






导读:本文是“数据拾光者”专栏的第四十五篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇从业务实践的角度分享NLP各任务的baseline,对于希望又快又好的解决实际业务中的NLP相关业务的小伙伴可能有所帮助
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇从业务实践的角度分享NLP各任务的baseline。首先介绍背景以及CLUE社区提供的NLP公共数据集;然后分别介绍了NLP各子任务的公共数据集、技术方案以及实践源码,主要包括文本分类任务、文本匹配任务、关键词识别任务、自动标题任务和图像描述生成任务。对于希望又快又好的解决实际业务中的NLP相关业务的小伙伴可能有所帮助。
下面主要按照如下思维导图进行学习分享:

01
背景介绍
已经工作了有些年头了,一直在思考一个问题:什么是公司真正需要的人?一个越来越清晰的答案是公司需要的是能又快又好的解决问题的人。要满足这项要求,不仅需要一定的技术深度,还需要一定的技术广度,而不是把自己紧紧的锁在某个点上。虽然我主要是做NLP相关工作,但是也会偶尔接一些CV相关的需求,这时候就需要有一定技术的广度。
就拿NLP来说,公司会有很多复杂的场景应用到NLP相关的技术,可以是文本分类、文案生成、文本匹配,或者自动标题等其他任务。面对复杂多变的应用场景,最重要的是能快速得到一个效果还不错的baseline,有了baseline之后就可以快速进行迭代优化,从而又好又快的解决问题。基于这种思考,本文整理一份NLP各子任务的baseline清单,从理论到实践解决各类NLP相关的问题。本文借鉴苏神的bert4keras开源项目整理NLP各子任务的baseline清单,主要包括文本分类任务、文本匹配任务、阅读理解+实体识别任务、成语理解任务、自动标题任务和图像生成描述任务等。
NLP各子任务中大部分使用的公开数据集是CLUE社区提供的,关于CLUE任务集列表如下图所示:
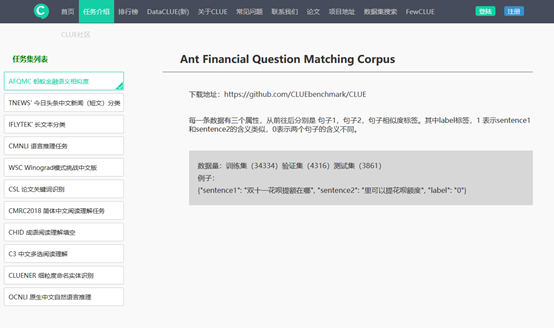
图1 CLUE社区任务集列表
下文中baseline使用的大部分公共数据集也可以通过CLUE进行下载,CLUE官方地址如下:
https://www.cluebenchmarks.com/index.html
02
文本分类任务
文本分类任务是NLP中最常见的任务,也是实际工作中使用最多的任务。之前在知乎上看到有还在学校的小伙伴提问:研究NLP哪一个方向最容易找到工作?那么文本分类任务是一个很不错的方向,虽然相比于其他NLP任务来说文本分类是比较简单的,但是要足够深足够广也不容易。我们线上使用文本分类任务的场景主要有数据源内容理解、商店舆情、小B助手红线模型等等。
2.1 数据集介绍
文本分类任务相关的公开数据集主要有IFLYTEK、TNEWS和WSC,下面会结合数据集一起介绍文本分类任务。
(1) IFLYTEK
IFLYTEK数据集主要是关于app描述的长文本数据,量级为1.7W条。数据以json格式进行存储,主要包括三个字段:sentence、label和label_des,其中sentence是app描述,也是需要识别的文本数据,label是标签id,label_des是标签描述,下面是数据展示:

图2 IFLYTEK数据展示
构建文本分类任务其实就是根据文本sentence来打标,得到对应的分类结果label,所以最重要的就是得到sentence和label,本代码中主要使用的也是这两个字段。
(2) TNEWS
TNEWS数据集是今日头条新闻版块提供的,主要包含旅游、教育、金融、军事等15个类别的新闻,字段和IFLYTEK类似,这里不再赘述。
(3) WSC
WSC数据集是一类代词消除歧义的任务,根据数据集示例来解释更容易理解:

图3 WSC数据展示
WSC数据集是识别文本text中的代词到底代表的是啥,比如上面示例的数据“它们”(text中位置为27和28的中文字符)代表的是“伤口”(text中位置为3和4的中文字符)。可以将代词消除歧义任务转化成文本分类任务,只需要将文本text转化成如下的形式“裂开的_伤口_涂满尘土,里面有碎石子和木头刺,我小心翼翼把_[它们]_剔除出去”,这里将“伤口”和“它们”添加了特殊符号进行标志。还有个重要的字段是label,如果“它们”代表“伤口”,则label为True,否则为False。上面示例中“它们”不是代表伤口,所以label为false。
2.2 方案介绍
目前主流使用的是基于预训练模型比如BERT等进行文本分类任务,整体流程如下图所示:
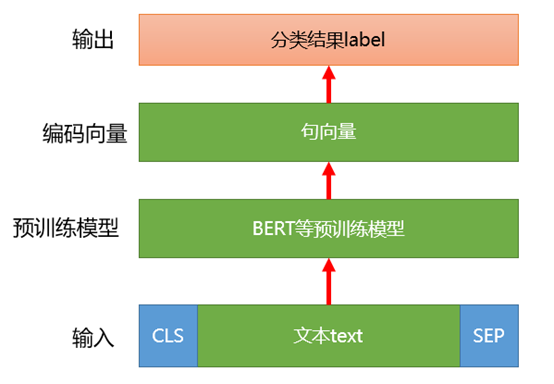
图4 基于BERT构建文本分类流程
对于文本分类任务来说,首先是输入流程,BERT会给输入文本text分别拼接开始标志CLS和结束标志SEP;然后是预训练流程,可以使用BERT等预训练模型,这里可以使用Google等公开的预训练模型,也可以使用业务上下游相关的数据训练模型。不同的预训练模型带来的分类效果差异较大,建议使用RoBERTa-wwm-ext预训练模型,至于为什么效果好可以参考之前写过的一篇文章《广告行业中那些趣事系列18:RoBERTa-wwm-ext模型为啥能带来线上效果提升?》;接下来是获取编码向量流程,也就是得到句向量embedding表示。经过BERT预训练模型之后可以得到字粒度和语句粒度的向量表示,假如输入“传奇游戏好玩么”,因为拼接了CLS和SEP所以有9个字符,从字粒度来说就会得到9X768矩阵,这里768是BERT模型设置的字向量维度。而语句粒度的向量表示是1X768维度的向量。BERT论文作者建议使用CLS对应的向量作为句向量,经过业务实践更推荐使用第一层Transformer和最后一层Transformer得到的字向量累加之后再取均值操作,这么做的原因是对文本进行tokenembedding词编码之后第一层Transformer得到的embedding向量包含更多的词向量信息,最后一层Transformer之后的embedding向量包含更多语句向量信息,将两者累加之后可以最大程度上保留词和语句的向量信息;最后是输出分类结果流程,一般是接一个softmax层得到分类结果。
2.3 实践源码
可以直接基于bert4keras开源项目构建文本分类任务,直接使用iflytek数据集,下面是源码实践:
https://github.com/bojone/CLUE-bert4keras/blob/master/src/iflytek.py
03
文本匹配任务
文本匹配任务是识别两句话是否相似,在实际工作场景中也应用比较广泛,比如搜索场景中相似query识别、小布助手知识问答以及query-app/H5_ad匹配等任务场景中。文本匹配任务主要需要两句话sentence1和sentence2以及对应的标签label。
3.1 数据集介绍
文本匹配任务公开的数据集主要有AFQMC、CMNLI、OCNLI和C3等。
(1) AFQMC
AFQMC是蚂蚁金融语义相似度数据集,主要有三个字段,sentence1、sentence2和label,如果sentence1和sentence2是语义相似的,则label为1,否则为0。

图5 AFQMC数据集示例
(2) CMNLI
CMNLI 和AFQMC类似,只不过label有三类,分别是neutral(中立)、entailment(相关)和contradiction(不相关),这里不再赘述。
(3)OCNLI
OCNLI,即原生中文自然语言推理数据集,是第一个非翻译的、使用原生汉语的大型中文自然语言推理数据集,数据示例如下图所示:

图6 OCNLI数据集示例
其中level代表样本难度,主要包括easy,medium和 hard三个级别;label是五位标注人员投票得到的标注结果,label0-4是五位标注人员分别标注的结果;genre代表文本类别,主要有政府公报、新闻、文学、电视谈话节目、电话转写五类。Baseline代码中主要使用sentence1、sentence2和label三个字段。
(4) CSL
CSL 是中文科技文献数据集,主要包括三个重要字段:abst是论文摘要,keyword是论文关键词,label是识别论文摘要和关键词是否相关。CSL改造成文本匹配任务,将abst作为sentence1,keyword通过分号进行拼接起来作为sentence2,下面是CSL数据集示例:

图7 CSL数据集示例
(5)C3
C3是中文多选阅读理解数据集,将段落、问题question和各个选项进行拼接,构建文本匹配任务,比如下面样本会构建成四条样本:
[1]段落_question_恐怖片0
[2] 段落_question_爱情片0
[3]段落_question_喜剧片1
[4]段落_question_科幻片0

图8 C3数据集示例
3.2 方案介绍
基于BERT构建语句匹配任务和文本分类任务比较类似,区别在于输入流程。文本匹配任务会将两句话通过SEP拼接起来,添加开始标志CLS和结束标志SEP,后面和文本分类流程类似。
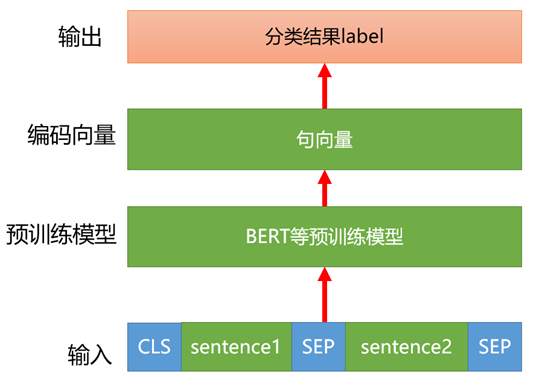
图9 基于BERT构建文本匹配流程
3.3 实践源码
可以直接基于bert4keras开源项目构建文本匹配任务,使用afqmc数据集,下面是源码实践:
https://github.com/bojone/CLUE-bert4keras/blob/master/src/afqmc.py
04
关键词识别任务
关键词识别任务代表一类从语句中识别子片段的任务,这里的子片段可以是实体、有特殊意义的关键词或者阅读理解中的子片段等。对应到我们线上实际的业务主要是关键词标签,这里的关键词是一类pv较高有明显意义的词,比如汽车中的各子品牌,游戏中的角色等等。相比于分类任务来说有固定的标签名,关键词是更细粒度的标签,数量相比于标签也更多。
4.1 数据集介绍
对于关键词识别任务来说公共数据集更多,可以是实体数据集,这里主要介绍CMRC2018数据集,这是简体中文阅读理解任务数据集,需要从一段文本中根据问题找到对应的答案,这里的答案是段落中的一个子片段,下面是CMRC2018数据集示例:
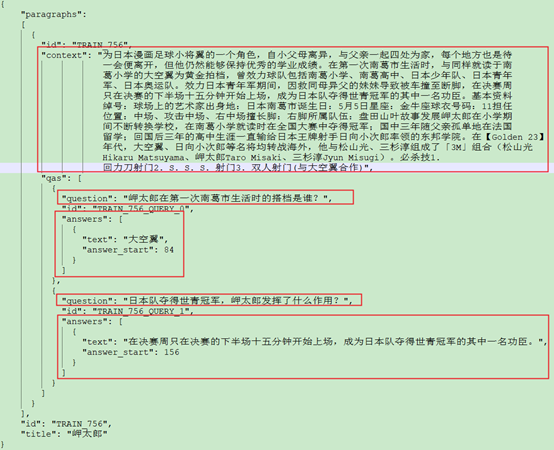
图10 CMRC2018数据集示例
CMRC2018数据集中重要的字段有三个:第一个是context,这是段落文本字段。第二个字段是question,也就是阅读理解的问题。第三个字段是answers,这是问题的答案。
4.2 方案介绍
基于BERT构建关键词识别任务,因为识别的结果主要是段落的子片段,常规做法是基于BERT+CRF的结构。苏神提出了一种BERT+GlobalPointer结构,用统一的方式来处理嵌套和非嵌套NER,下面是方案图:
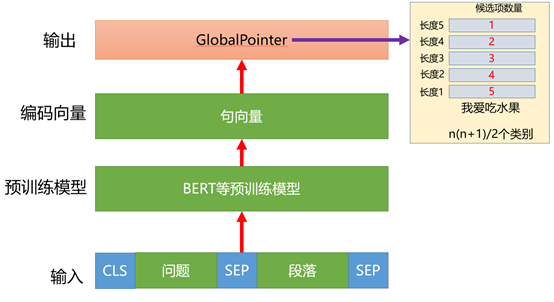
图11 基于BERT+GlobalPointer构建关键词识别流程
从上图可以看出,输入是将问题和段落拼接起来,中间的预训练模型和编码向量不变,最后输出使用GlobalPointer结构。关于GlobalPointer通俗易懂的理解就是将NER任务转化成了分类任务。举例说明,如果需要识别的文本是”我爱吃水果”,对应的答案是文本的子片段“水果”。因为答案是文本的子片段,那么候选答案可能是长度1-5的字符,如果长度为1那么有5个候选项,分别是“我”、“爱”、“吃”、“水”、“果”,如果长度为2那么有4个候选项,以此类推,总共有15个候选项,也就是n(n+1)/2个候选项。这种方式相比于CRF结构来说是从全局的角度来识别关键词,效果相比于CRF也有不错的提升。
4.3 实践源码
可以直接基于bert4keras开源项目构建关键词识别任务,使用cmrc2018数据集,下面是源码实践:
https://github.com/bojone/CLUE-bert4keras/blob/master/src/cmrc2018.py
05
其他NLP任务
5.1 自动标题任务
自动标题任务是指根据一段文本生成另一段文本,是典型的seq2seq2任务。线上应用的场景有广告文案自动生成,这块之前写过一篇文章详细介绍文案生成方案,感兴趣的小伙伴可以查看《广告行业中那些趣事系列29:文案生成之路-基于BERT构建文案生成模型》
基于bert4keras开源项目构建自动标题任务主要有以下两个源码实践:
基于UNILM构建Seq2Seq模型的例子:
https://github.com/bojone/bert4keras/blob/master/examples/task_seq2seq_autotitle.py
基于Conditional Layer Normalization的条件文本生成模型的例子:
https://github.com/bojone/bert4keras/blob/master/examples/task_conditional_language_model.py
5.2 图像描述生成任务
图像描述生成任务属于CV和NLP相结合的任务,主要是根据图片生成对应的描述,这块之前也写过一篇文章详细介绍,感兴趣的小伙伴可以查看《广告行业中那些趣事系列27:围观机器学习是怎么解决“看图说话”任务》
基于bert4keras开源项目构建图像描述生成任务可以参考源码实践:
https://github.com/bojone/bert4keras/blob/master/examples/task_seq2seq_autotitle.py
06
总结及反思
本篇从业务实践的角度分享NLP各任务的baseline。首先介绍背景以及CLUE社区提供的NLP公共数据集;然后分别介绍了NLP各子任务的公共数据集、技术方案以及实践源码,主要包括文本分类任务、文本匹配任务、关键词识别任务、自动标题任务和图像描述生成任务。对于希望又快又好的解决实际业务中的NLP相关业务的小伙伴可能有所帮助。
07
参考资料
[1] https://github.com/bojone/bert4keras
[2] https://github.com/CLUEbenchmark/CLUE
[3] 苏剑林. (May. 01, 2021). 《GlobalPointer:用统一的方式处理嵌套和非嵌套NER 》[Blog post]. Retrieved from https://www.kexue.fm/archives/8373
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们点赞和分享。














 3879
3879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









