语言环境:Python3.9.18 编译器:Jupyter Lab 深度学习环境:Pytorch 1.12.1 import torch
import torch. nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, random, pathlib
device = torch. device( 'cuda' if torch. cuda. is_available( ) else 'cpu' )
device
import os, PIL, random, pathlib
data_dir = "F:/365data/P4/"
data_dir = pathlib. Path( data_dir)
data_paths = list ( data_dir. glob( '*' ) )
classeNames = [ str ( path) . split( "\\" ) [ 3 ] for path in data_paths]
classeNames
total_datadir = 'F:/365data/P4/'
train_transforms = transforms. Compose( [
transforms. Resize( [ 224 , 224 ] ) ,
transforms. ToTensor( ) ,
transforms. Normalize(
mean= [ 0.485 , 0.456 , 0.406 ] ,
std= [ 0.229 , 0.224 , 0.225 ] )
] )
total_data = datasets. ImageFolder( total_datadir, transform= train_transforms)
total_data
train_size = int ( 0.8 * len ( total_data) )
test_size = len ( total_data) - train_size
train_dataset, test_dataset = torch. utils. data. random_split( total_data, [ train_size, test_size] )
train_dataset, test_dataset
batch_size = 32
train_dl = torch. utils. data. DataLoader( train_dataset,
batch_size= batch_size,
shuffle= True ,
num_workers= 1 )
test_dl = torch. utils. data. DataLoader( test_dataset,
batch_size= batch_size,
shuffle= True ,
num_workers= 1 )
for X, y in test_dl:
print ( "Shape of X [N, C, H, W]: " , X. shape)
print ( "Shape of y: " , y. shape, y. dtype)
break
import torch. nn. functional as F
class inception_block ( nn. Module) :
def __init__ ( self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj) :
super ( inception_block, self) . __init__( )
self. branch1 = nn. Sequential(
nn. Conv2d( in_channels, ch1x1, kernel_size= 1 ) ,
nn. BatchNorm2d( ch1x1) ,
nn. ReLU( inplace= True )
)
self. branch2 = nn. Sequential(
nn. Conv2d( in_channels, ch3x3red, kernel_size= 1 ) ,
nn. BatchNorm2d( ch3x3red) ,
nn. ReLU( inplace= True ) ,
nn. Conv2d( ch3x3red, ch3x3, kernel_size= 3 , padding= 1 ) ,
nn. BatchNorm2d( ch3x3) ,
nn. ReLU( inplace= True )
)
self. branch3 = nn. Sequential(
nn. Conv2d( in_channels, ch5x5red, kernel_size= 1 ) ,
nn. BatchNorm2d( ch5x5red) ,
nn. ReLU( inplace= True ) ,
nn. Conv2d( ch5x5red, ch5x5, kernel_size= 5 , padding= 2 ) ,
nn. BatchNorm2d( ch5x5) ,
nn. ReLU( inplace= True )
)
self. branch4 = nn. Sequential(
nn. MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 ) ,
nn. Conv2d( in_channels, pool_proj, kernel_size= 1 ) ,
nn. BatchNorm2d( pool_proj) ,
nn. ReLU( inplace= True )
)
def forward ( self, x) :
x1 = self. branch1( x)
x2 = self. branch2( x)
x3 = self. branch3( x)
x4 = self. branch4( x)
outputs = [ x1, x2, x3, x4]
return torch. cat( outputs, 1 )
class InceptionV1 ( nn. Module) :
def __init__ ( self, num_classes= 1000 ) :
super ( InceptionV1, self) . __init__( )
self. Stem = nn. Sequential(
nn. Conv2d( 3 , 64 , kernel_size= 7 , stride= 2 , padding= 3 ) ,
nn. ReLU( ) ,
nn. MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 ) ,
nn. Conv2d( 64 , 64 , kernel_size= 1 ) ,
nn. ReLU( ) ,
nn. Conv2d( 64 , 192 , kernel_size= 3 , padding= 1 ) ,
nn. ReLU( ) ,
nn. MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 )
)
self. inception1 = nn. Sequential(
inception_block( 192 , 64 , 96 , 128 , 16 , 32 , 32 ) ,
inception_block( 256 , 128 , 128 , 192 , 32 , 96 , 64 ) ,
nn. MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 )
)
self. inception2 = nn. Sequential(
inception_block( 480 , 192 , 96 , 208 , 16 , 48 , 64 ) ,
inception_block( 512 , 160 , 112 , 224 , 24 , 64 , 64 ) ,
inception_block( 512 , 128 , 128 , 256 , 24 , 64 , 64 ) ,
inception_block( 512 , 112 , 144 , 288 , 32 , 64 , 64 ) ,
inception_block( 528 , 256 , 160 , 320 , 32 , 128 , 128 ) ,
nn. MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 )
)
self. inception3 = nn. Sequential(
inception_block( 832 , 256 , 160 , 320 , 32 , 128 , 128 ) ,
inception_block( 832 , 384 , 192 , 384 , 48 , 128 , 128 ) ,
nn. AvgPool2d( kernel_size= 7 , stride= 1 ) ,
nn. Dropout2d( 0.4 )
)
self. classifier = nn. Sequential(
nn. Linear( 1024 , 1024 ) ,
nn. ReLU( ) ,
nn. Linear( 1024 , num_classes) ,
nn. Softmax( dim= 1 )
)
def forward ( self, x) :
x = self. Stem( x)
x = self. inception1( x)
x = self. inception2( x)
x = self. inception3( x)
x = x. view( x. size( 0 ) , - 1 )
x = self. classifier( x)
return x
import torchsummary as summary
model = InceptionV1( num_classes= len ( classeNames) ) . to( device)
summary. summary( model, ( 3 , 224 , 224 ) )
print ( model)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Layer ( type ) Output Shape Param
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == ==
Conv2d- 1 [ - 1 , 64 , 112 , 112 ] 9 , 472
ReLU- 2 [ - 1 , 64 , 112 , 112 ] 0
MaxPool2d- 3 [ - 1 , 64 , 56 , 56 ] 0
Conv2d- 4 [ - 1 , 64 , 56 , 56 ] 4 , 160
ReLU- 5 [ - 1 , 64 , 56 , 56 ] 0
Conv2d- 6 [ - 1 , 192 , 56 , 56 ] 110 , 784
ReLU- 7 [ - 1 , 192 , 56 , 56 ] 0
MaxPool2d- 8 [ - 1 , 192 , 28 , 28 ] 0
Conv2d- 9 [ - 1 , 64 , 28 , 28 ] 12 , 352
BatchNorm2d- 10 [ - 1 , 64 , 28 , 28 ] 128
ReLU- 11 [ - 1 , 64 , 28 , 28 ] 0
Conv2d- 12 [ - 1 , 96 , 28 , 28 ] 18 , 528
BatchNorm2d- 13 [ - 1 , 96 , 28 , 28 ] 192
ReLU- 14 [ - 1 , 96 , 28 , 28 ] 0
Conv2d- 15 [ - 1 , 128 , 28 , 28 ] 110 , 720
BatchNorm2d- 16 [ - 1 , 128 , 28 , 28 ] 256
ReLU- 17 [ - 1 , 128 , 28 , 28 ] 0
Conv2d- 18 [ - 1 , 16 , 28 , 28 ] 3 , 088
BatchNorm2d- 19 [ - 1 , 16 , 28 , 28 ] 32
ReLU- 20 [ - 1 , 16 , 28 , 28 ] 0
Conv2d- 21 [ - 1 , 32 , 28 , 28 ] 12 , 832
BatchNorm2d- 22 [ - 1 , 32 , 28 , 28 ] 64
ReLU- 23 [ - 1 , 32 , 28 , 28 ] 0
MaxPool2d- 24 [ - 1 , 192 , 28 , 28 ] 0
Conv2d- 25 [ - 1 , 32 , 28 , 28 ] 6 , 176
BatchNorm2d- 26 [ - 1 , 32 , 28 , 28 ] 64
ReLU- 27 [ - 1 , 32 , 28 , 28 ] 0
inception_block- 28 [ - 1 , 256 , 28 , 28 ] 0
Conv2d- 29 [ - 1 , 128 , 28 , 28 ] 32 , 896
BatchNorm2d- 30 [ - 1 , 128 , 28 , 28 ] 256
ReLU- 31 [ - 1 , 128 , 28 , 28 ] 0
Conv2d- 32 [ - 1 , 128 , 28 , 28 ] 32 , 896
BatchNorm2d- 33 [ - 1 , 128 , 28 , 28 ] 256
ReLU- 34 [ - 1 , 128 , 28 , 28 ] 0
Conv2d- 35 [ - 1 , 192 , 28 , 28 ] 221 , 376
BatchNorm2d- 36 [ - 1 , 192 , 28 , 28 ] 384
ReLU- 37 [ - 1 , 192 , 28 , 28 ] 0
Conv2d- 38 [ - 1 , 32 , 28 , 28 ] 8 , 224
BatchNorm2d- 39 [ - 1 , 32 , 28 , 28 ] 64
ReLU- 40 [ - 1 , 32 , 28 , 28 ] 0
Conv2d- 41 [ - 1 , 96 , 28 , 28 ] 76 , 896
BatchNorm2d- 42 [ - 1 , 96 , 28 , 28 ] 192
ReLU- 43 [ - 1 , 96 , 28 , 28 ] 0
MaxPool2d- 44 [ - 1 , 256 , 28 , 28 ] 0
Conv2d- 45 [ - 1 , 64 , 28 , 28 ] 16 , 448
BatchNorm2d- 46 [ - 1 , 64 , 28 , 28 ] 128
ReLU- 47 [ - 1 , 64 , 28 , 28 ] 0
inception_block- 48 [ - 1 , 480 , 28 , 28 ] 0
MaxPool2d- 49 [ - 1 , 480 , 14 , 14 ] 0
Conv2d- 50 [ - 1 , 192 , 14 , 14 ] 92 , 352
BatchNorm2d- 51 [ - 1 , 192 , 14 , 14 ] 384
ReLU- 52 [ - 1 , 192 , 14 , 14 ] 0
Conv2d- 53 [ - 1 , 96 , 14 , 14 ] 46 , 176
BatchNorm2d- 54 [ - 1 , 96 , 14 , 14 ] 192
ReLU- 55 [ - 1 , 96 , 14 , 14 ] 0
Conv2d- 56 [ - 1 , 208 , 14 , 14 ] 179 , 920
BatchNorm2d- 57 [ - 1 , 208 , 14 , 14 ] 416
ReLU- 58 [ - 1 , 208 , 14 , 14 ] 0
Conv2d- 59 [ - 1 , 16 , 14 , 14 ] 7 , 696
BatchNorm2d- 60 [ - 1 , 16 , 14 , 14 ] 32
ReLU- 61 [ - 1 , 16 , 14 , 14 ] 0
Conv2d- 62 [ - 1 , 48 , 14 , 14 ] 19 , 248
BatchNorm2d- 63 [ - 1 , 48 , 14 , 14 ] 96
ReLU- 64 [ - 1 , 48 , 14 , 14 ] 0
MaxPool2d- 65 [ - 1 , 480 , 14 , 14 ] 0
Conv2d- 66 [ - 1 , 64 , 14 , 14 ] 30 , 784
BatchNorm2d- 67 [ - 1 , 64 , 14 , 14 ] 128
ReLU- 68 [ - 1 , 64 , 14 , 14 ] 0
inception_block- 69 [ - 1 , 512 , 14 , 14 ] 0
Conv2d- 70 [ - 1 , 160 , 14 , 14 ] 82 , 080
BatchNorm2d- 71 [ - 1 , 160 , 14 , 14 ] 320
ReLU- 72 [ - 1 , 160 , 14 , 14 ] 0
Conv2d- 73 [ - 1 , 112 , 14 , 14 ] 57 , 456
BatchNorm2d- 74 [ - 1 , 112 , 14 , 14 ] 224
ReLU- 75 [ - 1 , 112 , 14 , 14 ] 0
Conv2d- 76 [ - 1 , 224 , 14 , 14 ] 226 , 016
BatchNorm2d- 77 [ - 1 , 224 , 14 , 14 ] 448
ReLU- 78 [ - 1 , 224 , 14 , 14 ] 0
Conv2d- 79 [ - 1 , 24 , 14 , 14 ] 12 , 312
BatchNorm2d- 80 [ - 1 , 24 , 14 , 14 ] 48
ReLU- 81 [ - 1 , 24 , 14 , 14 ] 0
Conv2d- 82 [ - 1 , 64 , 14 , 14 ] 38 , 464
BatchNorm2d- 83 [ - 1 , 64 , 14 , 14 ] 128
ReLU- 84 [ - 1 , 64 , 14 , 14 ] 0
MaxPool2d- 85 [ - 1 , 512 , 14 , 14 ] 0
Conv2d- 86 [ - 1 , 64 , 14 , 14 ] 32 , 832
BatchNorm2d- 87 [ - 1 , 64 , 14 , 14 ] 128
ReLU- 88 [ - 1 , 64 , 14 , 14 ] 0
inception_block- 89 [ - 1 , 512 , 14 , 14 ] 0
Conv2d- 90 [ - 1 , 128 , 14 , 14 ] 65 , 664
BatchNorm2d- 91 [ - 1 , 128 , 14 , 14 ] 256
ReLU- 92 [ - 1 , 128 , 14 , 14 ] 0
Conv2d- 93 [ - 1 , 128 , 14 , 14 ] 65 , 664
BatchNorm2d- 94 [ - 1 , 128 , 14 , 14 ] 256
ReLU- 95 [ - 1 , 128 , 14 , 14 ] 0
Conv2d- 96 [ - 1 , 256 , 14 , 14 ] 295 , 168
BatchNorm2d- 97 [ - 1 , 256 , 14 , 14 ] 512
ReLU- 98 [ - 1 , 256 , 14 , 14 ] 0
Conv2d- 99 [ - 1 , 24 , 14 , 14 ] 12 , 312
BatchNorm2d- 100 [ - 1 , 24 , 14 , 14 ] 48
ReLU- 101 [ - 1 , 24 , 14 , 14 ] 0
Conv2d- 102 [ - 1 , 64 , 14 , 14 ] 38 , 464
BatchNorm2d- 103 [ - 1 , 64 , 14 , 14 ] 128
ReLU- 104 [ - 1 , 64 , 14 , 14 ] 0
MaxPool2d- 105 [ - 1 , 512 , 14 , 14 ] 0
Conv2d- 106 [ - 1 , 64 , 14 , 14 ] 32 , 832
BatchNorm2d- 107 [ - 1 , 64 , 14 , 14 ] 128
ReLU- 108 [ - 1 , 64 , 14 , 14 ] 0
inception_block- 109 [ - 1 , 512 , 14 , 14 ] 0
Conv2d- 110 [ - 1 , 112 , 14 , 14 ] 57 , 456
BatchNorm2d- 111 [ - 1 , 112 , 14 , 14 ] 224
ReLU- 112 [ - 1 , 112 , 14 , 14 ] 0
Conv2d- 113 [ - 1 , 144 , 14 , 14 ] 73 , 872
BatchNorm2d- 114 [ - 1 , 144 , 14 , 14 ] 288
ReLU- 115 [ - 1 , 144 , 14 , 14 ] 0
Conv2d- 116 [ - 1 , 288 , 14 , 14 ] 373 , 536
BatchNorm2d- 117 [ - 1 , 288 , 14 , 14 ] 576
ReLU- 118 [ - 1 , 288 , 14 , 14 ] 0
Conv2d- 119 [ - 1 , 32 , 14 , 14 ] 16 , 416
BatchNorm2d- 120 [ - 1 , 32 , 14 , 14 ] 64
ReLU- 121 [ - 1 , 32 , 14 , 14 ] 0
Conv2d- 122 [ - 1 , 64 , 14 , 14 ] 51 , 264
BatchNorm2d- 123 [ - 1 , 64 , 14 , 14 ] 128
ReLU- 124 [ - 1 , 64 , 14 , 14 ] 0
MaxPool2d- 125 [ - 1 , 512 , 14 , 14 ] 0
Conv2d- 126 [ - 1 , 64 , 14 , 14 ] 32 , 832
BatchNorm2d- 127 [ - 1 , 64 , 14 , 14 ] 128
ReLU- 128 [ - 1 , 64 , 14 , 14 ] 0
inception_block- 129 [ - 1 , 528 , 14 , 14 ] 0
Conv2d- 130 [ - 1 , 256 , 14 , 14 ] 135 , 424
BatchNorm2d- 131 [ - 1 , 256 , 14 , 14 ] 512
ReLU- 132 [ - 1 , 256 , 14 , 14 ] 0
Conv2d- 133 [ - 1 , 160 , 14 , 14 ] 84 , 640
BatchNorm2d- 134 [ - 1 , 160 , 14 , 14 ] 320
ReLU- 135 [ - 1 , 160 , 14 , 14 ] 0
Conv2d- 136 [ - 1 , 320 , 14 , 14 ] 461 , 120
BatchNorm2d- 137 [ - 1 , 320 , 14 , 14 ] 640
ReLU- 138 [ - 1 , 320 , 14 , 14 ] 0
Conv2d- 139 [ - 1 , 32 , 14 , 14 ] 16 , 928
BatchNorm2d- 140 [ - 1 , 32 , 14 , 14 ] 64
ReLU- 141 [ - 1 , 32 , 14 , 14 ] 0
Conv2d- 142 [ - 1 , 128 , 14 , 14 ] 102 , 528
BatchNorm2d- 143 [ - 1 , 128 , 14 , 14 ] 256
ReLU- 144 [ - 1 , 128 , 14 , 14 ] 0
MaxPool2d- 145 [ - 1 , 528 , 14 , 14 ] 0
Conv2d- 146 [ - 1 , 128 , 14 , 14 ] 67 , 712
BatchNorm2d- 147 [ - 1 , 128 , 14 , 14 ] 256
ReLU- 148 [ - 1 , 128 , 14 , 14 ] 0
inception_block- 149 [ - 1 , 832 , 14 , 14 ] 0
MaxPool2d- 150 [ - 1 , 832 , 7 , 7 ] 0
Conv2d- 151 [ - 1 , 256 , 7 , 7 ] 213 , 248
BatchNorm2d- 152 [ - 1 , 256 , 7 , 7 ] 512
ReLU- 153 [ - 1 , 256 , 7 , 7 ] 0
Conv2d- 154 [ - 1 , 160 , 7 , 7 ] 133 , 280
BatchNorm2d- 155 [ - 1 , 160 , 7 , 7 ] 320
ReLU- 156 [ - 1 , 160 , 7 , 7 ] 0
Conv2d- 157 [ - 1 , 320 , 7 , 7 ] 461 , 120
BatchNorm2d- 158 [ - 1 , 320 , 7 , 7 ] 640
ReLU- 159 [ - 1 , 320 , 7 , 7 ] 0
Conv2d- 160 [ - 1 , 32 , 7 , 7 ] 26 , 656
BatchNorm2d- 161 [ - 1 , 32 , 7 , 7 ] 64
ReLU- 162 [ - 1 , 32 , 7 , 7 ] 0
Conv2d- 163 [ - 1 , 128 , 7 , 7 ] 102 , 528
BatchNorm2d- 164 [ - 1 , 128 , 7 , 7 ] 256
ReLU- 165 [ - 1 , 128 , 7 , 7 ] 0
MaxPool2d- 166 [ - 1 , 832 , 7 , 7 ] 0
Conv2d- 167 [ - 1 , 128 , 7 , 7 ] 106 , 624
BatchNorm2d- 168 [ - 1 , 128 , 7 , 7 ] 256
ReLU- 169 [ - 1 , 128 , 7 , 7 ] 0
inception_block- 170 [ - 1 , 832 , 7 , 7 ] 0
Conv2d- 171 [ - 1 , 384 , 7 , 7 ] 319 , 872
BatchNorm2d- 172 [ - 1 , 384 , 7 , 7 ] 768
ReLU- 173 [ - 1 , 384 , 7 , 7 ] 0
Conv2d- 174 [ - 1 , 192 , 7 , 7 ] 159 , 936
BatchNorm2d- 175 [ - 1 , 192 , 7 , 7 ] 384
ReLU- 176 [ - 1 , 192 , 7 , 7 ] 0
Conv2d- 177 [ - 1 , 384 , 7 , 7 ] 663 , 936
BatchNorm2d- 178 [ - 1 , 384 , 7 , 7 ] 768
ReLU- 179 [ - 1 , 384 , 7 , 7 ] 0
Conv2d- 180 [ - 1 , 48 , 7 , 7 ] 39 , 984
BatchNorm2d- 181 [ - 1 , 48 , 7 , 7 ] 96
ReLU- 182 [ - 1 , 48 , 7 , 7 ] 0
Conv2d- 183 [ - 1 , 128 , 7 , 7 ] 153 , 728
BatchNorm2d- 184 [ - 1 , 128 , 7 , 7 ] 256
ReLU- 185 [ - 1 , 128 , 7 , 7 ] 0
MaxPool2d- 186 [ - 1 , 832 , 7 , 7 ] 0
Conv2d- 187 [ - 1 , 128 , 7 , 7 ] 106 , 624
BatchNorm2d- 188 [ - 1 , 128 , 7 , 7 ] 256
ReLU- 189 [ - 1 , 128 , 7 , 7 ] 0
inception_block- 190 [ - 1 , 1024 , 7 , 7 ] 0
AvgPool2d- 191 [ - 1 , 1024 , 1 , 1 ] 0
Dropout2d- 192 [ - 1 , 1024 , 1 , 1 ] 0
Linear- 193 [ - 1 , 1024 ] 1 , 049 , 600
ReLU- 194 [ - 1 , 1024 ] 0
Linear- 195 [ - 1 , 2 ] 2 , 050
Softmax- 196 [ - 1 , 2 ] 0
== == == == == == == == == == == == == == == == == == == == == == == == == == == == == == == ==
Total params: 7 , 039 , 122
Trainable params: 7 , 039 , 122
Non- trainable params: 0
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Input size ( MB) : 0.57
Forward/ backward pass size ( MB) : 81.86
Params size ( MB) : 26.85
Estimated Total Size ( MB) : 109.29
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
InceptionV1(
( Stem) : Sequential(
( 0 ) : Conv2d( 3 , 64 , kernel_size= ( 7 , 7 ) , stride= ( 2 , 2 ) , padding= ( 3 , 3 ) )
( 1 ) : ReLU( )
( 2 ) : MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 , dilation= 1 , ceil_mode= False )
( 3 ) : Conv2d( 64 , 64 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 4 ) : ReLU( )
( 5 ) : Conv2d( 64 , 192 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 6 ) : ReLU( )
( 7 ) : MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 , dilation= 1 , ceil_mode= False )
)
( inception1) : Sequential(
( 0 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 192 , 64 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 192 , 96 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 96 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 96 , 128 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 192 , 16 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 16 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 16 , 32 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 32 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 192 , 32 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 32 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 1 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 256 , 128 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 256 , 128 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 128 , 192 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 192 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 256 , 32 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 32 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 32 , 96 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 96 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 256 , 64 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 2 ) : MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 , dilation= 1 , ceil_mode= False )
)
( inception2) : Sequential(
( 0 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 480 , 192 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 192 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 480 , 96 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 96 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 96 , 208 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 208 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 480 , 16 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 16 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 16 , 48 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 48 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 480 , 64 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 1 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 512 , 160 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 160 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 512 , 112 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 112 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 112 , 224 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 224 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 512 , 24 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 24 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 24 , 64 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 512 , 64 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 2 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 512 , 128 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 512 , 128 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 128 , 256 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 256 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 512 , 24 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 24 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 24 , 64 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 512 , 64 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 3 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 512 , 112 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 112 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 512 , 144 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 144 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 144 , 288 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 288 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 512 , 32 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 32 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 32 , 64 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 512 , 64 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 64 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 4 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 528 , 256 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 256 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 528 , 160 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 160 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 160 , 320 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 320 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 528 , 32 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 32 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 32 , 128 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 528 , 128 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 5 ) : MaxPool2d( kernel_size= 3 , stride= 2 , padding= 1 , dilation= 1 , ceil_mode= False )
)
( inception3) : Sequential(
( 0 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 832 , 256 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 256 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 832 , 160 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 160 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 160 , 320 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 320 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 832 , 32 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 32 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 32 , 128 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 832 , 128 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 1 ) : inception_block(
( branch1) : Sequential(
( 0 ) : Conv2d( 832 , 384 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 384 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
)
( branch2) : Sequential(
( 0 ) : Conv2d( 832 , 192 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 192 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 192 , 384 , kernel_size= ( 3 , 3 ) , stride= ( 1 , 1 ) , padding= ( 1 , 1 ) )
( 4 ) : BatchNorm2d( 384 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch3) : Sequential(
( 0 ) : Conv2d( 832 , 48 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 1 ) : BatchNorm2d( 48 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 2 ) : ReLU( inplace= True )
( 3 ) : Conv2d( 48 , 128 , kernel_size= ( 5 , 5 ) , stride= ( 1 , 1 ) , padding= ( 2 , 2 ) )
( 4 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 5 ) : ReLU( inplace= True )
)
( branch4) : Sequential(
( 0 ) : MaxPool2d( kernel_size= 3 , stride= 1 , padding= 1 , dilation= 1 , ceil_mode= False )
( 1 ) : Conv2d( 832 , 128 , kernel_size= ( 1 , 1 ) , stride= ( 1 , 1 ) )
( 2 ) : BatchNorm2d( 128 , eps= 1e-05 , momentum= 0.1 , affine= True , track_running_stats= True )
( 3 ) : ReLU( inplace= True )
)
)
( 2 ) : AvgPool2d( kernel_size= 7 , stride= 1 , padding= 0 )
( 3 ) : Dropout2d( p= 0.4 , inplace= False )
)
( classifier) : Sequential(
( 0 ) : Linear( in_features= 1024 , out_features= 1024 , bias= True )
( 1 ) : ReLU( )
( 2 ) : Linear( in_features= 1024 , out_features= 2 , bias= True )
( 3 ) : Softmax( dim= 1 )
)
)
def train ( dataloader, model, optimizer, loss_fn) :
size = len ( dataloader. dataset)
num_batches = len ( dataloader)
train_acc, train_loss = 0 , 0
for X, y in dataloader:
X, y = X. to( device) , y. to( device)
pred = model( X)
loss = loss_fn( pred, y)
optimizer. zero_grad( )
loss. backward( )
optimizer. step( )
train_loss += loss. item( )
train_acc += ( pred. argmax( 1 ) == y) . type ( torch. float ) . sum ( ) . item( )
train_loss /= num_batches
train_acc /= size
return train_acc, train_loss
def test ( dataloader, model, loss_fn) :
size = len ( dataloader. dataset)
num_batches = len ( dataloader)
test_loss, test_acc = 0 , 0
with torch. no_grad( ) :
for imgs, target in dataloader:
imgs, target = imgs. to( device) , target. to( device)
target_pred = model( imgs)
loss = loss_fn( target_pred, target)
test_loss += loss. item( )
test_acc += ( target_pred. argmax( 1 ) == target) . type ( torch. float ) . sum ( ) . item( )
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
loss_fn = nn. CrossEntropyLoss( )
learn_rate = 1e-4
opt = torch. optim. Adam( model. parameters( ) , lr= learn_rate)
import copy
epochs = 20
train_loss= [ ]
train_acc= [ ]
test_loss= [ ]
test_acc= [ ]
best_acc = 0
for epoch in range ( epochs) :
model. train( )
epoch_train_acc, epoch_train_loss = train( train_dl, model, opt, loss_fn)
model. eval ( )
epoch_test_acc, epoch_test_loss = test( test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy. deepcopy( model)
train_acc. append( epoch_train_acc)
train_loss. append( epoch_train_loss)
test_acc. append( epoch_test_acc)
test_loss. append( epoch_test_loss)
lr = opt. state_dict( ) [ 'param_groups' ] [ 0 ] [ 'lr' ]
template = ( 'Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}' )
print ( template. format ( epoch+ 1 , epoch_train_acc* 100 , epoch_train_loss,
epoch_test_acc* 100 , epoch_test_loss, lr) )
PATH = 'F:/365data/J8best_model.pth'
torch. save( best_model. state_dict( ) , PATH)
print ( 'Done' )
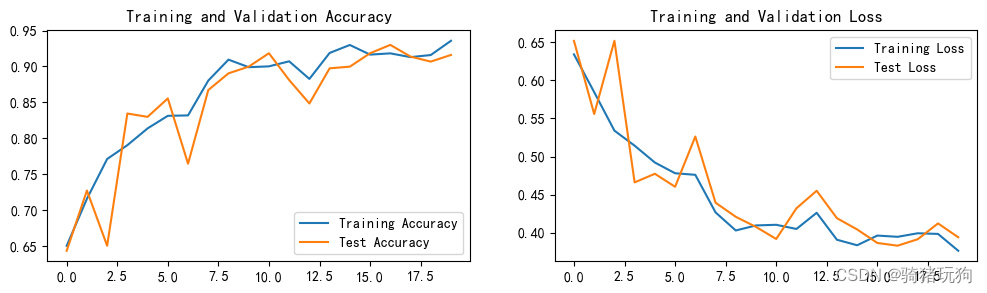
Epoch: 1 , Train_acc: 65.0 % , Train_loss: 0.634 , Test_acc: 64.3 % , Test_loss: 0.652 , Lr: 1.00E-04
Epoch: 2 , Train_acc: 71.6 % , Train_loss: 0.585 , Test_acc: 72.7 % , Test_loss: 0.556 , Lr: 1.00E-04
Epoch: 3 , Train_acc: 77.1 % , Train_loss: 0.534 , Test_acc: 65.0 % , Test_loss: 0.652 , Lr: 1.00E-04
Epoch: 4 , Train_acc: 79.0 % , Train_loss: 0.514 , Test_acc: 83.4 % , Test_loss: 0.466 , Lr: 1.00E-04
Epoch: 5 , Train_acc: 81.4 % , Train_loss: 0.492 , Test_acc: 83.0 % , Test_loss: 0.477 , Lr: 1.00E-04
Epoch: 6 , Train_acc: 83.1 % , Train_loss: 0.478 , Test_acc: 85.5 % , Test_loss: 0.460 , Lr: 1.00E-04
Epoch: 7 , Train_acc: 83.2 % , Train_loss: 0.476 , Test_acc: 76.5 % , Test_loss: 0.526 , Lr: 1.00E-04
Epoch: 8 , Train_acc: 88.0 % , Train_loss: 0.427 , Test_acc: 86.7 % , Test_loss: 0.439 , Lr: 1.00E-04
Epoch: 9 , Train_acc: 91.0 % , Train_loss: 0.403 , Test_acc: 89.0 % , Test_loss: 0.421 , Lr: 1.00E-04
Epoch: 10 , Train_acc: 89.9 % , Train_loss: 0.410 , Test_acc: 90.0 % , Test_loss: 0.408 , Lr: 1.00E-04
Epoch: 11 , Train_acc: 90.0 % , Train_loss: 0.410 , Test_acc: 91.8 % , Test_loss: 0.392 , Lr: 1.00E-04
Epoch: 12 , Train_acc: 90.7 % , Train_loss: 0.405 , Test_acc: 88.1 % , Test_loss: 0.432 , Lr: 1.00E-04
Epoch: 13 , Train_acc: 88.3 % , Train_loss: 0.426 , Test_acc: 84.8 % , Test_loss: 0.455 , Lr: 1.00E-04
Epoch: 14 , Train_acc: 91.9 % , Train_loss: 0.391 , Test_acc: 89.7 % , Test_loss: 0.419 , Lr: 1.00E-04
Epoch: 15 , Train_acc: 93.0 % , Train_loss: 0.384 , Test_acc: 90.0 % , Test_loss: 0.404 , Lr: 1.00E-04
Epoch: 16 , Train_acc: 91.7 % , Train_loss: 0.396 , Test_acc: 91.8 % , Test_loss: 0.387 , Lr: 1.00E-04
Epoch: 17 , Train_acc: 91.8 % , Train_loss: 0.395 , Test_acc: 93.0 % , Test_loss: 0.383 , Lr: 1.00E-04
Epoch: 18 , Train_acc: 91.3 % , Train_loss: 0.399 , Test_acc: 91.4 % , Test_loss: 0.392 , Lr: 1.00E-04
Epoch: 19 , Train_acc: 91.6 % , Train_loss: 0.399 , Test_acc: 90.7 % , Test_loss: 0.412 , Lr: 1.00E-04
Epoch: 20 , Train_acc: 93.6 % , Train_loss: 0.376 , Test_acc: 91.6 % , Test_loss: 0.394 , Lr: 1.00E-04
Done
import matplotlib. pyplot as plt
import warnings
warnings. filterwarnings( "ignore" )
plt. rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
plt. rcParams[ 'figure.dpi' ] = 100
epochs_range = range ( epochs)
plt. figure( figsize= ( 12 , 3 ) )
plt. subplot( 1 , 2 , 1 )
plt. plot( epochs_range, train_acc, label= 'Training Accuracy' )
plt. plot( epochs_range, test_acc, label= 'Test Accuracy' )
plt. legend( loc= 'lower right' )
plt. title( 'Training and Validation Accuracy' )
plt. subplot( 1 , 2 , 2 )
plt. plot( epochs_range, train_loss, label= 'Training Loss' )
plt. plot( epochs_range, test_loss, label= 'Test Loss' )
plt. legend( loc= 'upper right' )
plt. title( 'Training and Validation Loss' )
plt. show( )
Inception v1的特点是并行,简单来讲就是同时使用多个卷积核(如33、5 5),之后使用torch.cat方法将多个输出结果叠加 并行增加了网络的深度,因为在同一层提取了不同的特征 另外,在卷积核前还使用了1*1卷积核,目的是减少运算量






















 2502
2502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









