






导读:本文是“数据拾光者”专栏的第八十八篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本文主要从理论到实践详细介绍了NLP中常见的NER任务。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
01 NER任务介绍
1.1 NER定义
命名实体识别(Named Entity Recognition,简称NER),也称作“专名识别”,是自然语言处理(NLP)中的一项基础任务。NER的目标是从文本中识别出具有特定意义的实体,并将其分类到预定义的类别中。这些实体通常包括人名、地名、机构名、日期时间、专有名词等。
NER的发展历程从早期基于规则和词典的方法,发展到基于统计机器学习的方法,再到近年来基于深度学习的方法。目前,条件随机场(Conditional Random Field,CRF)是NER的主流模型之一,它在标注过程中可以利用丰富的内部及上下文特征信息。
NER的应用非常广泛,它是关系抽取、事件抽取、知识图谱、信息提取、问答系统、句法分析、机器翻译等NLP任务的基础。NER系统能够从非结构化的输入文本中抽取出实体,并且可以按照业务需求识别出更多类别的实体,如产品名称、型号、价格等。
在实际应用中,NER面临的挑战包括多义词与上下文依赖、新词与未登录词、领域特定的NER以及语言与文化差异等。为了解决这些挑战,NER技术不断进化,包括增强的上下文理解、多语言NER的进展以及NER与知识图谱的结合。
NER的实现方法多样,包括基于规则的方法、机器学习方法和深度学习方法。一些流行的NER工具包括HanLP、CRF++等,它们提供了简单易用的接口来实现NER任务。此外,还有一些NER API,如自然语言工具包(NLTK)、斯坦福命名实体识别器和SpaCy,它们提供了预训练模型和易于使用的接口来提取命名实体。
1.2 三种NER任务
常见的NER任务主要包括以下三种:
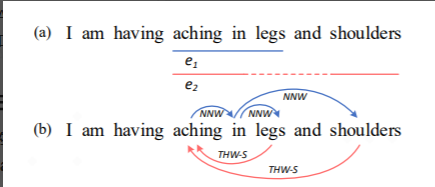
flat NER : 传统的NER任务,简单且扁平的实体抽取,比如从下图中抽取“aching in legs”;
discontinuous NER: 不连续实体任务,比如从下图中抽取“aching in shoulders”
overlapped NER:嵌套实体任务,比如从下图中抽取“aching in legs”“aching in shoulders”和两个实体共同重复了“aching in”。
02 NER发展过程
2.1 基于规则和词典的方法
基于规则和词典的NER系统依赖于手工制定的规则。可以基于领域特定的地名词典语法-词汇模式设计规则。例如模板“播放歌曲${song}”,可以将query=“播放歌曲爷爷泡的茶”中的“爷爷泡的茶”作为歌曲抽取出来。
基于规则和词典的方法通常包括正向最大匹配 、反向最大匹配、双向最大匹配三种:
正向最大匹配:从前往后依次匹配子句是否是词语,以最长的优先。
后向最大匹配:从后往前依次匹配子句是否是词语,以最长的优先。
双向最大匹配原则:覆盖 token 最多的匹配。句子包含实体和切分后的片段,这种片段+实体个数最少的.
该方法主要有以下缺点:高精确、低召回,特定领域手工规则制定困难。
2.2 基于特征统计的有监督学习方法
将NER转换为一个分类问题或序列标记问题,这样能够运用特征工程和模型选择处理NER问题。主要包括隐马尔可夫模型、条件随机场等。
2.3 深度学习NER方法
深度学习中将CNN、RNN与CRF相融合,例如BILSTM-CRF模型、IDCNN-CRF模型:BiLSTM+CRF是2015年提出的,模型结构如下图所示:
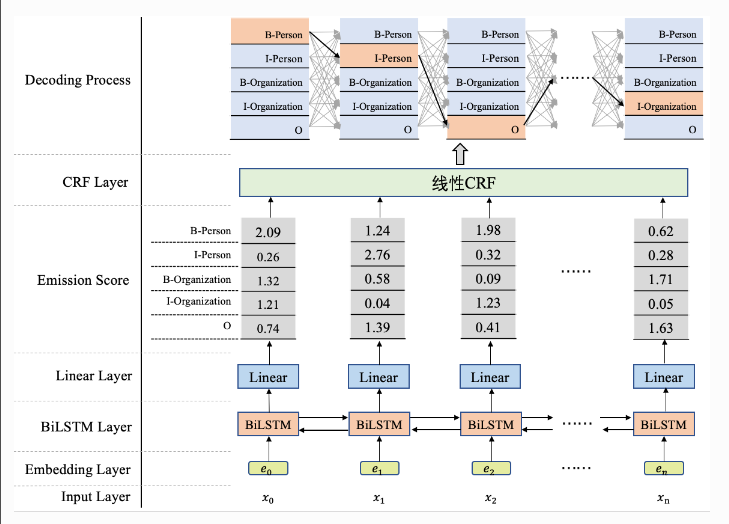
如果没有了CRF层,可以依据概率值进行实体识别,但并不能保证输出是合法的序列,因此这里的CRF层可以加入一些约束来保证最终预测结果是有效的。这些约束可以在训练数据时被CRF层自动学习得到。
2.4 当前具有代表性的NER模型
在原来深度学习算法的基础上引入了BERT模型,比如:BERT-CRF、BERT-BILSTM-CRF。
2.4.1 FLAT 2020
FLAT是2020年ACL的论文,由复旦大学邱锡鹏老师团队提出,该模型在中文NER任务中刷新了SOTA。FLAT的主要创新点在于基于Transformer设计了一种巧妙的position encoding来融合Lattice结构,可以无损地引入词汇信息,并且支持并行化计算,大幅提升推断速度。模型结构如下图所示:
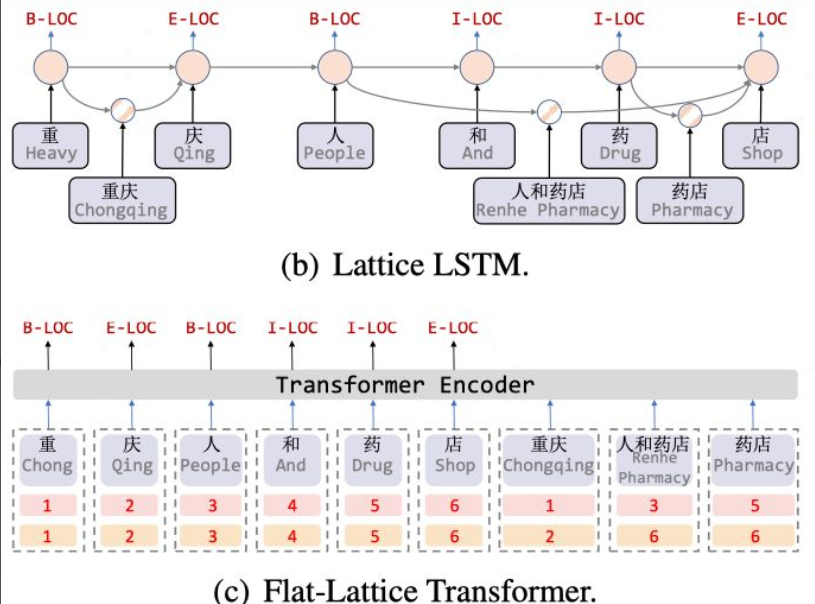
其中Lattice-LSTM存在如下问题:
RNN结构无法捕捉长距离依赖
引入词汇信息是有损的
动态的Lattice结构也不能充分进行GPU并行
FLAT github项目地址如下:https://github.com/LeeSureman/Flat-Lattice-Transformer
2.4.2 BERT-MRC 2020
BERT-MRC是2020年ACL上提出来的,将BERT作为基础模型主干,通过[CLS]和[SEP]将query和context连接起来,进入BERT模型训练,取BERT最后一层的context中字符的对应输出作为最终的输出。 利用pointer对Span选择同时解决overlapped NER与flat ner问题,对输入中的每个token都做一个二分类,来判断其是否为开始位置或者结束位置,这种策略就可以输出多个开始索引和多个结束索引,从而得到多个span。
BERT-MRC github项目地址如下:
代码链接:https://github.com/ShannonAI/mrc-for-flat-nested-ner
2.4.3 Word-Word Relation Classification 2022
Word-Word Relation Classification是2022年AAAI提出的基于超图的方法,这是一个统一的NER模型,它通过将NER任务建模为词-词关系分类问题,能够处理扁平实体、嵌套实体和非连续实体三种NER任务。W2NER在14个中英文数据集上取得了SOTA结果。它主要创新点在于利用统一的Word-Pair标记方式建模不同类型的NER任务,核心思想是通过预测word-word之间的关系解决所有NER问题。word与word之间的关系主要有三种:
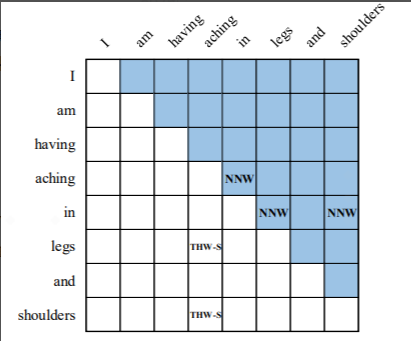
NNW(Next-Neighboring-Word):预测与后面词的关系
THW-*(Tail-Head-Word-*):预测与前面词的关系,其中*表示具体关系(ORG、PER等)
NONE:表示没有关系
论文采用一个多粒度2D图来表示word之间的关系,如下图,其中为了解决图的稀疏性,而将这两种关系放到一个图里,NNW在右上角,THW-*在左下角
模型结构如图所示:

Word-Word Relation Classification结构中主要包括Encoder Layer、Convolution Layer、Co-Predictor Layer、Decoder四部分:
Encoder Layer:通过BERT获取表示信息,然后通过LSTM获取上下文信息。
Convolution Layer:采用CLN(Conditional Layer Normalization)获取word j在word i前提下的表示。后接BERT-style Grid Representation层,这里主要受模型BERT的3个embedding层启发,构建三个表示层分别为信息表示、关系位置信息表示和位置域表示组成,通过MLP融合到一起。之后通过多粒度的空洞卷积采样不同的信息后GeLU激活得到。
Co-Predictor Layer:由两部分组成,一部分是Convolution Layer结果通过MLP的关系表示,另一部分则是Biaffine Predictor得到。Biaffine Predictor的输入来自Encoder Layer,这部分信息的处理方式可以看做特殊的残差网络,这编码信息的处理也相对简单;
Decoder:主要是通过NNW和HTW-*构成一个环的部分就是一个实体。利用NNW关系找到图中从一个词到另一个词的某些路径。每条路径都对应于一个实体提及。除了用于NER的类型和边界识别,THW关系也可以作为消歧义的辅助信息,如图所示:
Word-Word Relation Classification模型刷新了14个广泛测评的中英基准数据集新SOTA,下面是模型在中文数据集上的F1表现:

Word-Word Relation Classification的github项目地址如下:
代码链接:https://github.com/ljynlp/W2NER
2.4.4 RICON 2022
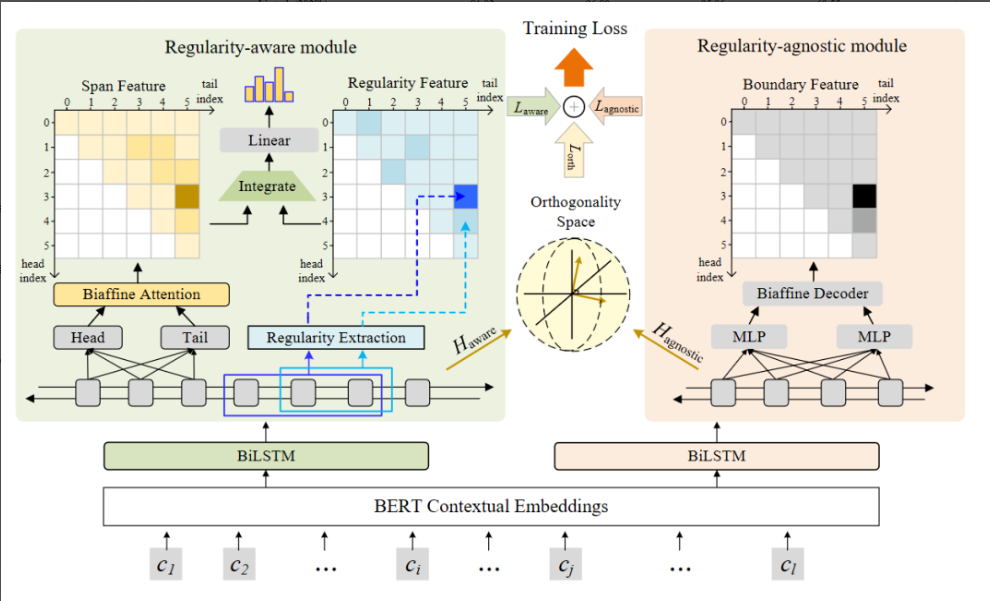
RICON是华为云研发团队在2022年在NAACL提出来的,该模型旨在抽取中文词汇中的命名规律,如“XX+河”对应地点实体。RICON结合了span-based方法,并通过自注意力层和门控机制强化规律特征。尽管在特定领域如医疗名词识别上有提升,但在开放领域数据上的效果提升不明显。实验表明,RICON在CBLUE-CMeEE数据集上表现优秀,尤其对具有规范后缀的专有名词识别准确率提高。
RICON是基于span的中文命名实体识别模型,结合了常规的span-based学习方法,主要创新点是在构建spanrepresentation过程中引入了规律信息。下面是模型结构图:
2.4.5 Global Pointer 2022
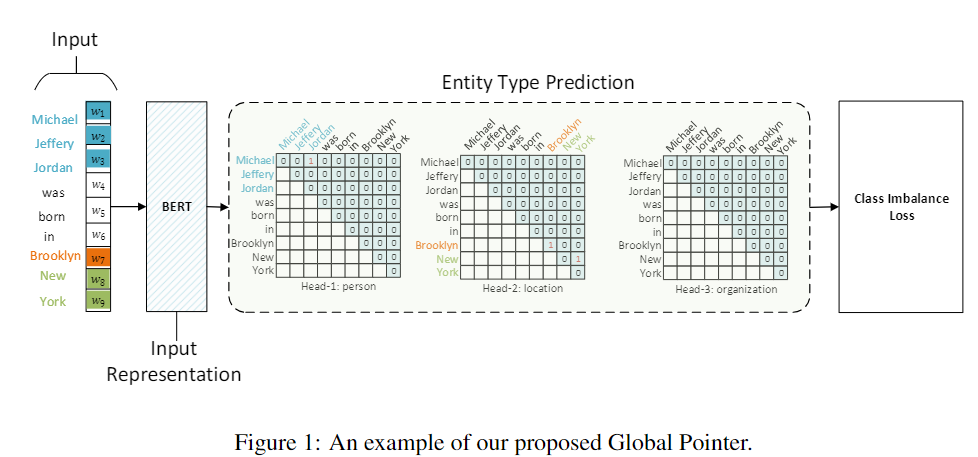
Global Pointer是苏剑林在论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》中提出来的,利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是O(1)。下面是使用Global Pointer的一个例子:
Global Pointer项目的github地址如下:https://github.com/bojone/bert4keras
03 NER常用的数据集
3.1 NER相关数据集特点
一般来说,不同的NER任务会有不同的Tags,下面介绍两种常见的tag标注方式:
BIO (B-begin,I-inside,O-outside)
BIOES(B-begin,I-inside,O-outside,E-end,S-single)
其中,B开始位置、I 中间位置、O 其他类别、E表示结束位置、S 单字表示一个实体;
3.2 常用中文数据集
NER任务常用中文数据集主要有以下几种:
ontoNotes4.0_ner:包含18种实体类别;
msra_ner:MSRA微软亚洲研究院开源数据,包含训练集(46364)、测试集(4365),实体类型包括地名(LOC)、人名(NAME)、组织名(ORG),数据源自新闻领域;
people_dairy_ner:由人民日报语料库1998版和2014版生成,包含了人名(PER)、地名(LOC)和机构名(ORG)3类常见的实体类型;
Weibo_ner:2015年微博中文数据集,包含训练集(1350)、验证集(269)、测试集(270),实体类型包括地缘政治实体(GPE.NAM)、地名(LOC.NAM)、机构名(ORG.NAM)、人名(PER.NAM)及其对应的代指(以NOM为结尾);
Resume_ner:2018年挖掘新浪财经获得,收录了中国股市公司精英的简历,包含8种实体类型:姓名,组织,职位,教育背景,地点等;
clue_ner:细粒度命名实体识别数据集,数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene);
简历命名实体识别数据集:包含训练集(3821)、验证集(463)、测试集(477),实体类型包括国籍(CONT)、教育背景(EDU)、地名(LOC)、人名(NAME)、组织名(ORG)、专业(PRO)、民族(RACE)、职称(TITLE)等9种实体;
中文医学命名实体识别数据集CMeEE:包含训练集15,000条,验证集5,000条和测试集数据3,000条。数据集包含504种常见的儿科疾病、7,085种身体部位、12,907种临床表现、4,354种医疗程序等九大类医学实体;
Yidu-S4K:医渡云结构化4K数据集:源自CCKS 2019 评测任务一,即“面向中文电子病历的命名实体识别”的数据集,包含训练集1000条,测试集379条,实体类型包括6种;
Youku NER Dataset / 文娱NER数据集:由阿里巴巴达摩院和新加坡科技设计大学联合提供,包含训练集8001条、验证集1000条、测试集1001条,包括娱乐明星名、影视名、音乐名等类别;
E-Commercial NER Dataset / 电商NER数据集:同样由阿里巴巴达摩院和新加坡科技设计大学联合提供,包含训练集6000条、验证集998条、测试集1000条,包括商品名称、商品型号、人名、地名等类别;
CLUENER2020:基于清华大学开源的文本分类数据集THUCNEWS,选出部分数据进行细粒度命名实体标注,并对数据进行清洗,得到一个细粒度的NER数据集
BOSON数据集 - boson:由玻森中文语义开放平台提供,共2000句。
这些数据集覆盖了不同的领域和实体类型,为研究人员提供了丰富的资源来训练和评估NER模型。
部分ner相关的数据集可以在下面的github下载:
https://github.com/hspuppy/hugbert/tree/master/ner_dataset
04 上手即用的ner项目
4.1 paddle ner
使用paddle训练ner模型,模型结构主要包含以下几种:

#安装paddle_ner库
pip install paddle_ner#下载数据集
从下面github地址下载人民日报语料处理工具集,将 char_crfpp 格式的 train.txt 和 test.txt 放到 data 目录下:
https://github.com/howl-anderson/tools_for_corpus_of_people_daily
#模型训练
python -m paddle_ner.train#本地调用
from paddle_ner.server import server
result = server("王小明在北京的清华大学读书。")
print(result)输出结果:

4.2 T-NER
这是一个基于Transformer的NER库,它提供了一个简单的接口来微调模型,并在跨领域和多语言数据集上进行测试。T-NER集成了大量公开可用的NER数据集,并支持自定义数据集的轻松集成。所有通过T-NER微调的模型都可以部署在Web应用中进行可视化。T-NER的GitHub仓库提供了详细的安装和使用说明,以及与HuggingFace模型库的集成。
github项目地址如下:https://github.com/asahi417/tner
4.3 Keras NER Example
这是一个使用Transformers进行NER的示例项目,它使用了CoNLL 2003共享任务的数据。这个项目提供了一个完整的教程,包括如何加载数据集、构建模型、训练和评估NER模型。这个示例使用了HuggingFace的datasets库来处理数据,并提供了一个Python脚本用于评估NER模型的性能。
github项目地址如下:https://github.com/keras-team/keras-io/blob/master/examples/nlp/ner_transformers.py
4.4 Stanford NLP
斯坦福NLP提供了一个Java套件,包括分词、句子分割、NER、解析、指代消解、情感分析等功能。它还有一个Python库,可以用于多种人类语言的分词、句子分割、NER和解析。
github项目地址如下:https://github.com/stanfordnlp/CoreNLP
4.5 spaCy
这是一个非常流行的开源自然语言处理库,它提供了多种语言的支持,包括中文。spaCy提供了预训练的模型,可以用于NER以及其他NLP任务。
github项目地址如下:https://spacy.io/api/entityrecognizer
4.6 HanLP
这是一个由一系列模型和算法组成的中文处理库,它支持分词、词性标注、NER等多种任务。
github项目地址如下:https://github.com/hankcs/HanLP
4.7 LAC (Lexical Analysis of Chinese)
由百度开发的中文词法分析工具,支持分词、词性标注、NER等多种任务。
github项目地址如下:https://github.com/baidu/lac
总结
本篇从理论到实践介绍了NLP中常见的基本任务NER。首先介绍了NER定义以及三种不同的NER任务;然后介绍了NER任务的发展过程以及NER常用的数据集;最后从实践角度介绍了NER任务。对于希望在实际业务中构建NER任务的小伙伴可能有帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们关注和分享。

















 3335
3335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









