







文章目录
- 语言模型
- 统计语言模型
- 统计语言模型中的平滑操作
- 马尔科夫假设
- 语言模型评价指标:困惑度(Perplexity)
- 词的表示方法 - One Hot(独热编码)
- 词的表示方法 - Distributed(分布式表示/稠密表示)
- 共现(co-occurrence)矩阵
- SVD分解 (奇异值分解Singular Value Decomposition)
- 前馈神经网络语言模型NNLM(Feedforward Neural Net Language Model)
- 循环神经网络语言模型RNNLM(Recurrent Nerual Net Language Model)
- Log-linear Model
- 哈夫曼树(Huffman Tree)
- 逻辑回归(Logistic Regression)
- exp()
本来旨在对概念有个基本了解,方便听课时不至于像天书一样。
建议关注,此文会持续更新~ 预计每晚11-12点更新。
语言模型
LM的目的是为一个句子或词序列赋予一个概率。
LM预测下一个词的概率,也就是说它预测下面最有可能出现的一个词。
任何一个具有上面任务的模型称为语言模型。
如word2vec通过当前词预测上下文词,或通过上下文词预测当前的目标词。
统计语言模型
统计语言模型是自然语言处理(Natural Language Processing,NLP)的基础模型,是从概率统计角度出发,解决自然语言上下文相关的特性的数学模型。统计语言模型的核心就是判断一个句子在文本中出现的概率
详细可以看这个https://blog.csdn.net/foneone/article/details/102832347
统计语言模型中的平滑操作
有一些次或者词组在预料中没有出现过,但这不代表它不能存在。
平滑操作就是给那些没有出现过的词或者词组也给出一下比较小的概率。
Laplace smoothing也称为加1平滑:每个词在原来出现的次数的基础上加1 (缺点:参数空间过大,数据稀疏严重)
马尔科夫假设
下面一个词的出现仅仅依赖前面的一个或几个词
语言模型评价指标:困惑度(Perplexity)
给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好
句子概率越大,语言模型越小,困惑度越小。
详细可参考这里
词的表示方法 - One Hot(独热编码)
Word Representation - One Hot Representation
一个向量里面只有一个地方是1,其余地方是0
缺点:
- 词越多,维度越高
- 无法表示词与词之间的关系
词的表示方法 - Distributed(分布式表示/稠密表示)
共现(co-occurrence)矩阵
参考
主要用于发现主题,解决词向量相近关系的表示
将共现矩阵行(列)作为词向量
例如:语料库如下:
• I like deep learning.
• I like NLP.
• I enjoy flying.
则共现矩阵表示如下:(使用对称的窗函数(左右window length都为1) )
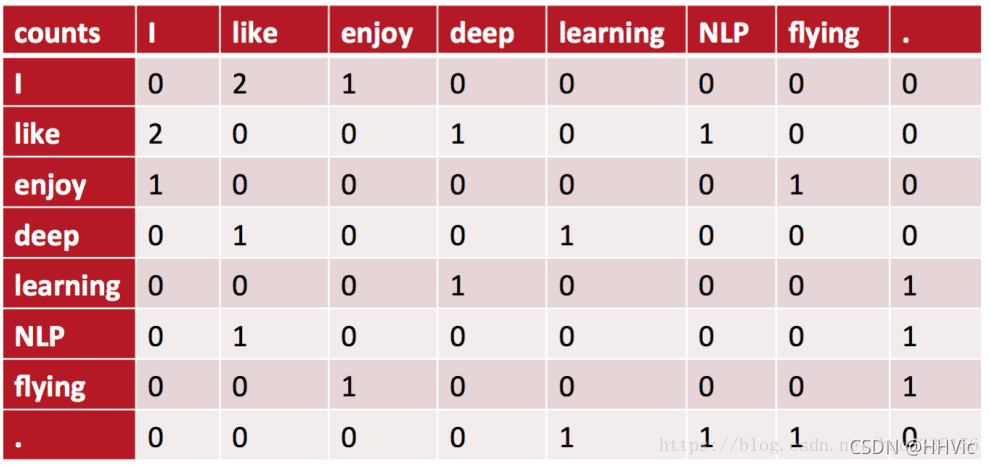
例如:“I like”出现在第1,2句话中,一共出现2次,所以=2。
对称的窗口指的是,“like I”也是2次
将共现矩阵行(列)作为词向量表示后,可以知道like,enjoy都是在I附近且统计数目大约相等,他们意思相近
共现矩阵不足:
面临稀疏性问题、向量维数随着词典大小线性增长
解决:SVD、PCA降维,但是计算量大
SVD分解 (奇异值分解Singular Value Decomposition)
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个m×n的矩阵,那么我们定义矩阵A的SVD为:
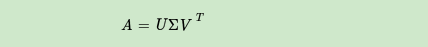
优点: 可以一定程度上得到词与词之间的相似度
缺点:矩阵太大,SVD矩阵分解效率低,学习得到的词向量可解释性差
前馈神经网络语言模型NNLM(Feedforward Neural Net Language Model)
NNLM是从语言模型出发(即计算概率角度),构建神经网络针对目标函数对模型进行最优化,训练的起点是使用神经网络去搭建语言模型实现词的预测任务,并且在优化过程后模型的副产品就是词向量。
进行神经网络模型的训练时,目标是进行词的概率预测,就是在词环境下,预测下一个该是什么词,目标函数如下式, 通过对网络训练一定程度后,最后的模型参数就可当成词向量使用.
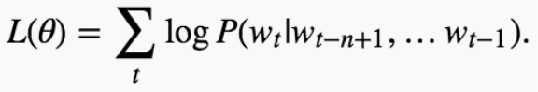
过程如下图:
输入层:将词映射成向量,相当于
1
1
1x
V
V
V的one-hot向量乘以一个
V
V
Vx
D
D
D的向量得到一个
1
1
1x
D
D
D的向量。
隐藏层:一个以
t
a
n
h
tanh
tanh为激活函数的全连接层
a
=
t
a
n
h
(
d
+
U
x
)
a=tanh(d+Ux)
a=tanh(d+Ux)
输出层:一个全连接层,后面接一个softmax函数来生成概率分布。其中
y
y
y是一个
1
1
1x
V
V
V的向量:
P ( W t ∣ W t − n + 1 , . . . , W t − 1 ) = e x p ( y w t ) / ∑ i e x p ( y i ) P(W_t|W_{t-n+1}, ..., W_{t-1})=exp(y_{w_t})/\sum_i exp(y_i) P(Wt∣Wt−n+1,...,Wt−1)=exp(ywt)/i∑exp(yi)
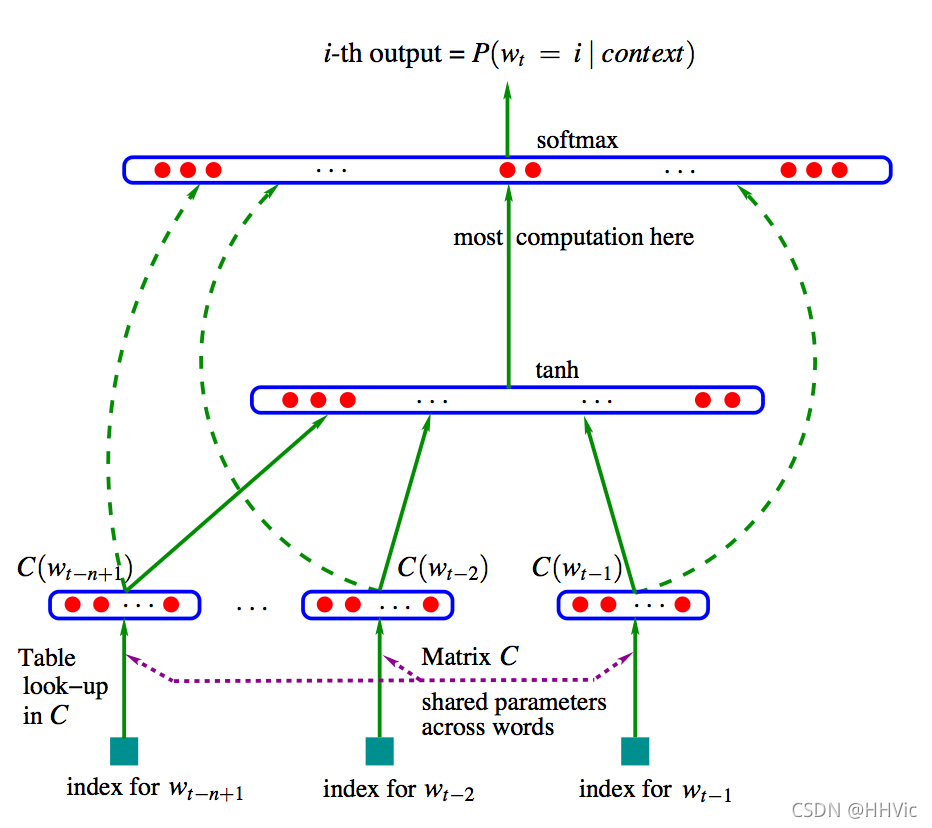
由于NNLM模型使用了低维紧凑的词向量对上文进行表示,这解决了词袋模型带来的数据稀疏、语义鸿沟等问题。显然nnlm是一种更好的n元语言模型;另一方面在相似的上下文语境中,nnlm模型可以预测出相似的目标词,而传统模型无法做到这一点。
循环神经网络语言模型RNNLM(Recurrent Nerual Net Language Model)
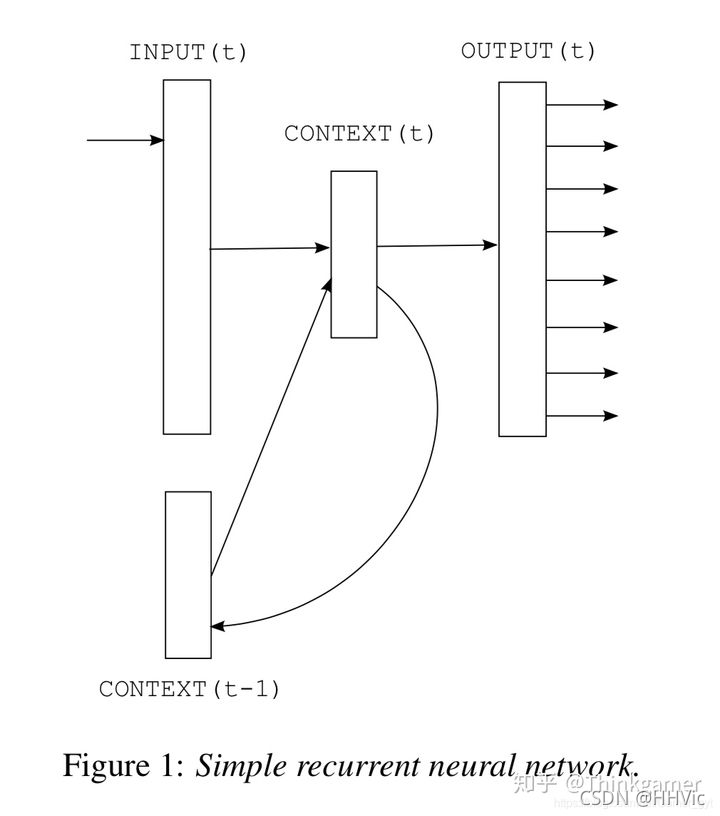
循环神经网络语言模型(RNNLM)是想要解决前馈神经网络模型窗口固定的问题。其次,前馈神经网络模型假设每个输入都是独立的,但是这个假设并不合理。循环神经网络的结构能利用文字的这种上下文序列关系,更好地对语句之间的关系进行建模。在某种程度上也能很好地进行上下文的联系,但由于RNN可能有的长距离梯度消失问题,这个上下文的记忆能力也是有限的。
过程如下图:
输入层:和NNLM一样,需要将当前时间步的转化为词向量
隐藏层:对输入和上一个时间步的隐藏输出进项全连接操作:
s
(
t
)
=
U
w
(
t
)
+
W
s
(
t
−
1
)
+
d
s(t)=U w(t)+W s(t-1)+d
s(t)=Uw(t)+Ws(t−1)+d
输出层:一个全连接层,后面接一个softmax函数来生成概率分布。
y
(
t
)
=
b
+
V
s
(
t
)
y(t)=b+V s(t)
y(t)=b+Vs(t)
其中 y y y是一个 1 1 1x V V V的向量:
P
(
W
t
∣
W
t
−
n
+
1
,
.
.
.
,
W
t
−
1
)
=
e
x
p
(
y
w
t
)
/
∑
i
e
x
p
(
y
i
)
P(W_t|W_{t-n+1}, ..., W_{t-1})=exp(y_{w_t})/\sum_i exp(y_i)
P(Wt∣Wt−n+1,...,Wt−1)=exp(ywt)/i∑exp(yi)
RNNLM优缺点
优点:
可以处理任意长度的输入
理论上可以追溯前面时间步的信息
模型参数大小固定,与输入长度无关
缺点:
计算时间长
实际应用中,难以追溯很久远的时间步的信息
Log-linear Model
将语言模型的建立看成是一个多分类问题,相当于线性分类器加上softmax。
Y
=
s
o
f
t
m
a
x
(
w
x
+
b
)
Y=softmax(wx+b)
Y=softmax(wx+b)
例如:多分类下的逻辑回归模型 Logistic模型
Word2vec里面的skip-gram以及CBOW模型都属于此模型
哈夫曼树(Huffman Tree)
哈夫曼树是一种带权路径长度最短的二叉树,也称为最优二叉树。下面用一幅图来说明:
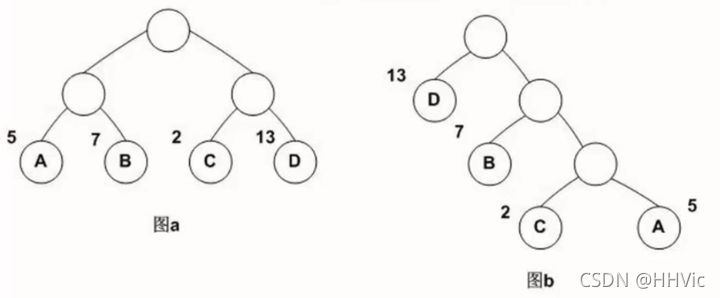
图a中的数字表示权重,图a是常见的二叉树,图b就是图a转换过的最优二叉树。
图a中权重表示重要程度,可以看出,D是最重要的,那么有这样一个规则:最重要的放在最前面,由此构造了图b的哈夫曼树。
它们的带权路径长度分别为:
图a:WPL = 5 * 2 + 7 * 2 + 2 * 2 +13 * 2 = 54
图b:WPL = 5 * 3 + 2 * 3 + 7 * 2 + 13 * 1 = 48
可见,图b的带权路径长度较小,我们可以证明图b就是哈夫曼树。
例如:有A B C D 四个词,数字表示词频,构造过程如下
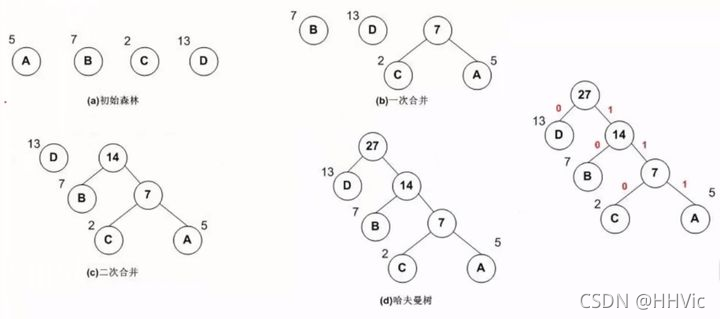
哈夫曼树编码
左子树为0,右子树为1
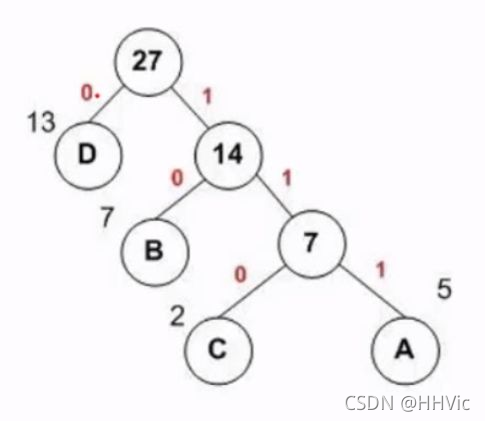
那么D编码为0,B编码为10,C编码为110,A编码为111。
逻辑回归(Logistic Regression)
Logistic Regression的思想很简单,利用Sigmoid函数把任意值映射到(0,1)的区间上来实现分类问题(主要是二分类)
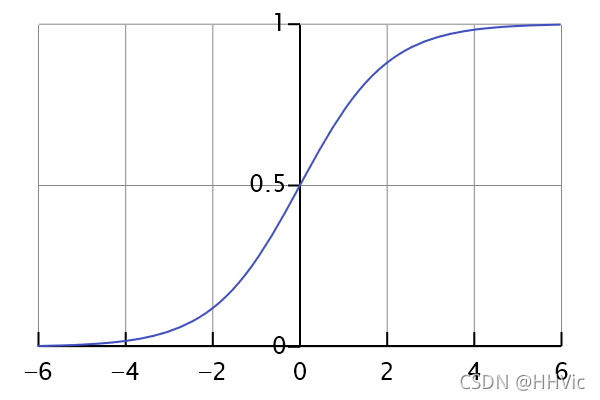
exp()
高等数学里指以自然常数e为底的指数函数。
这里的e是数学常数,就是自然对数的底数,近似等于 2.718281828,还称为欧拉数。














 2054
2054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









