







声明:
本文主要涉及利用pandas库对csv文件中的数据进行填充,删除,求值,特征提取,相关性分析,可视化等操作。主要涉及的技术为机器学习中的特征工程。
数据集来源:
本次学习用数据集为kaggle房价预测任务中提供的数据集,该数据集较粗糙,需进行数据预处理。
数据集下载:
数据集下载可前往博文:Kaggle 房价预测数据集下载-CSDN博客
正文:
csv文件的读取:
读取文件,保存为dataframe格式,一般习惯上读取为df的模式。这里df就类似于excel的格式,便于进行数据处理
import pandas as pd
df = pd.read_csv("train.csv") # 利用pandas读取文件的方法,有时候会出现编码问题,需要在
# 后面使用encoding=指定读取方式
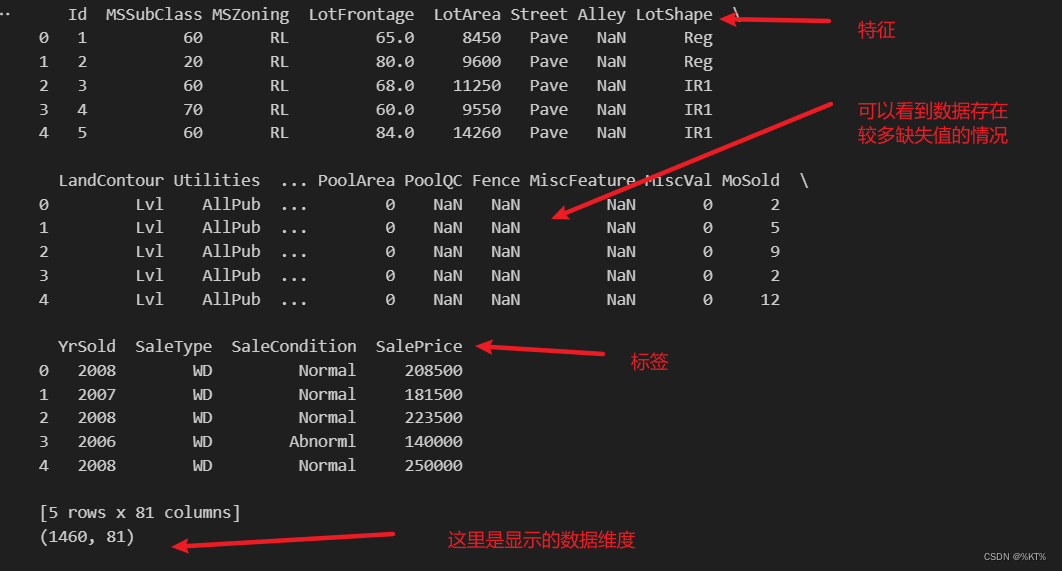
print(df.head()) # 只显示数据的前五行
print(df.shape) # 这是显示数据的维度,1460条数据,每一行有81维,这个数据集的话最后一个是房价,相当于标签了运行结果:
显示所有特征信息:
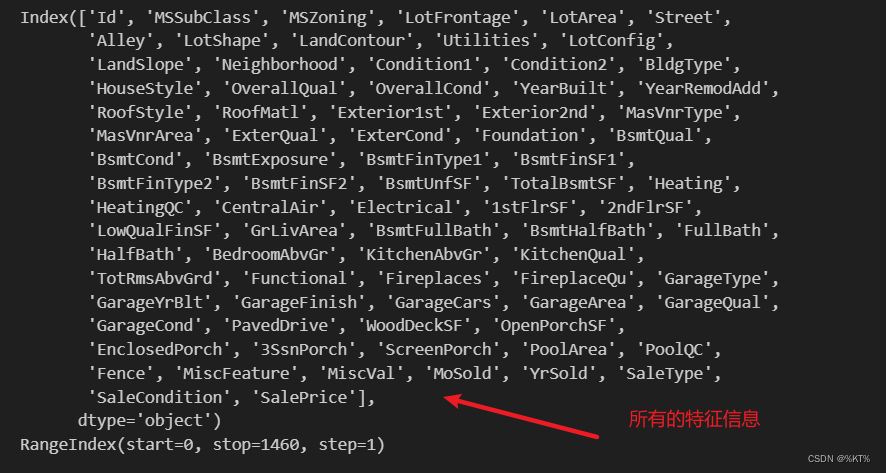
print(df.columns) # 这个操作是用来显示所有列名的
print(df.index)# 这个就是与列对应的,显示行的情况
# 后面进行批量删除的相关操作,都是和columns,index这两个参数有关的运行结果:
删除行/列的操作:
删除某一行或者某一列,使用函数drop()操作。
# 这种方式是通过列名“Id”来进行删除的,如果没有列名,可以尝试通过索引的方式进行删除
print(df.head())
df = df.drop(columns="Id",axis=1) # 这里axis = 1表示列操作,若axis = 0表示行操作,drop()函数默认参数是axis = 0
# 这里的columns=参数是指明列表是"Id",如果想指明行标签,是使用labes=
print(df.shape)通过索引删除列:
df = df.drop(df.columns[1],axis=1) # 这里就是通过索引进行删除列
#df = df.drop(df.columns[0:20],axis=1) # 通过索引的话,也能够批量删除,这里[0:20]也遵循左闭右开的规则
print(df.head())
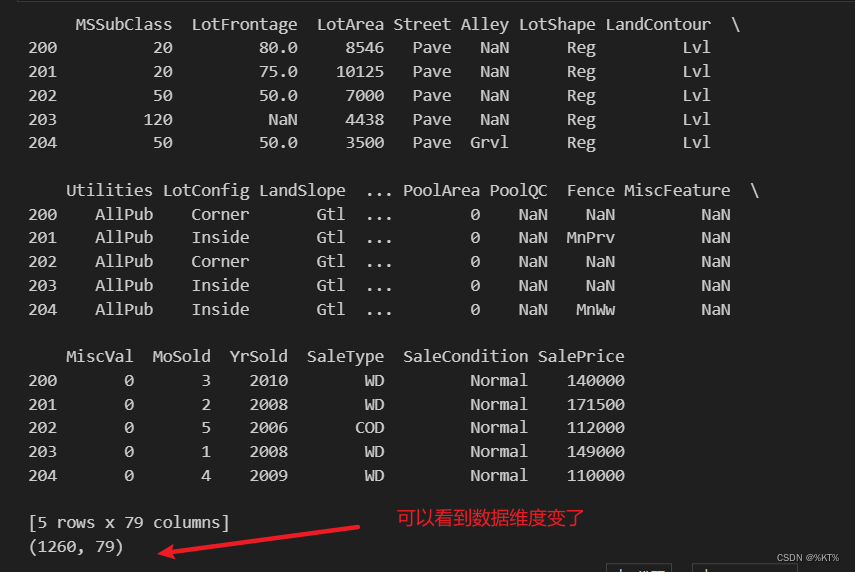
print(df.shape)删除行操作:
df = df.drop(df.index[:200]) # 删除前200行数据
print(df.head())
print(df.shape)运行结果:
统计每个“特征”的取值情况:
在机器学习中,一般列名就是一个特征,特征可以有不同的取值
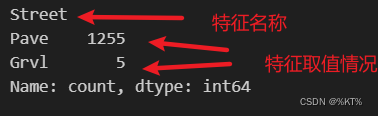
※方法是使用value_counts()函数
※从计算结果可以看到,df.columns[3]这个特征只有两个取值,其中Pave出现了1255次,而Grvl只出现了5次
value_count = df["Street"].value_counts() # 直接通过列名的方式统计
value_count = df[df.columns[3]].value_counts() # 通过索引的方式进行统计
print(value_count)运行结果:
计算平均值、最大、最小等值:
在机器学习中,回归模型一般在正态分布类型的数据集上表现较好,所以需要探究标签数据的分布情况
# 根据列名计算某列的相关值
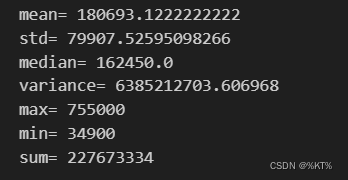
mean_value = df["SalePrice"].mean() # 计算均值
std_value = df["SalePrice"].std() # 计算标准差
median_value = df['SalePrice'].median() # 计算中位数
variance = df['SalePrice'].var() # 计算方差
max_value = df['SalePrice'].max() # 计算最大值
min_value = df['SalePrice'].min() # 计算最小值
sum_value = df['SalePrice'].sum() # 求和
print("mean=",mean_value)
print("std=",std_value)
print("median=",median_value)
print("variance=",variance)
print("max=",max_value)
print("min=",min_value)
print("sum=",sum_value)运行结果:
数据清洗:
此部分的操作有删除异常值,用均值填补缺失值等操作
# 这里以LotFrontage特征练习,这是一个数值型的特征,当其中存在确实之时,会使用NaN表示
# 需要说明的是,NaN可以直接被pandas识别为空
# 这里使用isna()函数来筛选出哪些是空数据,之后使用sum()函数进行统计数量
print(df.head())
print(df.shape)
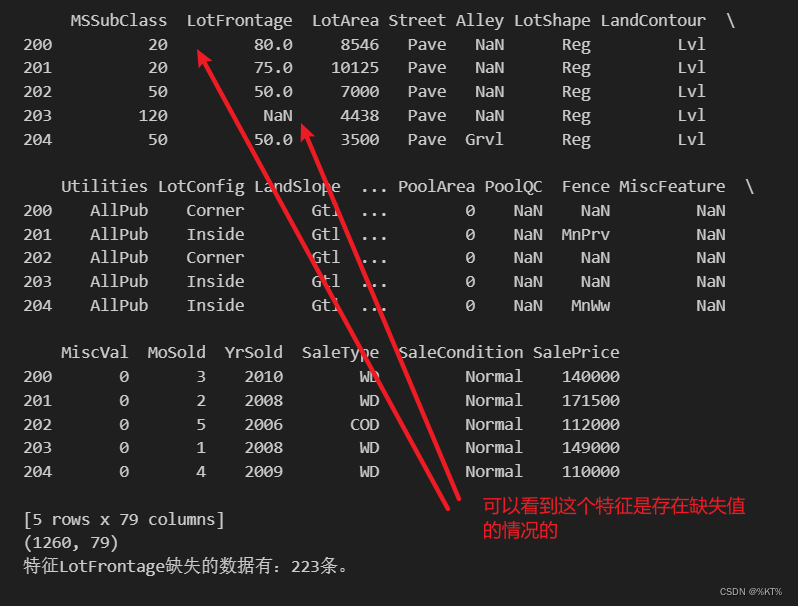
missing_data = df["LotFrontage"].isna().sum()
print("特征LotFrontage缺失的数据有:{0}条。".format(missing_data))
# 如果表格中的空数据不是NaN这种标准形式,可以使用replace()函数将其转化成标准形式
# df['feature_column'] = df['feature_column'].replace(['Nan', 'NA', 'null', 'missing'], pd.NA)运行结果1:
#针对缺失值,一般采用的方式是利用平均值,中位数,众数等方式填补或者直接删除
# 填补的函数是fillna(),直接删除缺失值的函数是dropna()
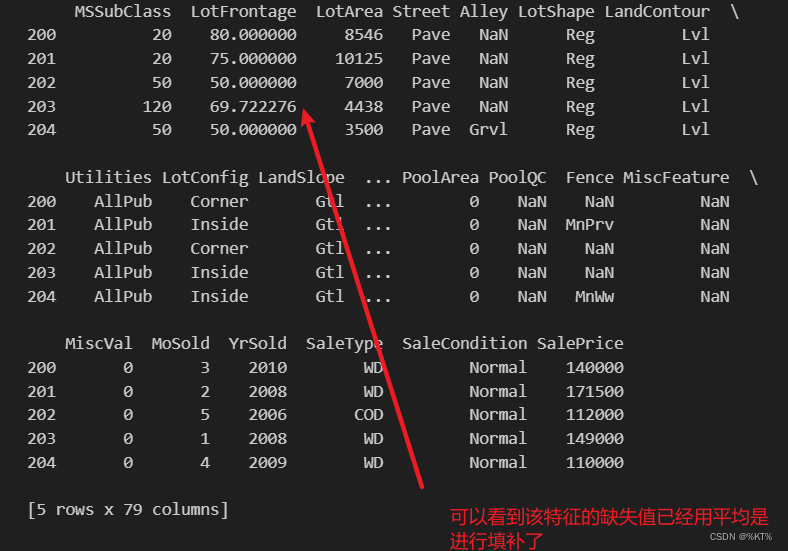
LotFrontage_mean_value = df["LotFrontage"].mean()
df["LotFrontage"] = df["LotFrontage"].fillna(LotFrontage_mean_value) # 使用前面计算得到的平均值进行填补
#df = df.dropna(subset=['LotFrontage'])
print(df.head())运行结果2:
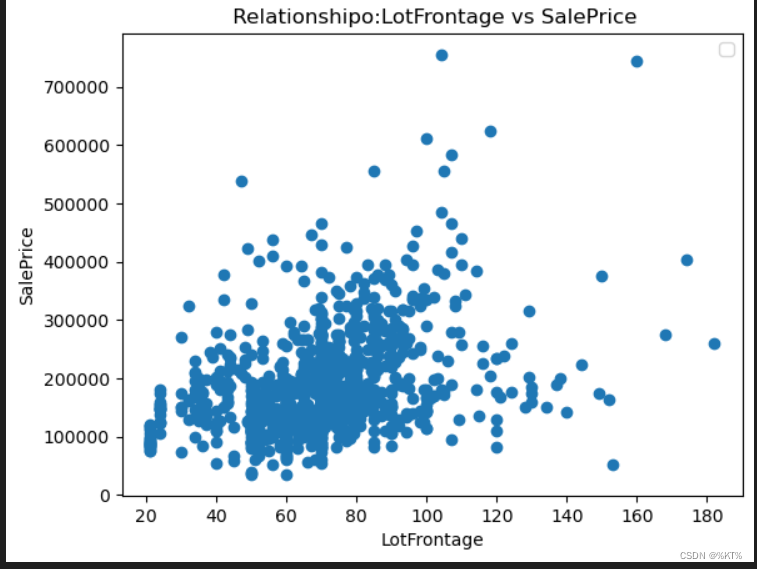
绘制散点图:
散点图可用来分析某个特征和标签之间的关联度
※ 散点图的主要作用:
(1)分析变量之间是否存在数量关联趋势;
(2)如果存在关联趋势,是线性还是非线性的;
(3)观察是否有存在离群值,从而分析这些离群值对建模分析的影响。
import matplotlib.pyplot as plt
# 使用matplotlib绘制散点图
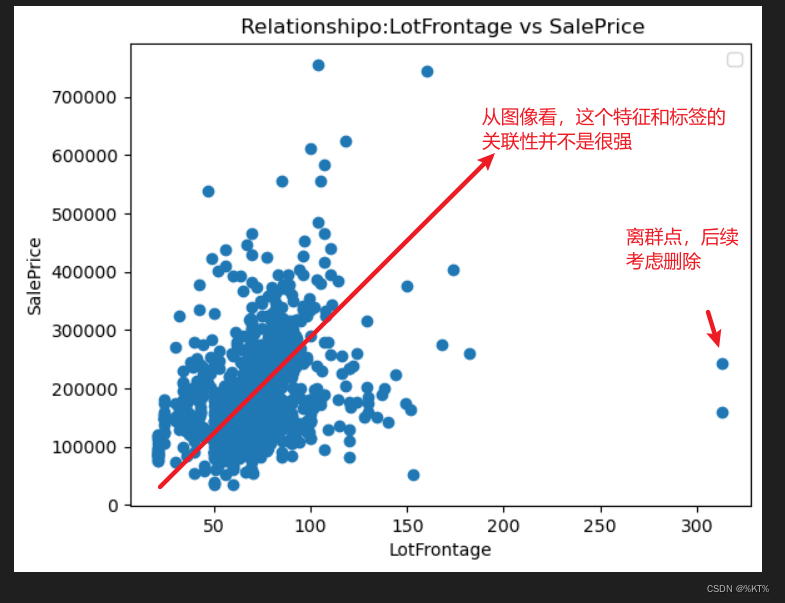
plt.scatter(df["LotFrontage"], df["SalePrice"])
# 添加标题和轴标签
plt.title(' Relationshipo:LotFrontage vs SalePrice')
plt.xlabel('LotFrontage')
plt.ylabel('SalePrice')
# 显示图例
plt.legend()
# 显示图表
plt.show()
# 从结果来看,这个特征和标签是弱线性相关吧,说明这个特征对于标签的影响一般运行结果:
删除异常值/离群点:
# 通过上图,我们也发现存在部分异常值/离群点,比如最右边两个
# 这里可以采用指定范围的方式删除异常值
threshold_upper = 250
threshold_lower = 0
df = df[(df["LotFrontage"] <= threshold_upper) & (df["LotFrontage"] >= threshold_lower)]
# print(df.head())
# 重新绘制图像
# 使用matplotlib绘制散点图
plt.scatter(df["LotFrontage"], df["SalePrice"])
# 添加标题和轴标签
plt.title(' Relationshipo:LotFrontage vs SalePrice')
plt.xlabel('LotFrontage')
plt.ylabel('SalePrice')
# 显示图例
plt.legend()
# 显示图表
plt.show()
# 从结果可以看到,最右边的两个离群点已经被删除了运行结果:
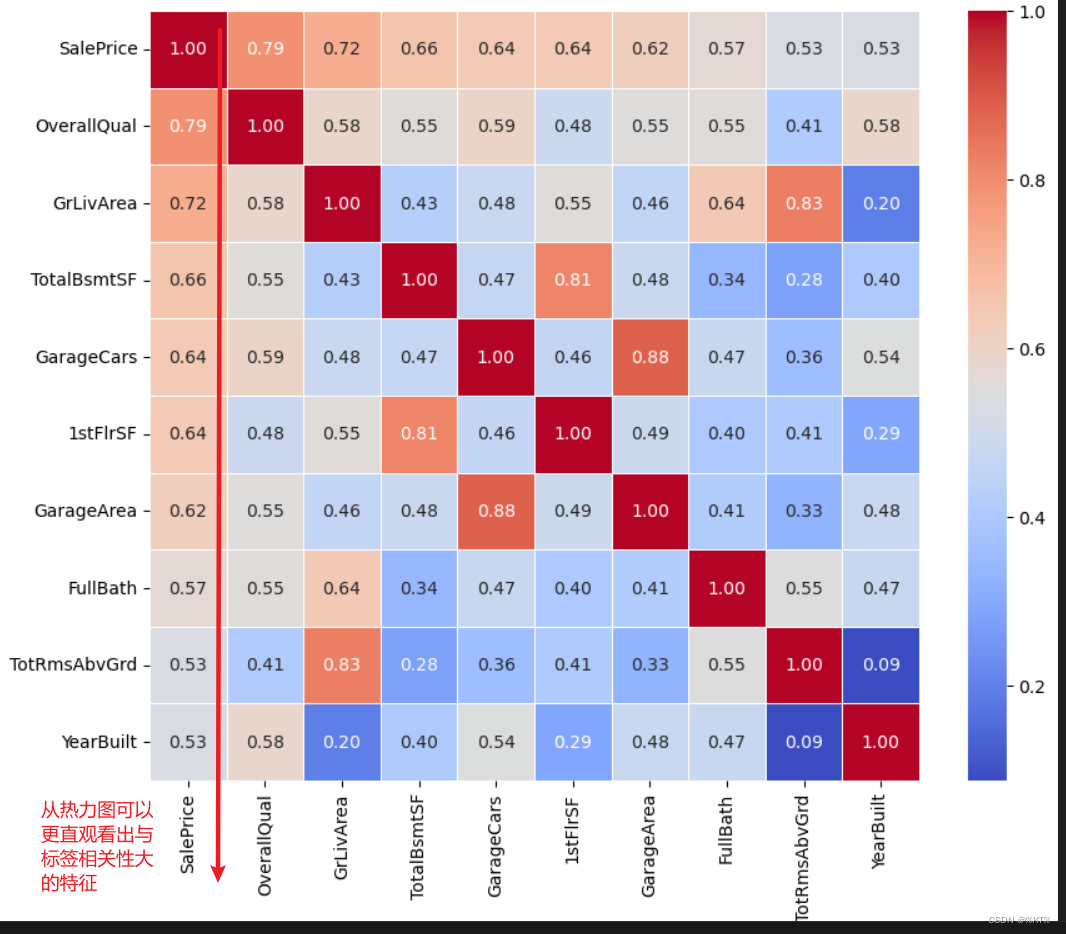
绘制热力图:
热力图是一种通过颜色变化展示数据矩阵中数值大小的图形,非常适合用来可视化特征之间的关联程度
import seaborn as sns
import numpy as np
# 计算相关系数矩阵,只选择数值型列
# 这里进行了筛选,只对数值型的特征进行了关联分析
# 对于非数值型特征,可以采用独热编码等的方式,将其转为数值型特征
numeric_columns = df.select_dtypes(include=[np.number]).columns # 筛选出数值型特征
corr = df[numeric_columns].corr()
# sns.heatmap(corr, annot=True, fmt='.2f', cmap='coolwarm', square=True, linewidths=.5) 这一行代码是显示所有特征之间的相关性
#由于特征的数量非常多,这里只选择展示10个和标签关联性较大的特征
cols_10 = corr.nlargest(10, 'SalePrice')['SalePrice'].index
corrs_10 = df[numeric_columns][cols_10].corr()
# 使用seaborn绘制热力图
plt.figure(figsize=(10, 8)) # 可以根据需要调整大小
sns.heatmap(corrs_10, annot=True, fmt='.2f', cmap='coolwarm', square=True, linewidths=.5)
# 显示热力图
plt.show()运行结果:
对非数值型特征进行编码:
上面的一系列操作其实都是针对数值型特征的,如果遇到非数值型特征,往往需要进行特征编码。
这里采用的方式是独热编码,独热编码的原理也比较简单。比如某个特征的取值有三种:aaa,bbb,ccc,那么就可以将这三种string类型数据转化为100,010,001这三个二进制数来表示,这样计算机就能处理非数值型特征了。
当然,独热编码的一个明显的缺点是:如果特征的取值非常多,那么很容易导致维度灾难。比如如果特征的取值有100中,那么就要用一个长度为100的0/1串来表示这些取值,是非常不合理的。针对这种情况,可以常用采用其他编码方式或者数据降维。
print(df.shape)
# 这里以Street特征为例
df = pd.get_dummies(df, columns=['Street'])
print("对Street特征独热编码后为:---------------")
print(df.shape)
# 从之前的实验我们知道,Street只有两个取值,所以对street进行都热编码后,特征相当于多了一个,现在数据是80维的了
# 当然,都热编码也有局限性,若是特征的取值类别非常多,可能导致维度灾难,这是往往需要采用数据降维,降低计算量运行结果:

保存文件:
df.to_csv('final_data.csv', index=False)














 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









