







原文知乎地址:https://zhuanlan.zhihu.com/p/60919662,主要看1.1 点的映射
由于本系列主讲目标检测,所以对于这篇文章我们主要讲解SPP-net在目标检测上的应用。在目标检测的问题上,SPP-net主要是在R-CNN的基础上进行改进的,但是它仍旧继承了R-CNN的多阶段的处理过程(图1):
- Extract region proposal,使用selective search的方法提取2000个候选区域
- Compute CNN features,使用CNN网络提取feature map
- Classify regions,将提取到的feature输入到SVM中进行分类
- Non-maximum suppression,用于去除掉重复的box
- Bounding box regression,位置精修,使用回归器精细修正候选框的位置
但它同时也指出了R-CNN存在的一些不足之处:
- R-CNN对于每个region proposal都重复的使用CNN提取特征,这是非常消耗时间的,使得特征提取成为测试时的一个时间瓶颈
- 对于不同size的region proposal的feature map,都需要resize到固定大小才能输入到FC layer或SVM分类器,resize会导致图片形变,影响最终的结果
图1 SPP-net结构
因此,SPP-net对R-CNN做了改进来解决这些问题,如图1所示,将原来R-CNN中红色框的区域改成了蓝色框的区域,这样改动主要解决了两方面的问题:
- 直接一整张图输入CNN网络,提取整个图片的特征,然后再根据region proposal的位置来在整个feature map上截取出对应的feature就好啦,这样就避免了重复性用CNN对每个region proposal单独提取特征。
- 第二点就是在原来的CNN网络的conv5层后加入了SPP layer,这样就可以不需要warp region proposal了,因为SPP layer可以接受不同size的输入,并可以得到相同尺寸的输出。
接下来,我们就针对这两方面详细探究SPP-net是怎么操作的。
1. 特征提取(Extract Feature)
我们知道在SPP-net中,一整张图输入CNN网络中,然后经过5个卷积层得到整个图的feature map,然后我们需要从这整个feature map上截取出每个region proposal对应的feature,例如图2中,如何在feature map中得到原图中蓝色的region对应的feature呢?我们知道一般要定位一个矩形框,只要知道中心点的坐标和矩形框的宽高就可以啦。所以我们需要根据原图中的region proposal推导出对应的feature map的中心点和宽高就行了。这就需要我们找到卷积网络中两个卷积层之间的映射关系:包括边的映射和点的映射。
图2 特征提取
1.1 边的映射

1.2 点的映射
(1)有规律的网络:对于有规律的网络,像VGG16,统一使用(3, 3)的卷积核和(2, 2)的池化尺度,这样就使得特征图的尺寸成倍的减少,那么feature map之间的映射关系就是简单的倍数关系,例如在conv5层中中心点的坐标为(2, 2), 那么在conv4中对应点的坐标就是(4, 4)。
(2)无规律的网络:那对于无规律的网络来说,这种映射关系就不是简单的倍数关系了,但是也是有规律可循的,只是比较难理解,我看好多博客里都是直接给公式,没有推到过程,虽然我也没有推导出来,我只能尽力帮大家理解公式,哈哈哈!好了,先上公式:
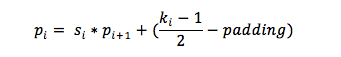

因此,按照上边的公式找到边和点的映射关系就可以推出原图的region proposal在feature map中的位置。
因此,按照上边的公式找到边和点的映射关系就可以推出原图的region proposal在feature map中的位置。
2. SPP Layer
2.1 Why we need SPP?
众所周知,我们训练CNN时需要输入固定size的图像,这主要是受CNN中的全连接层所限制。因为卷积层计算的方式类似于滑窗,因此对于不同size的输入,卷积层都可以正确计算。但是对于连接数固定的全连接层,例如4096*1000,那么这个全连接层的输入必须是4096维,否则就会出现错误。因此在训练CNN之前都需要先把图片resize到一个固定的尺寸,常见的resize方法有两种,如图6所示:
图6 crop和warp
- crop:这种方法就是从原图中裁剪出固定大小的图片,这样的方式会使得部分图像的信息丢失。
- warp:这种方法就是直接将图片resize到规定的大小,这样会导致图片发生形变。
可以看出,固定输入图片的size会导致诸多问题。那么怎样才能设计出一个不需要固定size的CNN网络呢?答案就是使用SPP,空间金字塔。
在目标检测中,这点尤其重要,因为我们会通过selective search来提取出不同size的region proposal,然后对不同的region proposal提取出不同尺寸的feature map, 那这些feature map也要经过warp之后才输入之后的FC layer或SVM分类器,那这样或多或少会影响最后的检测结果。因此加入SPP层会改善结果。
2.2 How does it work?
为了使得CNN可以接受多尺度输入,我们把SPP(Spatial Pyramid Pooling)层加到FC layer之前即可。如下图所示,第一行是原来的CNN网络,需要crop/warp输入图片;第二行是加了SPP层的CNN网络,可以接受任何size的输入。
图7 网络结构
所以,如果我们在R-CNN的conv5层之后加入SPP layer,那对于不同size的region proposal的feature map就不需要再进行warp了,直接可以进行分类了。如图所示,不同size的feature map经过SPP后都变成固定长度的。
图8 SPP Layer
具体来说就是把输入的feature map划分成不同尺度的,比如图中(4, 4) (2, 2) (1, 1)三种不同的尺度,然后会产生不同的bin,比如分成(4, 4)就16个bin,然后在每个bin中使用max pooling,然后就变成固定长度为16的向量。例如下图9和图10中不同尺寸的输入,经过SPP层之后都得到了相同的长度的向量,之后再输入FC layer就可以啦。
图9 一种尺寸输入
图10 另一种尺寸输入
所以,使用SPP Layer之后,不同size的输入就可以输出相同的size。 (注:在文中实际使用的是4层金字塔,就包括(1*1, 2*2, 3*3, 6*6),总共包括50个bin)。
总结
本文主要讲解了SPP net在目标检测应用上的两个创新点,改进之后的运行速度变快了,准确度也提高了,但仍然存在一些不足之处:
- 整个过程还是multi-stage pipeline,还是需要额外保存feature map以供输入SVM进行分类,因此空间的消耗也还是很大。
- 在fine-tune的时候SPP-net不像R-CNN一样,Spp-net不会更新spatial pyramid pooling layer之前的conv layer,所以这就限制了准确性。















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









