






网络栈位于内核(http://www.ibm.com/developerworks/cn/linux/l-linux-kernel/)中,而产生网络数据的应用程序很多都位于内核之外,客户端与服务器端通过内核网络协议栈实现网络传输,那么应用程序与内核之间数据与套接字是怎么样传输的呢?
套接字传输
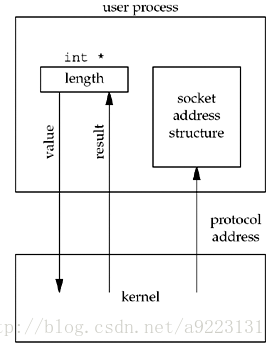
当往一个套接字函数传递一个套接字地址结构时,该结构总是以引用形式来传递,也就是传递的是指向该结构的一个指针。该结构的长度也作为一个参数来传递,不过其传递方式取决于该结构的传递方向:是从进程到内核,还是从内核到进程。
(1)从进程到内核传递套接字地址结构的函数有3个:bind、connect和sendto。这些函数的一个参数是指向某个套接字地址结构的指针,另一个参数是该结构的整数大小,例如:
struct sockaddr_in serv;
/*fill in serv{}/
connect(sockfd,(SA*)&serv,sizeof(serv)); 指针和指针所指内容的大小都传递给了内核,于是内核知道到底需从进程复制多少数据进来。图3-7展示了这个情形。

(2)从内核到进程传递套接字地址结构的函数有4个:accept,recvfrom,getsockname和getpeername。这四个函数的其中两个参数是指向某个套接字地址结构的指针和指向该结构大小的整数变量的指针。例如:
struct sockaddr_un cli; /* Unix domain */
socklen_t len;
len = sizeof(cli); /* len is a value */
getpeername(unixfd, (SA *)&cli, &len);
/* len may have changed */
数据传输

图2-15展示了某个应用进程写数据到一个TCP套接字中时发生的步骤。
每一个TCP套接字有一个发送缓冲区,我们可以使用SO_SNDBUF套接字选项来更改该缓冲区的大小(见7.5节)。当某个应用进程调用write时,内核从该应用进程的缓冲区中复制所有数据到所写套接字的发送缓冲区。如果该套接字的发送缓冲区容不下该应用进程的所有数据(或是应用进程的缓冲区大于套接字的发送缓冲区,或是套接字的发送缓冲区中已有其他数据),该应用进程将被投入睡眠。这里假设该套接字是阻塞的,它是通常的默认设置。(我们将在第16章中阐述非阻塞的套接字。)内核将不从write系统调用返回,直到应用进程缓冲区中的所有数据都复制到套接字发送缓冲区。因此,从写一个TCP套接字的write调用成功返回仅仅表示我们可以重新使用原来的应用进程缓冲区,并不表明对端的TCP或应用进程已接收到数据。(我们将在7.5节随SO_LINGER套接字选项详细讨论这一点。)
这一端的TCP提取套接字发送缓冲区中的数据并把它发送给对端TCP,其过程基于TCP数据传送的所有规则(TCPv1的第19章和第20章)。对端TCP必须确认收到的数据,伴随来自对端的ACK的不断到达,本端TCP至此才能从套接字发送缓冲区中丢弃已确认的数据。TCP必须为已发送的数据保留一个副本,直到它被对端确认为止。
本端TCP以MSS大小的或更小的块把数据传递给IP,同时给每个数据块安上一个TCP首部以构成TCP分节,其中MSS或是由对端通告的值,或是536(若对端未发送一个MSS选项)。(536是IPv4最小重组缓冲区字节数576减去IPv4首部字节数20和TCP首部字节数20的结果。)IP给每个TCP分节安上一个IP首部以构成IP数据报,并按照其目的IP地址查找路由表项以确定外出接口,然后把数据报传递给相应的数据链路。IP可能在把数据报传递给数据链路之前将其分片,不过我们已经谈到MSS选项的目的之一就是试图避免分片,较新的实现还使用了路径MTU发现功能。每个数据链路都有一个输出队列,如果该队列已满,那么新到的分组将被丢弃,并沿协议栈向上返回一个错误:从数据链路到IP,再从IP到TCP。TCP将注意到这个错误,并在以后某个时刻重传相应的分节。应用进程并不知道这种暂时的情况。
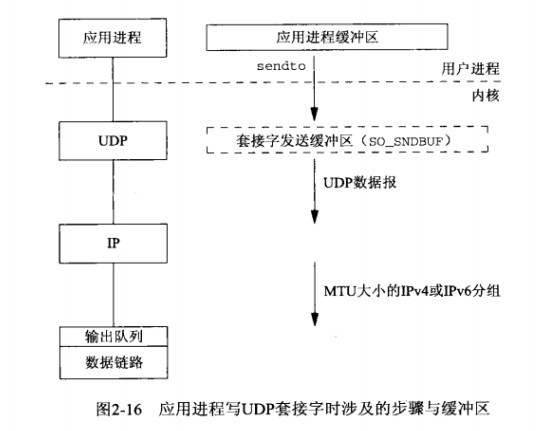
图2-16展示了某个应用进程写数据到一个UDP套接字中时发生的步骤。
这一次我们以虚线框展示套接字发送缓冲区,因为它实际上并不存在。任何UDP套接字都有发送缓冲区大小(我们可以使用SO_SNDBUF套接字选项更改它,见7.5节),不过它仅仅是可写到该套接字的UDP数据报的大小上限。如果一个应用进程写一个大于套接字发送缓冲区大小的数据报,内核将返回该进程一个EMSGSIZE错误。既然UDP是不可靠的,它不必保存应用进程数据的一个副本,因此无需一个真正的发送缓冲区。(应用进程的数据在沿协议栈向下传递时,通常被复制到某种格式的一个内核缓冲区中,然而当该数据被发送之后,这个副本就被数据链路层丢弃了。)
图2-16 应用进程写UDP套接字时涉及的步骤与缓冲区
这一端的UDP简单地给来自用户的数据报安上它的8字节的首部以构成UDP数据报,然后传递给IP。IPv4或IPv6给UDP数据报安上相应的IP首部以构成IP数据报,执行路由操作确定外出接口,然后或者直接把数据报加入数据链路层输出队列(如果适合于MTU),或者分片后再把每个片段加入数据链路层的输出队列。如果某个UDP应用进程发送大数据报(譬如说2000字节的数据报),那么它们相比TCP应用数据更有可能被分片,因为TCP会把应用数据划分成MSS大小的块,而UDP却没有对等的手段。
从写一个UDP套接字的write调用成功返回表示所写的数据报或其所有片段已被加入数据链路层的输出队列。如果该队列没有足够的空间存放该数据报或它的某个片段,内核通常会返回一个ENOBUFS错误给它的应用进程。
不幸的是,有些UDP的实现不返回这种错误,这样甚至数据报未经发送就被丢弃的情况应用进程也不知道。
socket缓冲区与其他协议的关系以及数据流在网络栈中流动的实现,看这里:http://www.ibm.com/developerworks/cn/linux/l-linux-networking-stack/ 网络协议部分。















 2461
2461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









