






简介
这篇文章是一篇视频动作识别的论文,和之前的图像分类文章不同。从结构来说它做的是将当前帧的patch(作为Q)和下一帧的八邻域patches(作为K和V)之间做一个注意力。这九个patches根据offset predictor 预测做的注意力和原位置做注意力的相加。
另外一个特点就是以通用图像识别骨干网络(resnet)作为主干网络。

代码
这个帧间关系的模块用在了resnet的倒数三个layer。
x_origin = self.layer4(x)
x_dual = self.maxpool_dual(x) #两帧抽一帧
x_dual = self.layer4_dual(x_dual) #抽一帧之后再来resnet_layer
x_g_origin = self.pool(x_origin)
x_g_dual = self.pool_dual(x_dual)
x_g_origin = self.drop(x_g_origin)
x_g_dual = self.drop_dual(x_g_dual)
x1_origin = self.fc(x_g_origin)
x1_dual = self.fc_dual(x_g_dual)
return [x1_origin, x1_dual]
out_tmp是运动图,通过运动图求偏置。这个偏置是
2
k
2
2k^2
2k2个位移。
corre_weight做一个带偏置的注意力。
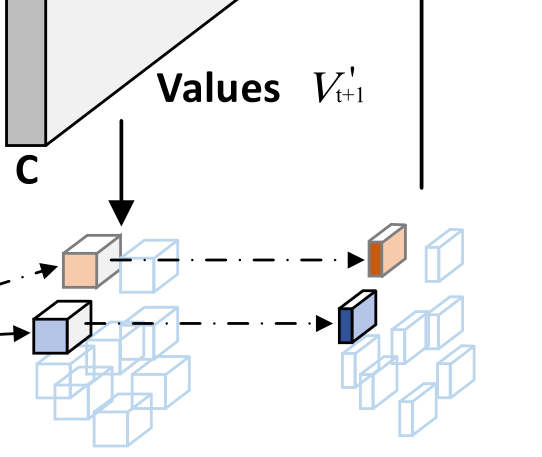
out_agg是融合,详细代码在下面:
# insert the aggregate block
out_tmp = out.clone()
out_tmp[:,:,1:,:,:] = out_tmp[:,:,:-1,:,:]
out_tmp = (torch.sigmoid(out - out_tmp) * out) + out # [sig(f_{t}-f_{t-1})*f_{t}]*f_{t}
offset = self.conv_offset(out_tmp)
corre_weight = self.def_cor(out, offset)
out_agg = self.def_agg(out, offset, corre_weight)
mask = torch.ones(out.size()).cuda()
mask[:,:,-1,:,:] = 0
mask.requires_grad = False
out_shift = out_agg.clone()
out_shift[:,:,:-1,:,:] = out_shift[:,:,1:,:,:]
out = out + out_shift * mask
代码写了一段cuda:核心代码如下:实现了下一帧的n个patch和本帧的patch相乘再乘一个通道权重。
float val = static_cast<float>(0);
const int c_in_start = group_id * c_in_per_defcor;
const int c_in_end = (group_id + 1) * c_in_per_defcor;
if (h_im > -1 && w_im > -1 && h_im < height && w_im < width){
for (int c_in = c_in_start; c_in < c_in_end; ++c_in){
const int former_ptr = (((n_out * channels + c_in) * times + t_former) * height + h_out) * width + w_out;
const int weight_offset = ((c_in * times + t_out) * kernel_h + kh) * kernel_w + kw;
const float* data_im_ptr = data_im + ((n_out * channels + c_in) * times + t_out) * height * width;
float next_val = im2col_bilinear_cuda(data_im_ptr, width, height, width, h_im, w_im);
val += (data_weight[weight_offset] * data_im[former_ptr] * next_val);
}
}
data_out[index] = val;
参考文章
[1]:可形变注意力机制的总结
[2]:CVPR2022《Stand-Alone Inter-Frame Attention in Video Models》















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









