






1.为什么要对Yuan2.0做微调?
Yuan2.0(https://huggingface.co/IEITYuan)是浪潮信息发布的新一代基础语言大模型,该模型拥有优异的数学、代码能力。自发布以来,Yuan2.0已经受到了业界广泛的关注。当前Yuan2.0已经开源参数量分别是102B、51B和2B的3个基础模型,以供研发人员做进一步的开发。
LLM(大语言模型)微调方案是解决通用大模型落地私有领域的一大利器。基于开源大模型的微调,不仅可以提升LLM对于指令的遵循能力,也能通过行业知识的引入,来提升LLM在专业领域的知识和能力。当前,学界和业界已经基于LLM开发及实践出了众多的微调方法,如指令微调、基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)、直接偏好优化(DPO,Direct Preference Optimization)等。内存和计算资源是制约LLM微调的两大瓶颈,通过使用高效微调(PEFT,Parameter-Efficient Fine-Tuning)方案可以有效缓解上述问题,当前业界已经出现了LoRA和QLoRA等高效微调技术,可以实现在单张GPU上完成千亿参数的微调训练。因此,一个能够实现上述功能的简洁、高效、易用、与时俱进的微调框架是开展LLM微调工作的最佳抓手。
LLaMA-Factory(https://github.com/hiyouga/LLaMA-Factory)是零隙智能(SeamLessAI)开源的低代码大模型训练框架,它集成了业界最广泛使用的微调方法和优化技术,并支持业界众多的开源模型的微调和二次训练,开发者可以使用私域数据、基于有限算力完成领域大模型的定制开发。LLaMA-Factory还为开发者提供了可视化训练、推理平台,一键配置模型训练,实现零代码微调LLM。自2023年5月开源以来,成为社区内最受欢迎的微调框架,github星数已超9K。
目前LLaMA-Factory已完成与Yuan2.0的适配微调,通过使用LLaMA-Factory可以方便快捷的对不同尺寸的Yuan2.0基础模型进行全量微调及高效微调。本文将介绍如何使用alpaca中文数据集、ShareGPT数据集和llama-factory提供的模型认知数据集,对Yuan2.0进行微调,来构建自己的人工智能助手。
2.资源需求评估和环境准备
下面的表格给出了使用llama-factory微调Yuan2.0模型的最低显存需求。大家可以根据手头GPU资源的显存情况来评估使用的模型以及对应的微调算法。比如选择Yuan2.0-2B模型,使用QLoRA微调方法,只需要最小5GB显存,当前业界绝大多数的GPU都可以满足。
表格2‑1:Yuan2.0不同微调策略所需要的最低显存需求评估。
| 微调方法 | Yuan2.0-2B | Yuan2.0-51B | Yuan2.0-102B |
| 全参微调 | 40GB | 1000GB | 2000GB |
| LoRA | 7GB | 120GB | 230GB |
| QLoRA | 5GB | 40GB | 80GB |
Llama-factory的部署可以参考其github上的部署文档,yuan2.0的github上也提供了完整的llama-factory的环境部署流程(https://github.com/IEIT-Yuan/Yuan-2.0/blob/main/docs/Yuan2_llama-factory.md)可供参考。在本文的部署实践中,使用了ngc-torch2308作为基础docker镜像。
3.Yuan2.0 Lora微调Step by step流程
下面以Yuan2.0-2B模型的LoRA微调为例,进行step by step的流程介绍。
Step by Step ,yuan2.0模型微调演示demo
- step1:基于torch2308镜像启动容器,可以映射容器内的7860端口到宿主机,以便后期微调及推理测试使用;克隆llama-factory项目,使用pip清华源,按照如下命令安装相关依赖。
-
cd /workspace/sa/LLM_test/LLaMA-Factory-main
-
vim src/train_web.py
-
-
-
#如下文件内容可以修改server_port为自己映射的端口
-
-
from llmtuner import create_ui
-
def main():
-
demo = create_ui()
-
demo.queue()
-
demo.launch(server_name=
"0.0.0.0",server_port=6666, share=False, inbrowser=True)
-
if __name__ ==
"__main__":
-
main()
-
-
#使用如下命令在终端启动web服务,并在浏览器中打开web界面
-
python src/train_web.py

- step2 :获取yuan2.0 huggingface模型,微调使用的huggingface模型可以在给出链接中获取。

- step3: 启动Web UI服务,训练自己的私有大模型智能助手。我们将使用llama-factory内置的中文数据集(GPT-4优化后的alpaca中文数据集、ShareGPT数据集和llama-factory提供的模型认数据集)完成此次微调。
-
cd /workspace/sa/LLM_test/LLaMA-Factory-main
-
vim src/train_web.py
-
-
#如下文件内容可以修改server_port为自己映射的端口
-
-
from llmtuner
import create_ui
-
def
main():
-
demo = create_ui()
-
demo.queue()
-
demo.launch(server_name=
"0.0.0.0",server_port=
6666, share=
False, inbrowser=
True)
-
if __name__ ==
"__main__":
-
main()
-
#使用如下命令在终端启动web服务,并在浏览器中打开web界面
-
python src/train_web.py
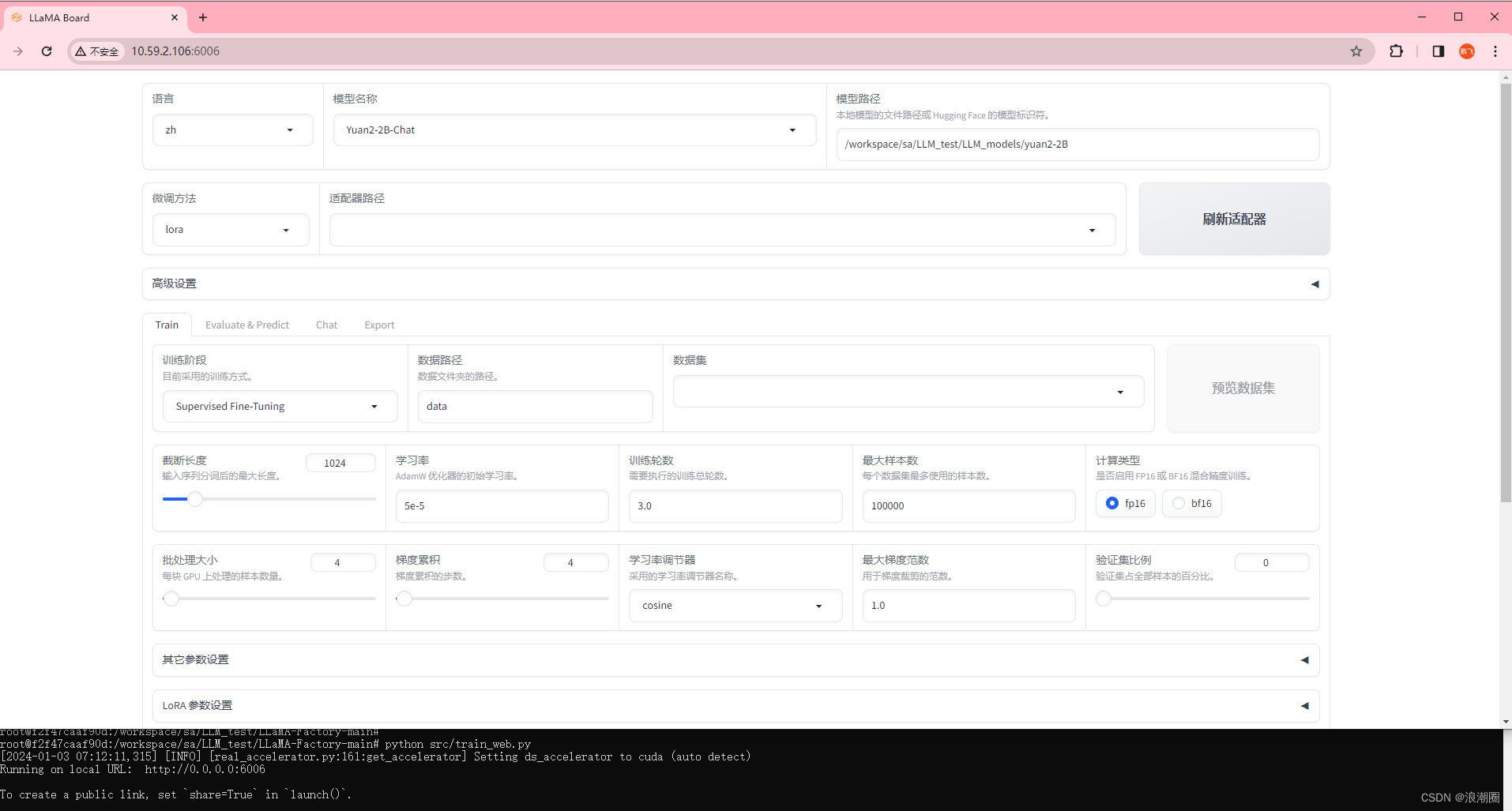
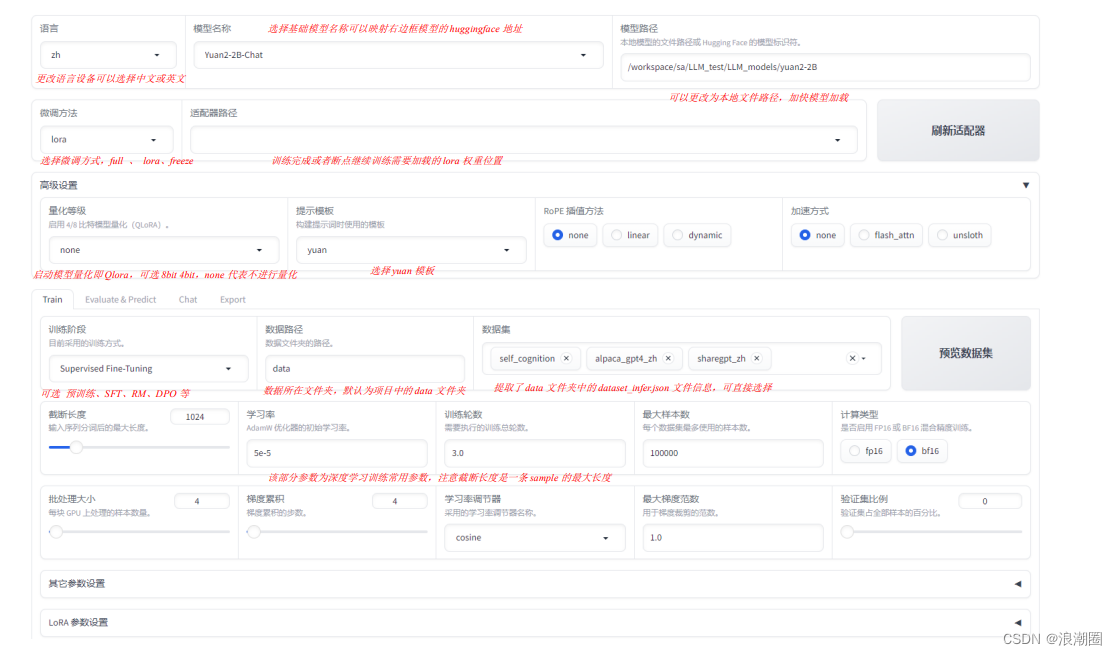
- step4:在web界面上配置参数微调Yuan2.0-2B。如下图为模型、微调方式、数据等的配置样例,具体信息参考图中注释。
(1)模型路径,数据集选择,训练精度,样本截断长度,与训练优化相关的学习率、batchsize等参数的设置
|
|
(2)日志、高效微调lora、模型保存等相关参数配置

(3)命令行执行命令显示
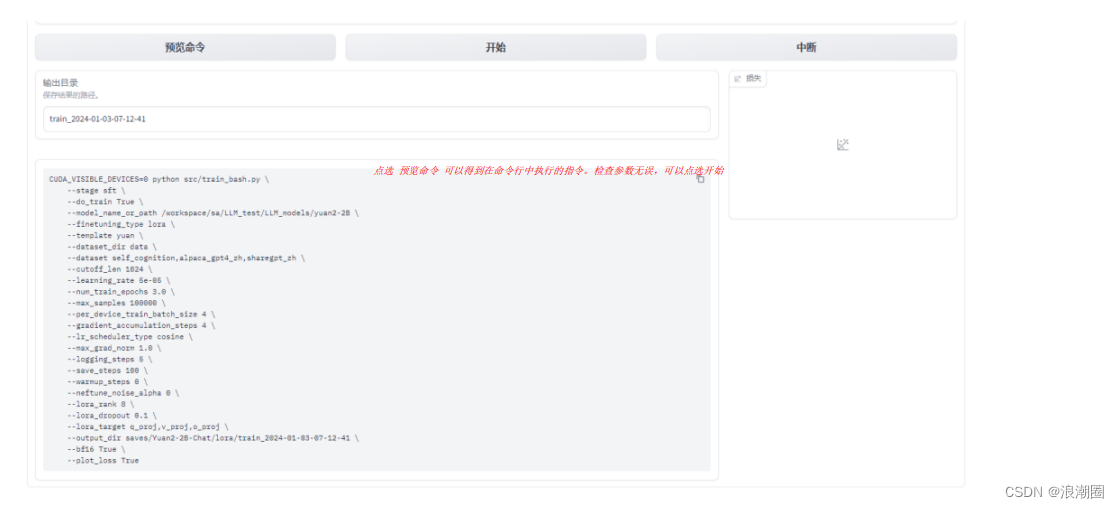
(4)训练日志及loss曲线展示
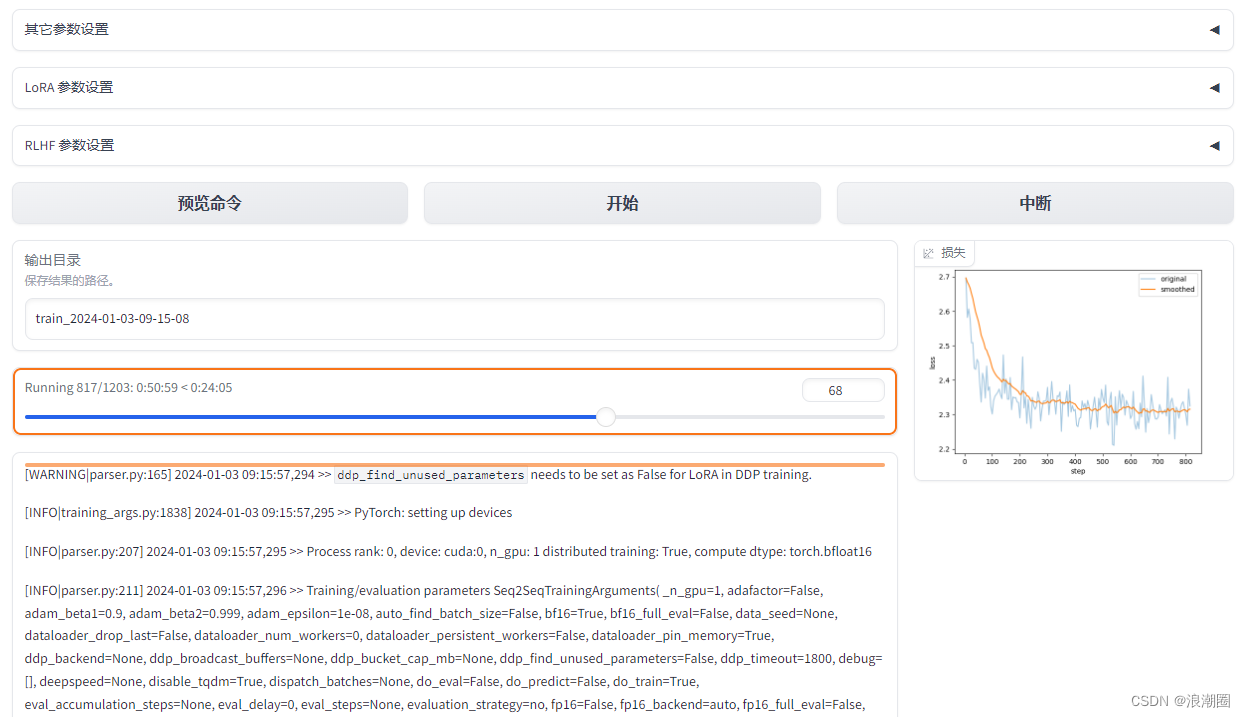
本次微调使用的微调数据集约有25.6K个sample,微调3个epoch,单块L20 GPU约6小时可以完成。如果要微调类似alpaca-data(52K)的数据集,tokenizer后其平均序列长度为226,拼接后sample个数为11.5K,微调3个epoch,单块L20 GPU约2.5小时可以完成。如果使用消费级显卡如RTX 4090等来微调Yuan2.0-2B,其实际算力水平约为L20的1.2~1.3X,微调所花费时间约为L20的80%;其余GPU设备均可做类似比对。
- step5:测试推理及效果展示
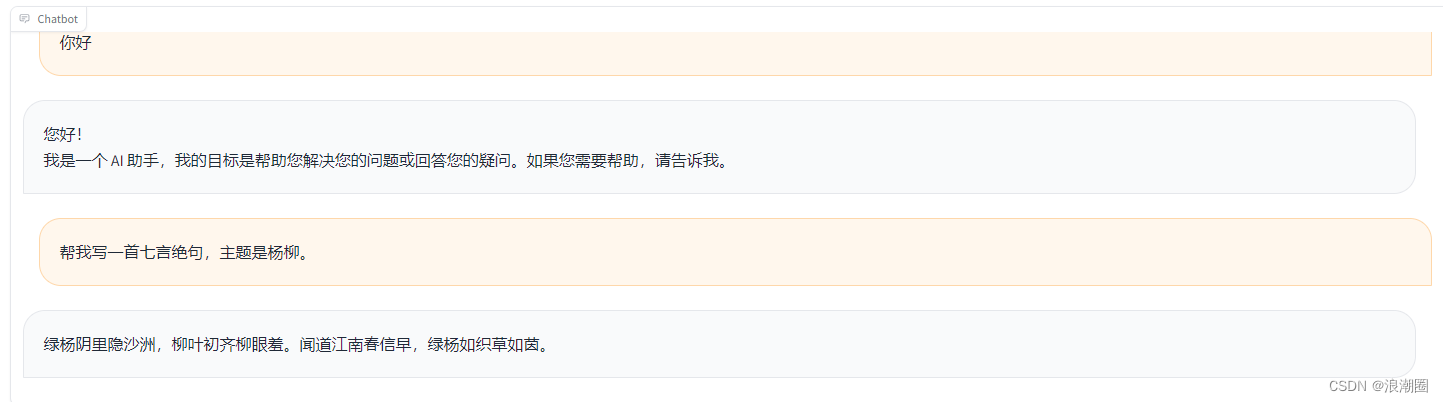
(1)写作
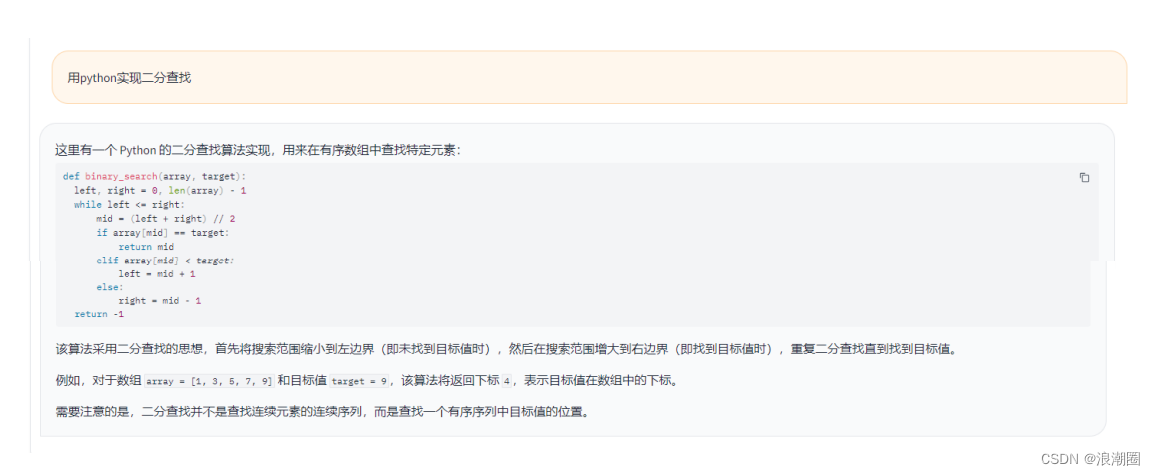
(2)代码
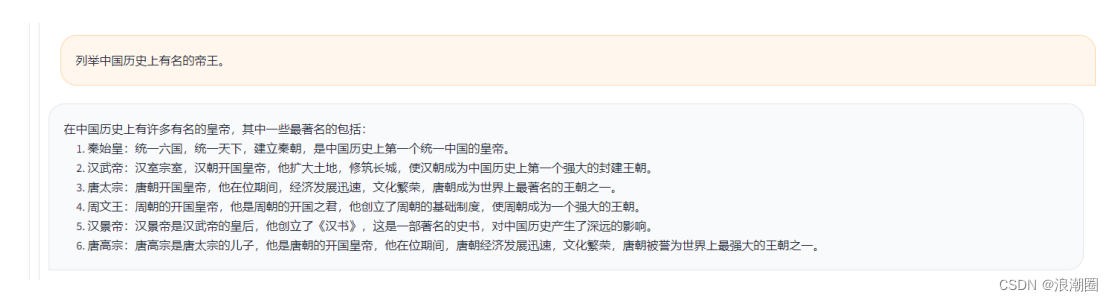
(3)历史
(4)数学
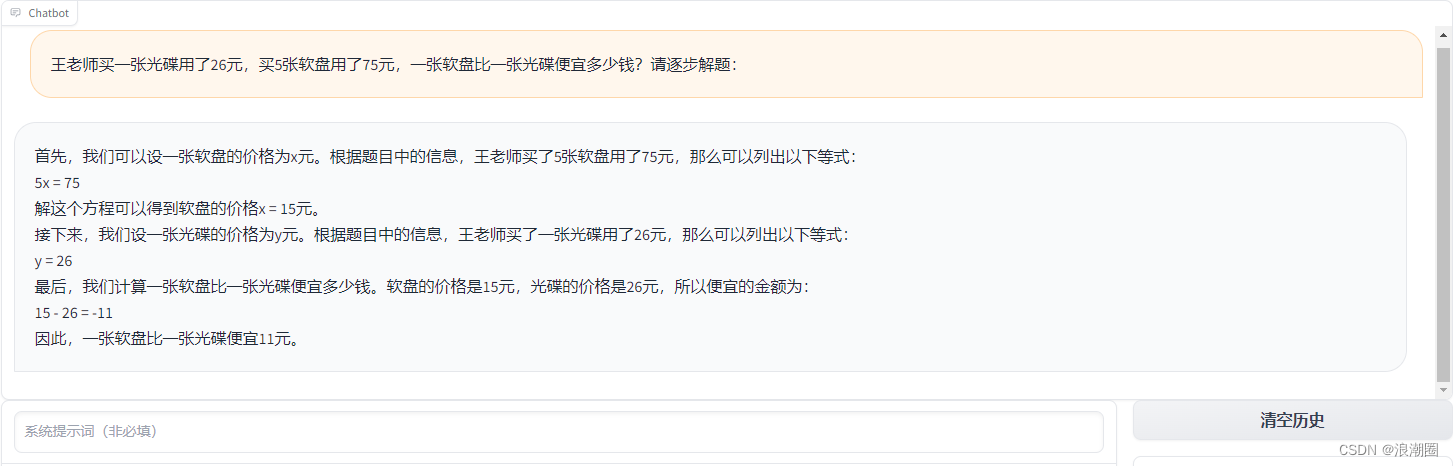
4.训练加速
在step-by-step流程中介绍了如何利用web UI界面微调和使用Yuan2.0-2B模型。接下来将在上述流程的基础上,展示如何使用llama-factory中的超参设置来加速模型的微调。
下述命令行大致对应了web UI启动微调所调用的命令,我们可以添加gradient_checkpointing True参数进一步节省显存,增大per_device_train_batchsize。可以添加--sft_packing参数,该参数能够将多个样本拼接在一起,防止计算资源浪费。
-
CUDA_VISIBLE_DEVICES=
0 python src/train_bash.
py \
-
--stage sft \
-
--model_name_or_path /workspace/sa/LLM_test/LLM_models/yuan2-2B/ \
-
--do_train \
-
--dataset alpaca_gpt4_zh,self_cognition,sharegpt_zh \
-
--finetuning_type lora \
-
--lora_target q_proj,v_proj \
-
--output_dir yuan2_2B_test_1gpu_qlora_checkpoint\
-
--overwrite_cache \
-
--per_device_train_batch_size
1 \
-
--per_device_eval_batch_size
4 \
-
--gradient_accumulation_steps
16 \
-
--preprocessing_num_workers
16 \
-
--lr_scheduler_type cosine \
-
--logging_steps
10 \
-
--save_steps
10000 \
-
--learning_rate
5e-4 \
-
--max_grad_norm
0.5 \
-
--num_train_epochs
3 \
-
--evaluation_strategy no \
-
--bf16 \
-
--template yuan \
-
--overwrite_output_dir \
-
--cutoff_len
1024\
-
--quantization_bit
4 \
-
--sft_packing
另外我们可以使用deepspeed-zero进行多机多卡的微调训练。使用torchrun或deepspeed启动脚本,并添加deepspeed config参数,使用多机多卡并行可以加快模型收敛;zero并行策略可以降低模型显存占用,让大模型的微调门槛降低。如下所示为启动多机多卡微调训练的命令行。
5.实测性能数据
我们基于浪潮信息的NF5468M7服务器(内置8个L40s加速卡),进行了Yuan2.0不同模型的微调性能对比,性能数据如下表,供读者参考。实验使用的数据集为yuan-sample-2W-data,单个yuan-sample-2W-datasample平均长度为167。
表格5‑1:基于llama-factory微调源2.0模型的实测性能(NF5468M7+L40s)
| 微调方法(基于llama-factory) | Model | 序列长度 | Micro/global BS | Samples/per-GPU | Tokens/per-GPU | 显存/per-GPU | 训练耗时 |
| 全参微调 | Yuan2.0-2B | 2048 | 4/128 | 2.23 | 4567 | 19G | 0.15h |
| LoRA | Yuan2.0-51B | 2048 | 1/128 | 0.097 | 199 | 34G | 3.54h |
| LoRA | Yuan2.0-102B | 2048 | 1/128 | 0.049 | 100 | 47G | 7h |
我们基于浪潮信息的NF5468M7服务器(内置8个L20加速卡),进行了Yuan2.0不同模型的微调性能对比,性能数据如下表,供读者参考。实验使用的数据集为yuan-sample-2W-data,单个yuan-sample-2W-datasample平均长度为167。
表格5‑2:基于llama-factory微调源2.0模型的实测性能(NF5468M7+L20)
| 微调方法(基于llama-factory) | Model | 序列长度 | Micro/global BS | Samples/per-GPU | Tokens/per-GPU | 显存/per-GPU | 训练耗时 |
| 全参微调 | Yuan2.0-2B | 2048 | 4/128 | 1.74 | 3559 | 19G | 0.2h |
| LoRA | Yuan2.0-51B | 2048 | 1/128 | 0.078 | 160 | 34G | 4.4h |
| LoRA | Yuan2.0-102B | 2048 | 1/128 | 0.039 | 81 | 47G | 8.7h |















 7636
7636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









