







目录
Bach Normalization与Batch_size综合调参
网络构建:
在构建网络中,我们会定义好一些选择哪种激活函数和是否需要进行BatchNorm以及是在激活函数之前进行BatchNorm还是之后进行,其它为正常网络构建过程:
import torch.nn as nn
import torch
class net_class1(nn.Module):
def __init__(self,act_fun=torch.relu,in_features=2,n_hidden=4,out_features=1,bias=True,BN_model=None,momentum=0.1):
super(net_class1, self).__init__()
self.linear1 = nn.Linear(in_features,n_hidden,bias=bias)
self.bn1 = nn.BatchNorm1d(n_hidden,momentum=momentum)
self.linear2 = nn.Linear(n_hidden,out_features,bias=bias)
self.act_fun = act_fun
self.BN_model = BN_model
def forward(self,x):
if self.BN_model == 'pre':
z1 = self.bn1(self.linear1(x))
f1 = self.act_fun(z1)
out = self.linear2(f1)
elif self.BN_model == 'post':
z1 = self.linear1(x)
f1 = self.act_fun(z1)
out = self.linear2(self.bn1(f1))
else:
z1 = self.linear1(x)
f1 = self.act_fun(z1)
out = self.linear2(f1)
return out
""""""无论bn层在隐藏层之前还是之后,对实际结果不会有影响
用写好的fit函数进行模型训练
from MyPython.test.study.MyTorchUtils import MyTorchUtils
"""fit model"""
utils = MyTorchUtils()
torch.manual_seed(420)
# create data
features,labls = utils.tensorDataGenRe(bag=2,w=[2,-1],bias=False)
# split data
train_loader,test_loader = utils.split_loader(features,labls)
# instantiation nn , enter training mode
relu_model1_norm = net_class1(BN_model='pre')
relu_model1_norm.train()
lr = 0.3
utils.fit(net=relu_model1_norm,
criterion=nn.MSELoss(),
optimizer=optim.SGD(relu_model1_norm.parameters(),lr=lr),
batchdata=train_loader,
epochs=20,
cla=False)
print([*relu_model1_norm.modules()][2].weight)
print([*relu_model1_norm.modules()][2].bias)
print([*relu_model1_norm.modules()][2].running_mean)
print([*relu_model1_norm.modules()][2].running_var)
# enter testing mdoe
relu_model1_norm.eval()
print(utils.mse_cla(train_loader, relu_model1_norm))
print(utils.mse_cla(test_loader, relu_model1_norm))
print([*relu_model1_norm.modules()][2].weight)
print([*relu_model1_norm.modules()][2].bias)
print([*relu_model1_norm.modules()][2].running_mean)
print([*relu_model1_norm.modules()][2].running_var)注意的是,单独无脑的加入BN层并不一定会提升模型的效果,这里加入一段对比代码:
def bn_sigmoid():
torch.manual_seed(929)
sigmoid_model1 = net_class1(act_fun=torch.sigmoid)
sigmoid_model_norm = net_class1(act_fun=torch.sigmoid,BN_model='pre')
model_1 = [sigmoid_model1,sigmoid_model_norm]
name_1 = ['simoid_model1','sigmoid_model1_norm']
lr = 0.03
num_epochs = 40
train_1,test_1 = utils.model_comparison(model_1=model_1,
name_1=name_1,
train_data=train_loader,
test_data=test_loader,
num_epochs=num_epochs,
criterion=nn.MSELoss(),
optimizer=optim.SGD,
lr=lr,
cla=False,
eva=utils.mse_cla)
for i,name in enumerate(name_1):
plt.plot(list(range(num_epochs)),train_1[i],label=name)
plt.legend(loc=1)
plt.show()在上面模型中加入bn层,模型效果反而会变差,此时需要和别的参数进行联合调参,结果:
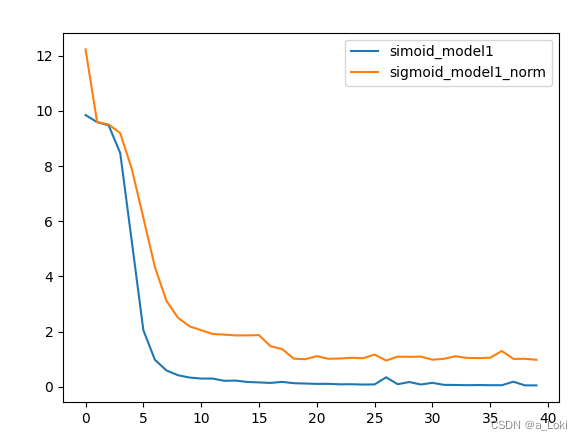
综合调参:
Bach Normalization与Batch_size综合调参
我们首先要明白的一点是,要让模型得到最好的效果其实就是bn层计算出的均值和方差越接近真实的均值和方差,而当面对的数据量(也就是Batch_size)太少的时候,我们用小批数据去估计大的整体就会出现较大的偏差,影响模型准确率。
调大数据数量来对比:
def bn_sigmoid2():
utils = MyTorchUtils()
torch.manual_seed(420)
features,labls = utils.tensorDataGenRe(bag=2,w=[2,-1],bias=False)
train_loader,test_loader = utils.split_loader(features,labls,batch_size=50)
sigmoid_model1 = net_class1(act_fun=torch.sigmoid)
sigmoid_model_norm = net_class1(act_fun=torch.sigmoid,BN_model='pre')
model_1 = [sigmoid_model1,sigmoid_model_norm]
name_1 = ['simoid_model1','sigmoid_model1_norm']
lr = 0.03
num_epochs = 40
train_1, test_1 = utils.model_comparison(model_1=model_1,
name_1=name_1,
train_data=train_loader,
test_data=test_loader,
num_epochs=num_epochs,
criterion=nn.MSELoss(),
optimizer=optim.SGD,
lr=lr,
cla=False,
eva=utils.mse_cla)
for i,name in enumerate(name_1):
plt.plot(list(range(num_epochs)),train_1[i],label=name)
plt.legend(loc=1)
plt.show()
对比上段代码,更改了batch_size,结果如下:
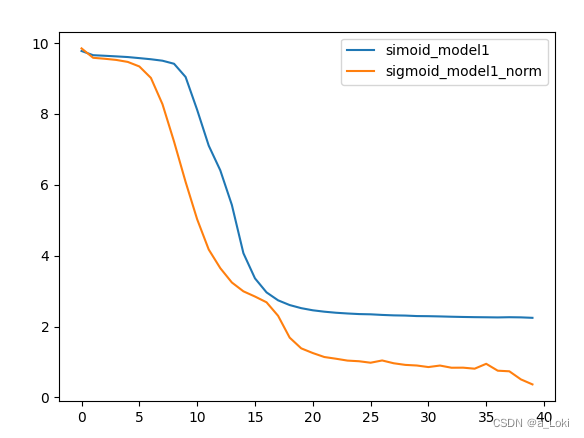
对比可以发现,调整batch_size后,带bn层的有更快的收敛速度和效果
这里相同的原理,除了提高batch_size外,还可以通过降低momentum参数来实现
复杂模型上Batch_normalization的表现
bn主要的优化手段是通过调整线性层的梯度,使整个模型的梯度达到平稳的状态,来获得更好的效果,所以,在一定范围内,bn方法对于复杂模型和复杂数据会更加有效,很多简单模型可以不用(会增加计算量,所以上述中我们的简单模型优化效果可能不是很明显.















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









