







学习强化学习总结的笔记,按照自己的理解总结的,还没总结完,边学边总结,可能存在错误欢迎指正
1. Q值和V值
Q值:代表了智能体选择这个动作后,一直到最终状态“奖励总和”的期望;(用于衡量动作)
V值:代表了智能体在“当前状态”下,一直到最终状态的“奖励总和”的期望;(用于衡量状态)
Q值和V值的关系:
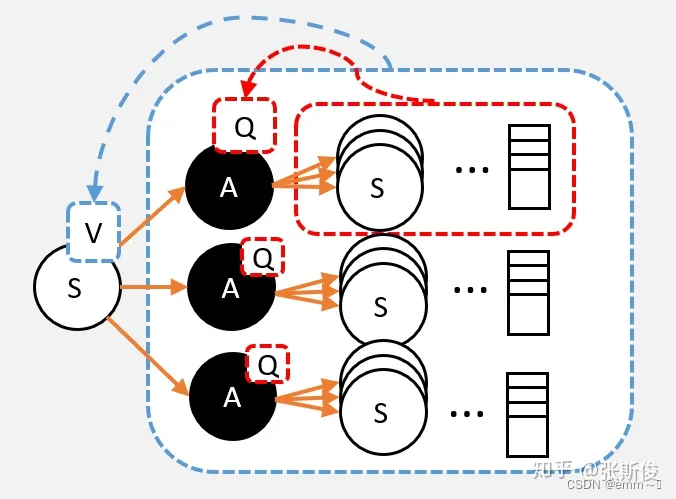
- 基于Q计算V:一个状态的V值,就是这个状态下的所有动作的Q值,在策略下的期望,即 V π ( s ) = ∑ a ∈ A π ( a ∣ s ) ⋅ Q π ( s , a ) V_\pi(s)=\sum_{a\in \mathcal{A}}\pi(a|s)\cdot Q_\pi(s,a) Vπ(s)=∑a∈Aπ(a∣s)⋅Qπ(s,a);

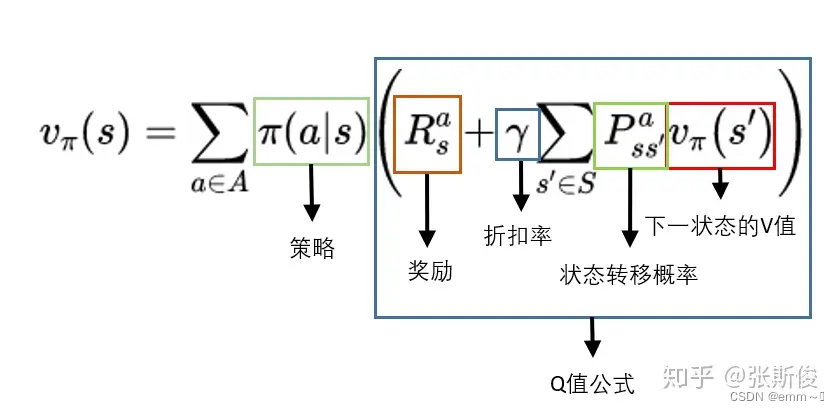
- 基于V计算Q:一个动作的Q值,就是执行这个动作后所有可能状态的V值的均值,即执行动作后,状态的期望。即 Q π ( s , a ) = R s a + γ ∑ s ′ P s s ′ a ⋅ v π ( s ′ ) Q_\pi(s, a)=R_s^a+\gamma \sum_{s'} P_{s s^{\prime}}^a \cdot v_\pi\left(s^{\prime}\right) Qπ(s,a)=Rsa+γ∑s′Pss′a⋅vπ(s′)
- 基于1和2,可以推出V到V的关系为
2. 蒙特卡洛(Monte-Carlo, MC)更新公式求V值
我们把智能体放到环境的任意状态 S \mathbf{S} S;从这个状态开始按照策略进行选择动作,并进入新的状态,并一直重复该步骤直到到达最终状态 S e n d \mathbf{S}_{end} Send,并计算这一个序列的累积奖励,记为G
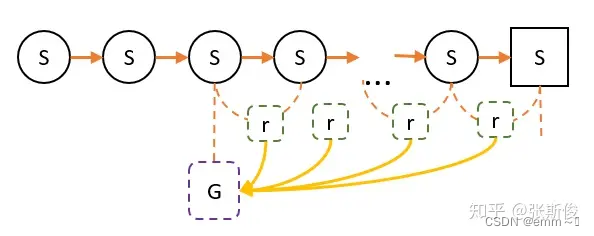
显然可以看出, S → S e n d \mathbf{S}\rightarrow \mathbf{S}_{end} S→Send有很多种情况(或者理解为路线),因此根据V的定义(智能体在“当前状态”下,一直 “走到” 最终状态的 “奖励总和” 的期望), V s V_{\mathbf{s}} Vs可以表示为 V s = E L { G L } = 1 L ∑ l ∈ L G L V_{\mathbf{s}}=\mathbb{E}_{L}\{G_{L}\} = \frac{1}{L}\sum_{l\in L}G_{L} Vs=EL{
GL}=L1∑l∈LGL,L表示总路径的数量(即 S → S e n d \mathbf{S}\rightarrow \mathbf{S}_{end} S→Send有多少种可能性)
基于上面阐述的 V s V_{\mathbf{s}} Vs的表示,若已经尝试了N种路线,且N种路线对应的 { G 1 , G 2 , . . . , G N } \{G_1, G_2,...,G_N\} {
G1,G2,...,GN}的均值为 V s V_{\mathbf{s}} Vs。若又有一种新的路线尝试了,即 G N + 1 G_{N+1} GN+1,则 V s V_{\mathbf{s}} Vs应该更新为:
V s ← V s + G N + 1 − V s N + 1 V_{\mathbf{s}} \leftarrow V_{\mathbf{s}} + \frac{G_{N+1} - V_{\mathbf{s}}}{N+1} Vs←Vs+N+1GN+1−V<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









