






双阶段目标检测算法
本文将系统的过一遍双阶段目标检测的经典算法,文献阅读顺序如下:
R-CNN
→
\rightarrow
→ SPPnet
→
\rightarrow
→ Fast R-CNN
→
\rightarrow
→ Faster R-CNN
→
\rightarrow
→ Mask R-CNN
R-CNN
一、研究背景
R-CNN可以说是将神经网络引用到目标检测任务之中的开山之作,在R-CNN之前,人们大多数还是利用手工特征和传统的机器学习方法,例如支持向量机(SVM),随机森林等等,但传统的这些方法往往在图像处理任务上展现出的性能没有很好。
于是我们的RBG(Ross Girshick )大神就提出了R-CNN,将卷积神经网络给引用到目标检测任务中,提高了检测精度,也算开创了这一系列的先河吧~
二、算法流程
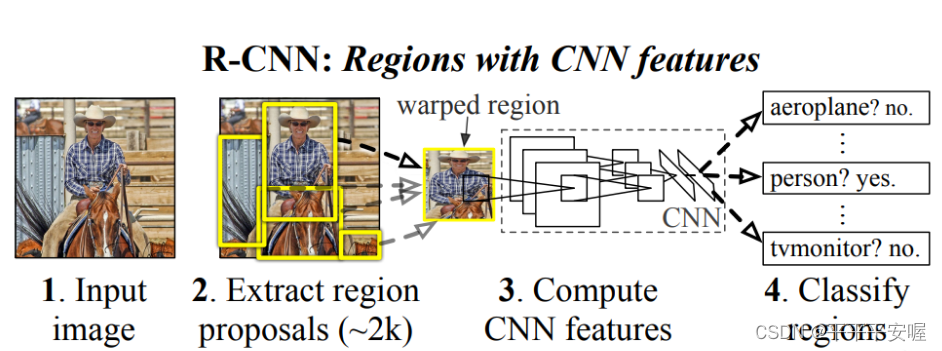
整体流程如上图所示,首先一张图片进来,先经过region proposal方法,提出待分类的区域,每张图大约会有2000个候选框,然后将这2000个候选框输入到CNN中进行特征提取,最后将提取的特征分为两个分支,一个分支输入到SVM中,进行分类,另一个分支进行回归,输出边界框的偏移值,进行边界框修正。具体来说主要分为以下四步:
(一) 利用Selective Search算法在图像上提取大约2000个候选框
(二)通过CNN对这些候选框进行特征的提取
(三)利用SVM方法进行特征分类
(四)利用线性回归器对边界框进行微调
其中(三)和(四)是并行的,并且SVM和线性回归器都是单独训练,其中他们的输入也各自有要求,这点后面会详细讲。
接下来我们分别详细阐述这四个步骤。

Selective Search(SS)算法
作者选择这个算法去提取候选框并不是因为这个算法多优秀,只不过当时大多数的方法用来提取候选框都是用这个算法的,作者为了比较方便,因此在提取候选框时也选用了这个算法。接下来我们大致说一下这个算法。
我们知道,最常规的方法,就是用不同尺寸的候选框,一行行遍历所有的点,判断候选框内物体是否有对象,是什么对象,但这样很显然,复杂度太高了,Selective Search可以快速的生成可能是物体的区域,具体算法流程如下

简单来说呢,对于一整张图像,他不断的合并相似度高的区域,直至全部合并完。当然,这样子合并完肯定会出现非常多密密麻麻的候选框,看源码还会对这些候选框进行进一步处理,例如排除太大或太小的候选框,排除扭曲的候选框,尽可能只保留矩形的等等。 这样,最后我们可以得到大约2000个候选框。 由于这块不是R-CNN的重点,例如相似度如何计算可以参考这篇文章。
https://blog.csdn.net/weixin_43694096/article/details/121610856

CNN进行特征提取
在这里需要说明的是网络的输入,我们知道候选框的大小肯定是不一样的,这点在最后输入到神经网络中可能会运行不起来,尽管现在网络大部分会在进入全连接层之前加一个 global pooling,但那样也会导致效果一般,以及那个时候global pooling应该还没有普及,因此最好的做法还是统一输入的shape。
如何选择让输入统一也是一个需要考虑的点,可以看下图,文中给出了许多统一shape的办法

第一列就是将图像等比例缩放并连带周围像素,第二列也是等比例缩放但是不连带周围像素,第三列就是强行将图像resize到所需的大小,是非等比例的。
第二行比第一行多的就是他们在底部加了16个像素的padding,实验结果表明这样会比不加好3~5个点。最终本文是选择了右下角的这种,非等比例缩放并在底部加16个像素的填充。
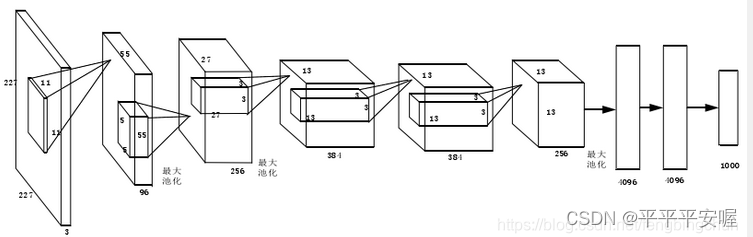
接着是R-CNN提取特征的网络结构,当然这里可以选择很多的网络,文中是用了8层的卷积神经网络,如图所示,5层卷积层,3层全连接层。具体的细节这里就不多说了,一个很简单的网络。
利用SVM进行分类
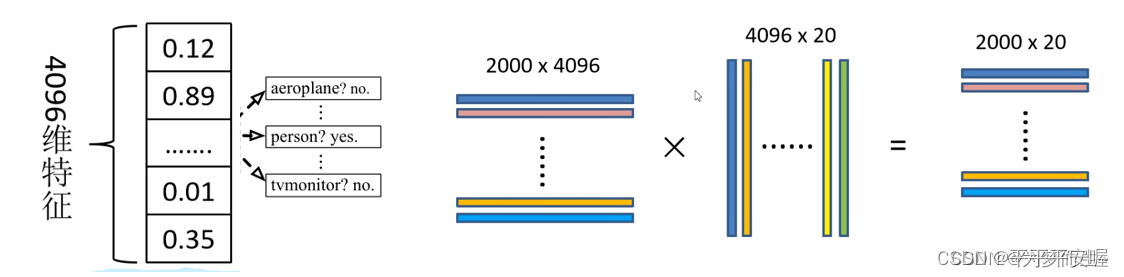
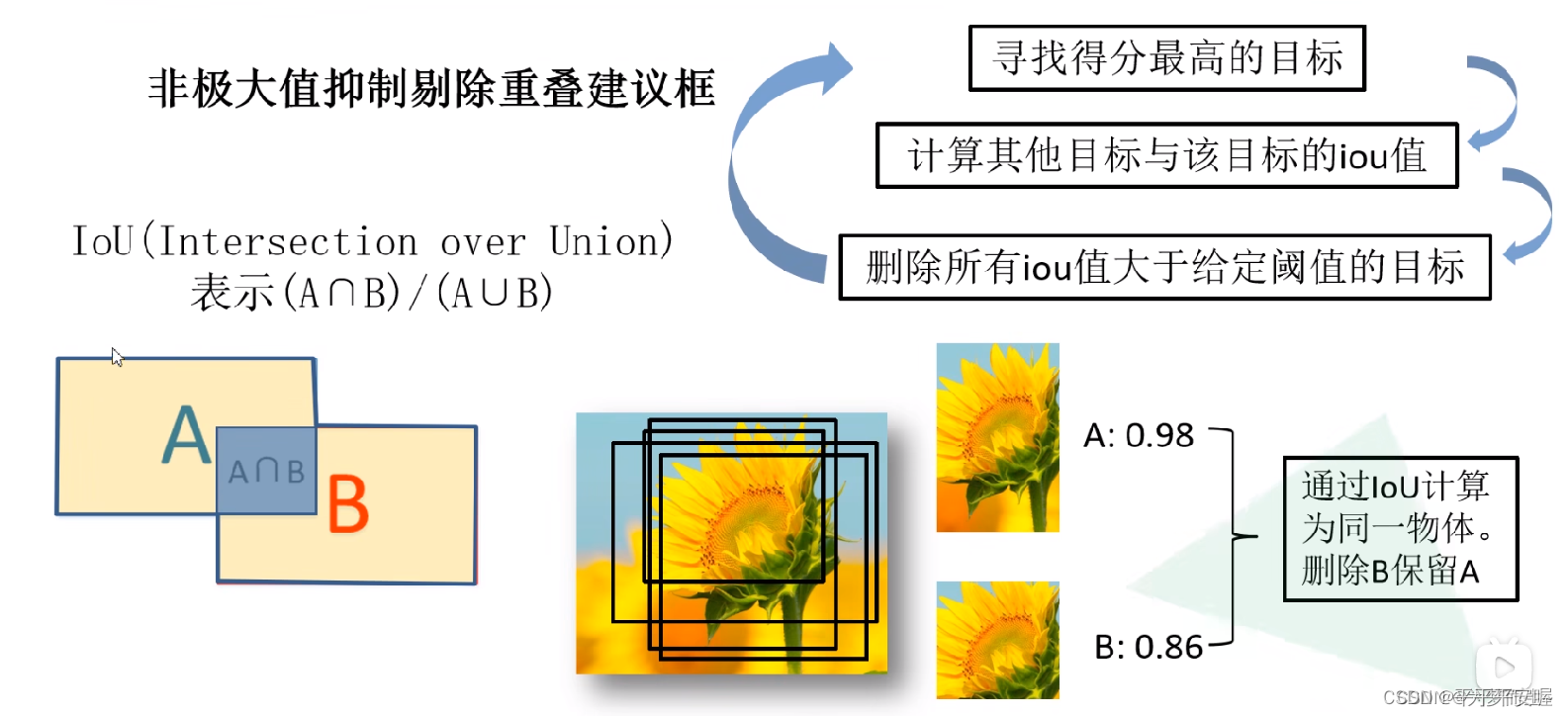
这一块其实也好说,就是假设有20个类别,那就对每个类别训练一个SVM,一共训练20个分类器,然后对进来的特征进行分类,之后再利用NMS对候选框进行选取。最基本的SVM这里就不一一推了,还有NMS,看图就很容易理解啦。
当然,也许时至发展今日,或许会有和我一样的疑惑,为什么要用SVM分类器?我直接用全连接不也可以吗(现在大部分都是这么做的)
作者也在文中的最后给出了解释:
Two design choices warrant further discussion. The first is: Why are positive and negative examples defined differently for fine-tuning the CNN versus training the object detection SVMs? To review the definitions briefly, for fine-tuning we map each object proposal to the ground-truth instance with which it has maximum IoU overlap (if any) and label it as a positive for the matched ground-truth class if the IoU is at least 0.5. All other proposals are labeled “background” (i.e., negative examples for all classes). For training SVMs, in contrast, we take only the ground-truth boxes as positive examples for their respective classes and label proposals with less than 0.3 IoU overlap with all instances of a class as a negative for that class. Proposals that fall into the grey zone (more than 0.3 IoU overlap, but are not ground truth) are ignored.
我简单翻译一下,我们在训练CNN时,使用的是与ground truth的IOU最大或IOU>0.5的候选框作为正样本,其余的是负样本。这是不好的,条件太宽松了,但是没办法,CNN训练需要更多的样本。 那我们在训练SVM的时候,就可以直接拿ground truth 作为正样本,与GT的IOU<0.3时作为负样本,利用了hard negative mining 进行训练。
PS:其实我觉得,一切还是要以实验为尊,在这里,实验表明,用SVM就是比用全连接要好,因此我们给他一个合理的解释。其实在后面读到Fast R-CNN的时候你会发现,他还是用了全连接,没用SVM,就是因为实验出来两者差不多甚至全连接更好。
利用线性回归器对边界框进行微调(Bounding-Box Regression)
Bounding-Box Regression 深挖原理,一个最基本的要求就是,假设我们的边界框目前是
P
(
P
x
,
P
y
,
P
w
,
P
h
)
P(P_x,P_y,P_w,P_h)
P(Px,Py,Pw,Ph) 其中
P
x
,
P
y
P_x,P_y
Px,Py表示的是边界框的中心,
P
w
,
P
h
P_w,P_h
Pw,Ph表示的是边界框的宽度和高度,Ground Truth我们就用
G
(
G
x
,
G
y
,
G
w
,
G
h
)
G(G_x,G_y,G_w,G_h)
G(Gx,Gy,Gw,Gh)表示,那么我们是希望找到一个映射,使得
f
(
P
)
=
G
^
≈
G
f(P)=\hat{G}\approx{G}
f(P)=G^≈G
RCNN论文里指出,边界框回归主要是利用平移变换和尺度变换来实现映射
平移变换可由下面公式表示
Δ
x
=
P
w
d
x
(
P
)
,
Δ
y
=
P
h
d
y
(
P
)
\Delta{x}=P_wd_x(P),\Delta{y}=P_hd_y(P)
Δx=Pwdx(P),Δy=Phdy(P)
G
^
x
=
P
x
+
Δ
x
,
G
^
y
=
P
y
+
Δ
y
\hat{G}_x=P_x+\Delta{x},\hat{G}_y=P_y+\Delta{y}
G^x=Px+Δx,G^y=Py+Δy
尺度变换由如下公式表示
Δ
w
=
e
d
w
(
P
)
,
Δ
h
=
e
d
h
(
P
)
\Delta{w}=e^{d_w(P)},\Delta{h}=e^{d_h{(P)}}
Δw=edw(P),Δh=edh(P)
G
^
w
=
P
w
∗
Δ
w
,
G
^
h
=
P
h
∗
Δ
h
\hat{G}_w=P_w*\Delta{w},\hat{G}_h=P_h*\Delta{h}
G^w=Pw∗Δw,G^h=Ph∗Δh
这里用 e e e次方是因为要保证尺度变化的非负性~
综上,我们可以得到以下四个公式
G
^
x
=
P
x
+
P
w
d
x
(
P
)
\hat{G}_x=P_x+P_wd_x(P)
G^x=Px+Pwdx(P)
G
^
y
=
P
y
+
P
h
d
y
(
P
)
\hat{G}_y=P_y+P_hd_y(P)
G^y=Py+Phdy(P)
G
^
w
=
P
w
∗
e
d
w
(
P
)
\hat{G}_w=P_w*e^{d_w(P)}
G^w=Pw∗edw(P)
G
^
h
=
P
h
∗
e
d
h
(
P
)
\hat{G}_h=P_h*e^{d_h(P)}
G^h=Ph∗edh(P)
那么其实就是去拟合这个 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_x(P),d_y(P),d_w(P),d_h(P) dx(P),dy(P),dw(P),dh(P),我们有
G
x
=
P
x
+
P
w
t
x
(
P
)
{G}_x=P_x+P_wt_x(P)
Gx=Px+Pwtx(P)
G
y
=
P
y
+
P
h
t
y
(
P
)
{G}_y=P_y+P_ht_y(P)
Gy=Py+Phty(P)
G
w
=
P
w
∗
e
t
w
(
P
)
{G}_w=P_w*e^{t_w(P)}
Gw=Pw∗etw(P)
G
h
=
P
h
∗
e
t
h
(
P
)
{G}_h=P_h*e^{t_h(P)}
Gh=Ph∗eth(P)
这个
t
x
,
t
y
,
t
w
,
t
h
t_x,t_y,t_w,t_h
tx,ty,tw,th我们是知道的,可以通过GT和P求出来,现在我们就是要让
d
∗
d_*
d∗去接近
t
∗
t_*
t∗,其中
∗
表示
x
,
y
,
h
,
w
*表示x,y,h,w
∗表示x,y,h,w
可以这样理解,模型想要的输出是什么?肯定是
t
∗
t_*
t∗对把?为此,就要让我们的回归器尽可能的去输出
t
∗
t_*
t∗,那么输入是什么呢?并不是
P
P
P,如果是
P
P
P的话那根本做不成,输入是我们之前通过CNN得到的特征,记为
ϕ
5
(
P
)
\phi_5(P)
ϕ5(P)也就是CNN中第五个池化层得到的特征,回归变换记为
W
W
W,那么就有如下的Loss
L
o
s
s
=
∑
i
=
1
N
(
t
∗
i
−
w
^
∗
T
ϕ
5
(
P
i
)
)
2
Loss=\sum_{i=1}^N(t_*^i-\hat{w}_*^T\phi_5(P^i))^2
Loss=i=1∑N(t∗i−w^∗Tϕ5(Pi))2
然后接下来就是要找到参数
w
w
w使得这个Loss最小了,当然文章还加了一个惩罚项,就是岭回归了,最终求解如下
w
∗
=
a
r
g
m
i
n
w
^
∗
∑
i
=
1
N
(
t
∗
i
−
w
^
∗
T
ϕ
5
(
P
i
)
)
2
+
λ
∣
∣
w
^
∗
∣
∣
2
w_*=argmin_{\hat{w}_*}\sum_{i=1}^N(t_*^i-\hat{w}_*^T\phi_5(P^i))^2+\lambda||\hat{w}_*||^2
w∗=argminw^∗i=1∑N(t∗i−w^∗Tϕ5(Pi))2+λ∣∣w^∗∣∣2
文章中取的用来训练Bounding box 回归的与GT的IOU>0.6的边界框,这是因为只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work。
那么也许你会有疑问,例如
t
w
=
l
o
g
G
w
P
w
t_w=log{\frac{G_w}{P_w}}
tw=logPwGw,你怎么能说他是线性变换呢?也就得运用到一个高数中学到的知识了,就是等价无穷小。我们知道,当
x
→
0
x\rightarrow0
x→0时,
l
o
g
(
1
+
x
)
=
x
log(1+x)=x
log(1+x)=x,那么
l
o
g
G
w
P
w
=
l
o
g
G
w
−
P
w
+
P
w
P
w
=
l
o
g
(
1
+
G
w
−
P
w
P
w
)
log{\frac{G_w}{P_w}}=log{\frac{G_w-P_w+P_w}{P_w}}=log(1+\frac{G_w-P_w}{P_w})
logPwGw=logPwGw−Pw+Pw=log(1+PwGw−Pw)
那么我们刚刚说了用来训练Bounding box 回归的与GT的IOU>0.6的边界框,在文中默认了这种方式
G
w
≈
P
w
G_w\approx{P_w}
Gw≈Pw,因此,依旧可以看作线性回归。
3. 实验结果
这篇文章做的实验蛮多的,在这里我就展示几个与其他方法在VOC数据集上的比较。
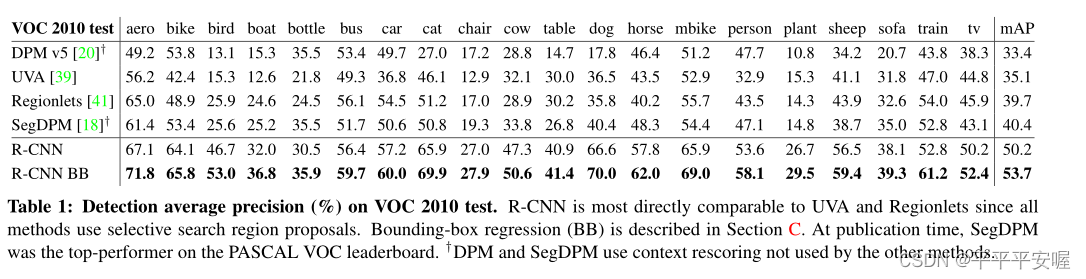
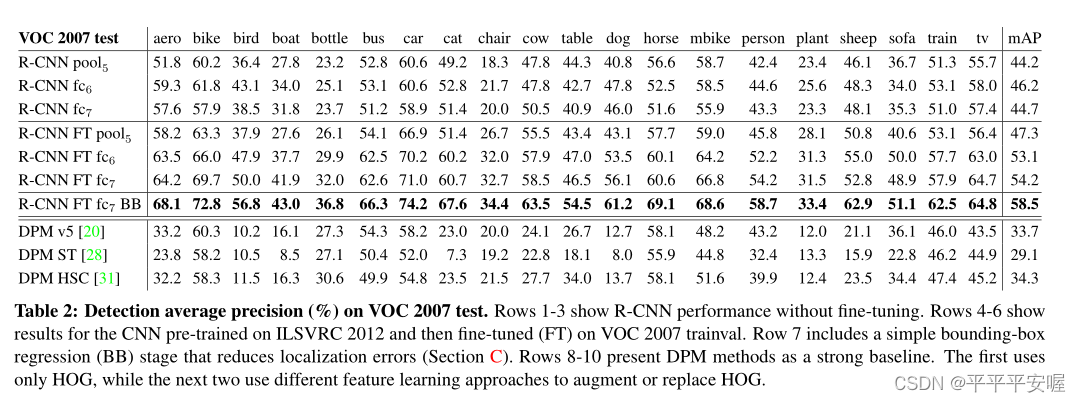
这里我就不多做阐述,几乎在每个类别上都达到了SOTA效果。
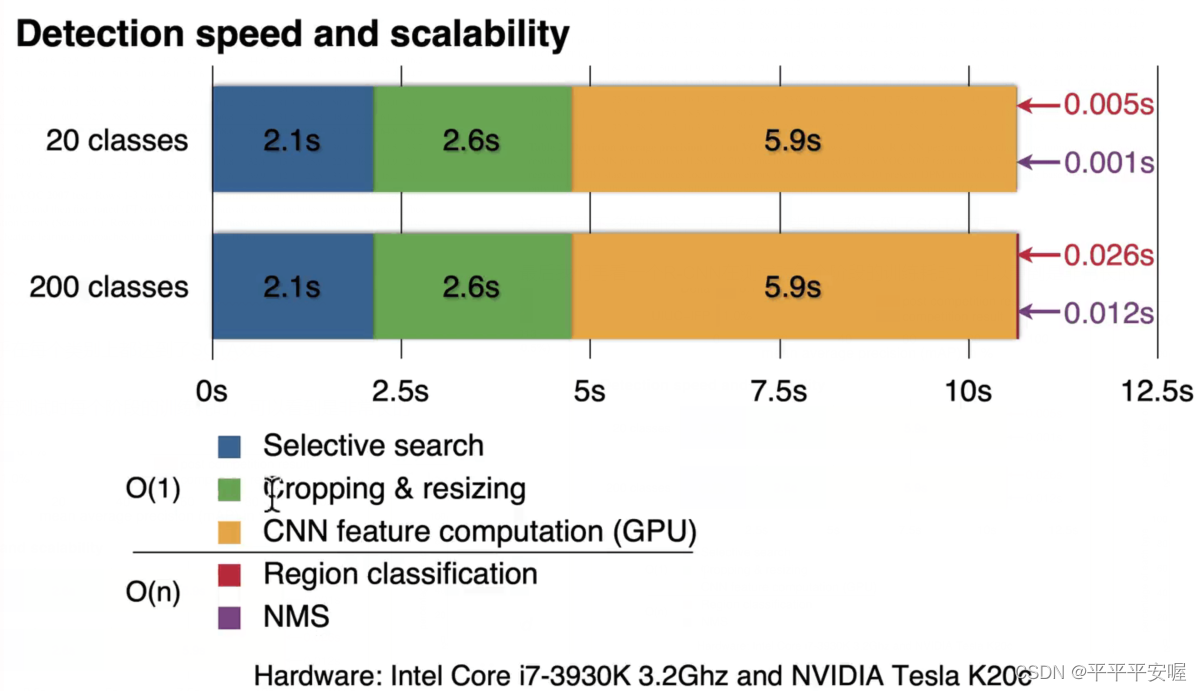
最后我们再看一个R-CNN在测试时每个阶段的训练耗时,可以看到是非常长的
SPPspatial pyramid pooling) net
其实读到第二篇之后,问题就会少很多,例如Bounding box 回归怎么做,SVM怎么做等等,在接下来就不会再重复解释。
一、研究背景
这篇文章是kaiming He提出来的,其实看完这些经典的检测算法,你会发现一作基本就是两个人,Kaiming He 或者上一篇提到的RGB大神哈哈。
回归正题,SPPnet为何被提出来呢,从上一篇R-CNN我们特意强调了,CNN在输入时,会wrap或者crop到网络需要的大小,因为全连接层需要输入段具有相同的神经元,因此这就需要你整个神经网络的输入需要一样,这样才一步步推到全连接层时得到的特征数(图片的shape)是一样的。
那么这种wrap或者crop的处理,其实是会对图片造成信息损失的,这是显而易见的,于是作者就想为什么不能在全连接层前,加入一个操作,使得任何形状的图片经过后,都变成一样的大小呢?于是就有了这篇SPPnet,当然现在大部分分类任务都会在全连接层前加一个全局池化,但这都是后话了~
二、算法流程
SPPnet整体的流程图其实和R-CNN类似,也是一样的要经过一轮Selective Search,然后将图像输入到CNN中提取特征,最后利用SVM和线性回归进行分类以及边界框微调。我在这里就不过整体流程了,我说SPPnet的三大改进。
(一)特征映射 — 整个图像只需要过一次CNN
(二)SPP具体的使用结构
(三)Multi-size 训练,SPPnet的天然优势,可以使用多尺度来训练
特征映射
首先我们先不说SPP(图像金字塔),先说SPPnet的另一个重要改进—特征映射。
我们知道,在R-CNN中,通过SS算法提取出来的每一个候选框都得经过一次CNN,那么一共有2000个候选框,就代表有两千张图像要经过CNN网络,这一部分是非常耗时的,从之前给的耗时图就可以看出来,这部分占的比例最大。那么本文作者是如何避免的呢?我们先看一张图

可以看到,原图像中车轮等轮廓,在后面的feature map中也会在相应位置体现出来,那么这就代表着,我们不用把一个个候选框都丢到CNN中去提取一遍特征,而是可以直接将整张图像用CNN提取完整体特征,然后再将SS提取到的候选框去对得到的feature map直接做映射,找到这个候选框在feature map上的位置,进而利用映射到feature map上的候选框去分类。
那么如何映射呢? 其实就是将图上的位置映射到feature map的相对位置。例如,你的feature map 相对于你图像大小缩小了两倍,那么如果你这个点原来在图像上的位置是(100,100),那么到feature map上的位置就是(50,50)。当然这只是一个大概的例子,为了方便理解,大差不差,不过具体操作会涉及到上下取整然后+1 - 1这种操作。
具体操作是:我们将conv 或者 Pool的所有步长做一个乘积称为S(因为基本都会有Padding,所以conv或者Pool的步长大小就可以看作他们缩小了基本,例如conv的步长为2,那么代表就会将图像缩小两倍)。作为边界框的上(左)界,投影的位置为 x ′ = ⌊ x / S ⌋ + 1 x^{'}=\lfloor x/S \rfloor + 1 x′=⌊x/S⌋+1,下(右)边界投影的位置为 x ′ = ⌈ x / S ⌉ − 1 x^{'}=\lceil x/S \rceil - 1 x′=⌈x/S⌉−1。
当然,如果你没有padding,那么还需要加上具体的偏移值。
SPP(spatial pyramid pooling) layer
SPP其实原理很简单,先看一张图
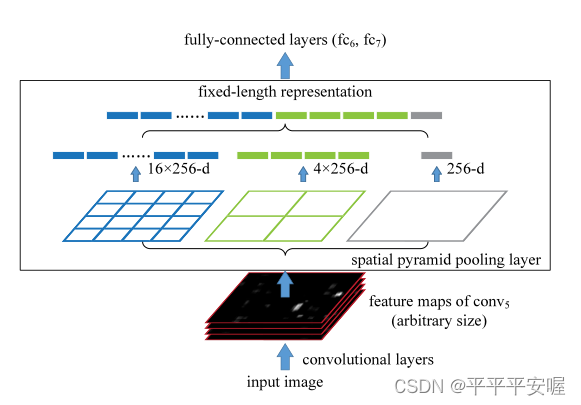
如图所示,SPP pooling的部分并不是像传统的直接2*2大小的格子为一个框然后取max或者ave,他是根据图像的大小来进行需要pooling的区域大小。其分为多级,一级就是将一整个图像都进行Pooling,二级是将整体图像分为四个区域进行Pooling,三级是将整体图像分为16个区域,以此类推。
举一个简单的例子,例如我现在输入的候选框大小是3232的,那么在做二级SPP时,每个需要Pooling的区域大小就是1616的,总共有四个。如果候选框大小是1616的,那么在做二级Pooling时,每个需要Pooling的区域大小就是88的。
文中是将三个级别的Pooling最后concat起来,作为最后全连接的输入,多层次池化已被证明对物体变形具有鲁棒性。
就是这种特性,使得SPPnet可以接受不同大小的输入,因为不管输入的图像是什么shape的,最后都会得到相同大小的输出。
Multi-size 训练
SPPnet可以接受不同大小的图像,这有一个天然的优势就是他们可以使用不同大小的图像进行训练,这里的不同大小不是指候选框,而是指的输入的图像。这样可以扩展数据集,也可以提升模型的泛化能力。
文中提到,在使用多尺度训练时,不同size图片的训练是交替进行的,例如第一个epoch训练的输入的224224的图像,第二个epoch训练的是180180的图像,第三个epoch训练的又是224*224的图像,这样进行训练,当然,训练过程中模型的权重肯定是要保持的。
其余整体的训练方式就跟R-CNN一样的,这里就不再赘述,使用的CNN如下
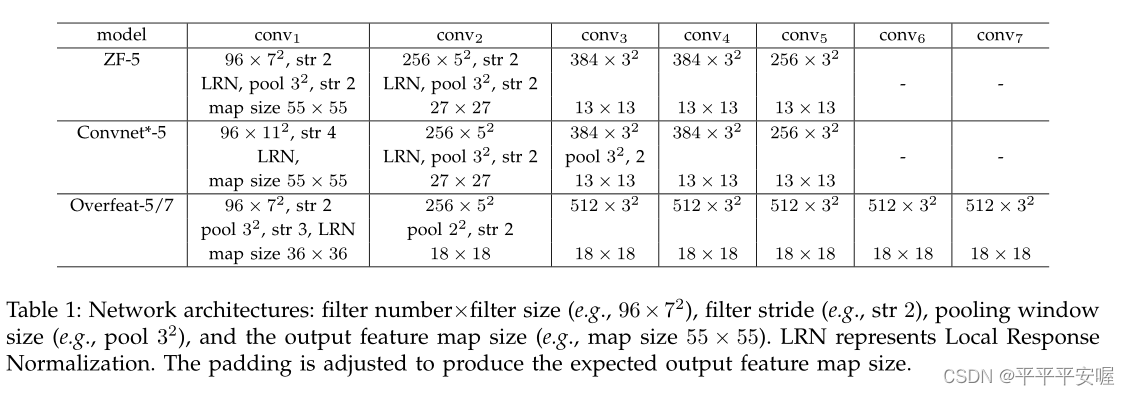
三、实验结果
同样的,这里不会把他所有的实验结果都拿出来说,这里只看重要的,与其他方法的比较
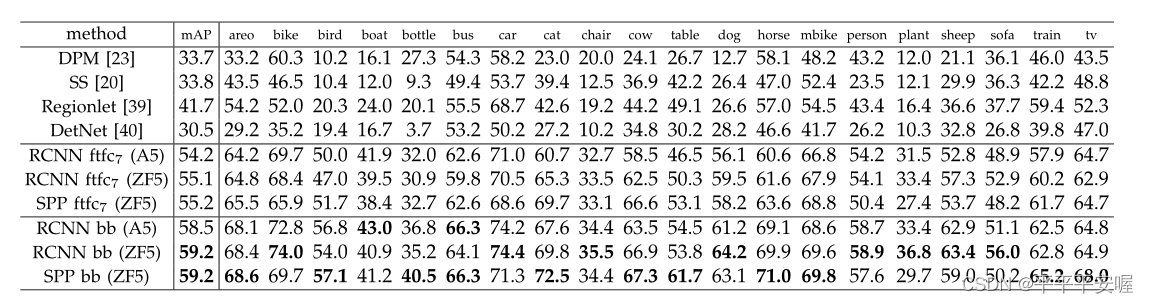
可以看到,在检测上,SPPnet达到了能与R-CNN相同甚至比R-CNN好的结果,但是其速度能快很多,这是毋庸置疑的,他不需要wrap/crop和全部候选框都过一遍CNN。
Fast R-CNN
一、研究背景
好了,这篇论文又是RBG大神独自提出来的了,这篇为什么提出来呢?首先我们先回顾一下前面R-CNN和SPPnet的缺点。
对于R-CNN来说,缺点十分的明显
- 训练是多阶段的,就是CNN,SVM和线性回归分开训练
- 训练十分的耗时间和空间(空间是因为在训练SVM和回归器的时候需要把CNN提取到的特征保存下来)
- 测试需要大量的时间
那么对于SPPnet呢,同样也有很多缺点
- 训练同样也是多阶段的
- 训练需要大量的空间
- 微调算法无法更新空间金字塔池化之前的卷积层
前面几点都好理解,最后这个为什么微调算法无法更新空间金字塔池化之前的卷积层? 在SPPnet中作者并没有说明,但我在文章里确实只看到作者对全连接层进行微调,没有对卷积层进行微调。RGB在本文中给出了答案,这是因为在特征图上的每个候选框所拥有的感受野是非常大的,每次更新通常需要跨越整个整张图片,那么可能随机到128个候选框,都来自不同的图片,这样子就会导致资源消耗非常的大。
二、算法流程
在这里,我们将根据以上研究背景,讲解过程如下:
(一)首先讲解Fast R-CNN的整体结构,模型解决了训练是多阶段的,
(二)之后再说明他的训练流程,他为什么可以解决SPPnet中无法更新空间金字塔池化之前的卷积层。
(三)作者如何加快模型的训练和测试速度,正常来说作者使用了一个特殊的SPP layer,测试速度应该和SPPnet差不多,但是作者使用了一个巧妙的方法加速了测试。
Fast R-CNN 整体结构
整体结构如下图所示
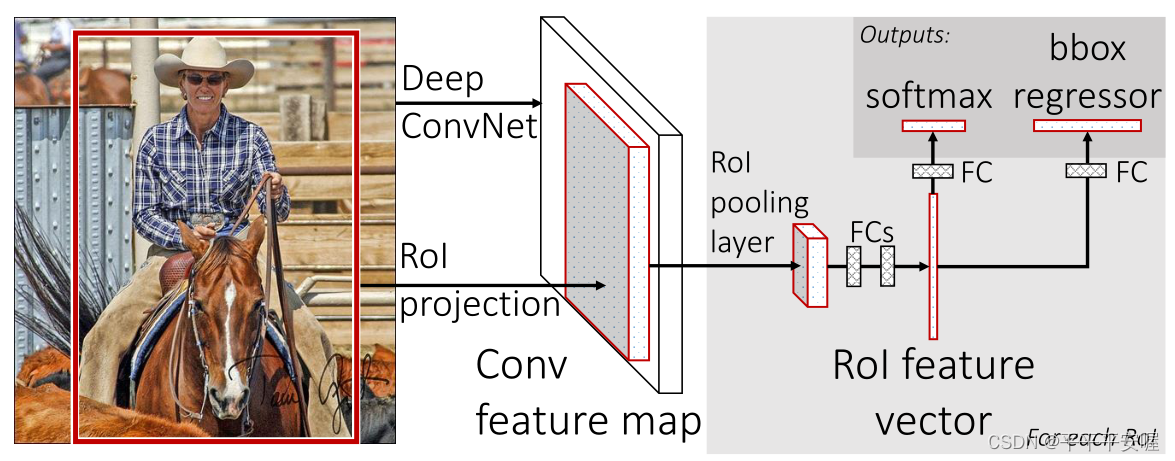
抛开最后面的两个fc层,前面提取特征的部分和SPPnet差不多,都是整体图像经过一次conv,然后利用SS算法提出了候选框,通过特征映射将候选框映射到feature map上,然后再进入Rol Pooling layer。与SPPnet在提取特征方面唯一的不同就是将SPP layer换成了Rol Pooling layer。最后再进入两个fc,摒弃了之前传统的SVM分类器,这样就可以把整体都串联到一起了,训练更加的方便。我们分三个结构介绍Fast R-CNN整体结构,分别是特征提取CNN部分,RoI Pooling,两个fc层以及他们的Loss。
1.特征提取结构
这里只是简单说明,文中用了一些比较经典的架构,例如Alexnet、VGG等。不再过多赘述。
2. RoI Pooling
接下来介绍一下RoI Pooling layer。Rol Pooling 呢,其实就是一种特殊了Spp layer,Spp layer是多层结构的,之前我们说过的,他是分级然后每级Pooling完后concat起来。而RoI Pooling是只有一级,只不过他可能是直接将整个候选框给用这种方式Pooling到2*2的图像,不像Spp layer那样去多级堆叠。如图所示,左下角是提出的候选框,然后通过这种分块方式,将候选框变为2*2的。
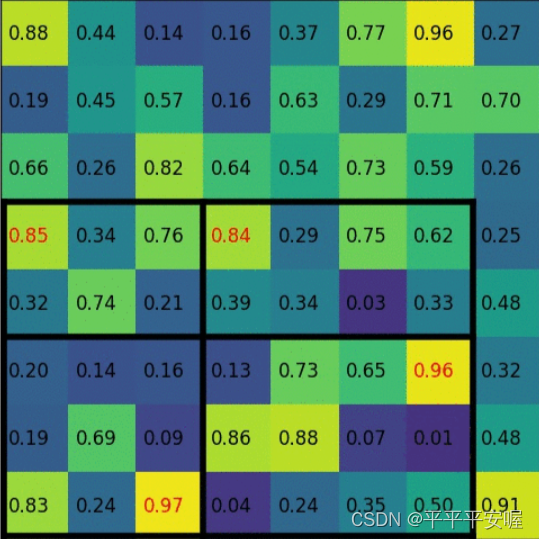
这样的话,也是一样的,所有候选框都会变为一个尺寸,也不用像之前说的wrap/croz图像,不会有信息损失出现。后续也证明了,即使在这块使用Spp layer多层次堆叠,精度也不会提高。
3. 多fc层(多任务)损失
Fast R-CNN 和 之前的SPPnet与R-CNN 很大的一个不同点就在这,其分类器和bounding box回归是可以和CNN一起训练的,用的也是传统的全连接层。整体损失是由两部分组成的,一个是分类损失,一个是bounding box 损失
L
(
p
,
u
,
t
u
,
v
)
=
L
c
l
s
(
p
,
u
)
+
λ
∣
u
⩾
1
∣
L
l
o
c
(
t
u
,
v
)
L(p,u,t^u,v)=L_{cls}(p,u) + \lambda|u\geqslant1|L_{loc}(t^u,v)
L(p,u,tu,v)=Lcls(p,u)+λ∣u⩾1∣Lloc(tu,v)
其中
p
p
p代表分类器预测的所有类别的概率,
u
u
u代表是属于
u
u
u类,
t
u
t^u
tu则表示预测Bounding Box偏移量的时候
u
u
u类需要偏移的量,
v
v
v则是对应的ground truth的边界框。具体的
L
c
l
s
(
p
,
u
)
=
−
l
o
g
(
p
u
)
L_{cls}(p,u)=-log(p_u)
Lcls(p,u)=−log(pu)
是最简单的softmax损失。而
L
l
o
c
L_{loc}
Lloc损失是用的smooth损失
L
l
o
c
(
t
u
,
v
)
=
∑
i
∈
{
x
,
y
,
w
,
h
}
s
m
o
o
t
h
L
1
(
t
i
u
−
v
i
)
L_{\mathrm{loc}}(t^u,v)=\sum_{i\in\{\mathrm{x,y,w,h}\}}\mathrm{smooth}_{L_1}(t_i^u-v_i)
Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu−vi)
其中smooth函数如下
s
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
i
f
∣
x
∣
<
1
∣
x
∣
−
0.5
o
t
h
e
r
w
i
s
e
,
\mathrm{smooth}_{L_1}(x)=\begin{cases}0.5x^2&\mathrm{if} |x|<1\\|x|-0.5&\mathrm{otherwise},\end{cases}
smoothL1(x)={0.5x2∣x∣−0.5if∣x∣<1otherwise,
至此,两个损失就介绍完了,文章最后将 λ \lambda λ设置为1,两个Loss的重要性是等价的。
训练流程
在这里,我们再次回顾一下为什么说SPPnet无法微调CNN前面的卷积层?
先来说一下他是怎么对CNN模型进行微调的,分类器不是用的SVM吗?因为在微调的时候,他将全连接层的输出改为类别输出,然后用类别的回归就好了,等微调完,再将全连接的输出作为特征,输入到SVM中、(不一定要是全连接层的,也可以将最后一个pool层特征输入SVM中),那么SPPnet此时会遇到一个问题,训练的时候是先利用SS算法,把图片的候选框给选取出来,然后再将这些候选框随机组成一个batch。这样会导致他一个batchsize=128内的候选框可能分别来自128张图片的,SPP layer的感受野又大,这就导致一次batch需要跨越128张图像,这时候消耗资源就非常大了。
Fast R-CNN做的改进:
假设SGD的一个mini-batch需要采样128个候选框,那么我们先采取N个图片,然后在N张图片上,再采样他们的R/N个候选框,在一张图片上的候选框进行反向传播的时候可以实现共享计算,这就大大降低了资源开销。
文中将N设置为2,R设置为128,意味着每个mini-batch采样2张图片,每张图片上采样64个候选框,每次反向传播只需要跨越2张整体图像就好了。
加快模型训练和测试技巧
由于特征映射的技巧,图像确实只需要过一遍CNN,但是每个候选框还是都要过fc层呀,这就导致有大量的时间消耗了。
于是Fast F-CNN采用了SVD分解加速全连接层的计算,这样的话,计算复杂度由uv会降低到(u+v)t,u和v分别为全连接层的输入输出,t为SVD分解出来的中间的矩阵。如果t远小于u,v的话,那么速度提升是明显的。
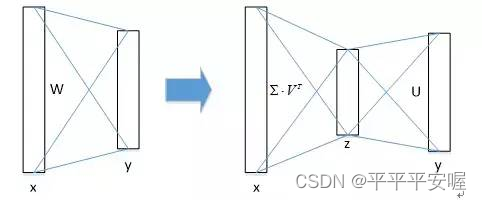
由实验得到,SVD分解可以在只损失了0.3%map的精度下,提升30%的速度,效果是显著的。
三、实验结果
还是一样的,这里只展示与SOTA方法的对比结果,其余结果例如消融实验可到原文中查询
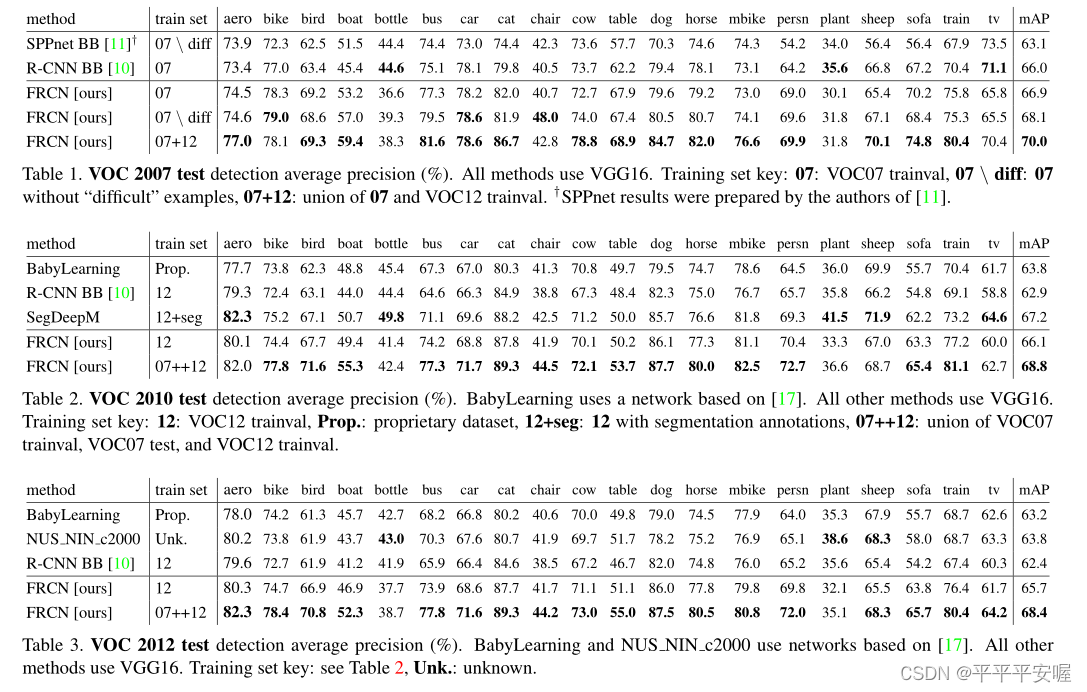
在VOC2007,2010,2012数据集上都取得了SOTA的结果。
训练速度:
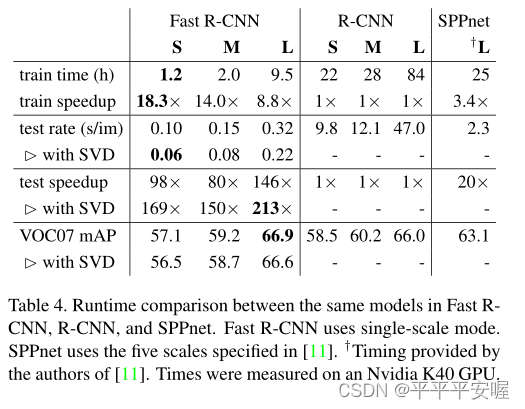
可以看到Fast R-CNN的训练速度
与RCNN相比时间减少9倍(84 vs 9.5)。与SPPnet相比时间快2.7倍(25.5 vs 9.5)
测试时
与RCNN相比不带SVD快146倍,带SVD快213倍。与SPPnet相比,不带SVD快7倍,带SVD的快10倍。
最后再来看一下,SVD分解带来的速度提升
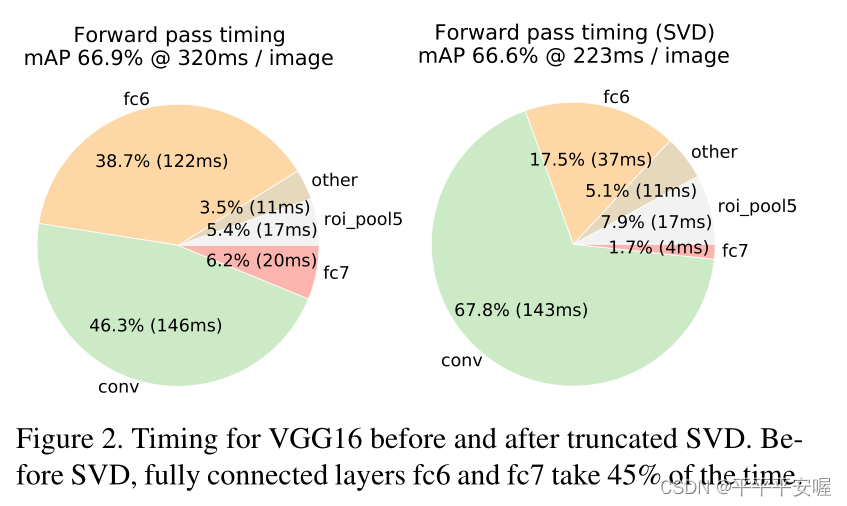
可以看到,一次test速度提升了约90ms,速度提升主要发生在全连接层,占总体的30%。
Faster R-CNN
一、研究背景
前面三篇论文读下来,不知道大家有没有感觉到一个地方和深度学习格格不入。没错,就是提取候选框用的SS算法,这个地方在我看来,还是用的传统的算法,该算法只是基于工程底层特征贪婪地合并像素,并且这块也是Fast R-CNN的一个速度和性能瓶颈,因为这块相较于CNN来说是很慢的,其次无法与CNN很好的衔接,于是本文作者提出了Faster R-CNN,抛弃了传统的候选框提出方法,而结合CNN重新提出了一种方法。
By the way,本文作者是何凯明和RGB一起写的~ 当然还有其他的作者,Shaoqing Ren和Jian Sun。
二、算法流程
先来看一下文章给的图
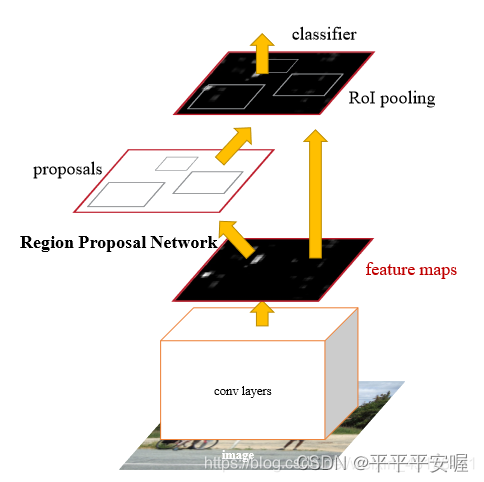
从这张图可以看出,中间是由一个RPN的网络提出的候选框,然后融合feature map 通过ROI pooling后进行分类,这张图只是表现的一个大体的框架,更加细节的框架如下。
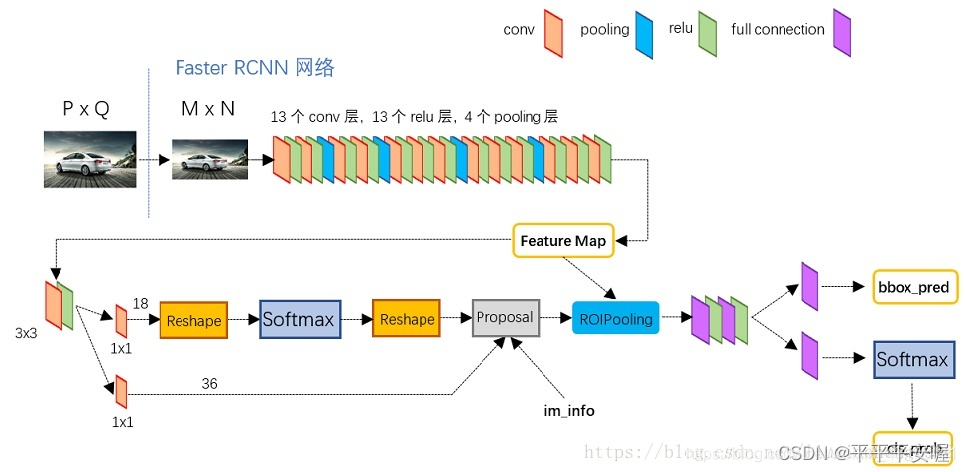
最后我们的目标就是看懂这个图,看懂这个图上每个箭头代表什么意思,那么整个Faster R-CNN我们也就全部掌握了。有些东西在Fast R-CNN我们就已经讲过了,例如ROI Pooling等,这里不再过多赘述。接下来我从特征提取,RPN,多任务损失,训练方法四个方面来讲述Faster R-CNN。
特征提取
这块依然没有什么好说的,此时Resnet还没有被提出来,用的依然是ZF、VGG这些网络去做特征提取。
Region Proposal Networks(RPN)
anchors
在一块我们先说anchors。
假设图像在经过特征提取后,特征图的大小为M
×
\times
×N,那么Faster R-CNN会在特征图的每个点上,各生成k个anchor,这样总共有M
×
\times
×N
×
\times
×k个锚框,在原文中每个点生成9个anchor,这9个anchor的大小用三种尺度和三种长宽比ratio设置。如下图所示,之后,RPN会对所有锚框进行分类(正类或负类)和微调(是直接对所有的锚框进行分类和微调,只需要前向传播一次,不需要一个个锚框进行输入)
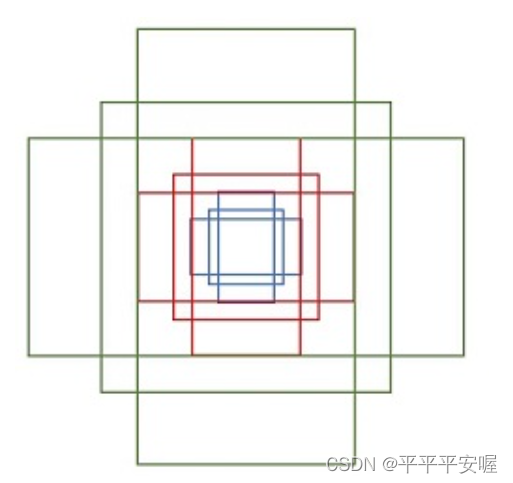
RPN详细模块
anchors说完了,接下来我们再来具体看RPN的具体结构,看看他是如何对这些锚框进行分类和微调,以及最终提取出的候选框是什么、RPN的方法结构如下。
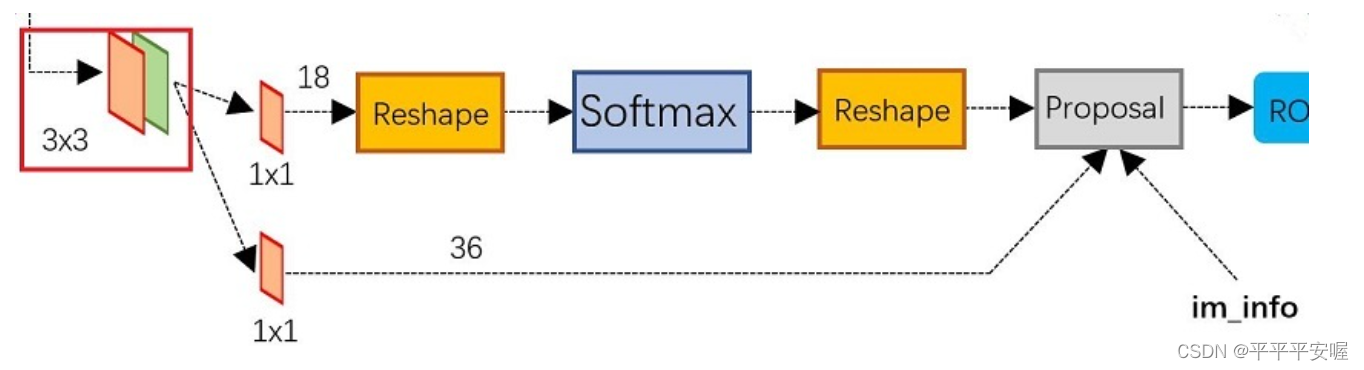
首先,feature map会经过一个33的卷积,然后分成两条路径,一条路径是分类(正类和背景类,作用后面会体现),另一条路径是对anchors进行微调,中间的reshape是技术细节,这里我们暂时不需要了解。总而言之,上面这条分类路径,最终会输出的shape是MN*2k(文中k为9)。这样,对于每一个点生成的anchors,例如一个点生成了9个anchor,最终对应的输出为18,即每个anchor对应两个输出,分别为 是正类和负类的概率。
同理的,对于下面这条做anchor微调的,最终会输出的shape是MN4k。一个anchor对应4个值用作微调,具体怎么微调在一开始就介绍了,忘记了可以往前翻一翻^ ^。顺便说一下,这里提出候选框时需要做一次微调,然后最后还需要再做一次微调,就是整体的Faster R-CNN需要做两次微调。
生成候选框
上面的流程都说完了,那么模型最后是怎么生成候选框的呢?总不能所有的anchor都算候选框把?那这样的话数量级太大了,不太现实,因此,本文的生成候选框的流程如下:
(1)利用回归层的偏移量,对所有原始anchor进行微调。
(2)利用分类层预测的scores,按正类得分从大到小排列所有anchors,取前N个(N自己设定)个anchor(对的,正类得分在这里可以帮助模型初筛掉一些anchor)
(3)将超出了图像边界的anchor部分收拢到图像边界处,这一步是为了防止后续的Rol Pooling时出问题。
(4)删除尺寸非常小的anchor
(5)对剩下的anchor进行NMS筛选
(6)最后就可以输出一堆候选框了,需要注意的是,这里的候选框对应的坐标是基于原图的,不是基于feature map。
因此现在我们回过头来看原始那张图,我们就能明白那些箭头是什么意思了
im_info那个箭头,指的是原始在输入图像上生成的锚框,进行微调。而Feature Map到ROI Pooling那个箭头,指的是最后RPN提出的anchor需要先映射到Feature Map上,然后再进行ROI Pooling操作。
多任务损失
这里有两个地方需要训练,一个是RPN,一个是RPN提出候选框后的Fast R-CNN部分,两块的Loss其实差不多,这里就挑RPN的Loss来讲,和后面的Fast R-CNN部分只是二分类和多分类的问题,差别不大。
总体Loss还是分为两部分,一部分分类,一部分回归。
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
.
L(\{p_{i}\},\{t_{i}\})=\frac{1}{N_{cls}}\sum_{i}L_{cls}(p_{i},p_{i}^{*})+\lambda\frac{1}{N_{reg}}\sum_{i}p_{i}^{*}L_{reg}(t_{i},t_{i}^{*}).
L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗).
其中
p
i
p_i
pi表示预测出来第
i
i
i个锚框是目标的概率
p
i
∗
p_i^*
pi∗为对应的ground truth,若第
i
i
i个anchor与真实目标的iou > 0.7,
p
i
∗
p_i^*
pi∗为1,若iou<0.3,则
p
i
∗
p_i^*
pi∗为0,其余情况不考虑
t
i
t_i
ti表示的是预测微调anchor的偏移
t
i
∗
t_i^*
ti∗表示对应的ground truth,表示真实的框和anchor之间的偏移
N
c
l
s
N_cls
Ncls为mini-batch的大小,文中设置为256
N
r
e
g
N_reg
Nreg设置为anchor位置的数量,文中设置为2400
λ
\lambda
λ用于平衡两个Loss,文中为10
可以看到,其实就是最小化了一下Fast R-CNN的Loss。其中分类Loss为
L
c
l
s
(
p
i
,
p
i
∗
)
=
−
l
o
g
(
p
i
)
L_{cls}(p_i,p_i^*)=-log(p_i)
Lcls(pi,pi∗)=−log(pi)
也有人说是用的交叉熵损失,也都差不多。
回归Loss还是为smooth L1 loss,如下
L
l
o
c
(
t
i
,
t
∗
)
=
∑
i
∈
{
x
,
y
,
w
,
h
}
s
m
o
o
t
h
L
1
(
t
i
−
t
∗
)
L_{\mathrm{loc}}(t_i,t^*)=\sum_{i\in\{\mathrm{x,y,w,h}\}}\mathrm{smooth}_{L_1}(t_i-t^*)
Lloc(ti,t∗)=i∈{x,y,w,h}∑smoothL1(ti−t∗)
其中smooth函数如下
s
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
i
f
∣
x
∣
<
1
∣
x
∣
−
0.5
o
t
h
e
r
w
i
s
e
,
\mathrm{smooth}_{L_1}(x)=\begin{cases}0.5x^2&\mathrm{if} |x|<1\\|x|-0.5&\mathrm{otherwise},\end{cases}
smoothL1(x)={0.5x2∣x∣−0.5if∣x∣<1otherwise,
总体的reg Loss前面乘了一个 p i ∗ p_i^* pi∗表示的是只微调那些带有目标的框。
训练方法
我们需要意识到,RPN和最后的Fast R-CNN模块是单独分开来训练的,他们还是不能同时训练,文中给出了一个两个模块交叉训练的方法。总共分四步,如下
(1):使用在ImageNet上的预训练权重初始化RPN网络的共享conv层(也就是最开始特征提取那部分),关于RPN的特有层可以随机初始化,然后开始训练RPN,得到RPN特有层的权重
(2)利用训练好的RPN拿到proposals,再利用Imagenet预训练权重初始化Fast R-CNN部分的共享conv层,Fast R-CNN特有部分随机初始化,训练完后,得到共享卷积层和Fast R-CNN特有层的权重。
(3)使用第二步得到的共享conv层和第一步训练好的RPN特有层来初始化RPN网络,再次训练RPN网络,但这次共享conv层权重不变,只训练RPN特有部分
(4)利用训练好的RPN得到proposals,并且将第二步训练好的共享conv层和第二步训练好的Fast R-CNN特有部分权重初始化Fast R-CNN,去训练Fast R-CNN,同样的,固定共享conv层。
综上四个步骤训练完毕,类似的交替训练可以运行多次迭代,但提升意义不大、
三、实验结果
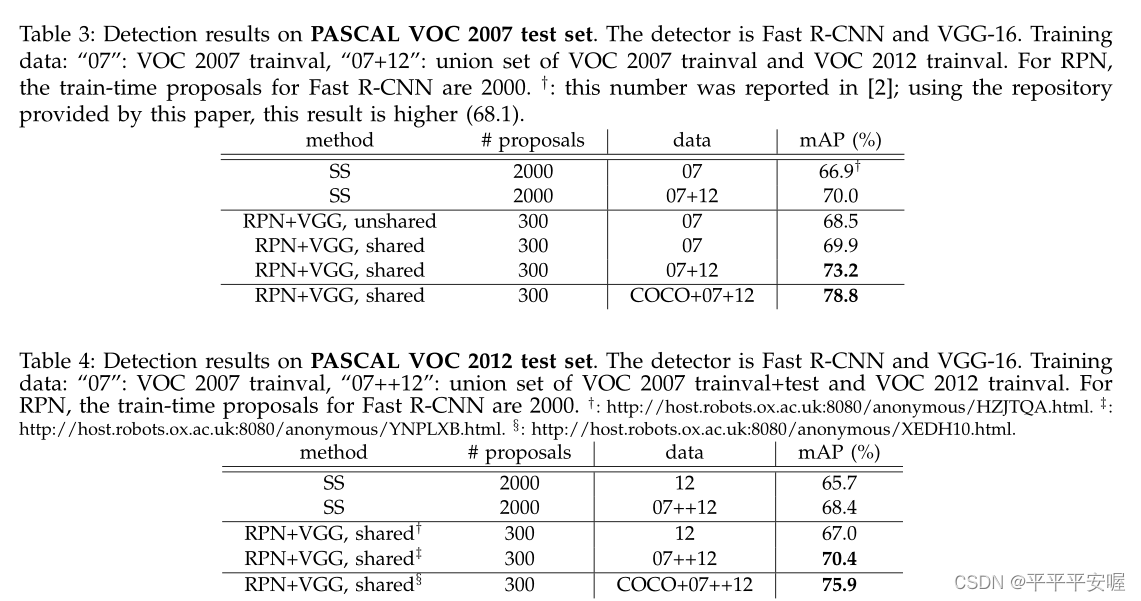
这里没有很多方法进行比较,主要就是和SS提出候选框的方法进行了比较,可以看到结果是会比他好很多的。
Mask R-CNN
Mask R-CNN的提出主要是为了做分割的,其在Faster R-CNN的基础上,加了一条平行路径出来做分割,可以看下面这张图
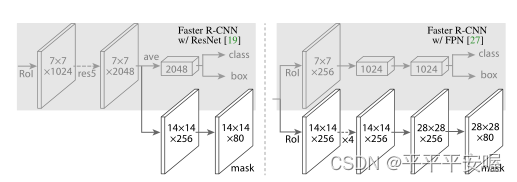
就像这样,在class,box以外又加了一条mask。不过本博客的目的是为了介绍双阶段目标检测算法,所以这里不会将mask部分,只会将关于检测的部分。
那么他对检测部分有什么提升呢?对于整体的架构来说,检测并没有改变,其只是把之前的Roi Pooling 改为RoI Align。
一、研究背景
我们之前介绍过,Roi Pooling能够适应候选框大小的不同,输出相同shape的特征,但是了解Roi pooling过程(之前讲过)的小伙伴知道,他在其中需要经过两次取整操作。具体如下
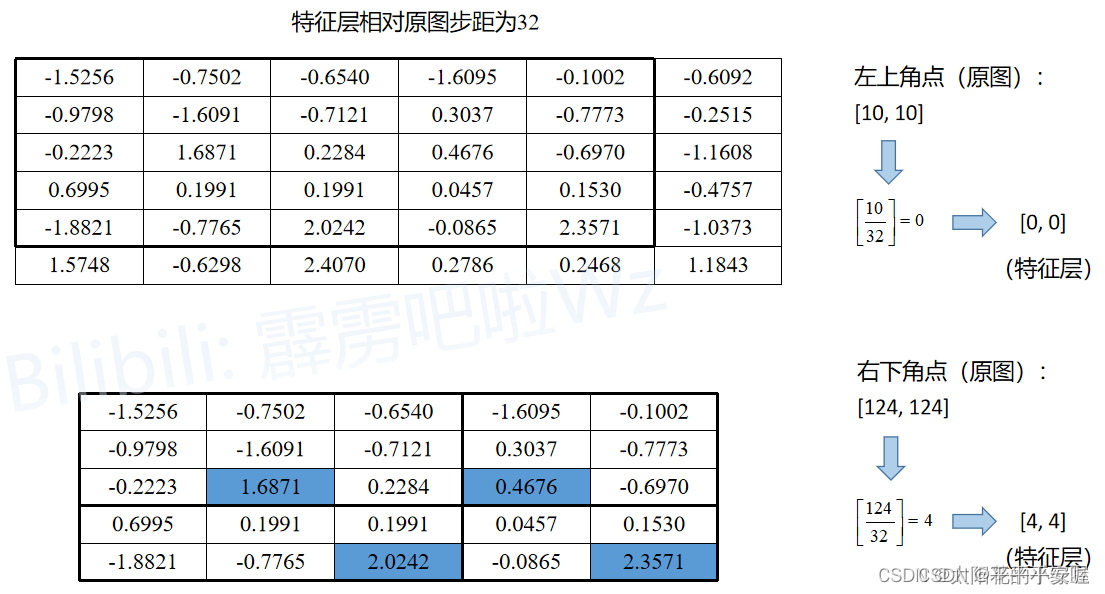
(图源https://blog.csdn.net/qq_37541097/article/details/123754766)
假设我们此时通过RPN得到一个候选框,在原图中左上角的坐标是(10,10),右下角的坐标为(124, 124),总步长假定为32,那么他在映射到特征图上时,会将 10 32 \frac{10}{32} 3210取整为0,将 124 32 \frac{124}{32} 32124取整为4,因此,候选框在特征图上的左上角坐标就为(0,0),在右下角的坐标为(4,4)。这次第一次取整。
而最后我们期望的输出假设为22的,但是候选框在特征图上的大小是55的,无法分割成22,因此,在强行划分后,有的Pooling区域大小为33,有的Pooling区域大小为2*2。这是第二次取整。
两次取整对模型的信息损耗是很大的,因此,作者提出了ROI Align,避免二次取整问题,候选框以获得更精确的空间特征信息。
二、算法流程
在检测方面,Mask R-CNN只有ROI Pooling改为了ROI Align,因此这里只介绍ROI Align。
Roi Align
直接看文中给的这个图会更让人容易理解些,可以看到,第一,候选框没在坐标点上就不在坐标点上无所谓,第二,需要Pooling的分割依旧是按照同样大小去分,那么这样他要如何Pooling呢?

文中是在每个区域,取四个点,每个点都是在其四分之一区域的中心,那么每个点的值该怎么算呢?
每个点,找到他邻近的四个具有数值的像素(如图所示),然后利用双线性插值,将这个点的值给求出来。双线性插值不是本节需要讲的内容,不过多阐述。
为此,每个Pooling区域的四个点都利用双线性插值得到一个值,然后对于每个Pooling区域再进行max Poolling or ave Pooling,最终就能求出我们想要的2*2的特征大小了。
三、实验结果
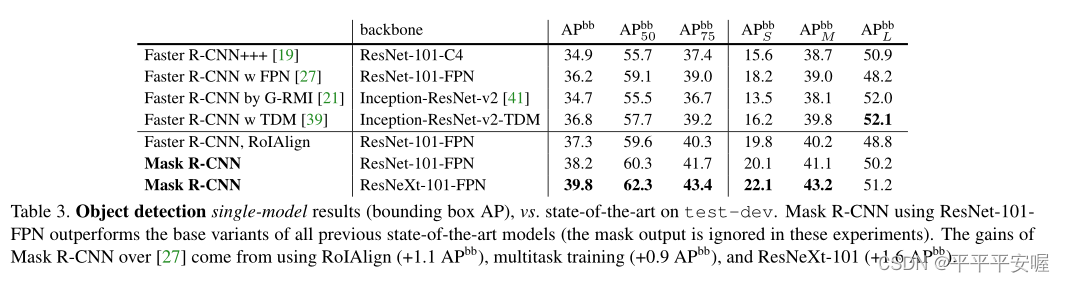
如图,具有RoIAlign的效果会好很多,现在大部分好像基本都是用RoIAlign了。
文章暂时告一段落,以下是参考文献
参考文献
[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[2] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
[3] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
[4] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28.
[5] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









