







xgb作为常用的集成模型,不仅是当前工业落地最常用的模型之一、而且几乎是风控面试的必考点,从gbdt到xgboost,有一个重要的新增特性就是模型可自行处理缺失值,减少我们在预处理过程中的工作量、不需要再进行缺失填充,极大地简化了我们建模流程。
那么xgb在训练和预测时是如何处理缺失值的呢?

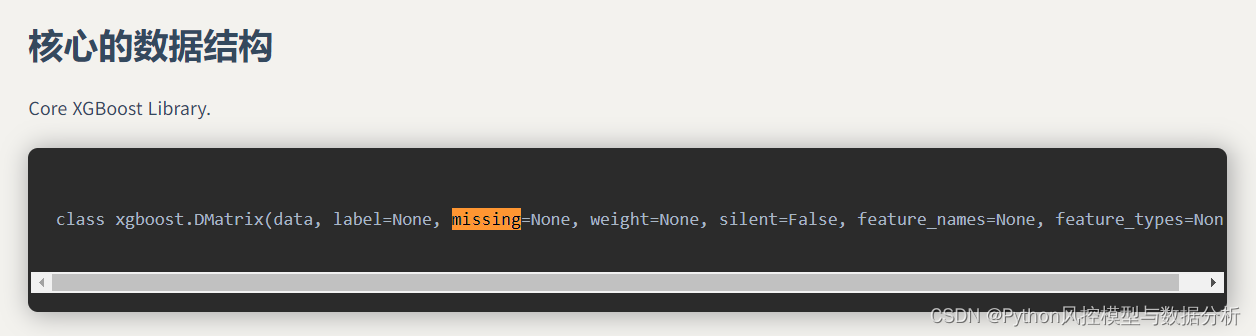
先来看看xgboost数据集初始化或模型初始化接口中的missing参数解释,missing可以指定一个值来表示缺失值,即可以在这个参数位置指定缺失值的填充值,如-1、-999等。
默认值为np.nan(float类型),在使用默认值np.nan时即为保留缺失值不进行填充,此时模型会将缺失值作为一类值进行处理,具体处理包含两种情况、不同的情况处理方式也不同。
原文伪代码

通俗点介绍,其实存在两种情况:
(1)训练时,若特征m存在空值,当树按照特征m分裂时,先不考虑空值、按照m有值的序列选择最优分裂点进行分裂,然后再分别将空值样本带入左子节点和右子节点、计算两侧信息增益,保留整体信息增益较大的分裂方向,预测时空值样本也按照该方向进行分裂;
(2)训练时特征无空值,预测时空值样本默认分裂到左侧子节点(注意:易错点来了,默认方向左侧子节点!默认方向左侧子节点!默认方向左侧子节点!)
如下图所示,在展示xgboost的子树时,每个节点分裂的左侧分支均包含missing的缺失值部分、即默认缺失值分裂到左侧子节点。
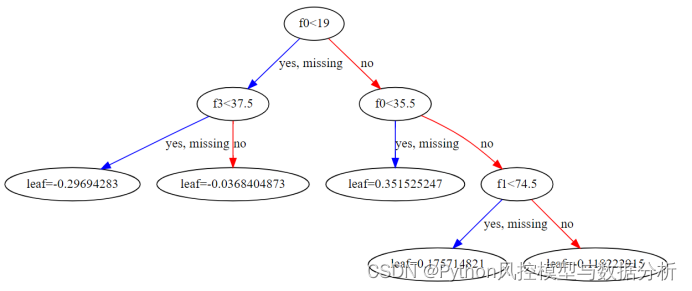
附上xgb子树的可视化demo
1、导包
import re
import os
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
import matplotlib.pyplot as plt
import gc
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import xgboost as xgb
import matplotlib.pyplot as plt2、数据读取
df=pd.read_csv('E:/文件/train.csv')
print(df.shape)
df.head()3、特征缺失值统计查看
def miss_sta_col(df):
'''
输入 df: 评估缺失的数据
输出 缺失分布图
'''
miss_per = df.isnull().sum() / len(df)
plt.figure(dpi=80, figsize=(7, 5))
plt.bar(miss_per.index, miss_per.values * 100)
# 添加数值标签
for a, b in zip(miss_per.index, miss_per.values * 100):
plt.text(a, int(b), int(b), ha='center', va='bottom')
plt.title('Missing %')
plt.ylim((0, 100))
plt.xticks(rotation=30)
plt.show()
df.loc[:,:'fea13'].pipe(miss_sta_col)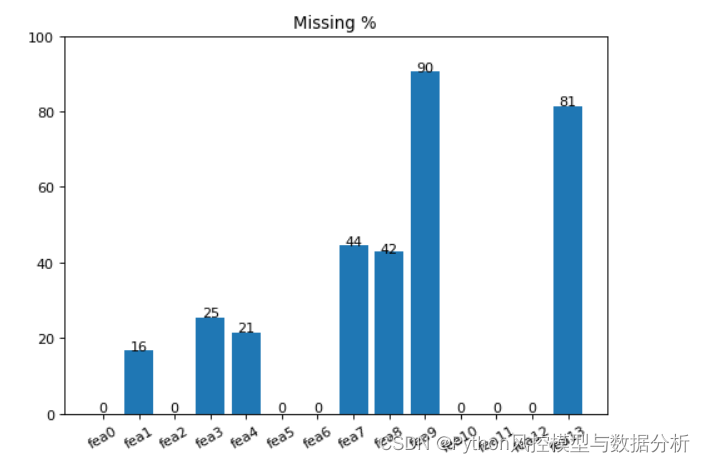
4、设置模型参数
params={
'objective':'binary:logistic'
,'eval_metric':'auc'
,'n_estimators':500
,'eta':0.03
,'max_depth':3
,'min_child_weight':100
,'scale_pos_weight':1
,'gamma':5
,'reg_alpha':10
,'reg_lambda':10
,'subsample':0.7
,'colsample_bytree':0.7
,'seed':123
}5、划分数据集并训练模型
x_train,x_test, y_train, y_test =train_test_split(df.drop(['id','isDefault'],axis=1)[col_list],df['isDefault'],test_size=0.3,random_state=1)
# 转化数据集格式 xgb.DMatrix
dtrain = xgb.DMatrix(train[col_list], label = train['isDefault'])
dtest = xgb.DMatrix(test[col_list], label = test['isDefault'])
model = xgb.train(params=params,
dtrain=dtrain,
# verbose_eval=True,
evals=[(dtrain, "train"), (dtest, "valid")],
# early_stopping_rounds=10,
num_boost_round = 30
)
6、子树可视化
xgb.to_graphviz(xgb_model, num_trees=0, rankdir='UT')















 2859
2859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









