






 本文详细介绍InceptionV1模型(又称GoogLeNet),包括模型结构、关键思想及其PyTorch实现源码。该模型利用多种尺寸的卷积核并行处理图像,有效提升了图像特征提取能力。
本文详细介绍InceptionV1模型(又称GoogLeNet),包括模型结构、关键思想及其PyTorch实现源码。该模型利用多种尺寸的卷积核并行处理图像,有效提升了图像特征提取能力。
Pytorch实现InceptionV1模型
模型简介
论文链接:https://arxiv.org/pdf/1409.4842v1.pdf
模型提出时间:2014年9月
参数量:5M
Top1准确率:69.8%
模型基本思想:同时使用1×1、3×3和5×5的卷积核对图像进行特征提取,充分增加了模型的宽度,从而提高模型对图像不同尺度特征的适应能力。其中,1×1的卷积核实际是对图像进行缩放,这对识别精度的提升也有一定帮助。
模型结构及源码
InceptionV1模块
InceptionV1模块由下图中的基本模块构成,其中每个子模块的stride均为1,padding均为⌊kernel_size/2⌋,通过这样设置stride和padding的大小,每个模块在处理图片时不会改变图片的大小,而只改变通道数目。由下图可见,InceptionV1模型的输出是四个卷积核的输出叠加的结果,即InceptionV1并没有改变图片的大小,而只改变了通道数目。
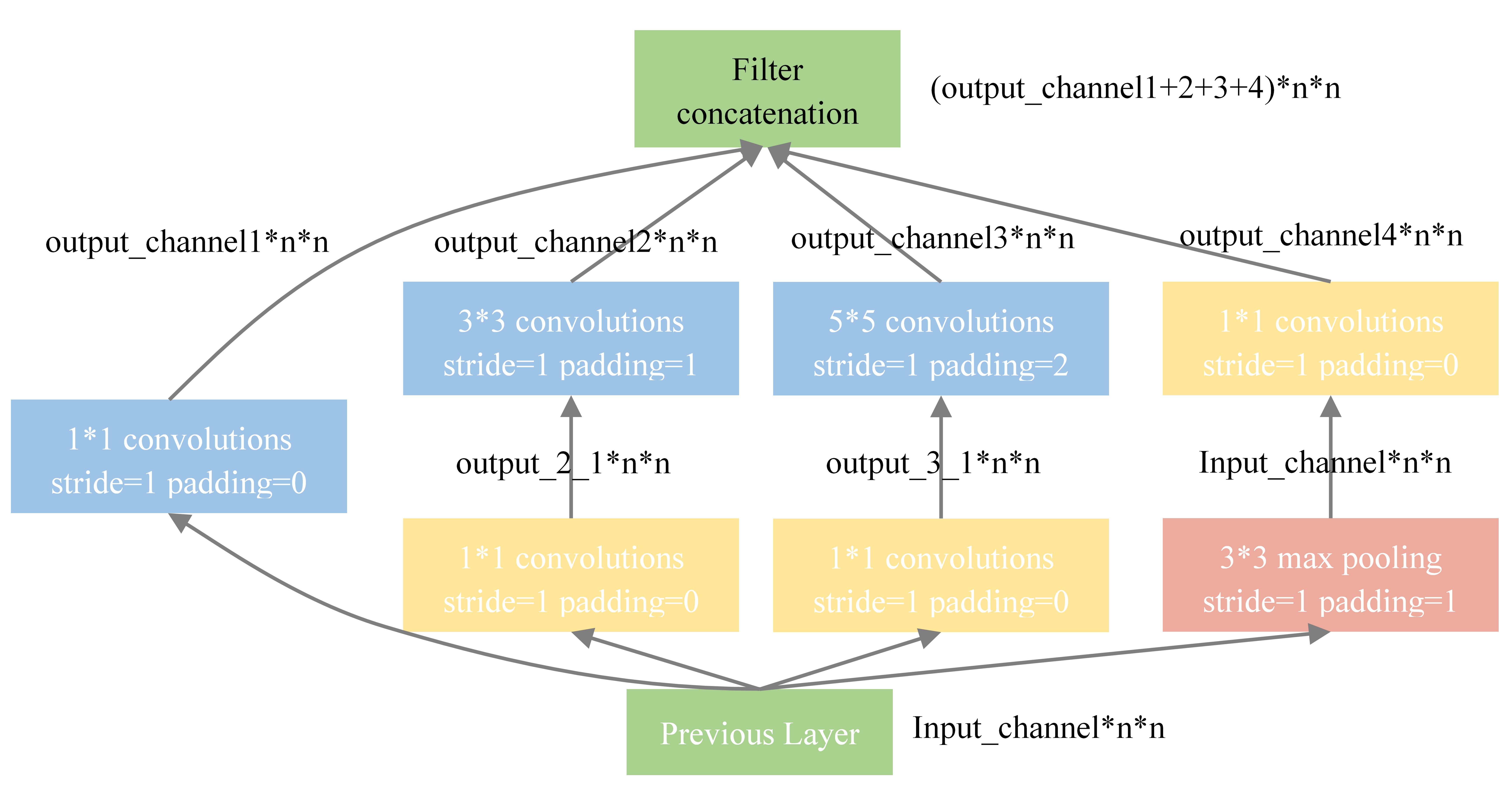
InceptionV1模块中的每个卷积模块由三部分构成:卷积、批标准化和激活。
InceptionV1模块中的卷积模块源码如下:
# InceptionV1的卷积模块:卷积 + 批标准化 + 激活
def ConvBNReLU(in_channels,out_channels,kernel_size):
return nn.Sequential(
# 卷积核的stride=1, padding=kernel_size//2
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=1,padding=kernel_size//2),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
InceptionV1模块的源码如下:
# InceptionV1模块
class InceptionV1Module(nn.Module):
def __init__(self, inchannel, outchannel1, outchannel2_1, outchannel2_2, outchannel3_1, outchannel3_2, outchannel4):
super(InceptionV1Module, self).__init__()
# 1*1卷积模块
self.block1 = ConvBNRelu(inchannel, outchannel1, 1)
# 1*1卷积模块 + 3*3卷积模块
self.block2_1 = ConvBNRelu(inchannel, outchannel2_1, 1)
self.block2_2 = ConvBNRelu(outchannel2_1, outchannel2_2, 3)
# 1*1卷积模块 + 5*5卷积模块
self.block3_1 = ConvBNRelu(inchannel, outchannel3_1, 1)
self.block3_2 = ConvBNRelu(outchannel3_1, outchannel3_2, 5)
# 3*3池化模块 + 1*1卷积模块
self.block4_1 = nn.MaxPool2d(kernel_size = 3, stride = 1, padding = 1)
self.block4_2 = ConvBNRelu(inchannel, outchannel4, 1)
def forward(self, x):
x1 = self.block1(x) # output1
x2 = self.block2_1(x)
x2 = self.block2_2(x2) # output2
x3 = self.block3_1(x)
x3 = self.block3_2(x3) # output3
x4 = self.block4_1(x)
x4 = self.block4_2(x4) # output4
x = torch.cat([x1, x2, x3, x4], dim=1) # 四个模块的输出叠加
return x
全连接模块
经过多个Inception模块处理后,可将Inception模块的输出通过一个全连接模块得到最终输出,全连接模块的基本构架如下图所示。全连接模块的输入是14×14的矩阵,而输出是待分类类别个数。全连接模块的结构和源码如下:
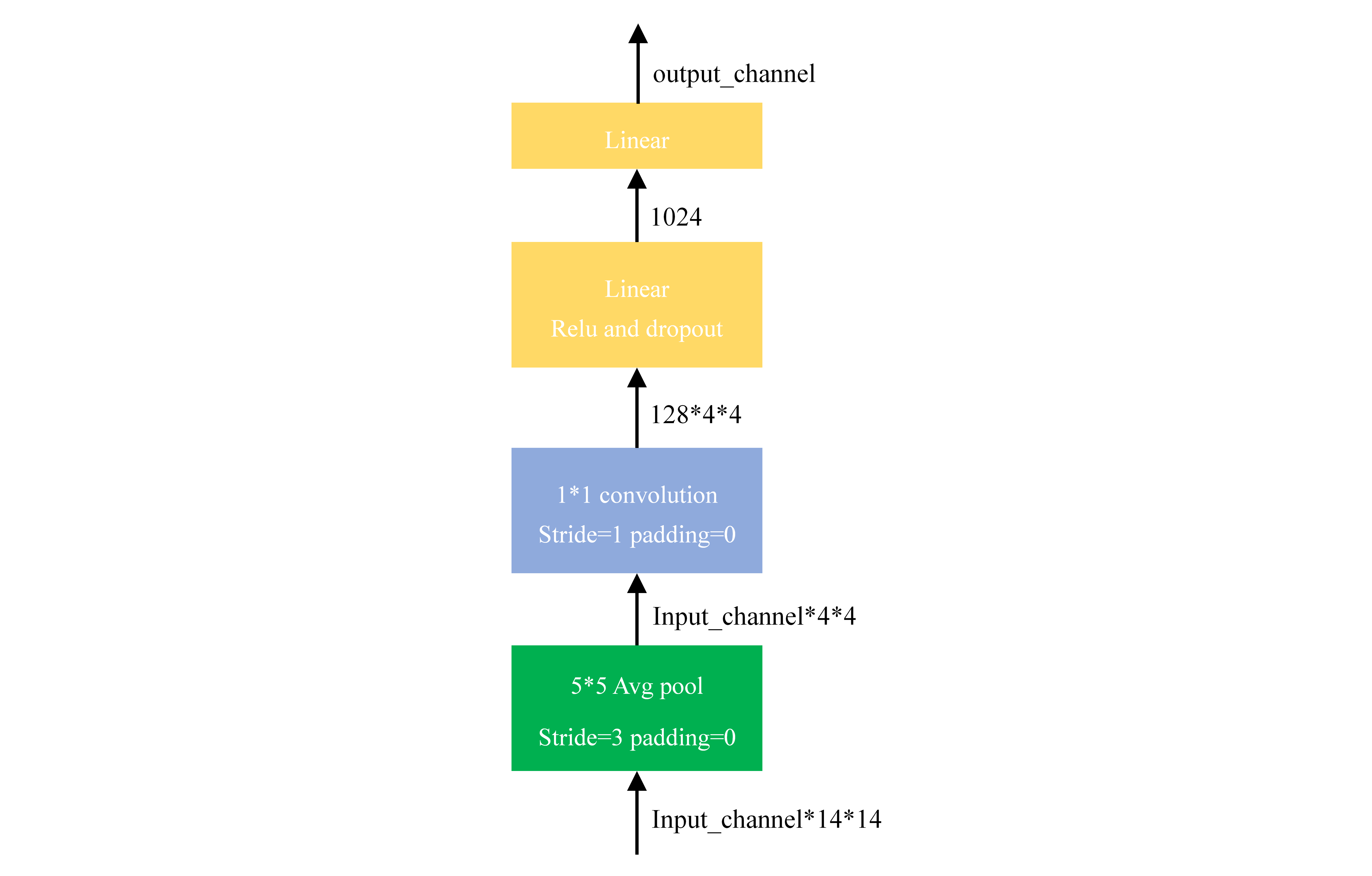
# 全连接模块
class InceptionAux(nn.Module):
def __init__(self, in_channels,out_channels):
super(InceptionAux, self).__init__()
# 5*5平均池化
self.auxiliary_avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
# 1*1卷积模块
self.auxiliary_conv1 = ConvBNReLU(in_channels=in_channels, out_channels=128, kernel_size=1)
# 全连接1 + 激活 + dropout
self.auxiliary_linear1 = nn.Linear(in_features=128 * 4 * 4, out_features=1024)
self.auxiliary_relu = nn.ReLU6(inplace=True)
self.auxiliary_dropout = nn.Dropout(p=0.7)
# 全连接2
self.auxiliary_linear2 = nn.Linear(in_features=1024, out_features=out_channels)
def forward(self, x):
x = self.auxiliary_conv1(self.auxiliary_avgpool(x))
x = x.view(x.size(0), -1)
x= self.auxiliary_relu(self.auxiliary_linear1(x))
out = self.auxiliary_linear2(self.auxiliary_dropout(x))
return out
GoogLeNet模型
GoogLeNet实际上就是多个InceptionV1模块和全连接模块的组合,其模型框架图如下图所示。
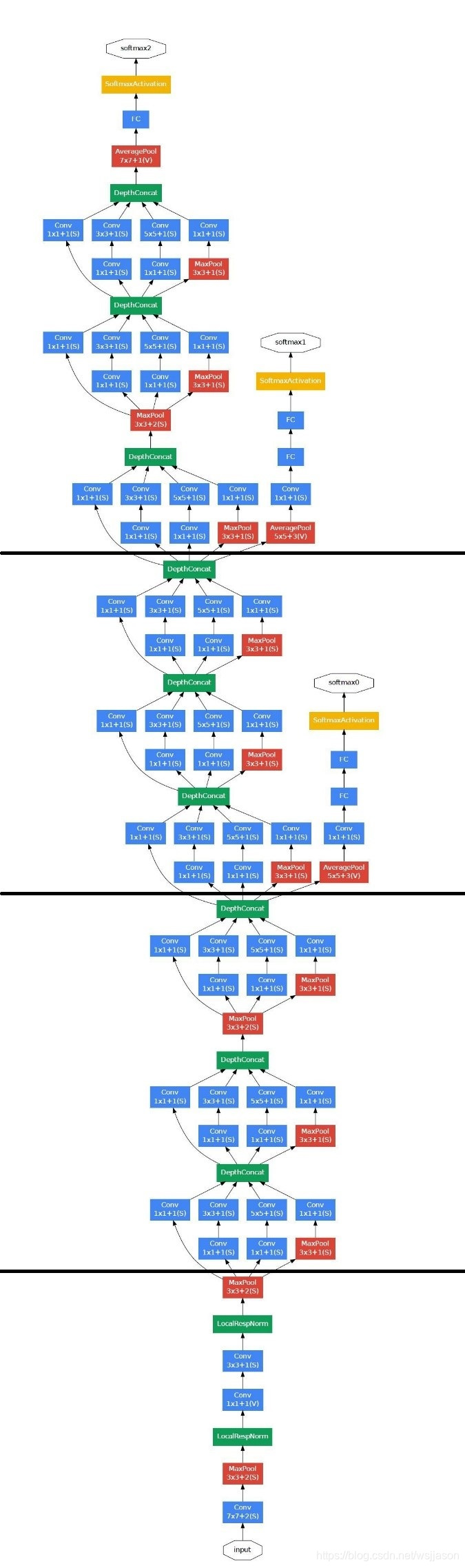
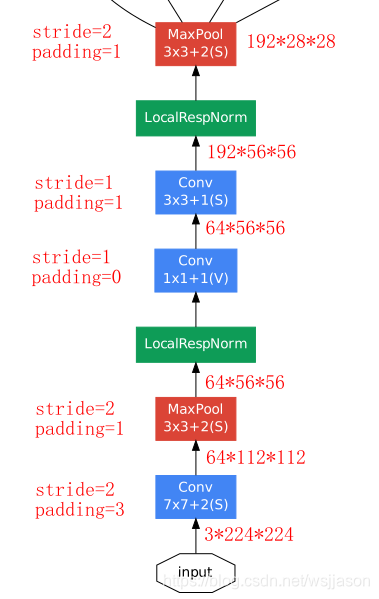
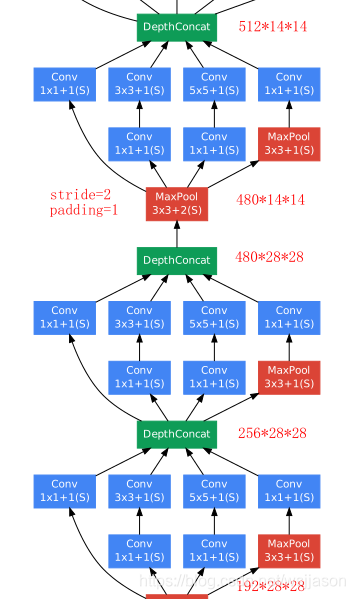
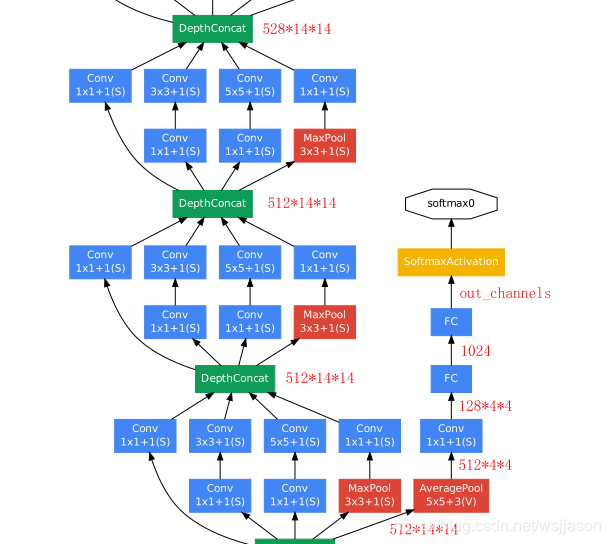
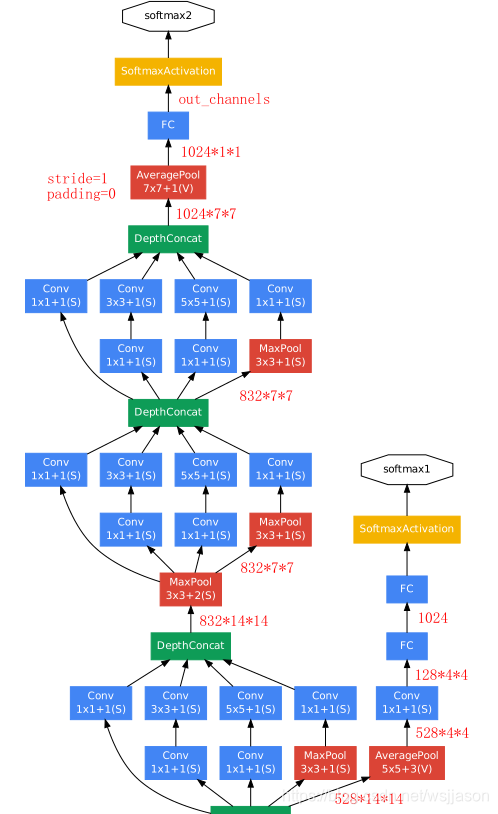
GoogLeNet模型的源码如下:
# GoogLeNet模型
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, stage='train'):
super(InceptionV1, self).__init__()
self.stage = stage
# 子模块1:一系列卷积池化操作
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3,stride=2, padding=1),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, stride=1),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(192),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
# 子模块2:三个InceptionV1模块
self.block2 = nn.Sequential(
InceptionV1Module(in_channels=192,out_channels1=64, out_channels2reduce=96, out_channels2=128,
out_channels3reduce = 16, out_channels3=32, out_channels4=32),
InceptionV1Module(in_channels=256, out_channels1=128, out_channels2reduce=128, out_channels2=192,
out_channels3reduce=32, out_channels3=96, out_channels4=64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
InceptionV1Module(in_channels=480, out_channels1=192, out_channels2reduce=96, out_channels2=208,
out_channels3reduce=16, out_channels3=48, out_channels4=64)
)
# 子模块3:三个InceptionV1模块 + 一个全连接模块
if self.stage == 'train':
self.aux_logits1 = InceptionAux(in_channels=512,out_channels=num_classes)
self.block3 = nn.Sequential(
InceptionV1Module(in_channels=512, out_channels1=160, out_channels2reduce=112, out_channels2=224,
out_channels3reduce=24, out_channels3=64, out_channels4=64),
InceptionV1Module(in_channels=512, out_channels1=128, out_channels2reduce=128, out_channels2=256,
out_channels3reduce=24, out_channels3=64, out_channels4=64),
InceptionV1Module(in_channels=512, out_channels1=112, out_channels2reduce=144, out_channels2=288,
out_channels3reduce=32, out_channels3=64, out_channels4=64),
)
# 子模块4:三个InceptionV1模块 + 两个全连接模块
if self.stage == 'train':
self.aux_logits2 = InceptionAux(in_channels=528,out_channels=num_classes)
self.block4 = nn.Sequential(
InceptionV1Module(in_channels=528, out_channels1=256, out_channels2reduce=160, out_channels2=320,
out_channels3reduce=32, out_channels3=128, out_channels4=128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
InceptionV1Module(in_channels=832, out_channels1=256, out_channels2reduce=160, out_channels2=320,
out_channels3reduce=32, out_channels3=128, out_channels4=128),
InceptionV1Module(in_channels=832, out_channels1=384, out_channels2reduce=192, out_channels2=384,
out_channels3reduce=48, out_channels3=128, out_channels4=128),
)
self.block4_1 = nn.Sequential(
nn.AvgPool2d(kernel_size=7,stride=1),
nn.Dropout(p=0.4),
nn.Linear(in_features=1024,out_features=num_classes)
)
def forward(self, x):
x = self.block1(x)
aux1 = x = self.block2(x)
aux2 = x = self.block3(x)
x = self.block4(x)
out = self.block4_1(x)
if self.stage == 'train':
aux1 = self.aux_logits1(aux1)
aux2 = self.aux_logits2(aux2)
return aux1, aux2, out
else:
return out
完整源码
InceptionV1模型(GoogLeNet模型)的完整代码如下:
import torch
import torch.nn as nn
import torchvision
# InceptionV1的卷积模块:卷积 + 批标准化 + 激活
def ConvBNReLU(in_channels,out_channels,kernel_size):
return nn.Sequential(
# 卷积核的stride=1, padding=kernel_size//2
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=1,padding=kernel_size//2),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
# InceptionV1模块
class InceptionV1Module(nn.Module):
def __init__(self, inchannel, outchannel1, outchannel2_1, outchannel2_2, outchannel3_1, outchannel3_2, outchannel4):
super(InceptionV1Module, self).__init__()
# 1*1卷积模块
self.block1 = ConvBNRelu(inchannel, outchannel1, 1)
# 1*1卷积模块 + 3*3卷积模块
self.block2_1 = ConvBNRelu(inchannel, outchannel2_1, 1)
self.block2_2 = ConvBNRelu(outchannel2_1, outchannel2_2, 3)
# 1*1卷积模块 + 5*5卷积模块
self.block3_1 = ConvBNRelu(inchannel, outchannel3_1, 1)
self.block3_2 = ConvBNRelu(outchannel3_1, outchannel3_2, 5)
# 3*3池化模块 + 1*1卷积模块
self.block4_1 = nn.MaxPool2d(kernel_size = 3, stride = 1, padding = 1)
self.block4_2 = ConvBNRelu(inchannel, outchannel4, 1)
def forward(self, x):
x1 = self.block1(x) # output1
x2 = self.block2_1(x)
x2 = self.block2_2(x2) # output2
x3 = self.block3_1(x)
x3 = self.block3_2(x3) # output3
x4 = self.block4_1(x)
x4 = self.block4_2(x4) # output4
x = torch.cat([x1, x2, x3, x4], dim=1) # 四个模块的输出叠加
return x
# 全连接模块
class InceptionAux(nn.Module):
def __init__(self, in_channels,out_channels):
super(InceptionAux, self).__init__()
# 5*5平均池化
self.auxiliary_avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
# 1*1卷积模块
self.auxiliary_conv1 = ConvBNReLU(in_channels=in_channels, out_channels=128, kernel_size=1)
# 全连接1 + 激活 + dropout
self.auxiliary_linear1 = nn.Linear(in_features=128 * 4 * 4, out_features=1024)
self.auxiliary_relu = nn.ReLU6(inplace=True)
self.auxiliary_dropout = nn.Dropout(p=0.7)
# 全连接2
self.auxiliary_linear2 = nn.Linear(in_features=1024, out_features=out_channels)
def forward(self, x):
x = self.auxiliary_conv1(self.auxiliary_avgpool(x))
x = x.view(x.size(0), -1)
x= self.auxiliary_relu(self.auxiliary_linear1(x))
out = self.auxiliary_linear2(self.auxiliary_dropout(x))
return out
# GoogLeNet模型
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, stage='train'):
super(InceptionV1, self).__init__()
self.stage = stage
# 子模块1:一系列卷积池化操作
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3,stride=2, padding=1),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, stride=1),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(192),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
# 子模块2:三个InceptionV1模块
self.block2 = nn.Sequential(
InceptionV1Module(in_channels=192,out_channels1=64, out_channels2reduce=96, out_channels2=128,
out_channels3reduce = 16, out_channels3=32, out_channels4=32),
InceptionV1Module(in_channels=256, out_channels1=128, out_channels2reduce=128, out_channels2=192,
out_channels3reduce=32, out_channels3=96, out_channels4=64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
InceptionV1Module(in_channels=480, out_channels1=192, out_channels2reduce=96, out_channels2=208,
out_channels3reduce=16, out_channels3=48, out_channels4=64)
)
# 子模块3:三个InceptionV1模块 + 一个全连接模块
if self.stage == 'train':
self.aux_logits1 = InceptionAux(in_channels=512,out_channels=num_classes)
self.block3 = nn.Sequential(
InceptionV1Module(in_channels=512, out_channels1=160, out_channels2reduce=112, out_channels2=224,
out_channels3reduce=24, out_channels3=64, out_channels4=64),
InceptionV1Module(in_channels=512, out_channels1=128, out_channels2reduce=128, out_channels2=256,
out_channels3reduce=24, out_channels3=64, out_channels4=64),
InceptionV1Module(in_channels=512, out_channels1=112, out_channels2reduce=144, out_channels2=288,
out_channels3reduce=32, out_channels3=64, out_channels4=64),
)
# 子模块4:三个InceptionV1模块 + 两个全连接模块
if self.stage == 'train':
self.aux_logits2 = InceptionAux(in_channels=528,out_channels=num_classes)
self.block4 = nn.Sequential(
InceptionV1Module(in_channels=528, out_channels1=256, out_channels2reduce=160, out_channels2=320,
out_channels3reduce=32, out_channels3=128, out_channels4=128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
InceptionV1Module(in_channels=832, out_channels1=256, out_channels2reduce=160, out_channels2=320,
out_channels3reduce=32, out_channels3=128, out_channels4=128),
InceptionV1Module(in_channels=832, out_channels1=384, out_channels2reduce=192, out_channels2=384,
out_channels3reduce=48, out_channels3=128, out_channels4=128),
)
self.block4_1 = nn.Sequential(
nn.AvgPool2d(kernel_size=7,stride=1),
nn.Dropout(p=0.4),
nn.Linear(in_features=1024,out_features=num_classes)
)
def forward(self, x):
x = self.block1(x)
aux1 = x = self.block2(x)
aux2 = x = self.block3(x)
x = self.block4(x)
out = self.block4_1(x)
if self.stage == 'train':
aux1 = self.aux_logits1(aux1)
aux2 = self.aux_logits2(aux2)
return aux1, aux2, out
else:
return out

















 2685
2685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









