







在Mysql中,按数据结构来区分,可以分为Hash和B+树。B树和B+树两者中很重要的一个区别就是:B+树只有叶子节点存放数据,其余的节点,都只用来存放索引,而B树则是每个索引节点都会有Data。
其次,当数据量较大的时候,由于B树的非叶子节点,只存储索引,因此它能存储的数据就更多。因为众所周知,判断查询效率最重要的一个原因就是对磁盘IO的次数,次数越多,效率越低,反之则越高。因此,利用B+树作为索引的数据结构,有利于减少对磁盘的IO次数,从而增加查找效率。
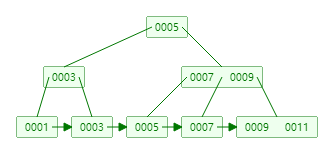
如图所示,利用B+树作为索引,还有一个优点,即所有的叶子节点都是相连的(双向)。因此,只要对叶子节点进行遍历,就可以查找出所有所需的数据。无需如同b树那样,找到某个索引值后,还需要找到它的父节点,然后接着找下一个数据。
所以其实结合这些b+树的特点,也有利于理解为什么索引在如【%XXX】【不遵循最左原则】等情况下会失效。
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
可以利用这个网址,自己构建b+树来帮助理解
综上所述,可以总结出使用B+树的几个优点:
- b+树的数据都只在叶子节点中,非叶子节点只有索引
- b+树的层高相比b树更小,IO次数更低,效率更高
- 数据只放在叶子节点中,命中索引即命中数据
- 叶子节点都是按顺序放置的,而且为双向链表,更有利于范围查询















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









