







预备知识
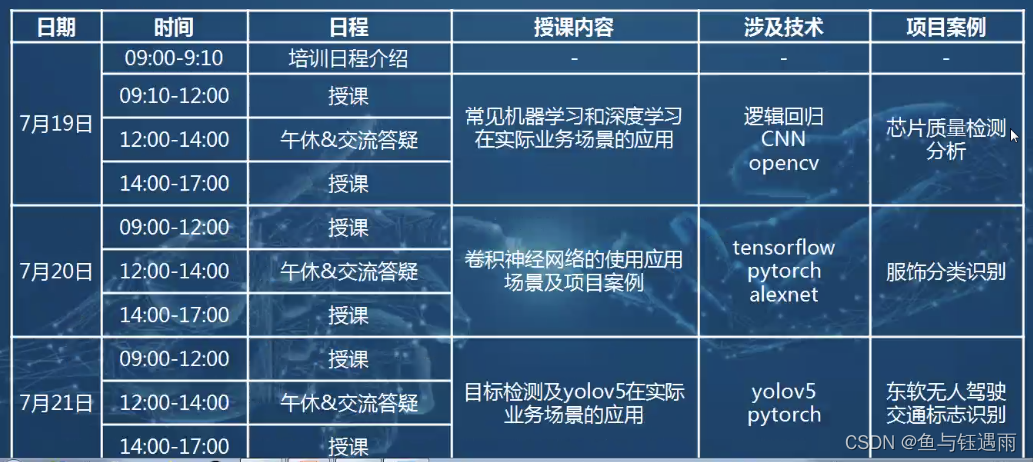











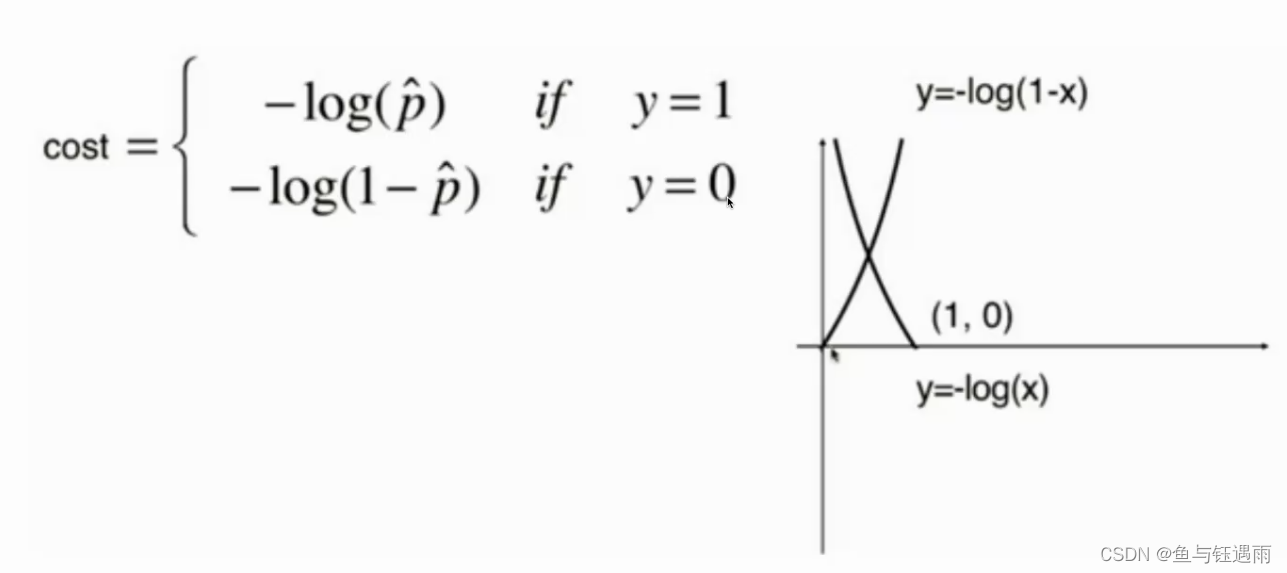
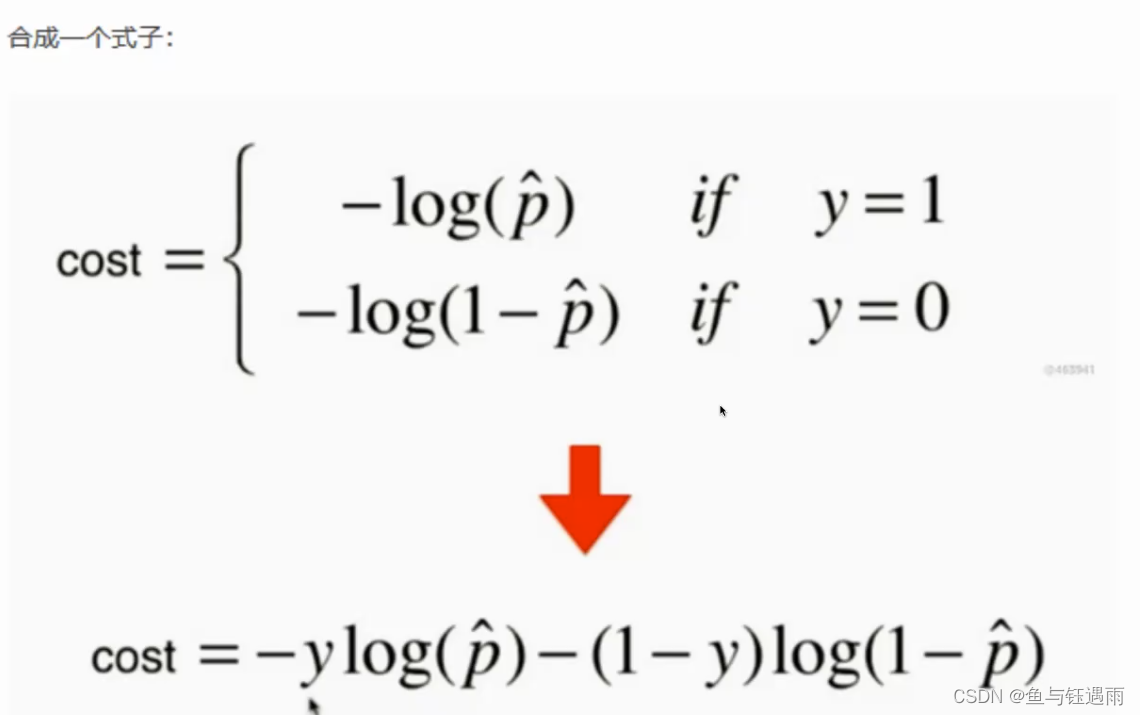
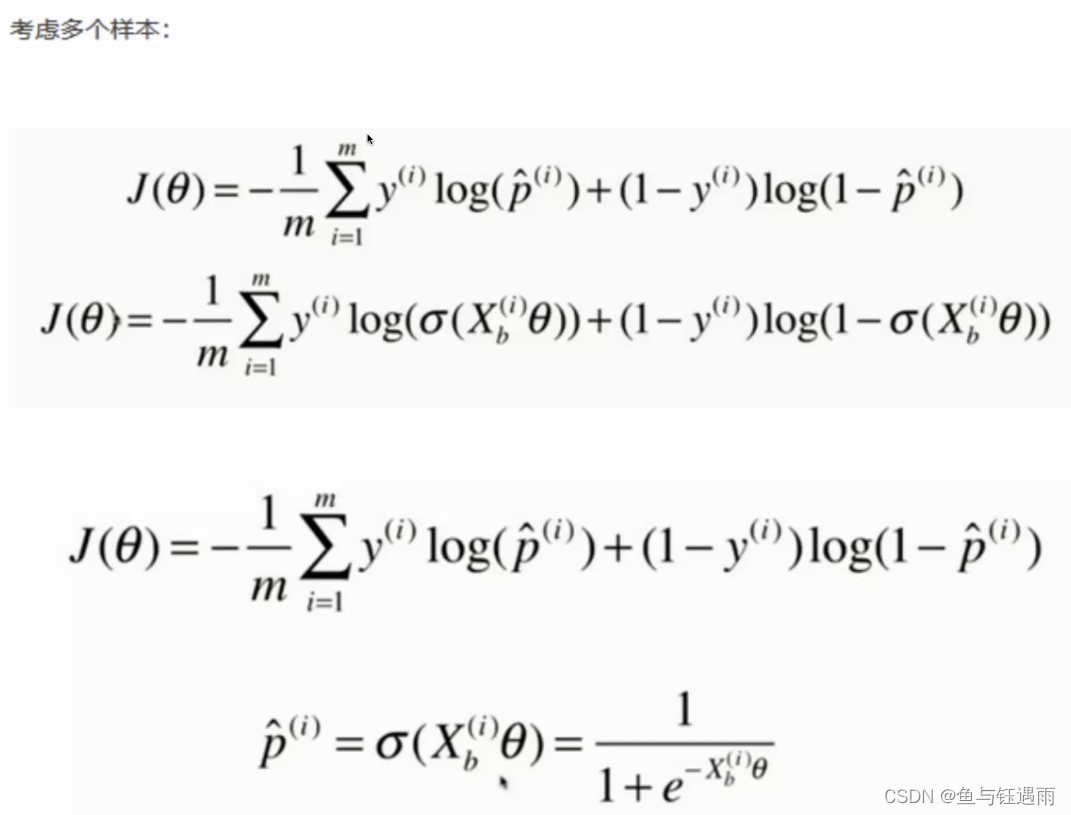





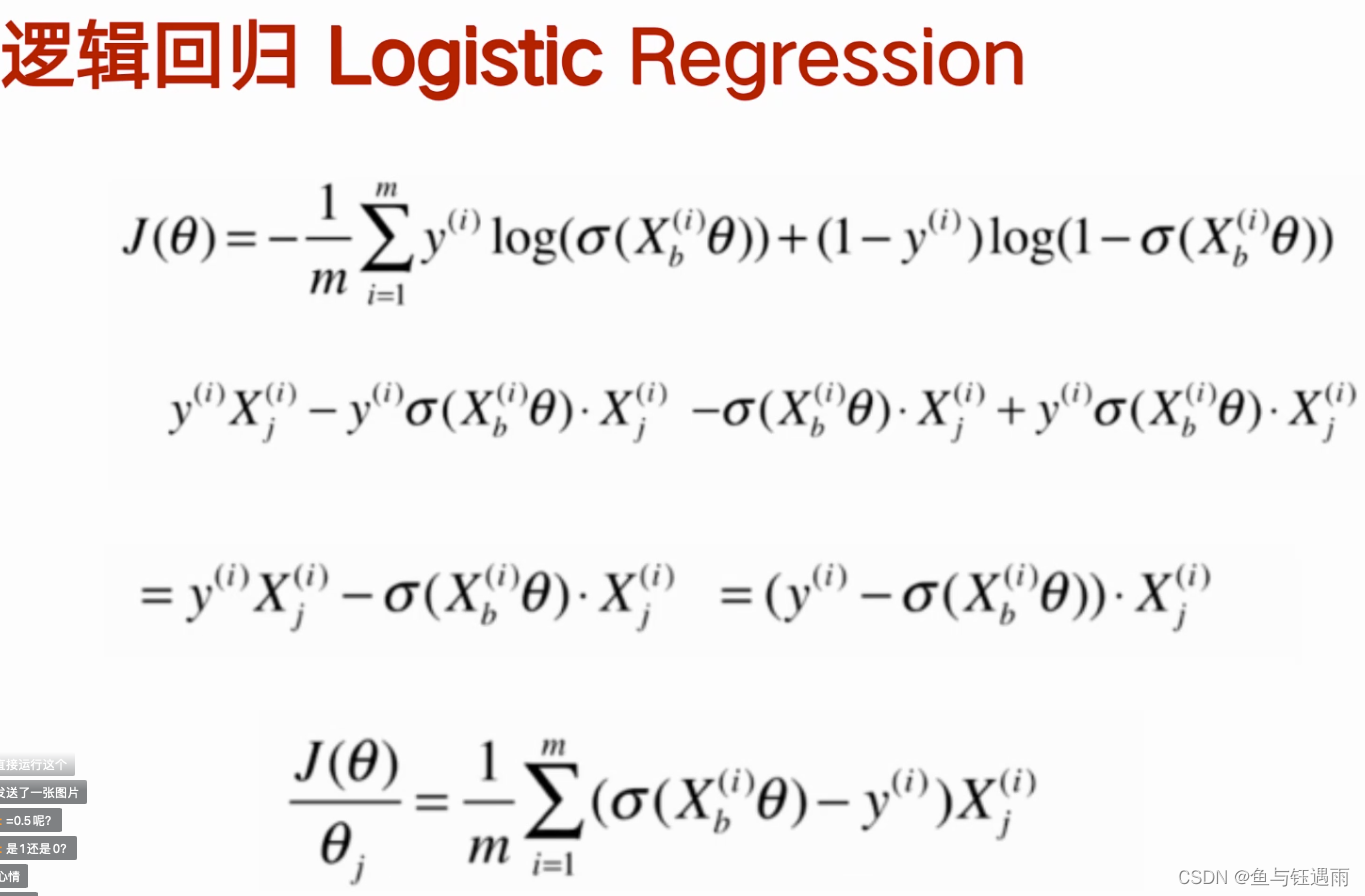

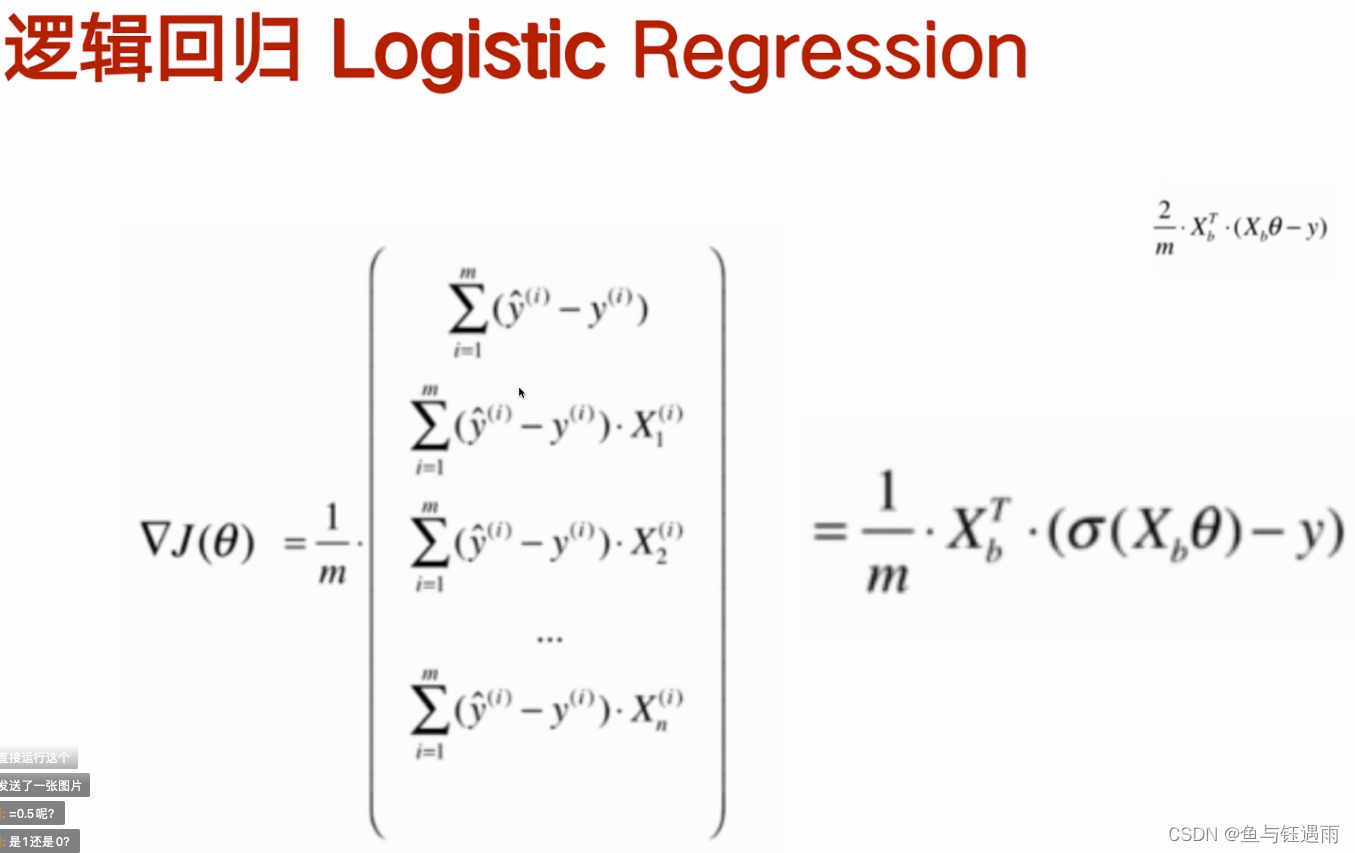
芯片质量检测任务代码详解
核心过程:定、数、模、训、测、上
(问题定义、数据准备、模型构建、模型训练和测试、模型预测、模型部署上线)
1 问题定义
芯片检测数据集(三列:x1,x2,y)是一个分类数据集,适用于逻辑回归模型。
标签y是0或1,代表芯片是否通过检测,x1和x2是芯片的两个评价指标数据。
数据集下载链接:https://download.csdn.net/download/adreammaker/86245857
2 数据准备
将数据进行划分
# 加载深度学习三件套 和 绘图工具
import numpy as np
import pandas as pd
import keras #这里深度学习工具包使用基于tensorflow的keras
from matplotlib import pyplot as plt
data = pd.read_csv('data.csv')
X = data.drop(['y'], axis=1) # 列方向删除
y = data.loc[:, 'y'] # 所有行都要, y列
# 绘图查看图像
#plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 用于mac jupyter
plt.rcParams['font.sans-serif'] = ['simhei'] # 用于linux jupyter
plt.figure(figsize=(5, 5))# 设置画布大小 英寸
passed = plt.scatter(X.loc[:, 'x1'][y==1],X.loc[:, 'x2'][y==1], color='green')
failed = plt.scatter(X.loc[:, 'x1'][y==0],X.loc[:, 'x2'][y==0], color='blue')
plt.legend((passed, failed), ('通过', '不通过'))
plt.show()
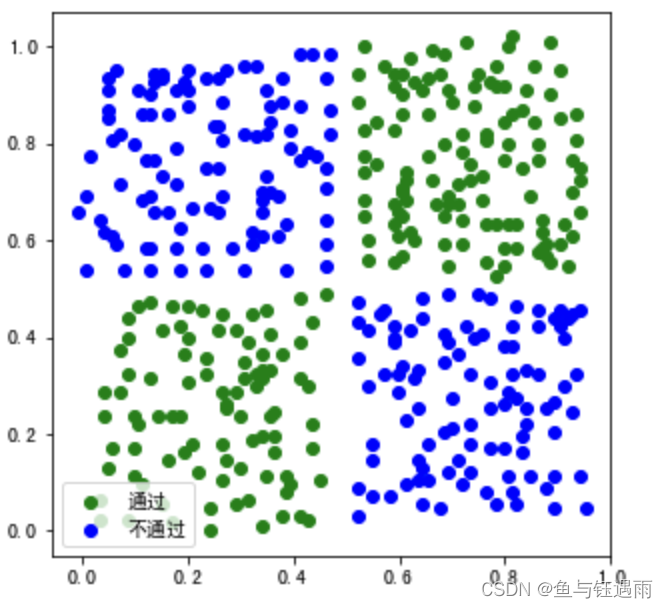
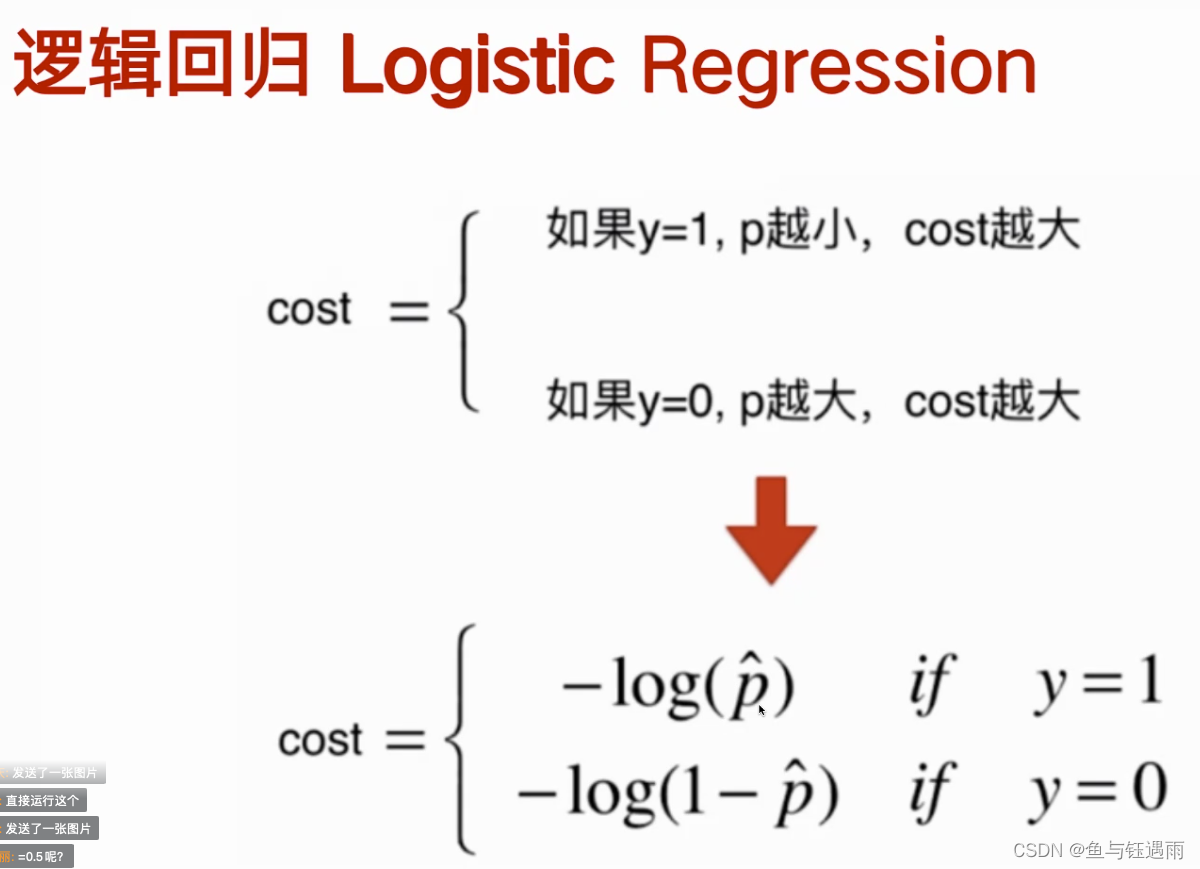
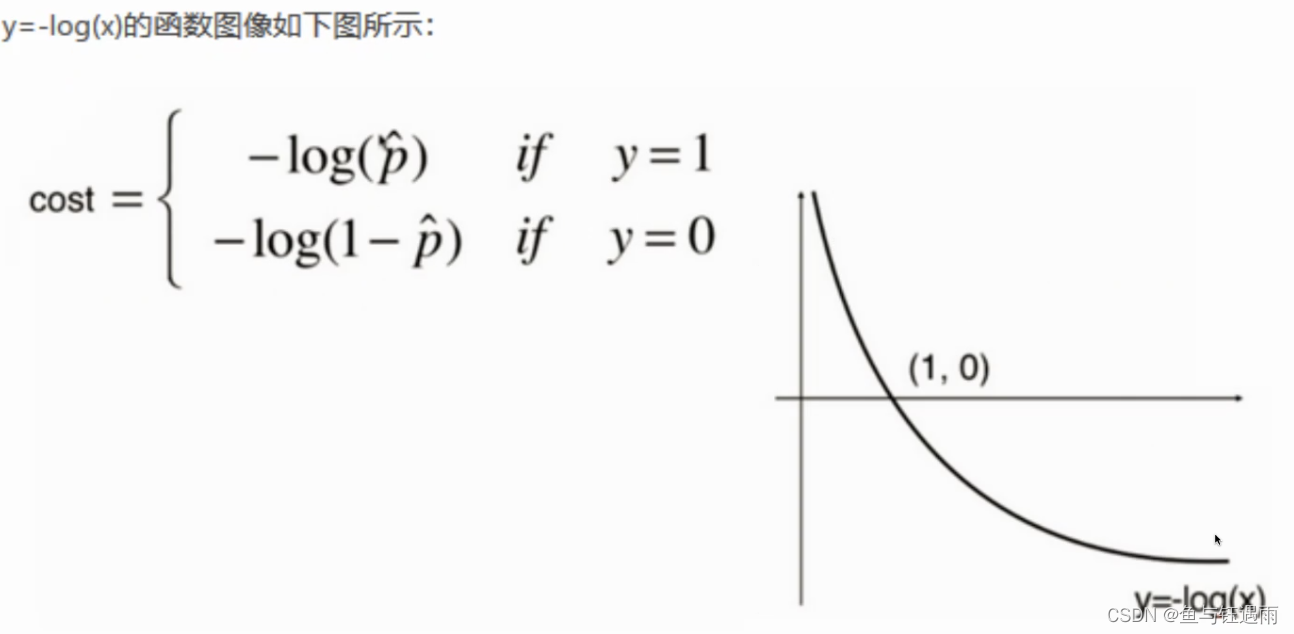
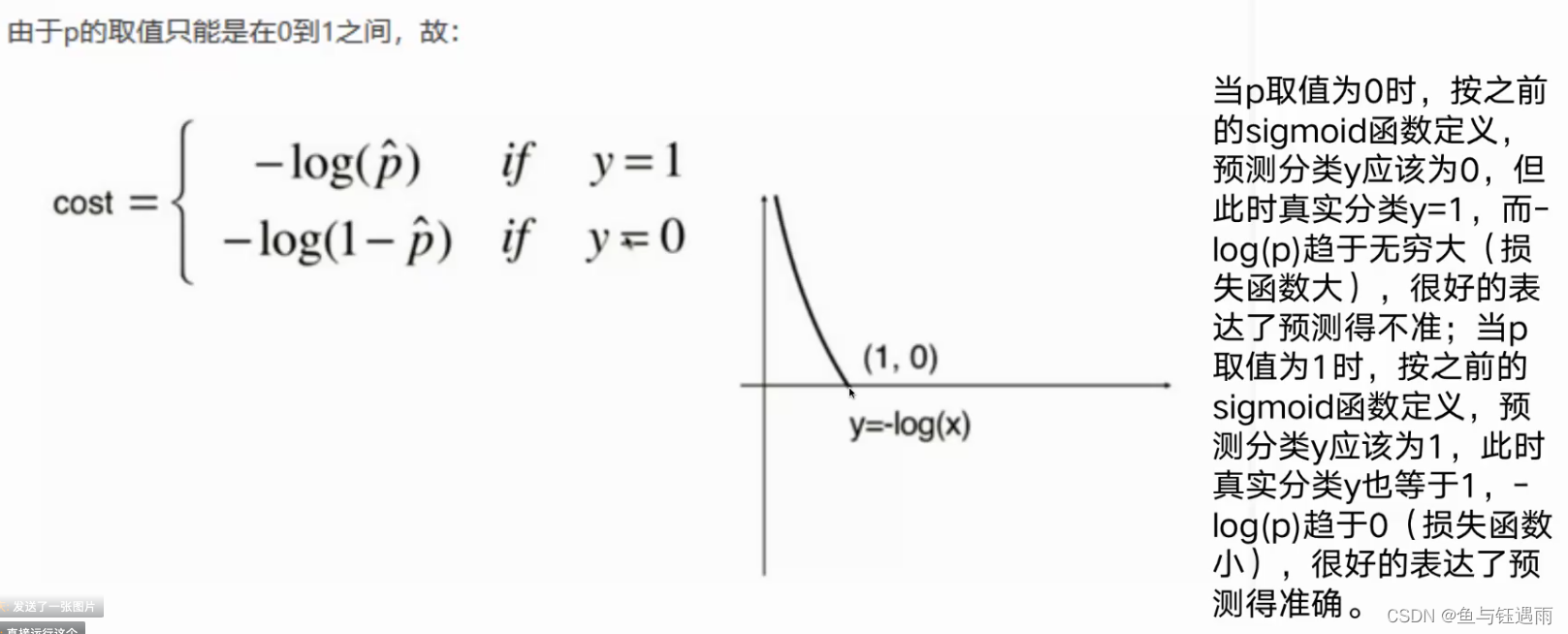
可以看出这个数据线性不可分,需要使用激活函数,逻辑回归就是在线性回归模型的基础上加了一个sigmoid激活函数,可以解决非线性分类问题。
# 数据集划分 3:1. 75%:25%
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
3模型构建
模型准备(小口诀:模型、损失、优化器;)
from keras.models import Sequential
from keras.layers import Dense, Activation # dense就是全链接层
## 网络
mlp = Sequential()
mlp.add(Dense(units = 20, input_dim = 2, activation = 'sigmoid'))
mlp.add(Dense(units=1, activation = 'sigmoid') )
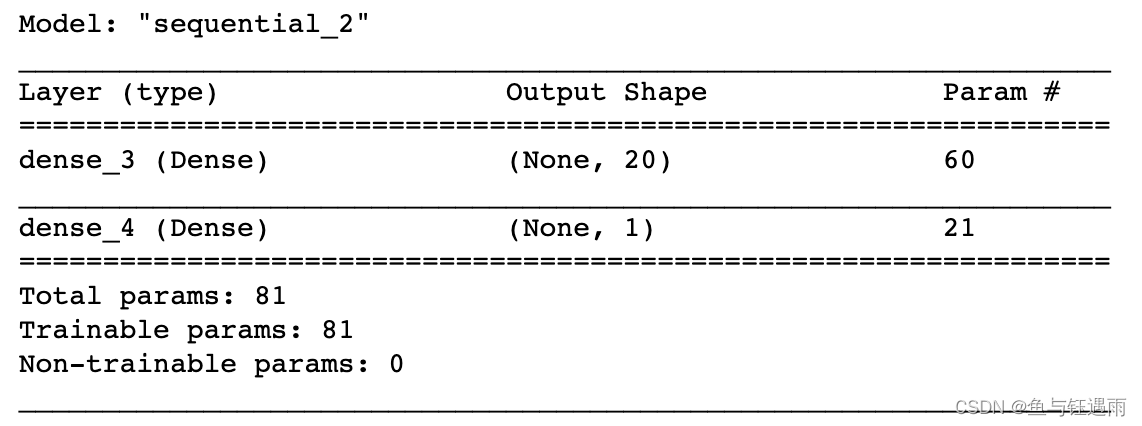
mlp.summary()
## 优化器 损失函数
mlp.compile(optimizer='adam', loss = 'binary_crossentropy')
4模型训练 + 5模型测试
mlp.fit(X_train, y_train, epochs=2000)
pred2 = mlp.predict(X_test)
result = []
for i in range(len(pred2)):
if pred2[i][0] > 0.5:
result.append(1)
else:
result.append(0)
y_pred = np.array(result)
accuray = sum(y_pred==y_test)/len(y_pred)
accuray
手写数字识别项目
数据可自行下载,也可通过代码自动下载:Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
from keras.datasets import mnist
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train.shape, y_train.shape, X_test.shape, y_test.shape
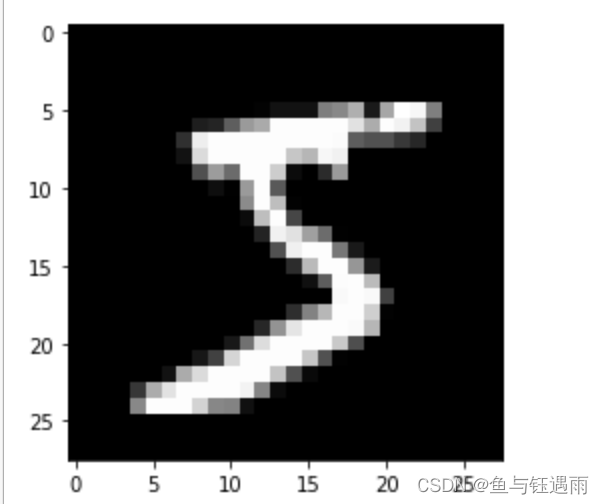
plt.imshow(X_train[0], cmap='gray')
plt.show()
print(y_train[0])
from keras.models import Sequential
from keras.layers import Dense, Activation
mlp = Sequential()
mlp.add(Dense(units = 392, input_dim = 784, activation = 'relu'))
mlp.add(Dense(units= 392, activation = 'relu') )
mlp.add(Dense(units= 10, activation = 'softmax') )# fc 层
mlp.summary()
mlp.compile(optimizer='adam', loss = 'categorical_crossentropy', metrics=['categorical_accuracy'])
X_train = X_train.reshape(X_train.shape[0], 784)
X_test = X_test.reshape(X_test.shape[0], 784)
# (x - xmin ) / (xmax - xmin ) 把数据 放到一个尺度下 [0, 1]
# 80/100 90/150
X_train = X_train/255
X_test = X_test/255
import tensorflow as tf
y_train = tf.one_hot(indices=y_train, depth=10,on_value=1, off_value=0, axis=1)
y_test = tf.one_hot(indices=y_test, depth=10,on_value=1, off_value=0, axis=1)
mlp.fit(X_train, y_train, epochs=10)
y_pred = mlp.predict(X_test)
y_pred = np.argmax(y_pred, axis=1)
y_pred = tf.convert_to_tensor(y_pred)
mlp.evaluate(X_test, y_test)















 1437
1437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









