






目录
1.使用官方scheduler
- lr_scheduler.LambdaLR
- lr_scheduler.MultiplicativeLR
- lr_scheduler.StepLR
- lr_scheduler.MultiStepLR
- lr_scheduler.ExponentialLR
- lr_scheduler.CosineAnnealingLR
- lr_scheduler.ReduceLROnPlateau
- lr_scheduler.CyclicLR
- lr_scheduler.OneCycleLR
- lr_scheduler.CosineAnnealingWarmRestarts
1.1 lr_scheduler.LambdaLR:
scheduler_1 = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
其中,更新学习率方式是 lr = lr*lr_lambda
lr_lambda可以是用户自定义的规则也可以是lambda表达式:
·lambda表达式: lr_lambda = lambda epoch:0.1
·用户自定义规则:
def rule(epoch):
lamda = math.pow(0.5, int(epoch / 3))
return lamda
1.2 lr_scheduler.MultiplicativeLR:
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
1.3 lr_scheduler.StepLR:
scheduler_2 = torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma, last_epoch=-1)
其中,step_size(int):每训练step_size个epoch,更新一次参数
gamma(float):更新lr的乘法因子
last_epoch (int):最后一个epoch的index
1.4 lr_scheduler.MultiStepLR:
torchscheduler_3 = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
其中,milestones:为一个数组,比如设为[20,30]。如果初始学习率设为0.1,当在第20epoch时为0.01,第30epoch时为0.001。
1.5 lr_scheduler.ExponentialLR:
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma)
按gamma的次方的方法调整。
1.6 lr_scheduler.CosineAnnealingLR:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
其中,参数T-max:指的是cosine 函数 经过多少次更新完成四分之一个周期
1.7 lr_scheduler.ReduceLROnPlateau:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode=‘min’, factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode=‘rel’, cooldown=0, min_lr=0, eps=1e-08)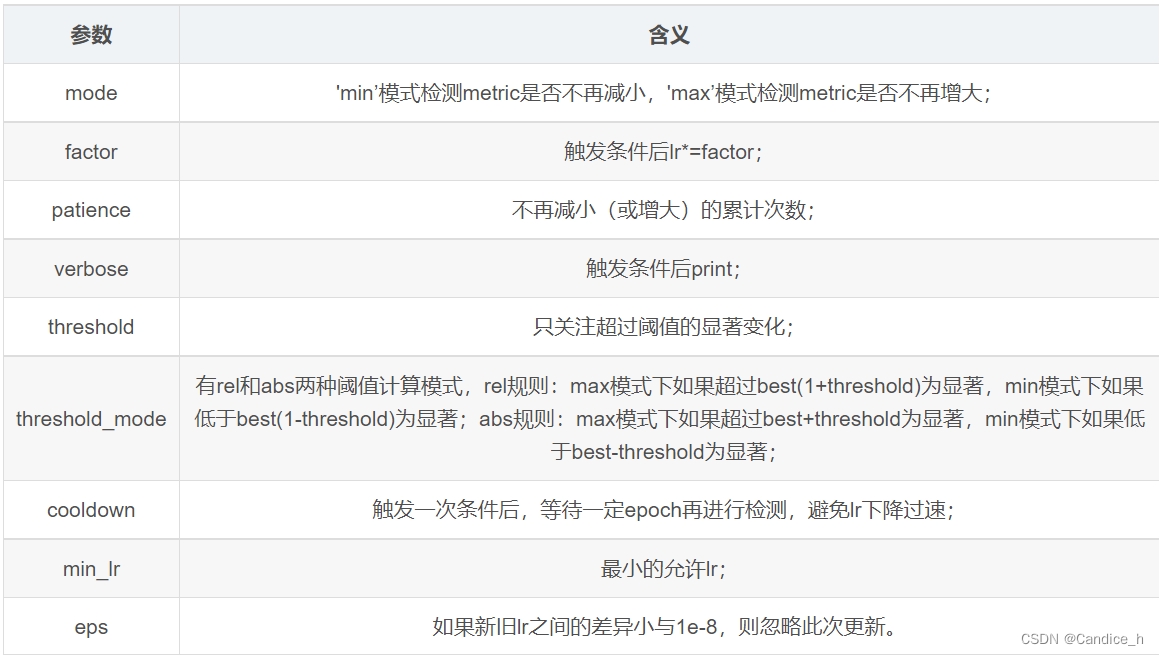
1.8 lr_scheduler.CyclicLR:
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=500, step_size_down=500, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)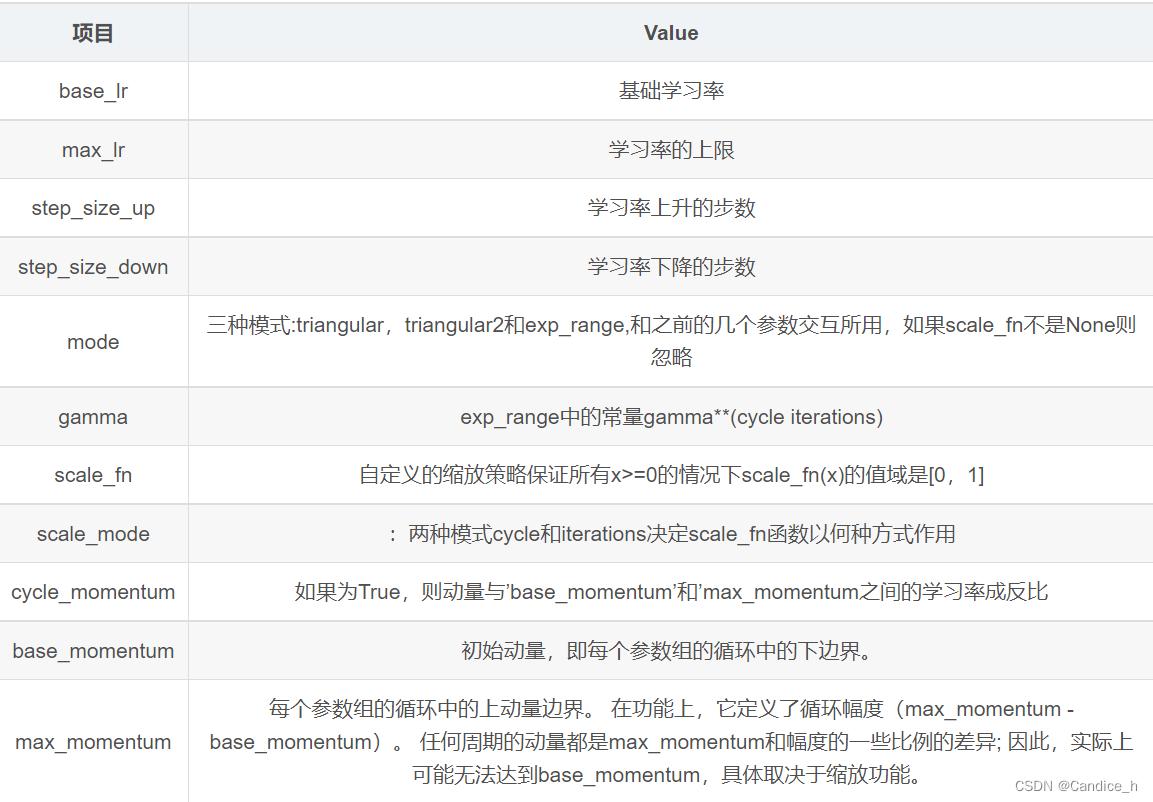
1.9 lr_scheduler.OneCycleLR:
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos', cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0, three_phase=False, last_epoch=- 1, verbose=False)
其中,
-
optimizer(Optimizer) -包装优化器。
-
total_steps(int) -循环中的总步数。请注意,如果此处未提供值,则必须通过提供 epochs 和 steps_per_epoch 的值来推断。默认值:无
-
epochs(int) -要训练的 epoch 数。如果未提供 total_steps 的值,则将其与 steps_per_epoch 一起使用以推断循环中的总步数。默认值:无
-
steps_per_epoch(int) -每个时期要训练的步数。如果未提供 total_steps 的值,则将其与 epochs 一起使用以推断循环中的总步数。默认值:无
-
pct_start(float) -用于提高学习率的周期百分比(以步数计)。默认值:0.3
-
anneal_strategy(str) -{‘cos’, ‘linear’} 指定退火策略:“cos” 用于余弦退火,“linear” 用于线性退火。默认值:‘cos’
-
cycle_momentum(bool) -如果
True,动量与 ‘base_momentum’ 和 ‘max_momentum’ 之间的学习率成反比循环。默认值:真 -
base_momentum(float或者list) -每个参数组的循环中较低的动量边界。请注意,动量循环与学习率成反比;在一个周期的峰值,动量是‘base_momentum’,学习率是‘max_lr’。默认值:0.85
-
max_momentum(float或者list) -每个参数组在循环中的上动量边界。从函数上讲,它定义了周期幅度 (max_momentum - base_momentum)。请注意,动量循环与学习率成反比;在循环开始时,动量为‘max_momentum’,学习率为‘base_lr’ 默认值:0.95
-
div_factor(float) -通过 initial_lr = max_lr/div_factor 确定初始学习率 默认值:25
-
final_div_factor(float) -通过 min_lr = initial_lr/final_div_factor 确定最小学习率 默认值:1e4
-
three_phase(bool) -如果
True,使用调度的第三阶段根据‘final_div_factor’来消灭学习率,而不是修改第二阶段(前两个阶段将关于‘pct_start’指示的步骤对称)。 -
last_epoch(int) -最后一批的索引。恢复训练作业时使用此参数。自从
step()应该在每批之后调用,而不是在每个 epoch 之后调用,这个数字代表总数量批次计算的,而不是计算的 epoch 总数。当last_epoch=-1 时,调度从头开始。默认值:-1 -
verbose(bool) -如果
True,每次更新都会向标准输出打印一条消息。默认值:False。
实际应用时可以简单表示为:
scheduler =torch.optim.lr_scheduler.OneCycleLR(optimizer,max_lr=0.9,total_steps=100, verbose=True)
其中,max-lr:每个参数组在循环中的上层学习率边界
total_steps: 总的batch数
1.10 lr_scheduler.CosineAnnealingWarmRestarts:
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
其中,T_0 (int) :学习率第一次回到初始值的epoch位置
T_mult (int, optional):T_mult=2意思是周期翻倍,第一个周期是1,则第二个周期是2,第三个周期是4。
eta_min (float, optional) – Minimum learning rate. Default: 0
2.自定义scheduler
首先定义动态变化函数:adjust_learning_rate
def adjust_learning_rate(optimizer, epoch):
lr = optimizer.param_groups[0]['lr'] # 学习率每个epoch乘以0.1
lr = lr * (0.1 ** (epoch // 10)) #学习率没10个epoch乘以0.1
return lr
在应用时,在优化函数之后:
optimizer.zero_grad() loss.backward() optimizer.step() adjust_learning_rate(optimizer, epoch)















 3605
3605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









