







2021
IBM’s POWER10 Processor 服务器
特性概述
- 提升20%性能和30%core 吞吐量(相对于power9)
- 优化矩阵运算
- 1TB/s的跨系统存储集群带宽
- 模块化die,支持1920同步线程
- 硬件安全
- 为AI优化的机器指令
- 18亿晶体管,602mm2(Power8:8个晶体管10亿个晶体管),三星7nm工艺
- 芯片中心的300mm2中包含共16个核心,每个核心支持8个同步线程,带有2MB二级缓存和8MB三级缓存
- 最多15个核心同时工作,1个核心备用,因此有120个核心和120MB的三缓
- 外围面积是系统互联
- L3的布局布线上方有大量通信线,通过优化的布局布线实现计算、带宽平衡
- 芯片具有单芯模式和双芯模式,单芯模式适合大规模互联、高性能场景,可以实现16芯互联;双芯模式为计算密度和IO密度优化,最大支持8核
- 系统互联方式:OMI(内存接口)、PowerAXON interface(核与OpenCAPI)
POWER10 CORE
- 相对于9,吞吐量提高30%,功耗下降一半

- 指令从L2预取后,先在predecode中进行fusion和prefix,再进入L1
- 每周期下发8指令/16指令(SMT8双芯模式下)
- 执行单元扩展到128b,提高了SIMD能力
- 在执行单元中引入了矩阵运算加速器MMA,带有8个512bit加速寄存器,具有向量-标量寄存器,每个输入向量标量寄存器包含2x1个双精度向量、4x1个单精度向量、4x2的16位矩阵(半精度浮点、bfloat16或有符号整数),4x4的8位矩阵(有符号/无符号整数),或4x8的4位矩阵(有符号)整数)
- MMA相对于SIMD,将数据存储于本地,提高了能效和频率
- power10使用了更多的时钟门控、减少数据交换、指令融合等方式提高能量效率

评价
- Power10最值得关注的点:在执行级引入了Vector的概念,相对于SIMD可以降低数据交换量;但Power10还是基于SIMD的
- 指令预处理技术或许可以参考,但是和指令集有关
Marvell ThunderX3: Next-Generation Arm-Based Server Processor 服务器
特性概述
- 服务器芯片
- ARM指令集,TSMC 7nm工艺
- 目标是降低TCO
- 60核心,每个具有4个线程;八个64bit位宽的DDR4通道;64条PCIe通道
- 片上功耗传感与控制系统
CORE
- 深度乱序四线程核心

- 每周期取八条指令,在指令cache中使用way prediction简化设计、降低功耗
- 条件分支、间接分支和返回有单独的预测结构
- 支持解耦取指,在数据中心型的应用中获得1.5x-2x的增益
- 解耦取指:分支预测(生成取值的地址)和指令缓存访问不应该紧密耦合,从而当指令取值阶段由于Icache发生miss或者back-pressure(不确定)而停止时,分支预测器可以提前运行并生成之后的取值地址。利用这些地址可以进行不同的优化,例如指令预取,并且可以隐藏跳转分支会产生的流水线空泡。
- BP能够在不访问I-cache的情况下跟踪(follow)发生跳转的分支。即需要一个BTB结构,能够提供分支跳转的目标地址。
- 解耦的BP在遇到I-cache未命中或者其它长延迟事件时,会将生成的取值地址放入一个解耦的队列中
- 解耦BP和Fetcher的优点:
- 提前执行BP和BTB得到的取值地址可以用于提供更加精确的指令预取器
- 在某些实现中,由于高频率的设计,如果BP预测分支跳转,则需要在流水线中插入一个或者多个空泡(在BTB命中的情况下也需要),来计算得到分支跳转的目标地址。通过解耦和BP和fetcher,分支地址可以被提前计算得到,从而掩盖一些空泡
- 解耦BP和Fetcher的缺点:
- 需要一个更大的BTB结构,以获取预测跳转的分支的目标地址。如果使用解耦结构进行指令预取,此时BTB的覆盖范围需要比I-cache更大,即需要更大的BTB结构
- 解耦会增加流水线深度(预测的时间更长了)。因此在解耦结构中,取值PC需要首先通过BP,然后在传递给I-cache。在耦合结构中,两者并行发生。这种情况下,分支预测错误代价也会增加
- 流水线深度的增加也会发生在BTB发生缺失的关键路径上,这种情况下,在相关目标地址被译码/计算得到后,译码(或者之后的)阶段需要重新引导BP
- 多级预测resteer降低性能损失
- decoder级优化微操作,对常用操作避免产生多组微操作
- decoder有指令融合的能力
- 前后端间有一个滑动(skid)buffer
- 何时用到skid buffer呢?前面我们也提到模块级流水所有模块的ready都是来自receiver,所以若是中间模块太多或者receiver中ready的逻辑太长,都会造成ready的Timing紧张,这时就需要对Ready也打拍。但是对Ready也打拍后就会出现,后级想停下(拉低ready)但传给前级会慢一拍,这样前级就多握一次手,多向后传一个数据,但后级已经停下了,所以就在本级做一个深度为1的缓冲将其存下来,等后级再启动时先把它传过去即可,这样就避免了由于ready打拍造成数据丢失。
//----------------------Version 8: skid buffer-----------------------------
assign DataOut = DataInRdy ? data_out[0] : data_out[1] ;
assign DataOutVld = DataInRdy ? data_out_vld[0] : data_out_vld[1];
always @( posedge Clk or negedge Rstn )
begin
if( ~Rstn )
DataInRdy <= 'h0;
else if( Clear )
DataInRdy <= 'h0;
else
DataInRdy <= DataOutRdy;
end
always @( posedge Clk or negedge Rstn )
begin
if( ~Rstn )
data_out <= 'h0;
else if( Clear )
data_out <= 'h0;
else
begin
if( DataInVld && DataInRdy )
data_out[0] <= DataIn;
if( ~DataOutRdy && DataInRdy )//skid-buffer
data_out[1] <= DataIn;
end
end
always @( posedge Clk or negedge Rstn )
begin
if( ~Rstn )
data_out_vld <= 'h0;
else if( Clear )
data_out_vld <= 'h0;
else
begin
if( DataOutRdy )
data_out_vld[0] <= DataInVld;
if( DataOutRdy && data_out_vld[1] )//skid-buffer
data_out_vld[1] <= 'h0;
else if( ~DataOutRdy && DataInRdy )//skid-buffer
data_out_vld[1] <= data_out_vld[0];
end
end
//------------------------------------------------------------------------------------
- 70-entry unified issue
- 性能:单核SPECInt比X2高30%,SPECFp高35%。收益来源分析:


- 其他技术:多线程优化、soc设计等,略
总结
- 最大特点:分支预测器的解耦概念
The Xbox Series X System Architecture 高性能
使用AVX256指令,每个时钟周期的峰值为32个单精度浮点运算,或8个CPU内核的峰值为972 GFLOPS
Manticore: A 4096-Core RISC-V Chiplet Architecture for Ultraefficient Floating-Point Computing 服务器
特性概述
- 为dataparallel FP workloads优化

@ Globalfoundries 22FDX, - 小的顺序、32位、整数risc-v核(Ariane RV64GC),带大的FPU,带SSRs和floating-point repetition指令扩展

- 4x32计算集群,四个Ariane RV64GC核,HBM控制器,27MB L2,16xPCIe
- 内存系统:分层结构,通过burst-based的DMA连接。四个clusters共享指令cache。cluster间互联带宽高达64TB/s。分层结构向上带宽逐渐缩减,有利于物理实现

- 每个计算集群内为8个22kGE,单级32位RISCV核,每个核带有一个双精度FPU,每周期可以计算一个DP FMA。8个核具有128KiB的紧耦合共享暂存。还有一个512bit位宽的DMA负责将数据传入暂存。
- 44%的计算面积,44%的L1,仅12%的控制面积,优秀的计算/控制资源比例
- 支持消除显式LD/ST指令的SSRs(Stream Semantic Registers)扩展和实现FPU-Only hardware loop的frep(Floating-Point Repetition)扩展
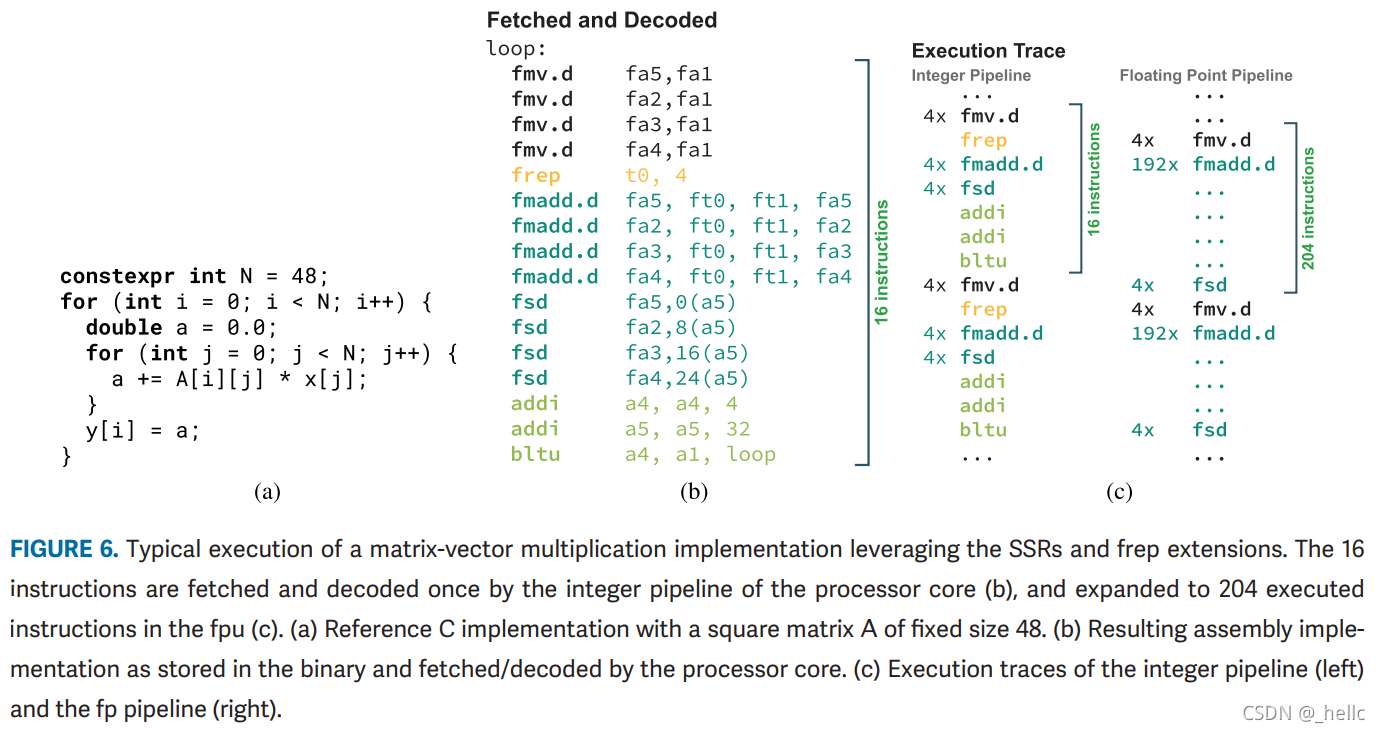
总结
- 核+cluster,cluster内还有核的架构,为高密度计算设计
- 引入SSRs、frep指令,提高数据和指令访问效率
※※Klessydra-T: Designing Vector Coprocessors for Multithreaded Edge-Computing Cores 边缘
概述
- 交错多线程(Interleaved multi-threading,IMT)处理器核心追求边缘计算的能效和低硬件成本,它们需要硬件加速方案来运行繁重的计算负载。本文采用矢量方法加速计算,探索了在RISC-V内核中实现矢量协处理单元的可能方案,展示了IMT和负载的数据级并行性之间的协同作用。
- Interleaved multi-threading,或 barrel-processing,which is a simple and widely known program execution paradigm that alternates instructions belonging to different execution threads in the stages of a single-issue in-order processor pipeline. In this scheme, while the throughput is limited to one instruction per cycle (IPC), pipeline stalls due to interinstruction dependence are avoided without any hardware overhead for dependence management. As long as the application workload can be programmed as multiple threads, the IMT approach can sustain IPC=1 with relatively high clock frequency and high energy efficiency, thanks to the hardware simplicity, which is a desirable goal in embedded edge-computing processors.这是一种简单的、广为人知的程序执行范式,它在单发顺序处理器流水线的各个阶段交替使用属于不同执行线程的指令。在这个方案中,虽然吞吐量被限制在每周期一条指令(IPC),但由于指令间的依赖性而导致的流水线停滞是可以避免的,而且没有任何硬件开销用于依赖性管理。只要应用工作负载可以被编程为多个线程,IMT方法就可以在相对较高的时钟频率和高能效的情况下维持IPC=1,这要归功于硬件的简单性,这是嵌入式边缘计算处理器的一个理想目标。)
- 边缘计算场景下的vector协处理器,需求:
- 支持2-D卷积
- FFT
- 矩阵乘
- 成果:
- 不同计算内核之间的定量比较
- TLP和DLP间的优化平衡
- IMT方法与其他方法的比较
- RISCV指令集的硬件潜力
Architecture
-
基础:
- RV32IMA+数学向量扩展
- 单周期完成线程上下文切换
- 顺序单发射
- 前向流水线,不支持硬件分支冒险和数据冒险处理
- bare metal execution (RISCV M mode)

-
Core交错了三个硬件线程(hart a\b\c)
-
寄存器、PC和CSR在每个hart间复制(IMT/FMT——Fine-Grained MultiThreading)
-
执行单元包括LSU、标量执行单元(EXEC)、基于向量的多用途单元(MFU)
-
LSU执行store时与其他单元同时工作,不会造成写回(write back)冲突
-
MFU可以读取寄存器,但是只允许写入本地暂存(SPMs)
-
LSU通过专用指令管理数据在Data Memory和SPMs之间的读写
-
MFU执行矢量运算,如果一个hart访问正在忙的MFU时,其会执行“self-referencing jump”直到MFU空闲,避免其他线程不必要的stalls

-
不依赖矢量寄存器,而是基于本地SPM上映射的内存空间;程序员可在SPM地址空间内任意移动数据。

、 -
MFU中的lanes数量D、MFU数量F、SPM容量、SPMs数量N、SPMIs数量M、the sharing scheme of MFUs, and SPMI among harts可配置
-
MFU支持类半字SIMD风格的8、16、32b整型,and also in element-SIMD fashion when D is configured to multiply the execution lanes for DLP
-
访问SPM的典型初始延迟为4-8cycle
-
每个SPM有1读1写端口,lanes数量D也对应SPM banks。所有bank在一个SPM line中访问,即FMU执行一个向量操作时,其每一周期取出整个SPM line的数据。bank rotator提供数据读写对齐能力。LSU通过32bit接口向SPM内填充数据,填充时由一个数据选择器选择bank。
-
通过配置,支持不同模式的在线程间共享:
- Shared coprocessor: 协处理器指令和非协处理器指令之间可以同步运行
- Thread-dedicated coprocessors: 每个hart分配一个完整的MFU/SPM子系统,允许多个矢量指令并行执行
- Thread-dedicated SPMI/shared MFU: 每个hart有专有SPM空间,但共享一个MFU,实现同时执行使用不同MFU功能的协处理器指令。

结果





总结
- 支持交错多线程的RISCV,结合向量扩展,可以实现良好的加速效果
- 仔细设计vector扩展的资源,以适应目标需求和资源约束
2020
Compute Solution for Tesla’s Full Self-Driving Computer 高性能
特性概述
- SoC,集成CPU、ISP、GPU
- 为神经网络提供72TOPs的加速能力
- 包含控制ISP和、GPU与视频编码功能的CPU组
- TDP小于40w
- 完整系统为双芯工作,两个FSD芯片
- FSD芯片面积260um2,2.5亿晶体管,14nm工艺,BGA封装

- 包含A72 CPUs,G71 GPUs,ISPs,以及两个自研的神经网络加速器(NNA),每个NNA包含32MB SRAM,96*96MAC,在2GHz下达到36TOPs
- 典型流程:图像处理器接受新的帧——预处理——存入DRAM——CPU指示NNA处理图像——NNA控制器本地SRAM——结果返回DRAM并产生中断;GPU用于处理NNA不支持的算法

The AMD “Zen 2” Processor 高性能
概述
- 微架构变化包括:
- TAGE分支预测器
- double-size op cache
- double-width floating-point unit
- 支持chiplet扩展至64核
CORE

- 通过工艺和微架构的改进,提高了能源效率
- 通过in-order front-end, integer execute, floating-point/vector execute, load/store, and cache hierarchy提高了约15%15 IPC
如何提高能量效率
- 改进分支预测准确性
- 改进op cache命中率
- continuous clock and data gating
安全性
略
取指
- 顺序前端+fetch+decode
- 分支预测为两级结构,L分支预测改为tagged geometric history length (TAGE) predictor。TAGE的单位容量预测精度更高,但是由于需要多路复用器来读取多个表的数据,因此延迟变长。L1使用perceptron预测器。
- L0 BTB:8→16
- L1 BTB:256→512
- L2 BTB:4096→7168
- indirect target array:512→1024
- 以上提升使zen2的预测错误率降低了30%
- op cache:2048→4096
- L1 Icache:64kB→32kB
- L1 Icache从四路关联变为8路关联
- op cache加入了更多指令融合cases
整数执行单元
- 分布式执行引擎
- 整数和浮点具有独立调度器、寄存器、执行单元,整数操作使用通用寄存器,浮点/向量操作使用向量寄存器
- 有2 load和1 store/cycle的能力,有三个地址生成单元(AGU)
- 有四个独立的ALU调度队列,每个队列有16个条目。AGU调度器为一个有28个条目的队列
- 物理寄存器(PRF):168→180
- ROB:192→224
- 新的执行引擎可以识别并行度更高的线程,将资源向其倾斜,以暴露更多程序并行性
浮点/向量执行单元
- 数据位宽128→256b
- 支持AVX256
LOAD/STORE AND L1D/L2 CACHE
- store queue size:44→48
- L2 data translation lookaside buffer:1536→2048
- 支持将1GB pages分割为2MB pages
- 32kB 8-wayL1D
- 512kB 8-way L2@latency=12cycle
CCX、L3、SoC
略
总结
分析AMD对分支预测的取舍以及各种分支预测资源的变化,有助于理解资源的作用和优化方法
BlackParrot: An Agile Open-Source RISC-V Multicore for Accelerator SoCs 边缘/平台
概述
- 开源、支持linux、cache-coherent的64bit多核RISCV
- tiny、模块化、友好
- 已在GF 12nm下tapeout
- 有文档、设计平台、社区等的支持,包含完善的代码审查、模块划分、PPA优化
- 实现了IMAFD指令集,支持三个特权等级和虚拟内存,足以运行操作系统

- 功能:
- 中断控制器
- coherent-cache
- 易于集成的加速器接口
- BlackParrot implements a distributed directory-based cache coherence protocol, which currently supports VI, MSI, and MESI.
- 互联、内存、加速器接口等:略
core

- 前端:顺序+分支预测
- 前后端做了解耦,允许前端在后端有大延迟操作时继续预取
- Because the RISC-V virtual memory scheme may modify architectural state during
instruction fetch [setting the “Access (A) bit”], all TLB misses in the front end are sent to the back end to be handled inline with other exceptions. - Along with the PC/instruction/exception pair, the front end also sends metadata associated with the branch prediction that resulted in that particular PC fetch.
- 从后端到前端的消息包括分支结果、中断重定向、iTLB操作、特权模式更改。

总结
提出了一个多核、易于扩展的riscv平台,设计时就考虑了模块化,为协加速器提供了接口,且经过了流片验证;细节需要配合文档仔细研究。
2019
Samsung M3 Processor 边缘
概述
- 为智能手机设计
- 6 wide 微架构
- 深度乱序资源
- fabricated in Samsung 10LPP
- 优化目标:优先提高IPC,保持频率不变,允许面积增加
CORE

- ARM-v8
- 64KB L1
- 6发射,实际可以达到11的峰值(4个ALU、1个分支、2个负载、1个存储和3个浮点/矢量)
- 动态分支预测
- 积极的数据预取策略
前端
- M1分支预测器和指令缓存的微架构是考虑到三类应用:适合微型分支目标缓冲器(BTB)的小内核,适合主BTB的中等规模的应用,以及从L2 BTB获得高覆盖的大型应用。微型和主BTB的神经网分支预测器的设计受到早期基于感知器的分支预测器工作的启发。
- 使用分层的方法可以在容量、延迟、带宽和功率之间进行权衡。
- 占用空间较小的内核可以在微型BTB中以低延迟、高带宽和低FE功率运行。在M3上,微型BTB的容量增加了一倍,达到128个条目,以涵盖一些稍大的内核。
- 通过增加本地历史长度,将权重表的容量增加一倍,以及调整置信机制,提高了微BTB条件分支预判器的准确性。
- M3微型BTB包括一个循环预测器和一个返回地址栈。
- 主BTB为中等规模的应用保存4K分支预测记录。通过一些微架构的优化,主BTB预测分支的延迟被降低。存储记录的优化允许增加每周期预测2个分支的机会,这与微型BTB的操作类似。
- 通过将权重表的容量增加一倍,用动态范围换取减少混叠,以及调整用于选择神经网络权重的时间间隔,主分支预测器的准确性得到了提高。
- M3的主BTB还包括一个64入口的返回栈。
- 为了更好地优化大尺寸的应用,L2BTB和指令TLB的大小增加了一倍,从L2缓存中获取指令的带宽也增加到32字节/周期。4路关联64KB指令高速缓存的获取管道通过一个地址队列与分支预测管道解耦。从FE到解码器的指令缓存带宽增加了一倍,达到每周期48字节,以支持更强大的机器。
- 预测器的变化使每1000条指令的分支错误预测率减少了15%(MPKI)。在4800个跟踪中,总体错误预测率从3.92MPKI减少到3.29MPKI。分支预测器准确性的提高有助于更好地利用更大的失序窗口,以及弥补为建立一个更宽的机器而增加的管道阶段。
DECODE, RENAME, AND DISPATCH
6发射+微码生成+ROB
整数调度与执行
- 4ALU(+1)+1branch+3AGU(+1)+1Store,调度126个ops(x2),PRF为192 entries@64bit(x2)
- Retire包含228个ops的ROB(+128)
FPU
- FPU处理浮点和SIMD
- 3op/cycle
- 62 entries(x2)
- 192下28bit vector PRF
- 所有单元均可处理128bit数据
- 浮点乘单元在浮点乘加单元内部,延迟比乘加小1cycle
- 每周期可以计算24SP/12DP
- 浮点divider采用radix64算法,可以达到6bit/cycle的速度,比radix4快了3x

LSU
- 将scheduler深度和Store Buffer翻倍,让乱序能力提高了一倍
- data cache容量从32KB/8-way变为64KB/8-way,在不增加负载延迟的情况下改善了有效数据延迟
- TLB 层次结构升级,虽然第一级32-entry dTLB 的延时太长,无法增加,但增加了新的中级 512-entry TLB,统一(指令和数据)L2 TLB 的增加了四倍,达到 4K。这些改进允许许多更大的应用程序适合核心TLB。
流水线

缓存结构

BROOM: An Open-Source Out-of-Order Processor With Resilient Low-Voltage Operation in 28-nm CMOS
概述
- 基于开源的BOOM乱序core
- 28nm@TSMC HPM,1.0GHz@0.9v,最低0.47v
- 基于chisel


2018
The Celerity Open-Source 511-Core RISC-V Tiered Accelerator Fabric: Fast Architectures and Design Methodologies for Fast Chips
概述
- 提出一种快速设计CPU的平台,最大限度缩短开发时间
- 由具有开源 Linux 能力的 RISC-V 核心组成通用层
- 由可缩放到任意大小的 RISC-V 多核阵列和使用HLS创建算法神经网络加速器的专业化层组成大规模并行层
- 这些层由一个高效的异构远程存储器编程模型绑在一起,灵活的分配在全局存储器地址空间上

2017
THE ARM SCALABLE VECTOR EXTENSION
- SVE允许选择128-2048bit的向量寄存器
- 支持未知长度向量编程
- 主要解决之前ARM SIMD指令不适应目前的多变的适量长度、需要gather/scatter、pre-lane预测、长向量等的问题
IBM POWER9 PROCESSOR ARCHITECTURE 服务器
概述
- 14nm,80亿晶体管,单芯支持24核,每内核支持4个硬件线程

INSIDE 6TH-GENERATION INTEL CORE: NEW MICROARCHITECTURE CODE-NAMED SKYLAKE 高性能
概述
重点强调了其功耗管理、内存子系统等

2016
Practical Multidimensional Branch Prediction
waiting














 3836
3836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









