







目录
一、AutoEncoder原理
自编码器(Autoencoder)是一种神经网络结构,由编码器(Encoder)和解码器(Decoder)两部分组成。编码器将输入数据映射到低维编码空间,而解码器将编码空间的表示映射回原始输入数据的空间,训练目标是最小化重构数据与原始输入数据之间的差异。
这样的网络结构下,编码器的输出则是在信息损失量最小的前提下、输入数据的低纬度表示。因此,自编码器可用于降维场景,而降维算法可以先进行降维、再重构数据,难以重构/重构误差较大的样本即位和整体分布差异较大的样本点,从而达到异常检测的目的。
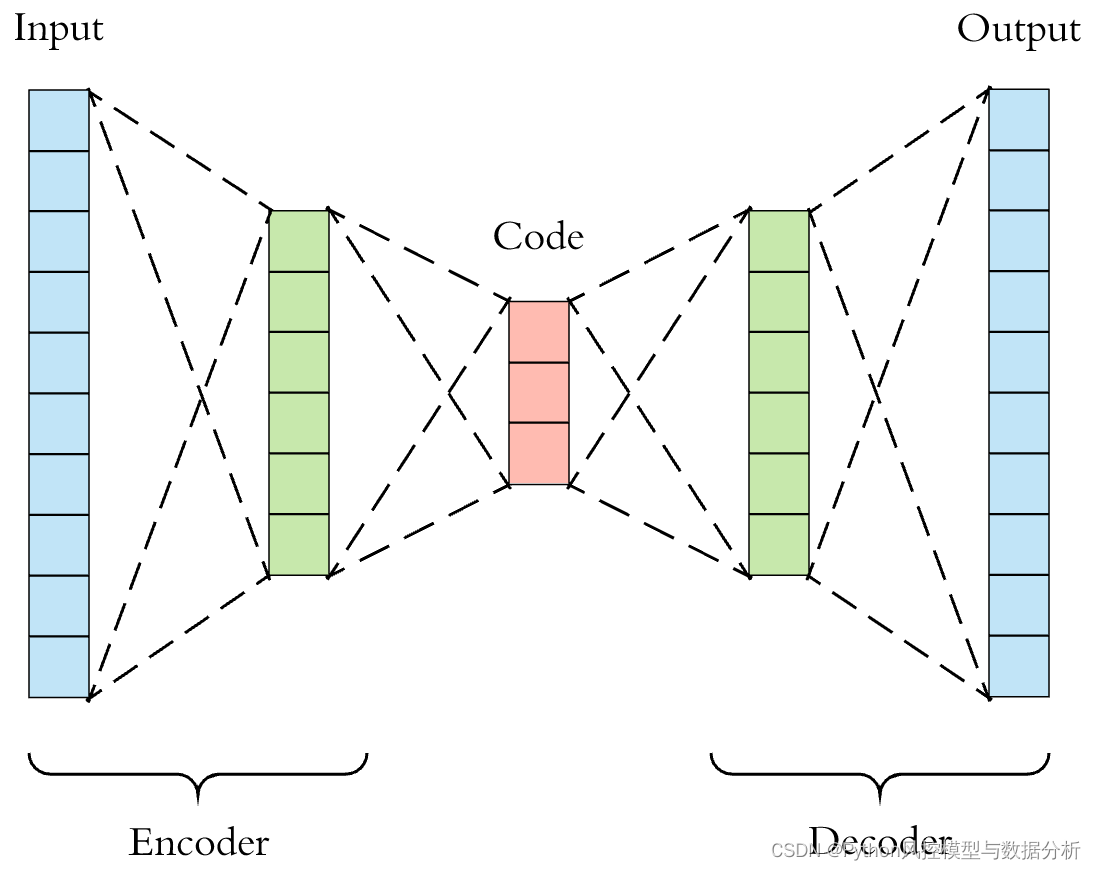
上图是自编码器的一般结构:
-
编码器(Encoder):编码器将输入数据转换为低维的编码表示。它由一系列的隐藏层组成,每个隐藏层通过非线性变换将输入数据映射到更低维的空间中。最终隐藏层的输出即为编码器的编码(latent code)。
-
解码器(Decoder):解码器将编码器的编码重构为与输入数据尺寸相同的输出。它与编码器的结构相似,但是是反向的过程。解码器接收编码器的编码作为输入,通过反向的非线性变换逐步恢复数据的维度,最终输出重构的数据。
-
损失函数(Loss Function):自编码器的目标是最小化重构数据与原始输入数据之间的差异。常用的损失函数是均方误差(Mean Squared Error),即最小化重构数据与原始输入数据之间的平方差。
除一般结构之外,自编码器还有不同的变体和扩展,以适应不同的任务和数据类型。常见的变体包括稀疏自编码器(Sparse Autoencoder)、卷积自编码器(Convolutional Autoencoder)、变分自编码器(Variational Autoencoder)等等。
二、信用卡退款欺诈行为检测实战
由于暂时并没有其他合适的数据,所以用上一篇文章的信用卡退款欺诈数据来介绍Autoencoder的应用,也欢迎大家提供其他合适的数据集、共同为知识分享贡献力量。
1、数据介绍
使用信用卡退款欺诈行为检测数据,具体来源记不住了。样本量11127条,包括卡号、退款操作时间、金额、以及是否欺诈的标签CBK,这里我们还是通过无监督的方式来识别欺诈退款,然后用欺诈标签评估模型效果、并用于调整特征和模型。

2、欺诈数据分析及特征衍生
(1)时间特征衍生
数据结构比较简单,而整个数据的时间窗口都在2015-05一个月内,所以我们先从Date字段提取出周、日、时、分、秒等时间字段,考虑到周内、周末信用卡操作频次可能存在差异,所以也提取出weekday(周几)。另外CBK也映射为0-1值,便于后续处理。

(2)欺诈行为分析及分组特征衍生
在很多场景里,聚集便意味着风险,这里我们也可以分组进行分析。数据集中提供了信用卡卡号,对于一个退款的欺诈用户而言,如果成功退款了一次,那么他一定会连续尝试、多次退款,所以可以查看一下是否存在短时间内频繁退款的情况。
如下图所示,存在部分信用卡在一个月内产生频繁退款的行为,结合欺诈标签进行分析,可以看到欺诈行为大多频繁退款的行为均存在异常。

从微观角度来看,退款频数top1的信用卡在半小时内发起了20次退款,每隔1-2分钟发起一笔,且退款金额为固定值250,看起来很像是程序控制的随机时间间隔来发起退款行为。

再来看退款频次top2的信用卡,与上图情况相似,不同的是退款金额间隔几次会存在一定变化。

另外,我们也可以发现部分高频退款行为的欺诈标签为0,与前面欺诈行为的区别在于退款金额不存在规律性。不过由于发生高频退款行为、而标签为未欺诈的数据较少(即从数据标签来看,高频退款的基本均为欺诈行为),这里为了方便不再额外去衍生高频退款行为下、金额规律性的特征,有兴趣的朋友可以尝试一下能否进一步提高识别欺诈的能力。

根据上述欺诈行为分析,高频退款便可能存在着风险,这里简单衍生出按照信用卡分组的月度退款频数、天退款频数、hour退款频数等特征。
3、特征分布分析及特征筛选
首先,分别从天、周数、小时来进行特征分布分析。如下图所示,从1-30日内每隔几天就会有低频退款的day,即存在不规则的周期波动性,所以结合图二当天所在周几来看,周六日的退款频数明显低于周内,尤其是周末,而低频则意味着风险,所以day、weekday特征均保留。
同理,hour特征分布来看,在凌晨1-7点的睡眠时间段之间交易频数偏低,且在这段时间发起退款行为难免让人疑惑,因此hour特征也保留入模。



与上面不同,分钟数、秒数特征几乎没有什么规律可言,每分钟的退款频次几乎相近,对于欺诈识别没有什么贡献,因此剔除分钟数、秒数特征。

最后再来看信用卡对应的退款频数特征,基本符合长尾分布,月度退款次数达多集中在2次以内、高频退款行为还是比较少的,根据其分布结合前文的欺诈分析,这部分特征可以极大地增强模型的欺诈异常识别能力


4、数据归一化处理
在使用PCA降维、重构之前先将数据进行归一化,避免因为量纲、数据量级的不统一
df2_copy2=df2_copy.copy()
scaler = MinMaxScaler()
fea_list=['Amount', 'day','hour', 'weekday','refund_cnt','refund_cnt_day','refund_cnt_day_hour']
df2_copy2[fea_list]=scaler.fit_transform(df2_copy[fea_list])5、自行构建AutoEncoder
def get_autoencode_model(input_size,X_train,X_test):
x = layers.Input(shape=(input_size,))
encode = Dense(int(input_size), activation='relu')(x)
encode = layers.Dropout(rate=0.3,seed=1)(encode)
encode = Dense(int(input_size/2), activation='relu')(encode)
encode = layers.Dropout(rate=0.3,seed=1)(encode)
decode = Dense(int(input_size/2), activation='relu')(encode)
decode = layers.Dropout(rate=0.3,seed=1)(decode)
decode = Dense(int(input_size), activation='relu')(decode)
decode = layers.Dropout(rate=0.3,seed=1)(decode)
decode = Dense(input_size)(decode)
autoencoder = Model(inputs=x, outputs=decode)
autoencoder.compile(optimizer='adam', loss='mae',metrics=['mae'])
history = autoencoder.fit(
X_train, X_train,
epochs=40,
batch_size=100,
shuffle=True,
validation_data=(X_test, X_test),
verbose=1
).history
return autoencoder,history
autoencoder,history=get_autoencode_model(
len(fea_list), # 7个变量
df2_copy2[df2_copy2['sample']=='train'][fea_list],
df2_copy2[df2_copy2['sample']=='test'][fea_list]
)
autoencoder.summary()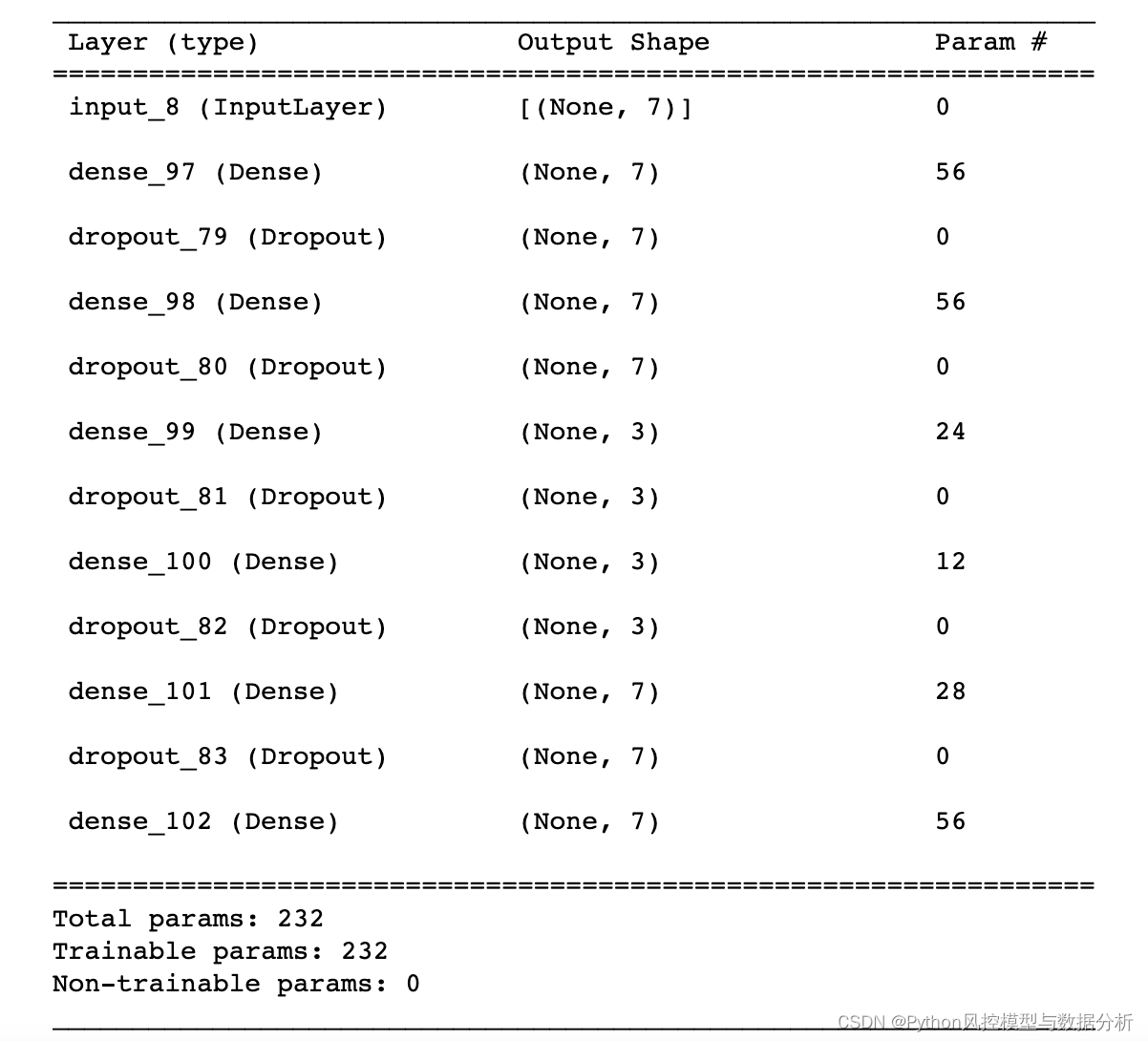
autoencoder_pred = autoencoder.predict(df2_copy2[fea_list])
df2_copy2['mae_autoencode']= np.mean(np.abs(df2_copy2[fea_list] - autoencoder_pred), axis=1)
ks_auc_value(df2_copy2[df2_copy2['sample']=='train'].CBK,df2_copy2[df2_copy2['sample']=='train'].mae_autoencode)
'''
output (0.5379112885150795, 0.8398380303495523)
'''
ks_auc_value(df2_copy2[df2_copy2['sample']=='test'].CBK,df2_copy2[df2_copy2['sample']=='test'].mae_autoencode)
'''
output (0.5474963939831032, 0.8504636307438699)
'''
6、调用pyod的AutoEncoder
调用赵越大佬pyod包(专用于异常检测),用参数hidden_neurons控制网络层数和每层的神经元数量,可以更加便捷地调整网络结构。
from pyod.models.auto_encoder import AutoEncoder
clf_name = 'AutoEncoder'
clf = AutoEncoder(epochs=50,hidden_neurons=[7,3,3,7], contamination=0.05)
clf.fit(df2_copy2[df2_copy2['sample']=='train'][fea_list])
y_train_pred = clf.labels_
y_train_scores = clf.decision_scores_
y_test_pred = clf.predict(df2_copy2[df2_copy2['sample']=='test'][fea_list])
y_test_scores = clf.decision_function(df2_copy2[df2_copy2['sample']=='test'][fea_list])
ks_auc_value(df2_copy2[df2_copy2['sample']=='train'].CBK,y_train_scores)
'''
output (0.6890833077462225, 0.8870460555039494)
'''
ks_auc_value(df2_copy2[df2_copy2['sample']=='test'].CBK,y_test_scores)
'''
output (0.6340614053162993, 0.8466062229548732)
'''划重点
关注威心公众号 Python风控模型与数据分析 ,回复 异常检测AutoEncoder实战 获取本文数据、完整代码!还可以获取更多理论知识与代码分享

















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









