







DUIX(Dialogue User Interface System)是硅基智能打造的AI数字人智能交互平台。通过将数字人交互能力开源,开发者可自行接入多方大模型、语音识别(ASR)、语音合成(TTS)能力,实现数字人实时交互,并在Android和iOS多终端一键部署,让每个开发者可轻松创建智能化、个性化的数字人Agent,并应用到各行各业。
该项目不仅开源了所有相关资源,还配套提供了详尽的文档指南,旨在帮助开发者轻松驾驭,快速打造出个性化虚拟人应用场景。得益于此开源项目,无论是在 Android 还是 iOS 平台上,开发者都能实现数字人的快速部署,为用户带来无缝、即时的虚拟互动体验。
更进一步,硅基智能全面开放了其数字人 SDK 的源代码,覆盖从底层的推理引擎到上层商业应用逻辑,无保留揭秘技术细节。这一举措不仅鼓励技术社区深入探索数字人的内在工作机制,还激发了对现有技术进行优化改良及创新拓展的可能性,共同推动全球数字人技术的边界。
—1—
开源数字人有多强?
这个开源的 SDK 不仅提供了直观的效果展示,还支持用户进行二次开发,核心功能有:
1. 个性数字人随你挑:14款不同风格的数字人模版等你来拿,还能不断更新,让你紧跟潮流。

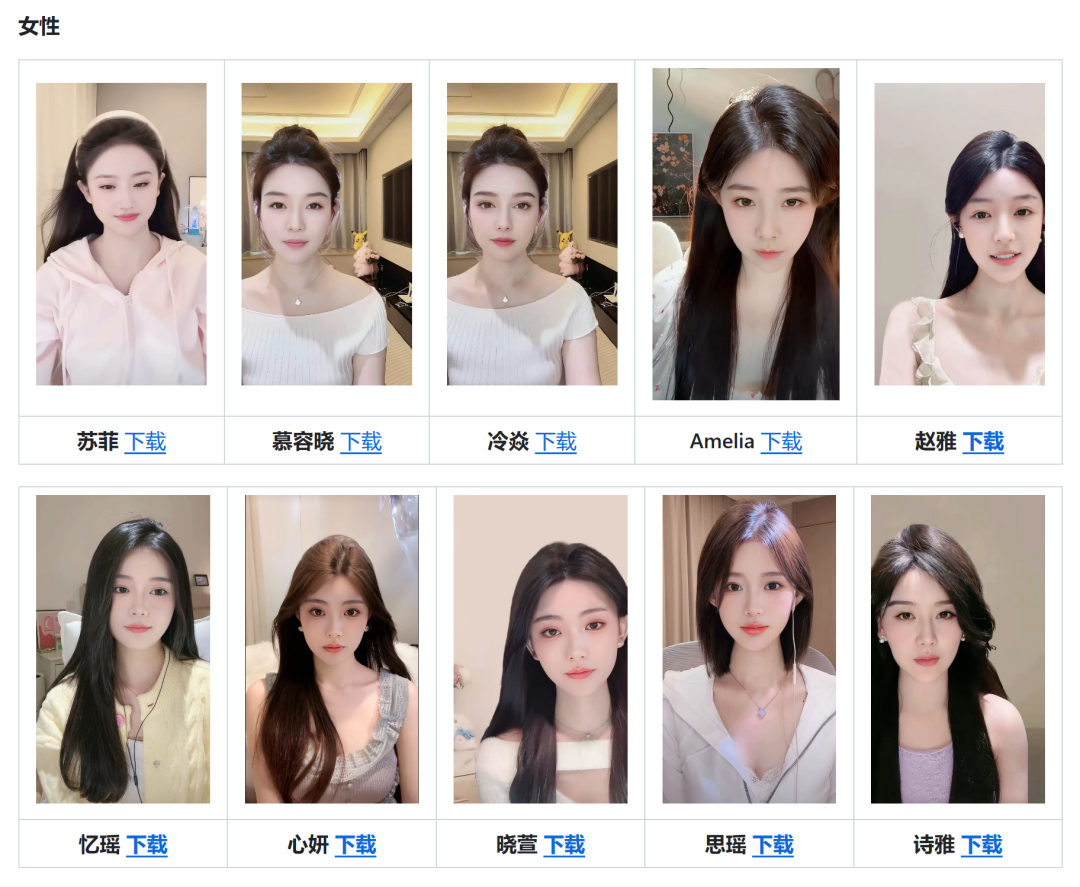
2. 超省钱高效:轻松部署在手机、大屏,甚至平板、车机,成本低、运行溜。

3. 丝滑体验:每秒50帧,画面流畅到爆,直播不卡顿,视频产出快。
4. 超真实感受:动作、唇形、微表情,模拟得跟真的一样,让人难辨真假。
5. 百变应用场景:打造 AI 小伙伴、直播售货、定制数字人短片,助力抖音、视频号等内容创作与品牌宣传。

—2—
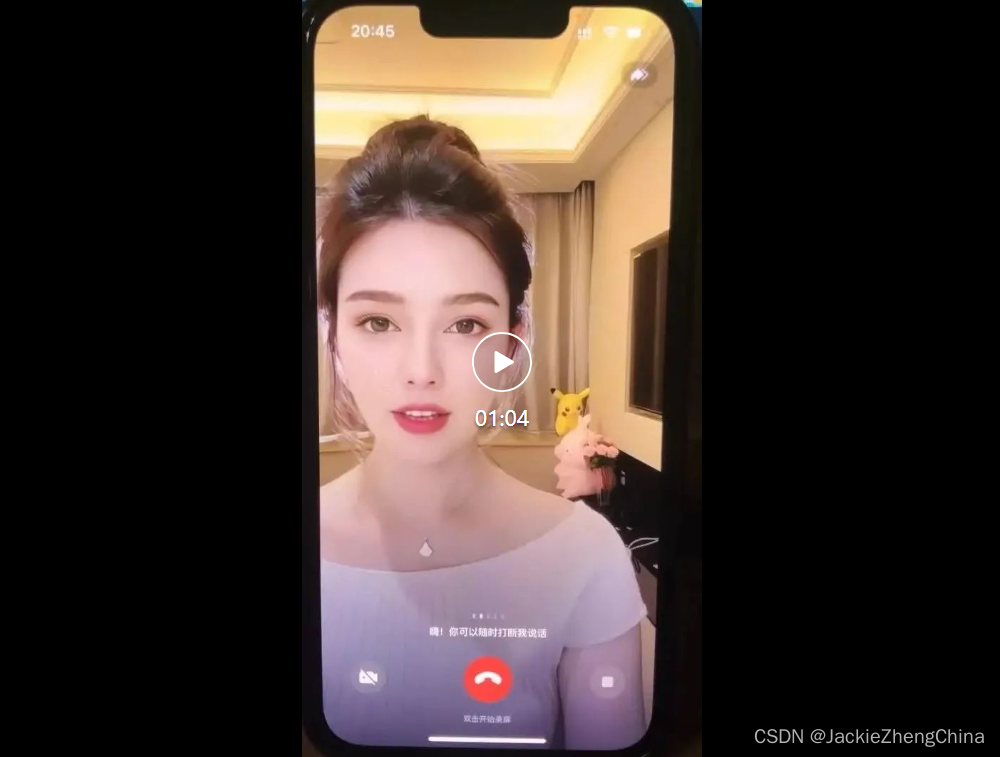
看看效果有多棒?
体验一下此数字人的生动演示,它能聪明地理解并回应你的每一句话。目前的小遗憾是,它的思考时间约为3到4秒,但这对话结束后才给出反应。别担心,技术的进步就在眼前,随着模型优化,这一等待时间即将成为过去。
—3—
如何部署使用?
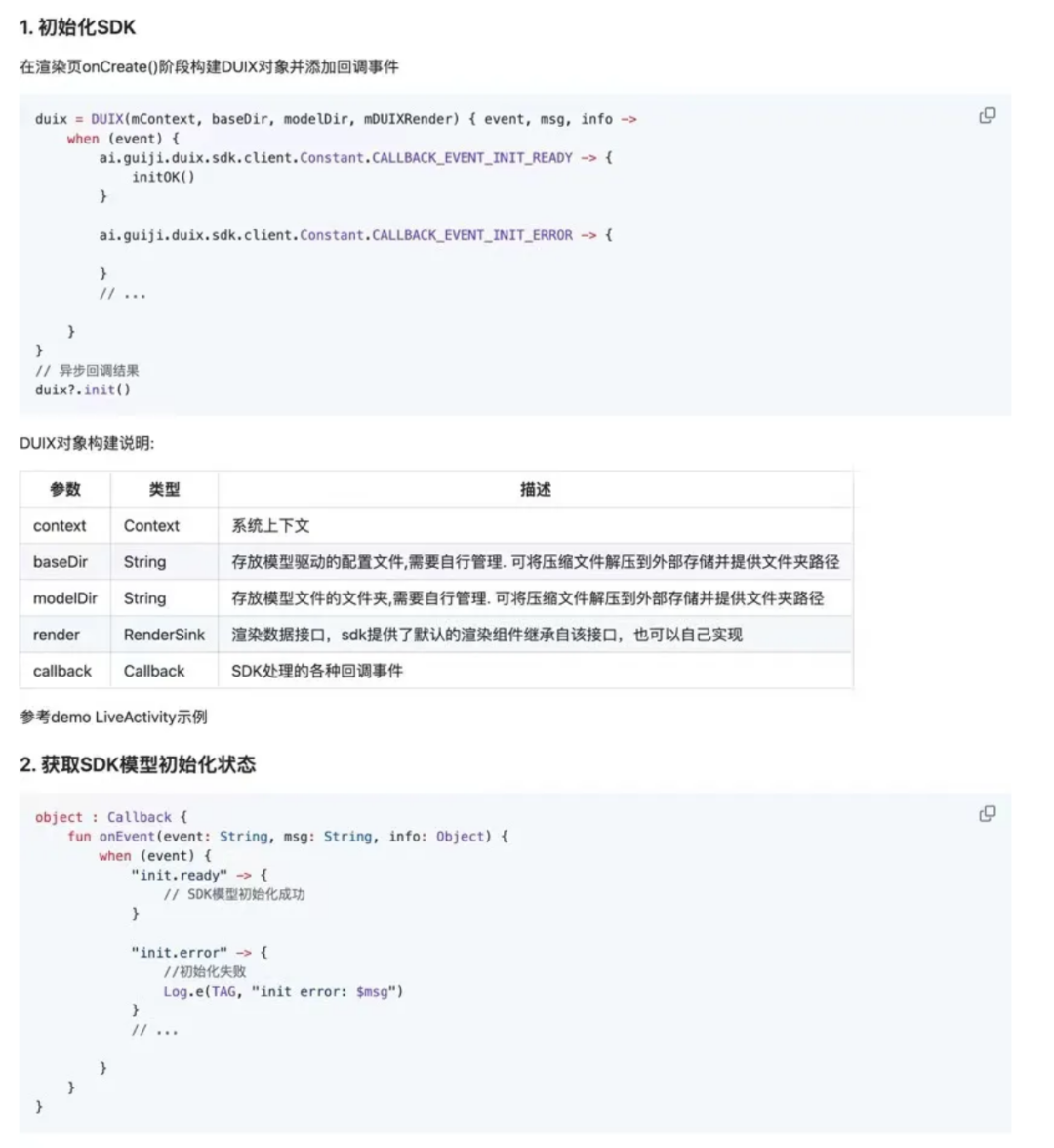
第一、安卓 SDK 集成教程
该开源项目提供了详细的使用部署教程,可以移步该项目的地址去查看,我直接把重要的部分贴在了下方。
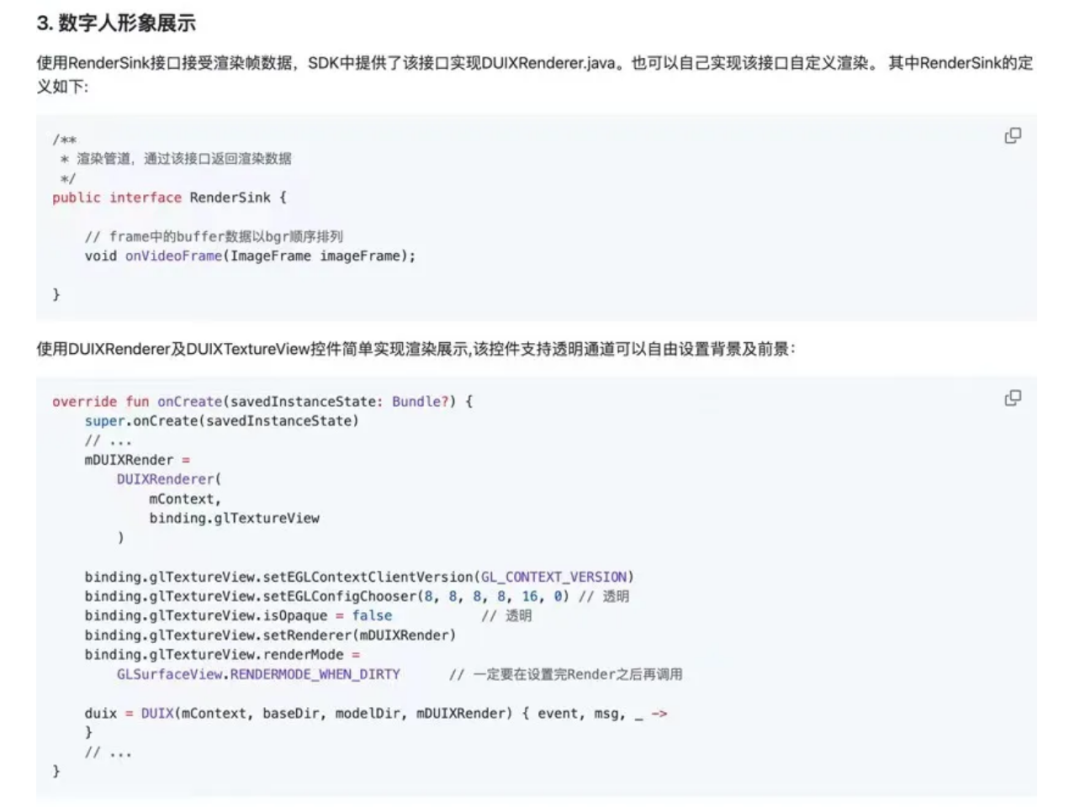
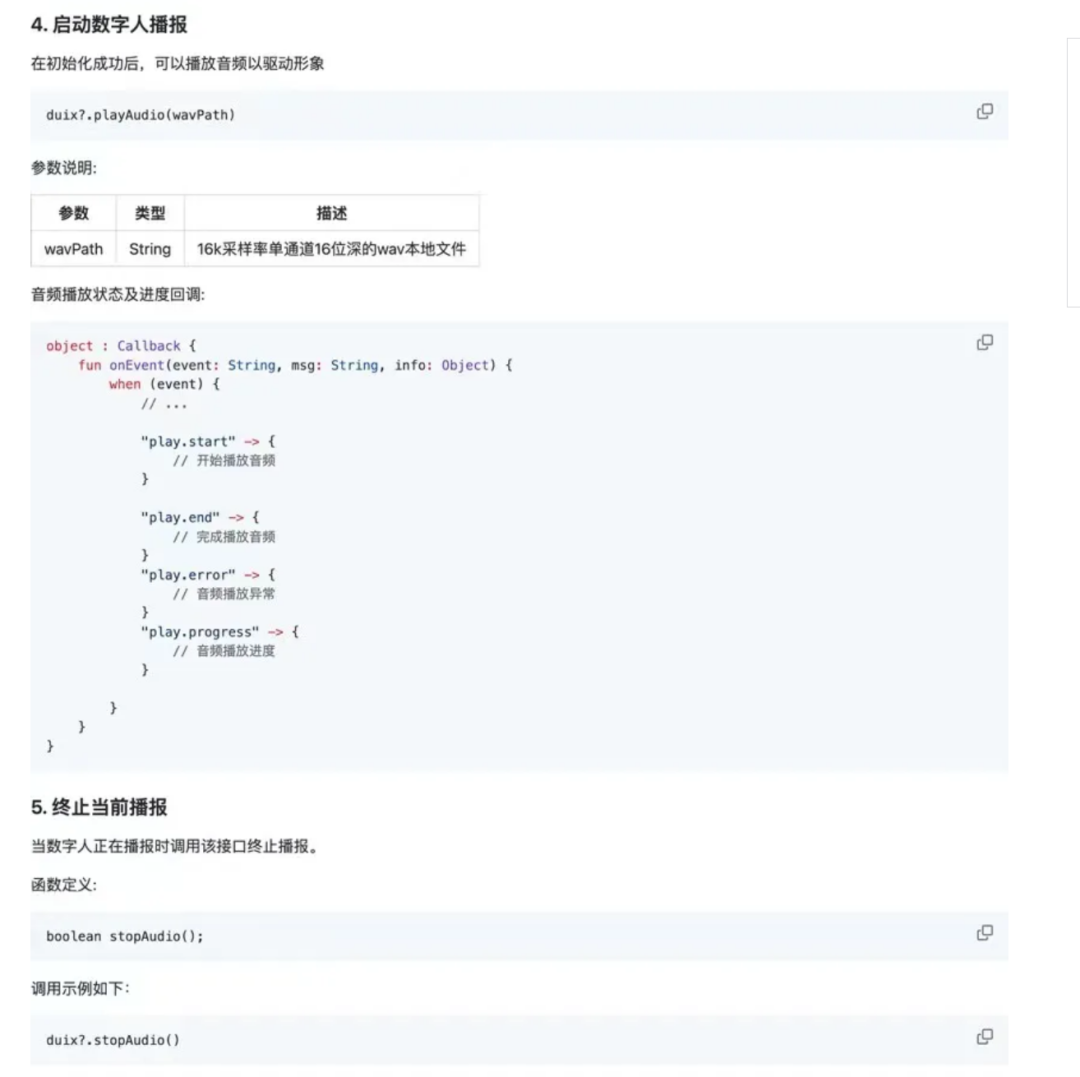

第二、iOS SDK 集成教程
SDK 提供了多种回调方法,包括数字人渲染报错回调、音频播放结束回调、音频播放进度回调等。
动作相关的还支持随机动作、开始动作、结束动作等。建议前往开源项目去查看详细文档。
NSString *basePath =[NSString stringWithFormat:@"%@/%@",[[NSBundle mainBundle] bundlePath],@"gj_dh_res"];
NSString *digitalPath =[NSString stringWithFormat:@"%@/%@",[[NSBundle mainBundle] bundlePath],@"lixin_a_540s"];
//初始化
NSInteger result= [[GJLDigitalManager manager] initBaseModel:basePath digitalModel:digitalPath showView:weakSelf.showView];
if(result==1)
{
//开始
[[GJLDigitalManager manager] toStart:^(BOOL isSuccess, NSString *errorMsg) {
if(!isSuccess)
{
[SVProgressHUD showInfoWithStatus:errorMsg];
}
}];
}—4—
项目开源地址
这个开源项目的背后功臣是硅基智能,一家在 AI 领域名声响当当的企业,我经常在短视频平台上看到他们的身影。他们已经复制了多达50万个独一无二的数字人,而且让 AIGC 技术在十几个行业里头大展拳脚,商业化走得挺远的。
为了让更多的个人开发者和企业有机会涉足数字人领域,不被高技术门槛挡在门外,硅基智能决定大方公开其核心技术的源代码,真正意义上推动了数字人技术的普惠与共创。
来源于玄姐论AI ,作者玄姐



















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











