







当我们想要写出效率极高的代码的时候, 我们一般要做到下面两个方面:
- 有效的算法和数据结构
- 理解编译器的性能和局限性
-
编译器的作用和局限性
虽然一般的编译器都可以在某些方面提高代码的质量, 但是他们对代码的优化总是遵从下面的几点:
- 不能改变程序的行为
- 对程序的行为和所处的编译环境所知甚少
- 快速编译程序的需求
观察下面的代码: -
void twiddle1(int* xp, int* yp) { *xp += *yp; *xp += *yp; } void twiddle2(int* xp, int* yp) { *xp += 2\* *yp; }咋一看, 我们觉得这两个程序有着相同的行为, 但是仔细观察之后我们会发现, 在xp和yp不重合的情况下, 第二个函数的效率要比第一个函数的效率要高(只是执行一次取地址和运算的操作), 而在xp和yp重合的情况下, 这两个函数将会产生完全不同的两种结果。
在此, 我们知道下面的因素会导致代码的效率下降:
- 两个地址相互交叉
- 两个进程(函数)共享公共资源
-
衡量代码效率的因素
现代处理器速度的衡量因素是由其主频的频率决定的。现在认为, 计算机CPU的频率已经达到了硅半导体的极限值(4GHz). 在计算机科学当中, 用以衡量代码效率的量就是CPE, 表示的是执行一次元操作所需要的时钟次数。
理解处理机的结构
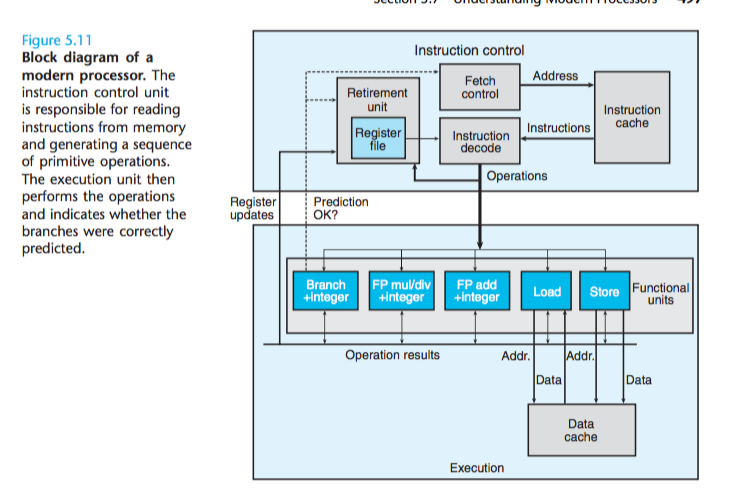
一个处理机的模型如下所示:
这个处理机主要有几个部分组成:
- 指令控制单元: 控制执行指令
- 执行单元: 负责执行相应的指令
- 指令缓存: 储存最近要执行的指令, 当存在转移指令的时候, 处理机会预测这个操作是否会发生, 甚至会直接执行这条指令, 当确认这条指令会执行的时候, 将操作数写入寄存器或内存, 否则执行相应的分支语句。
- 同时, 处理机存在一个模块来跟踪处于执行或者等待状态的指令, 并且缓存他们的结果。如果他们被确认将要执行, 则将他们的结果写入相应的内存和寄存器, 如果不, 则处理他们的结果。
- Load模块, 负责向内存中取数据
- Store模块, 负责向内存中存入数据
- 各种程序执行单元, 负责执行原子指令
-
一些提高代码效率的建议
通过上面的分析, 我们可以发现:
其实计算机中的操作甚至并不像我们所看到的汇编中所显示的操作。他包括取指令, 进行逻辑运算, 存取内存等等操作, 操作之间还有空隙的时间来保证每个原子操作的正确性。所以:
- 尽量使用代价较小的原子操作
- 尽量减少循环的次数
- 尽量减少循环的次数, 提高单次循环的效率。














 8223
8223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









