






这是一篇关于视频理解的文章,主要介绍了一种可以达到3DCNN的效果的,但是保持2DCNN计算量和参数量的方法,叫做TSM(Tempora Shift Module)也就是在一簇要处理的帧之间,把相邻帧之间的channel进行了交替拼接!比如我把第一帧图片的某个channel和第二帧之间的的某个channel进行了交替,这样使得相邻帧之间包含了对方的信息,因而保证了时间上的信息的获取,也就是文章中说的时域建模!
这也就是为什么这个方法有效的原因了!
 【摘要Abstract】
【摘要Abstract】
1. 当前的难点:
(1)视频流的大量增长导致了对视频理解达到高准确率以及低消耗变得十分具有挑战性;
(2)传统的2DCNN虽然计算量小,但是却不能好好利用时域上的连续信息;(而这又是非常重要的)
(3)3DCNN虽然效果很好,但是却不得不面临密集的计算量,使得实际应用变得困难。
2.本文的着力点:
提出了TSM模块:能过兼顾良好效果表现以及计算量。(Specifically, it can achieve the performance of 3D CNN but maintain 2D CNN’s complexity.)
(1)TSM做了什么:在时间维度上,移动了帧与帧之间的一些channel,因此使得帧间的信息得到了交换;
(2)TSM可以怎么用:这个模块是可以直接应用在传统2DCNN的模型上,在以基本上近乎于零的运算量的消耗上使其获得时域上的信息建模!
(3)TSM还怎么用:本文作者不但在一般视频上做了工作,还进行了拓展工作,让该方法可以实时在线运行,但是shift的方式和offline不同;
(4)TSM的主要应用场景:Video recognition以及object detection!
【一、 介绍Introduction】
1.前面的铺垫:
(1)强调了时序的重要性:比如打开门的视频正反播放那么就是不一样的结果;
(2)2DCNN的局限性:仅仅利用单独的frames,因此并不能对时序信息进行很好的建模;
(3)3DCNN的局限性:尽管可以学习到时空信息,但是运算量巨大,使得应用困难。
2.简介TSM的思路和想法
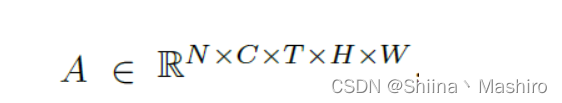
对于视频建模可以表示为:
N: batch size
C: channels
T: temporal dimension
H和W分别是高和宽,也就是分辨率
这篇文章的动机:既然卷积操作包括了shift和multiply-accumulate, 所以考虑在时间维度上也进行相应的操作看看效果如何。
文章提到的这种shift的方法在spatial中也有用到过,但是通常会面临两个问题。(!!!这里重要,也就是这篇文章主要做的事情,就是解决这两个问题)
(1)并不高效,尽管shift操作是基本zero FLOP的,但是这也同时会导致数据移动,这一步会使得延迟产生并且增加,而且尤其在视频文件中,该现象会更加显著,因为视频是5个维度的,上面说过;
(2)并不准确,这时第二个问题,如果shifting太多的channels的话将会损坏原有帧的空间新,也就是移动了,那么就不完整了,并不包含所有的该张图片本身应该具有的信息!
上面两个问题的解决:
(1)改进的shifts策略:并不是shift所有的channels,而是只选择性的shift其中的一部分,该策略能够有效的减少数据移动所带来的时间复杂度;
(2)TSM并不是直接被插入到从前往后的干道中的,而是以旁路的形式进行,如下图(b),因此在获得了时序信息的同时不会对二维卷积的空间信息进行损害!(到这里基本上听起来就很靠谱啦!)

文章的贡献:
(1)shift策略好,同时捕获视频中的时空信息;
(2)TSM移动一部分,是shift策略的改进版本;
(3)双向shift用来针对离线视频理解人物;
(4)单向shift用来针对在线视频理解人物(因为在线的下一刻的内容我们是不知道的),并且对资源友好,可以整合到edge 设备上进行运行!
【二、相关工作】
介绍了
(1)2D CNN
(2)3DCNN的方法
(3)可以利用两种信息的Trade-off的方法(可以理解为融合的方法)
【三、 TSM】
TSM的设计也是围绕着上面两个问题展开的:
1.为了降低shift移动太多会造成数据移动的开销,只shift一部分channels(按照比例移动,1/8, 1/4, 1/2, 1)
结果如下(延时与shift的比例的关系)左边图:
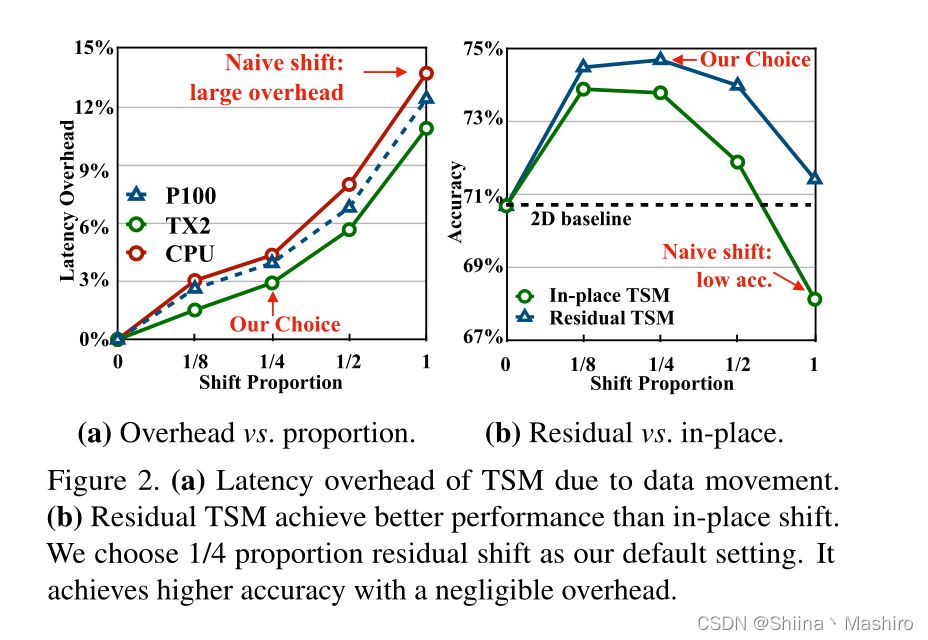
2. 为了保持特征的空间完整性,采用了残差模型,从旁路走TSM模块,使得TSM和直接的卷积两者都存在
这样只要控制好比例,就既保持了空间完整性,有增加了时序联系性。可以从上图的(b)中看出residual模式的效果更好!
也可以从实验结果中看出比例对准确性的影响(不能太大,也不能太小)
(1)shift比例太大,那么空间特征建模能力就会被削弱;
(2)shift比例太小,那么时序建模信息能力就会收到损害;
【四、 TSM的网络】
Offline的双向TSM 模型
(1)Backbone: ResNet-50
(2)TSM的加入模式:Residual Block
(3)特点1:对于每个插入的TSM模块,相当于其感受野得到了扩大2倍,因此可以获得很好的时序建模!
(4)特点2:TSM可以应用的任意的现成的2DCNN上面,使其具有3DCNN的效果但是同时维持2DCNN的计算量
Online的单向TSM模型
(1)方式:把之前的frames shifts到当前的frames上,从而也达到了时序信息建模的作用,从而实现在线的recognition功能!
(2)推理图如下:在推理的过程中,对于每一帧(比如Ft),只保存其首先的1/8的feature map。并且保存在cache中,对于下一帧(比如F t+1 ), 那么就是用Ft上的保存的1/8和当前帧Ft+1上的7/8组合起来。从而生成下一层feature map。如此循环下去!
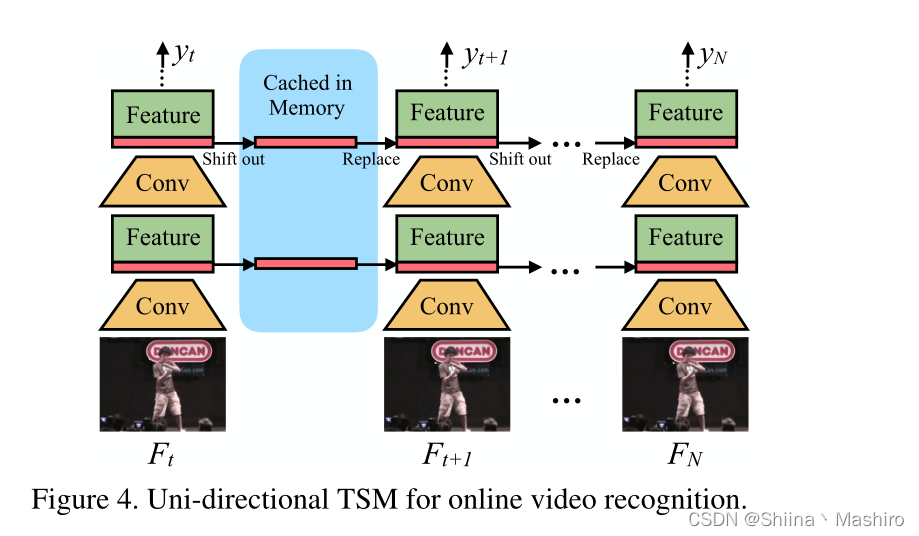
利用这样的单向shift策略!
有以下特点:
特点1:推理过程中的低时延;
特点2:低内存消耗
特点3:多层时序信息的融合(网络的每一层都能得到融合!)
【五、实验相关】
1.实验设置:
训练相关
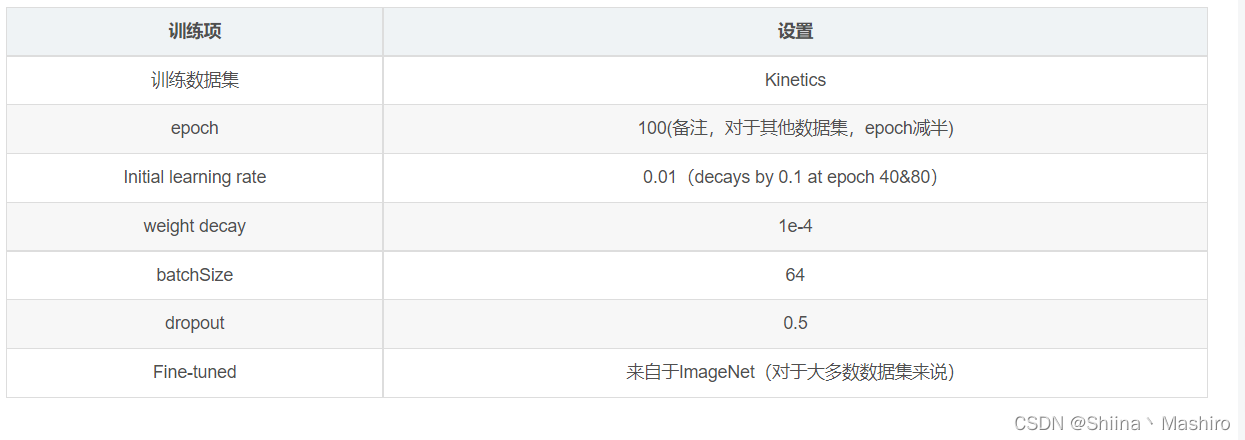
策略1:基于Kinetics上预训练的权重进行fine-tune, 并且冻结BN层
测试相关:
设置:为了获取高准确率,每个视频采样多个小片段(其中10个来自Kinetics, 两个来自于其他)
用到的模型:
ResNet-50 用来说明本方法比简单的2D CNN好了很多
用到的数据集:
(1)Kinetics: 类别繁多但是对时序信息并不是太敏感
(2)SomethingV1&V2 / Charades / Jester / 这些都是时序性比较强的
(3)UCF101 / HMDB51:对时序特征不是那么的敏感!
核心代码
class TemporalShift(nn.Module):
def __init__(self, net, n_segment=3, n_div=8, inplace=False):
super(TemporalShift, self).__init__()
self.net = net
self.n_segment = n_segment
self.fold_div = n_div
self.inplace = inplace
if inplace:
print('=> Using in-place shift...')
print('=> Using fold div: {}'.format(self.fold_div))
def forward(self, x):
x = self.shift(x, self.n_segment, fold_div=self.fold_div, inplace=self.inplace)
return self.net(x)
@staticmethod
def shift(x, n_segment, fold_div=3, inplace=False):
nt, c, h, w = x.size()
n_batch = nt // n_segment
x = x.view(n_batch, n_segment, c, h, w)
fold = c // fold_div
if inplace:
out = InplaceShift.apply(x, fold)
else:
out = torch.zeros_like(x)
out[:, :-1, :fold] = x[:, 1:, :fold] # shift left
out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right
out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift
return out.view(nt, c, h, w)















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









