






Abstract
现有的知识提炼方法侧重于基线设置,其中教师模型和培训策略不像最先进的方法那样强大和竞争,本文提出了一种称为DIST的方法,从更强大的教师中提炼出更好的知识。我们的经验发现,学生和更强的老师之间的预测差异可能会相当严重。因此,KL散度预测的精确匹配会干扰训练,使现有的方法表现不佳。在本文中,我们表明,简单地保留教师和学生的预测之间的关系就足够了,并提出了一个基于相关性的损失来明确地捕捉教师的内在阶级间关系。此外,考虑到不同的实例与每个类具有不同的语义相似度,我们还将这种关系匹配扩展到类内级别。我们的方法简单而实用,大量的实验表明,它能很好地适应各种架构、模型大小和训练策略,并能在图像分类、目标检测和语义分割任务上始终如一地达到最先进的性能。
一、Introduction
自动特征工程的出现促使深度神经网络在大量计算机视觉任务中取得显著成功,如图像分类、目标检测和语义分割在追求更好性能的道路上,目前的深度学习模型一般都在向更深、更广的方向发展。然而,由于计算和内存资源的限制,这种重型模型在实践中部署起来很笨拙。
对于一个与那些更大的模型具有竞争性能的高效模型,知识蒸馏(knowledge distillation, KD)被提出,通过在训练过程中提取更大的模型(teacher)的知识来提高高效模型(student)的性能。
知识蒸馏的本质在于如何将知识从教师手中形成并传递给学生。最直观而有效的方法是通过Kullback-Leibler (KL)散度来匹配师生之间的概率预测(反应)分数。这样,在训练过程中,可以用更多的信息信号来引导学生,从而比单独训练的学生有更有希望的表现。除了这种普通的预测匹配之外,其他研究也研究了中间表示中的知识,以进一步提高蒸馏性能,但这通常会导致额外的训练成本。例如,OFD提出通过多个中间层提取信息,但需要额外的卷积来进行特征对齐;CRD引入了传输成对关系的相对损失,但它需要为ImageNet图像的所有128-d特征保留内存库,并产生额外的260M FLOPs计算成本。
最近,一些研究解决了学生和教师模型规模显著不同时学生网络学习不良的问题。例如,TAKD提出通过增加一个模型大小适中的助教来减少师生之间的差异;DGKD通过密集聚集所有的辅助模型来指导学生,进一步完善了TAKD。然而,增加模型大小只是拥有更强大的教师的流行方法之一。缺乏对培养更强教师的训练策略及其对KD的影响的深入分析。最重要的是,一个足够通用的解决方案来解决较强教师带来的KD困难,而不是单独努力应对不同类型的较强教师(模型规模更大或训练策略更强)。
为了理解是什么造就了更强的教师及其对KD的影响,我们系统地研究了设计和训练深度神经网络的流行策略,并表明:
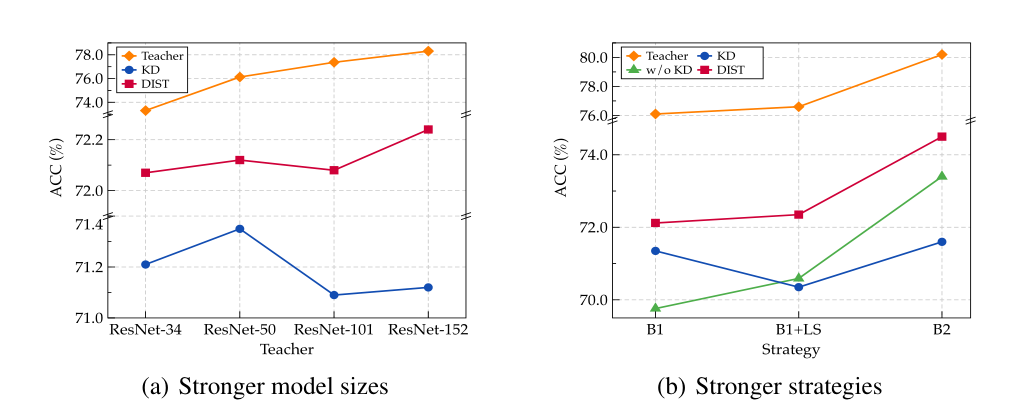
1.除了按比例扩大模型大小之外,还可以通过高级训练策略(如标签平滑和数据增强)获得更强的教师。然而,如果有一个更强的老师,学生在原始KD上的表现可能会下降,甚至比没有KD的从头开始训练还要糟糕,如图1所示。
2.当我们将教师和学生的训练策略转换为更强的训练策略时,教师和学生之间的差异往往会变得相当大(见图2)。在这种情况下,通过KL散度精确恢复预测可能具有挑战性,并导致香草KD的失败。
3.保留师生之间的预测关系是充分有效的。当知识从老师传递给学生时,我们真正关心的是保留老师的偏好(预测的相对排名),而不是准确地恢复绝对值。教师与学生预测的相关性有利于放宽KL散度的精确匹配,提炼出内在关系。
因此,在本文中,我们利用Pearson相关系数作为一种新的匹配方式来取代KL散度。此外,除了预测向量中的类间关系(见图3)之外,直观地认为不同的实例相对于每个类具有不同的相似性谱,我们还建议提取类内关系以进一步提高性能,如图3所示。具体地说,对于每一个类,我们在一个批次中收集所有实例对应的预测概率,然后将这种关系从教师转移到学生。我们提出的方法(称为DIST)非常简单、高效和实用,只需几行代码就可以实现(参见附录A.1),并且与普通的KD几乎具有相同的培训成本。因此,学生可以从匹配一个强大的老师的精确输出的负担中解放出来,但只有适当的引导才能提炼出那些真正有用的关系。
在基准数据集上进行了大量的实验,以验证我们在各种任务上的有效性,包括图像分类,目标检测和语义分割。实验结果表明,我们的DIST明显优于原始KD和那些精心设计的最先进的KD方法。例如,在ImageNet上使用相同的基线设置,我们的DIST在ResNet-18上达到了最高的72.07%的精度。使用更强的策略,我们的方法在最近的Transformer swin - t上获得了82.3%的准确率,将KD提高了1%。
二、Revisiting Prediction Match of KD
在原始知识蒸馏中,通过最小化教师模型和学生模型的预测分数之间的差异,将知识从预训练的教师模型转移到学生模型。
形式上,学生网络和教师网络的
l
o
g
i
t
s
Z
(
s
)
∈
R
B
×
C
logits Z^{(s)}∈R^{B×C}
logitsZ(s)∈RB×C和
Z
(
t
)
∈
R
B
×
C
Z^{(t)}∈R^{B×C}
Z(t)∈RB×C,其中B和C分别表示批大小和类数量,则原始KD损失表示为
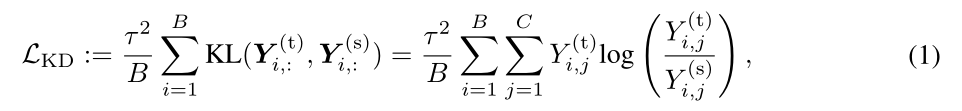 其中KL指的是Kullback-Leibler散度
其中KL指的是Kullback-Leibler散度
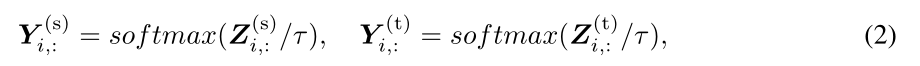
式(2)为概率预测向量,τ为控制logit柔软度的温度因子。
除了等式(1)中教师的软目标外,KD指出,与ground-truth标签一起训练学生是有益的,整体训练损失由原始分类损失
l
c
l
s
l_{cls}
lcls和KD损失
L
K
D
L_{KD}
LKD组成,即

其中
L
c
l
s
L_{cls}
Lcls通常是学生网络和基础真值标签预测之间的交叉熵损失,α和β是平衡损失的因素。
2.1 Catastrophic discrepancy with a stronger teacher
如第1节所示,教师对KD的影响尚未得到充分的研究,特别是当预训练教师的表现变得更强时,例如模型规模更大,或者使用更先进和竞争的策略进行训练,例如标签平滑、混合、自动增强等。因此,如图2所示,我们分别使用策略B1和策略B2**[与B1相比,B2训练获得更高的准确率,例如,在ResNet-18上,73.4% (B2)对69.8% (B1)]**对ResNet-18和ResNet-50进行单独训练,得到4个训练模型(R18B1、R18B2、R50B1和R50B2,准确率分别为69.76%、73.4%、76.13%和78.5%),然后使用KL散度(τ = 1和τ = 4)比较它们在预测概率Y上的差异。我们有以下看法:

**1.**与ResNet-50相比,ResNet-18的输出在更强的策略下没有太大变化。这意味着再现能力限制了学生的表现,当他们的差异变得更大时,学生要完全匹配老师的输出往往是相当具有挑战性的。
**2.**当教师和学生模型以更强的策略训练时,教师和学生之间的差异会更大。这表明当我们采用更强的KD训练策略时,KD损失与分类损失之间的错位会更严重,从而影响学员的训练。
因此,与KL发散的精确匹配(即,当且仅当教师和学生的输出完全相同时,损失达到最小)似乎过于雄心勃勃和苛刻,因为学生和教师之间的差异可能相当巨大。因为精确的匹配对于一个更强的老师来说可能是有害的,我们的直觉是发展一种轻松的方式来匹配老师和学生之间的预测。
三、DIST: Distillation from A Stronger Teacher
3.1 Relaxed match with relations
预测分数表明教师对所有类的信心(或偏好)。为了让老师和学生之间的预测轻松匹配,我们有动力去考虑我们真正关心的是老师的输出。而不是确切的概率值,实际上,在推理过程中,我们只关心它们之间的关系,即教师预测的相对等级。
这样,对于
R
C
×
R
C
→
R
+
R^C × R^C→R^+
RC×RC→R+的某个度量d(·,·),在式(1)的KL散度中,对于任意两个预测向量
Y
i
,
:
(
s
)
Y^{(s)}_{i,:}
Yi,:(s)和
Y
i
,
:
(
t
)
Y^{(t)}_{i,:}
Yi,:(t),如果a = b,则d(a, b) = 0。
然后作为一个松弛匹配,我们可以引入
R
C
→
R
C
R^C→R^C
RC→RC的附加映射φ(·)和ψ(·),使得

因此,d(a, b) = 0并不一定要求a和b完全相同。然而,由于我们关心a或b内的关系,映射φ和ψ应该是等渗的,并且不影响预测向量的语义信息和推理结果。
在这方面,一种简单而有效的等渗映射选择是正线性变换,即
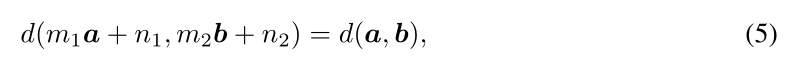
其中m1, m2, n1, n2为常数,m1 ×m2 > 0。因此,这种匹配在预测的尺度和位移的单独变化下可能是不变的。实际上,为了满足等式5的性质,我们可以采用广泛使用的Pearson’s距离作为度量,即

ρ
p
(
u
,
v
)
ρ_p(u, v)
ρp(u,v)是两个随机变量u和v之间的Pearson相关系数:
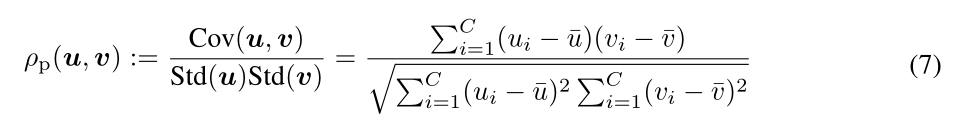
其中Cov(u, v)为u和v的协方差,
u
‾
\overline{u}
u和Std(u)分别为u的均值和标准差。
这样,我们就可以把这种关系定义为相关性。更具体地说,在原始KD中,原始的精确匹配可以被放松并替换为最大化线性相关,以保持教师和学生在每个实例的概率分布上的关系,我们称之为类间关系。形式上,对于每一对预测向量
Y
i
,
:
(
s
)
Y^{(s)}_{i,:}
Yi,:(s)和
Y
i
,
:
(
t
)
Y^{(t)}_{i,:}
Yi,:(t),相互关系损失可以表示为:
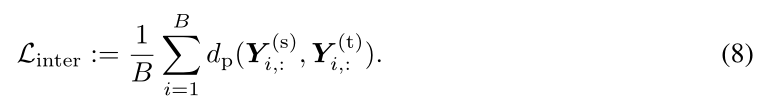
一些等渗映射或度量也可以像等式4一样用来放松匹配,如在第4.5节的经验研究的余弦相似度;其他更高级和更微妙的选择可以留给未来的工作。
3.2 Better distillation with intra-relations
除了类间关系,我们在每个实例中转移多个类的关系,每个类中多个实例的预测分数也很有用。这个分数表示多个实例与一个类的相似性。例如,假设我们有三张分别包含“猫”、“狗”和“飞机”的图像,它们在“猫”类上有三个预测分数,分别表示为e、f和g。一般来说,“猫”的图像对“猫”类的分数应该是最大的,而“飞机”的分数应该是最小的,因为它是无生命的。这种“e > f > g”的关系也可以转移到学生身上。此外,即使是同一类别的图像,语义相似度的内在类内方差实际上也提供了信息。它表明了老师的先验判断,在这个类里投哪一个更可靠。

图3:我们的DIST和现有KD方法的区别。传统KD将student (s∈R5)和teacher (t∈R5)的输出点明智地匹配起来;实例关系方法在特征层上操作,分别测量学生和教师实例之间的内部相关性(corr),然后将教师的相关性传递给学生。我们的DIST建议维持学生和老师之间的班级间和班级内的关系。班级间关系:教师和学生在每个实例上的预测概率分布之间的相关性。类内关系:每个类上所有实例的概率的相关性。
因此,我们也鼓励提炼这种内部关系以获得更好的性能。实际上,将每一行的预测矩阵Y (s)和Y (t)定义为
Y
i
,
:
(
s
)
Y^{(s)}_{i,:}
Yi,:(s)和
Y
i
,
:
(
t
)
Y^{(t)}_{i,:}
Yi,:(t),则上述相互关系是为了使相关行明智地最大化(见图3)。相反,对于内关系,则相应的损失是为了使相关列明智地最大化,即:
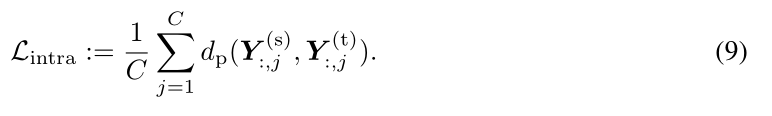
因此,整体训练损失
L
t
r
L_{tr}
Ltr可以由分类损失、类间KD损失和类内KD损失组成,即

其中α、β和γ是平衡损失的因子。这样,通过关系损失,我们赋予了学生或多或少的自由来自适应匹配教师网络的输出,从而在很大程度上提高了蒸馏性能。
四、Experiments
4.1 Image Classification
Baseline results on ImageNet
我们首先使用基线设置将我们的方法与先前的工作进行比较。如表2所示,我们的DIST显著优于先前的KD方法。需要注意的是,我们的方法只对模型的输出进行处理,其计算成本与KD相似[16]。然而,与那些精心设计的方法相比,它甚至达到了更好的性能。例如,CRD[41]需要为ImageNet图像的所有128-d特征保留一个内存库,并产生额外的260M FLOPs的计算成本;SRRL[47]和Review[7]需要额外的卷积来进行特征对齐。DIST的实现可以在附录A.1中找到,与这些方法相比,它非常简单。

Distillation from stronger teacher models
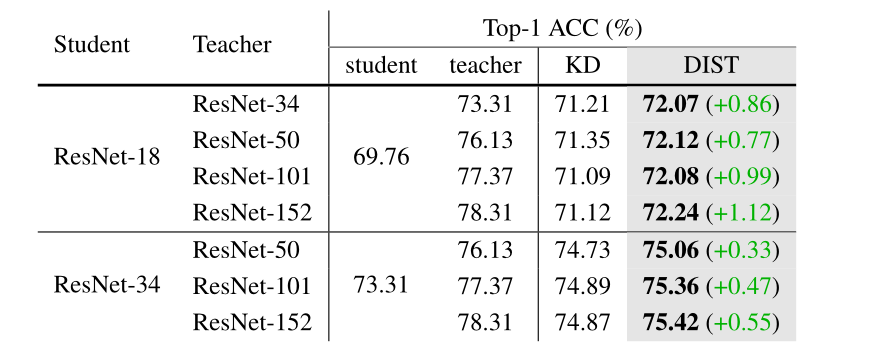
由于更强的教师来自更大的模型尺寸和更强的策略,我们在这里首先进行实验,将我们的DIST与基线策略B1的ResNets不同尺度(模型尺寸)上的vanilla KD进行比较。如表3所示,当教师规模更大时,ResNet-18学生的表现甚至比ResNet-50作为教师的表现还要差。尽管如此,我们的DIST在教师体型较大的情况下呈现上升趋势,并且与KD相比的改进也变得更加显著,这表明我们的DIST更好地解决了学生与体型较大的教师之间的巨大差异。
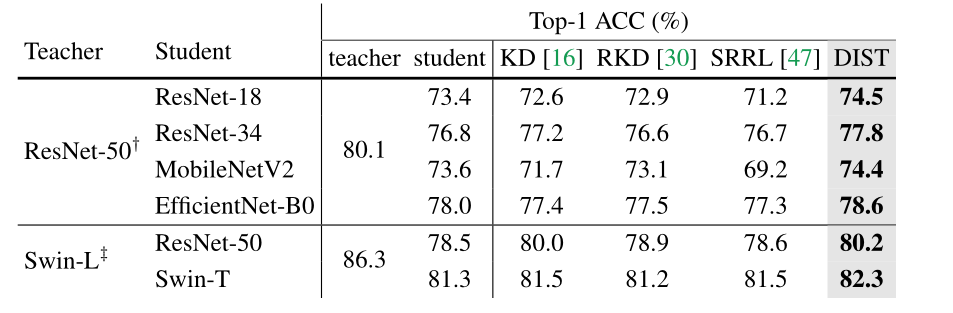
Distillation from stronger training strategies
最近,通过复杂的训练策略和强大的数据增强(例如:, TIMM[44]在ResNet-50上的准确率为80.4%,而基线策略B1仅为76.1%)。然而,大多数KD方法仍然采用简单的训练设置进行实验。很少有人研究KD方法是否适用于高级策略。通过这种方式,我们使用高级训练策略进行实验,并将我们的方法与vanilla KD、基于实例关系的RKD[30]和SRRL[47]进行比较。
我们首先训练具有强策略的传统cnn,也使用[44]训练的具有80.1%准确率的强ResNet-50作为老师。如表4所示,在相似的体系结构(ResNet-18、ResNet-34)和不同的体系结构(MobileNetV2、EfficientNet-B0)上,我们的DIST都能达到最佳性能。请注意,RKD和SRRL的表现可能比从头开始训练更差,特别是当学生很小(ResNet-18和MobileNet)或教师和学生的架构相当不同(ResNet-50和swwin - l)时,这可能是因为它们专注于中间特征,与预测相比,这对学生恢复教师的特征更具挑战性。
此外,我们对最新的最先进的swin - transformer进行了实验[27]。结果表明,我们的DIST在更强大的模型和策略上获得了改进。例如,对于swin - L teacher,我们的方法分别提高了ResNet-50和swin - T的1.7%和1.0%。
CIFAR-100
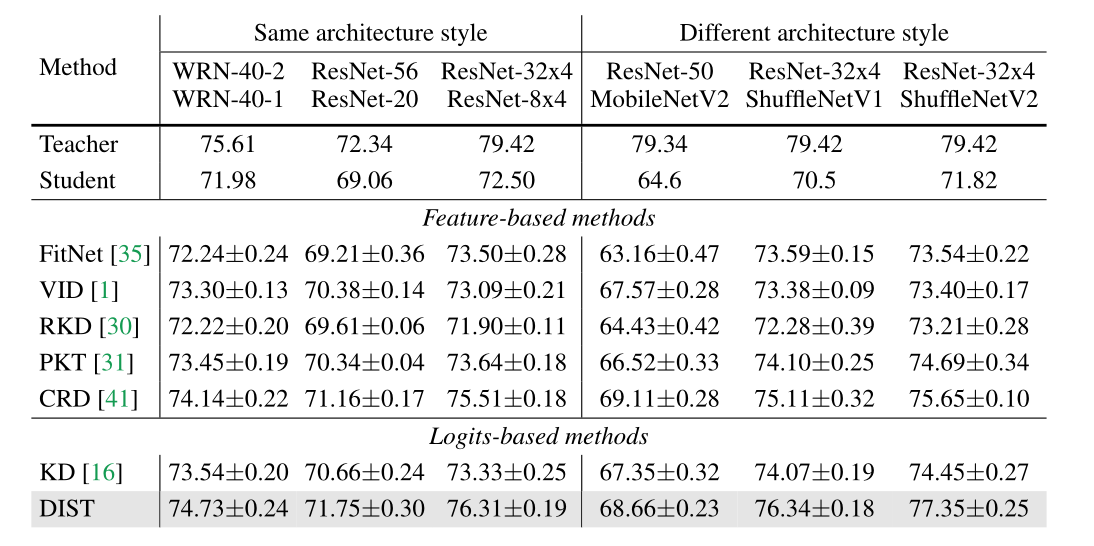
表5中对CIFAR-100数据集的结果表明,通过对预测逻辑进行提取,我们的方法甚至优于那些精心设计的特征提取方法。
4.2 Ablation studies
Effects of inter-class and intra-class correlations
本文提出了两种类型的关系:阶级间关系和阶级内关系。为了验证每种关系的有效性,我们分别进行了实验,对学生进行了这些关系的训练。表8的结果表明,类间关系和类内关系都优于普通KD;此外,将它们组合在一起可以进一步提高性能。

Effect of intra-class relation in vanilla KD
为了研究原始KD中类内关系的有效性,我们采用KL散度作为关系度量来训练我们的DIST,记为DIST (KL div)[具体来说,原始KD与只有类间关系的DIST (KL div.)相同。]。如表8所示,在原始KD中加入类内关系也可以提高性能(从71.21%提高到71.62%)。然而,当学生仅使用类内关系进行训练时,使用KL散度的改善不如使用Pearson相关(70.61% vs. 71.55%),因为类内分布的均值和方差可能会发生变化。
五、Conclusion
本文提出了一种新的知识蒸馏方法——DIST,以实现从更强的教师中进行更好的知识蒸馏。我们实证研究了学生与较强教师之间的灾难性差异问题,并提出了一种基于关系的损失来放松KL散度在线性意义上的精确匹配。我们的DIST方法简单而有效地处理强教师。大量的实验证明了我们在各种基准任务中的优势。例如,DIST甚至优于专门为对象检测和语义分割而设计的最先进的KD方法。















 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









