







安装的前提条件
- 安装Docker,这个应该不用多说,这
- Docker至少得分配4GB的内存; Elasticsearch至少需要单独2G的内存;所以配置好的尽量分配大一点
- 防火墙开放相关端口;
- vm.max_map_count至少需要262144我们主要介绍一下怎么设置vm.max_map_count,不设置的话在安装过程中会提示你需要设置。

设置vm.max_map_count的方式有两种。
- 正在运行的机器(不是永久的):
sysctl -w vm.max_map_count=262144
- 1
- 永久性的修改,在/etc/sysctl.conf文件中添加一行
grep vm.max_map_count /etc/sysctl.conf # 查找当前的值。
vm.max_map_count=262144 # 修改或者新增
我们来介绍一下这种方案。
首先我们用root用户修改配置sysctl.conf
sudo vi /etc/sysctl.conf
添加下面配置
vm.max_map_count=655360
- 1
并执行命令
sudo sysctl -p
- 1

安装Kafka
先使用命令 docker search kafka 查看kafka的安装包
docker search kafka
- 1
结果我使用命令的时候报了这么一个错误。
error during connect: Get https://192.168.99.100:2376/v1.39/images/json: dial tcp 192.168.99.100:2376: connectex: No connection could be made because the target machine actively refused it.
- 1
执行docker version的时候也是同样的错误:
所以大家安装好docker的时候最好使用docker version查看一下docker的安装有什么问题。
然后我们继续。
选择
docker pull wurstmeister/kafka
- 1

Zookeeper
安装Kafka需要安装Zookeeper
同样的操作安装zookeeper
docker search zookeeper
- 1

选择
docker pull wurstmeister/zookeeper
- 1

启动Zookeeper和Kafka镜像
首先启动zookeeper
docker run -d --name zookeeper --publish 2181:2181 --volume /etc/localtime:/etc/localtime wurstmeister/zookeeper:latest
- 1

然后在启动Kafka
docker run -d --name kafka --publish 9092:9092 --link zookeeper --env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
--env KAFKA_ADVERTISED_HOST_NAME=kafka所在宿主机的IP --env KAFKA_ADVERTISED_PORT=9092 --volume /etc/localtime:/etc/localtime
wurstmeister/kafka:latest
- //可为集群之外的客户端链接
- --env KAFKA_ADVERTISED_HOST_NAME=kafka所在宿主机的IP (一定要是公网ip,否则远程是无法操作kafka的,kaka tools也是无法使用的,如果仅仅紧紧集群服务器间通信可以 设置 内网IP)
中间的kafka所在宿主机的IP,如果不这么设置,可能会导致在别的机器上访问不到kafka。
所以我们这里的命令是:
docker run -d --name kafka --publish 9092:9092 --link zookeeper --env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
--env KAFKA_ADVERTISED_HOST_NAME=192.168.99.100 --env KAFKA_ADVERTISED_PORT=9092 --volume /etc/localtime:/etc/localtime
wurstmeister/kafka:latest
-
5、验证kafka是否可以使用 5.1、进入容器 $ docker exec -it kafka bash 5.2、进入 /opt/kafka_2.12-2.3.0/bin/ 目录下 $ cd /opt/kafka_2.12-2.3.0/bin/ 5.3、运行kafka生产者发送消息 $ ./kafka-console-producer.sh --broker-list localhost:9092 --topic sun 发送消息 > {"datas":[{"channel":"","metric":"temperature","producer":"ijinus","sn":"IJA0101-00002245","time":"1543207156000","value":"80"}],"ver":"1.0"} 5.4、运行kafka消费者接收消息 $ ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sun --from-beginningkafka 可视化工具 kafka tool安装和简单使用:https://blog.csdn.net/qq_42255763/article/details/99541914
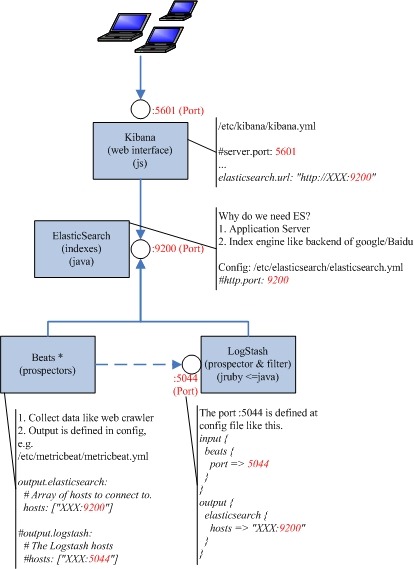
安装ELK
接下来我们来安装ELK
docker pull sebp/elk

执行命令,将镜像运行为容器,为了保证ELK能够正常运行,加了-e参数限制使用最小内存及最大内存。
docker run -p 5601:5601 -p 9200:9200 -p 9300:9300 -p 5044:5044 -e ES_MIN_MEM=128m -e ES_MAX_MEM=2048m -it --name elk sebp/elk
错误:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
即可永久修改
- 1

打开浏览器,输入:http://宿主机ip:5601,看到如下界面说明安装成功

配置ELK
使用以下命令进入容器
docker exec -it <container-name> /bin/bash
单独启动或者关闭服务
//关闭服务
service elasticsearch stop
service logstash stop
service kibana stop
//启动服务
service elasticsearch start
service logstash start
service kibana start

进入容器后执行命令:
/opt/logstash/bin/logstash -e 'input { stdin { } } output { elasticsearch { hosts => ["localhost"] } }'
- 1
注意:如果看到这样的报错信息 Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the “path.data” setting.
请执行命令:service logstash stop 然后在执行就可以了。
然后等待一会之后输入hello world!!
然后可以在http://宿主机ip:9200/_search?pretty 中查看
到此,ELK简单配置成功
接下来配置Logstash连接Kafka将日志发送给es
进入elk容器,进入 /etc/logstash/conf.d 文件夹地址中创建文件 logstash.conf 添加一下内容:
input {
beats {
port => 5044
}
kafka {
bootstrap_servers => ["宿主机IP:9092"]
group_id => "test-consumer-group"
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
topics => ["user_consumer"]
type => "bhy"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "myservice-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}

执行命令
vim /etc/init.d/logstash
打开logstash启动文件后,找到为logstash启动用户,都改为root,logstash的默认执行用户(logstash)可能会导致权限不足的问题。
LS_USER=root //原来默认为logstash
LS_GROUP=root //原为默认为logstash

启动logstash
/etc/init.d/logstash start
- 1
到此,logstash已经连接上Kafka并且实时监控消息发送到es存储,以上的logstash配置都是参考:https://blog.csdn.net/yhq1913/article/details/86523014, 可以参考这篇博文使用Springboot发送一下消息试一下。
下面我讲一下我项目中的logstash的配置
input {
beats {
port => 5044
}
kafka {
bootstrap_servers => ["192.168.99.100:9092"]
topics => ["cloud-service-member"]
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "member-service-%{+YYYY.MM.dd}" //修改index前面的,应该是这个
#user => "elastic"
#password => "changeme"
}
}

然后我在项目中是做了一个AOP进行拦截并把log发送到kafka。感兴趣的可以看看:
https://gitee.com/cckevincyh/cloud-demo/tree/ELK-1.0/
我们启动一下项目,访问以下我们的服务,也是查看http://宿主机ip:9200/_search?pretty,如果没有新的日志数据,可以尝试重启一下elk,之后就刷新了我们的服务页面就可以看到有新的日志进来了。
配置Kibana

我们可以看到在index pattern这里多了一个我们之前设置es的index。然后我们创建一个index pattern


然后我们就可以看到日志数据了。
















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









