









一、主要学习:
应用op的name参数实现op的名字修改
应用variable_scope实现图程序作用域的添加
应用scalar或histogram实现张量值的跟踪显示
应用merge_all实现张量值的合并
应用add_summary实现张量值写入文件
应用tf.train.saver实现TensorFlow的模型保存以及加载
应用tf.app.flags实现命令行参数添加和使用
应用reduce_mean、square实现均方误差计算
应用tf.train.GradientDescentOptimizer实现有梯度下降优化器创建
应用minimize函数优化损失
知道梯度爆炸以及常见解决技巧
二、线性回归:y_predict=w1x1+w2x2+…+wnxn+b
线性回归的流程:
1.准备x和y_true
2.根据数据建立数据模型
y_predict=wx+b :wx利用矩阵乘(tf.matmul(x, w))
w:随机初始化一个权重
b:随机初始化一个偏置
3.利用y_predic和y_true求出均方误差损失(tf.square(error) 求平方、tf.reduce_mean(error) 求均值)
4.利用梯度下降去减少模型的损失,从而优化模型的参数w和b
注:梯度下降有一个学习率:需要我们去指定,学习率时0~1之间的值
梯度下降API:
tf.train.GradientDescentOptimizer(learning_rate)
梯度下降优化
learning_rate:学习率,一般为0~1之间比较小的值
method:
minimize(loss)
return:梯度下降op
三、步骤
1、准备数据的特征值和目标值 inputs
2、根据特征值建立线性回归模型(确定参数个数形状) inference
模型的参数必须使用变量OP创建
3、根据模型得出预测结果,建立损失 loss
4、梯度下降优化器优化损失 sgd_op
四、代码实现
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
class MyLinerRegression(object):
"""
用tensorflow实现线性回归
"""
def __int__(self):
pass
def inputs(self):
"""
获取需要训练的数据
:return:
"""
# x:[100:1] x这样定义为了矩阵的乘 y_true=x*0.7+0.8
x_data = tf.random_normal(shape=[100, 1], mean=0.0, stddev=1.0, name="x_data")
y_true = tf.matmul(x_data, [[0.7]]) + 0.8
return x_data, y_true
def inference(self, feature):
"""
根据数据特征值,建立线性回归模型
:param feature:数据的特征值[100,1]
:return: y_predict
"""
# 定义一个命名空间防止数据很乱
with tf.variable_scope("liner_model"):
# w,b
# x [100,1] *w[1,1]+b=y_predict
# 随机初始化权重和偏执
# 权重和偏执必须使用tf.Variable去定义,因为只有Variable才能被梯度下降训练
self.weight = tf.Variable(tf.random_normal(shape=[1, 1], mean=0.0, stddev=0.0), name="weight")
self.bais = tf.Variable(tf.random_normal(shape=[1], mean=0.0, stddev=1.0), name="bais")
# 建立模型
y_predict = tf.matmul(feature, self.weight) + self.bais
return y_predict
def loss(self, y_true, y_predict):
"""
根据真实值和预测值求出均方误差
:param y_true:真实值
:param y_predict:预测值
:return:
"""
# 定义一个命名空间
with tf.variable_scope("losses"):
# sum((y_true-y_predict)^2) mean()
# 求出损失
# tf.reduce_mean对列表中的数据求和之后在求平均值
loss = tf.reduce_mean(tf.square(y_true - y_predict))
return loss
def sgd_op(self, loss):
"""
利用梯度下降优化器去优化损失(优化参数weight和bais)
:param loss:损失
:return:梯度下降op(不是结果是操作)
"""
self.learning_rate = 0.01
# 定义一个命名空间
with tf.variable_scope("train_op"):
train_op = tf.train.GradientDescentOptimizer(self.learning_rate).minimize(loss)
return train_op
def merge_summary(self, loss):
"""
收集需要显示的张量的值
:param loss: 损失
:return:
"""
# 收集对于损失函数和准确率等单值变量
tf.summary.scalar("losses", loss)
# 收集高维护张量值
tf.summary.histogram("w", self.weight)
tf.summary.histogram("b", self.bais)
# 合并变量(OP)
merged = tf.summary.merge_all()
return merged
def train(self):
"""
用于训练的函数
:return: None
"""
# 获取默认的图用于操作(此步骤可以不做)
g = tf.get_default_graph()
# 在默认图中去做操作
with g.as_default():
# 进行训练
# 1.获取数据
x_data, y_true = self.inputs()
# 2.利用模型得到预测值
y_predict = self.inference(x_data)
# 3.计算损失
loss = self.loss(y_true, y_predict)
# 4.优化损失
train_op = self.sgd_op(loss)
# 收集需要观察的张量值
merged = self.merge_summary(loss)
# d定义一个保存文件的saverOP
saver = tf.train.Saver()
# 开启会话去训练
with tf.Session() as sess:
# 初始化变量
sess.run(tf.global_variables_initializer())
# 创建events文件
file_write = tf.summary.FileWriter("./tmp/summary/", graph=sess.graph)
# 打印模型么可有训练的初始化的参数
print("模型初始化的参数的权重 %f,偏置 %f" % (self.weight.eval(), self.bais.eval()))
#加载模型,从模型当中找出与当前训练的模型代码当中(名字一样的OP操作),覆盖原来的值
ckpt=tf.train.latest_checkpoint("./tmp/model/")
if ckpt:
saver.restore(sess,ckpt)
print("第一次加载模型初始化的参数的权重 %f,偏置 %f" % (self.weight.eval(), self.bais.eval()))
for i in range(500):
_, summary = sess.run([train_op, merged]) #一定要写成_,summary
# 把summary,张量的值写入events文件当中去
file_write.add_summary(summary, i)
print("第%d步,总损失%f,模型优化的参数的权重 %f,偏置 %f" % (
i,
loss.eval(),
self.weight.eval(), self.bais.eval()))
# 每隔100次保存一次模型
if i % 100 == 0:
# 要指定路径+名字
saver.save(sess, "./tmp/model/linerregression")
if __name__ == "__main__":
lr = MyLinerRegression()
lr.train()
五、总结:
1.梯度下降中的学习率不应该设置过大、0~1之间的数,如果过大,导致梯度爆炸(损失、参数优化成)
2.学习率越大,达到最终比较好的效果步长越小
3.学习率越小,达到最终比较好的效果步长越大
4.解决梯度爆炸问题(深度神经网络当中更容易出现)
1)、重新设计网络
2)、调整学习率
3)、使用梯度截断(在训练过程中检查和限制梯度的大小)
4)、使用激活函数
5.trainable的参数作用,指定是否训练,如果指定为False就不会变化
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="weights", trainable=False)
6.增加命名空间
with tf.variable_scope(“lr_model”):
是代码结构更加清晰,Tensorboard图结构更加清楚
六、在TensorBoard当中观察模型的参数、损失值等变量值的变化
1.收集需要在TensorBoard中显示的变量值:这部分操作我们一般放在会话前面去做
1)tf.summary.scalar(name=’’,tensor) 收集对于损失函数和准确率等单值变量,name为变量的名字,tensor为值

2)tf.summary.histogram(name=‘’,tensor) 收集高维度的变量参数,记录收集权重变量和梯度输出
histogram在如下地方显示
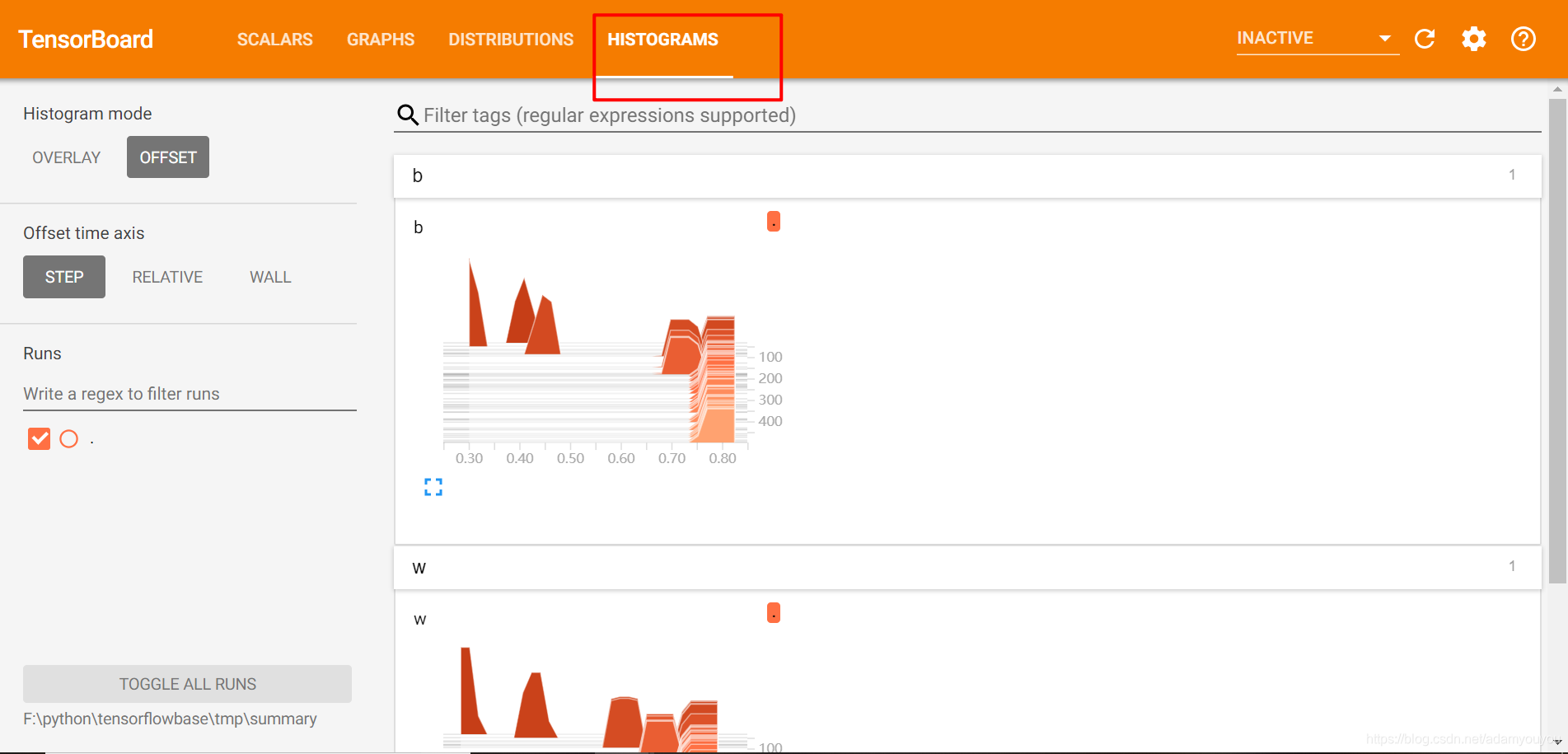
3)tf.summary.image(name=‘’,tensor) 收集输入的图片张量能显示图片
2.合并变量写入事件文件
merged = tf.summary.merge_all()
运行合并:summary = sess.run(merged),每次迭代都需运行
添加:FileWriter.add_summary(summary,i),i表示第几次的值
如果修改了最好先把之前生成的events文件删除
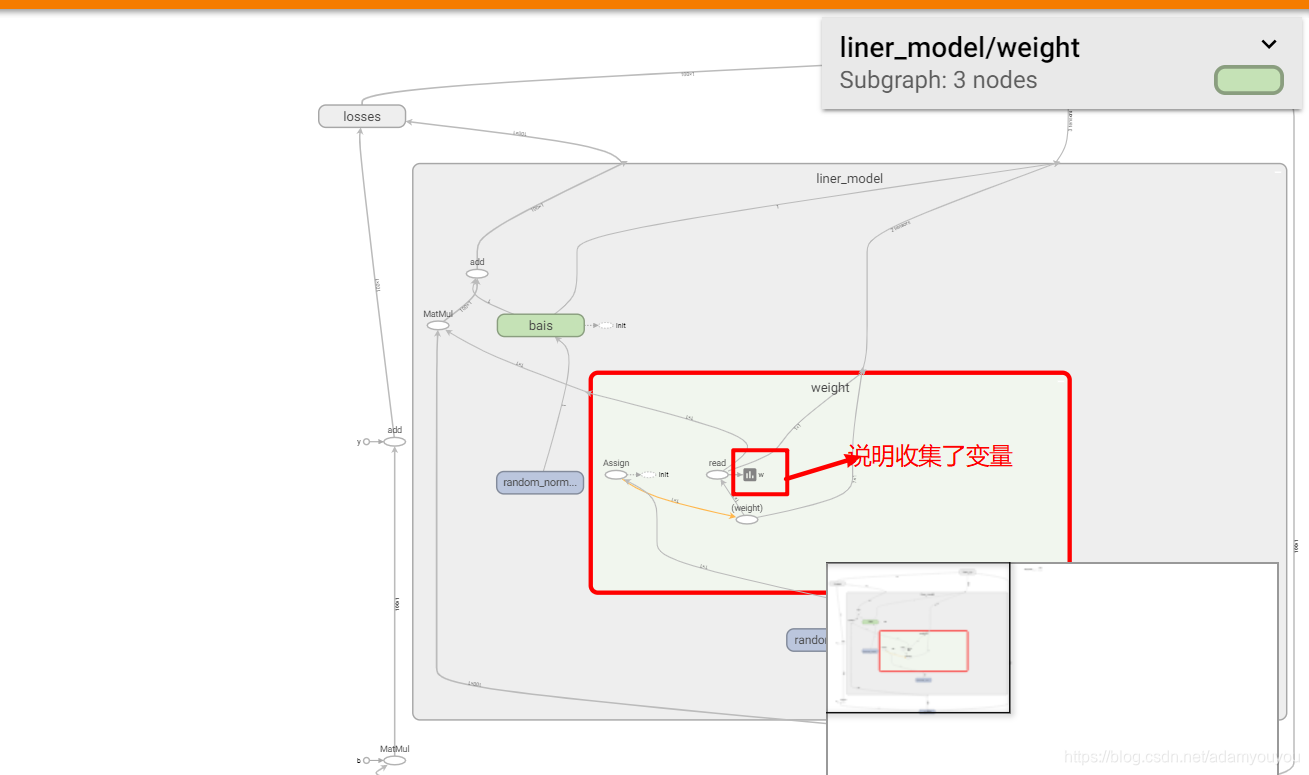
七.模型的保存与加载
1.模型保存的文件格式:checkpoint文件
2.tf.train.Saver(var_list=None,max_to_keep=5)
保存和加载模型(保存文件格式:checkpoint文件)
var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
max_to_keep:指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
指定目录+模型名字
saver.save(sess, '/tmp/ckpt/test/myregression.ckpt')
saver.restore(sess, '/tmp/ckpt/test/myregression.ckpt')
注:1.保存时需要指定路径,指定要保存的会话,默认保存tf.Variable的OP,可以指定保存哪些
2.加载模型(saver.restore)本地文件的模型当中的一些变量名字与要进行加载训练的代码中的变量名字必须一致。并且代码训练已保存模型的参数值继续训练,比如第一次保存模型结束时w=0.699372,则加载模型以后继续训练的w值从w=0.699372开始继续训练
八、cmd命令行中运行程序
2、 tf.app.flags.,在flags有一个FLAGS标志,它在程序中可以调用到我们
前面具体定义的flag_name
3、通过tf.app.run()启动main(argv)函数
# 定义一些常用的命令行参数
# 训练步数
tf.app.flags.DEFINE_integer("max_step", 0, "训练模型的步数")
# 定义模型的路径
tf.app.flags.DEFINE_string("model_dir", " ", "模型保存的路径+模型名字")
# 定义获取命令行参数
FLAGS = tf.app.flags.FLAGS
# 开启训练
# 训练的步数(依据模型大小而定)
for i in range(FLAGS.max_step):
sess.run(train_op)















 5934
5934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









