







DQN

DDQN(Double DQN)
DQN中的q值总是被高估了

DQN中使用一个神经网络Q,计算每一个action的的Q值,选择Q值最大的action加上rt
DDQN中使用两个神经网络Q、Q’,使用Q计算action的Q值,选择Q值最大的action,使用Q’计算被选择action的Q’值。

Dueling DQN
相比于DQN只更改了网络的架构
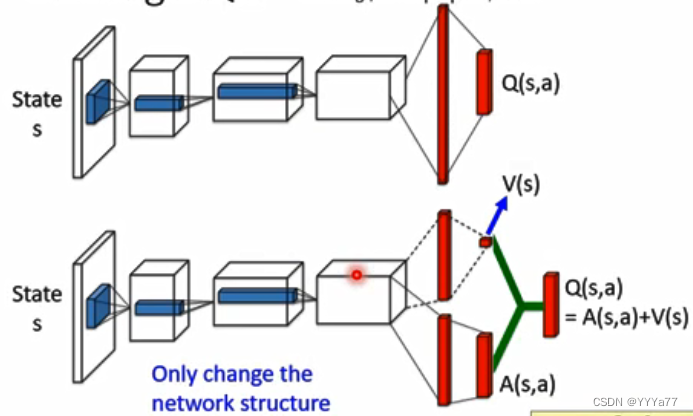
DQN中的Q是直接输出一个Q值
Queling DQN是将输出分为价值函数和动作函数,价值函数输出一个实数,表示对当前局势的价值量,动作函数输出每个动作的价值。
这样的更改后,更新更有效率
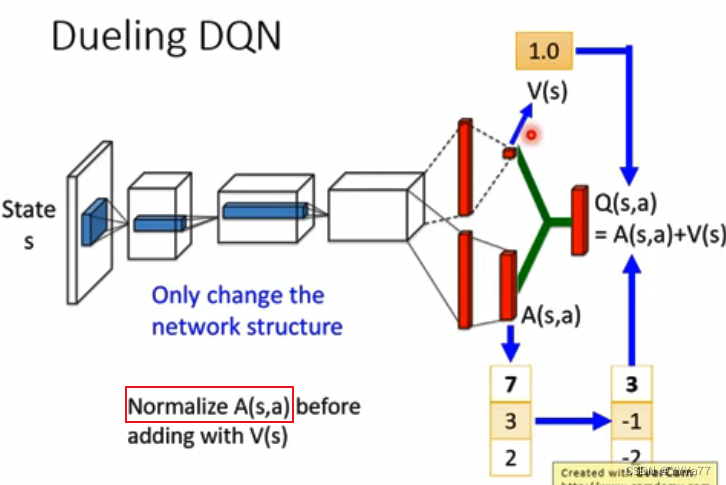
加layer normalization
PER(Prionritized Reply)
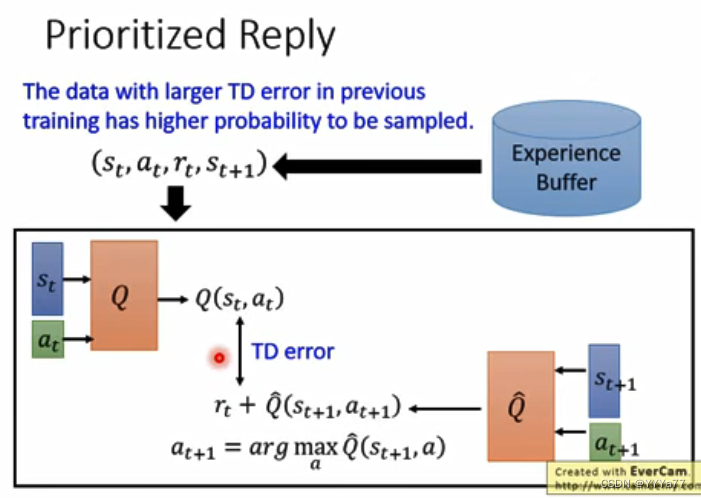
如果有一些data非常好,td error比较大的,代表train的不太好,所以给他比较大的几率被采样到















 4164
4164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









