是目标节点地址
{
while (head != NULL)
{
if (head->data == data)
{
return head;
}
else
{
head = head->next;
}
}
}
void deleteNode(Node*head,int data)//第一个参数是链表的头结点,第二个参数是删除节点的值,该函数会删除所有匹配的值
{
//这里采用双指针的形式,进行删除
Node* P1 = head;
Node* P2 = head->next;
while (P2!= NULL )
{
if (P2->data == data)
{
Node* AimNode = P2;
P2 = P2->next;
P1->next = P2;
free(AimNode);
}
else
{
P1 = P2;
P2 = P2->next;
}
}
}
void bubbleSort(Node* head) //利用冒泡排序对列表中数据进行排序
{
Node* p = head->next;
int len = 1; //计算链表的长度(不包括头节点)
while (p->next!= NULL)
{
len++;
p = p->next;
}
printf("这个链表的长度为:%d\n", len);
for (int i = 0; i < len-1; i++)
{
p = head->next; //这里需要注意,每次重新遍历后需要先讲p指针指向第一个一般节点
for (int j = 0; j < len - 1 - i; j++)
{
if (p->data > p->next->data) //这里仅仅是交换了数据域,没有交换两个节点
{
int temp = p->data;
p->data = p->next->data;
p->next->data = temp;
}
p = p->next;
}
}
}
int main()
{
Node* n1 = createNode(5);
printf("初始化列表结果为:\n");
printNode(n1);
printf("头部插入节点6\n");
addNode_From_Head(n1, 6);
printNode(n1);
printf("删除列表中所有节点2\n");
deleteNode(n1,2);
printNode(n1);
Node*pos = findNode(n1, 3);
printf("节点的地址为:%p\n", pos); //通过返回的节点,查看该节点的相关信息
printf("该节点的值为:%d\n",pos->data);
printf("该节点的下一节点地址为:%p\n", pos->next);
bubbleSort(n1);
printf("排序后结果为:\n");
printNode(n1);
freeNode(n1);
printf("链表内存已释放");
printNode(n1);
return 0;
}运行结果:















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









