






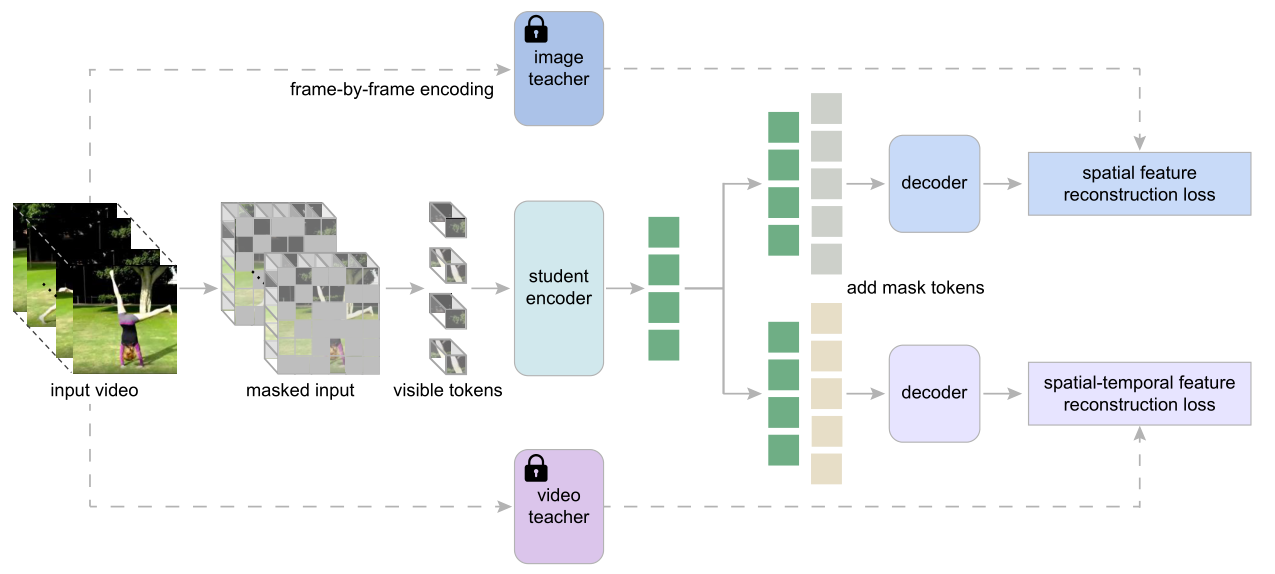
Masked Video Distillation蒸馏损失函数伪码实现:
# f: student encoder # encoder
# g_img: decoder for reconstructing spatial features # decoder for image
# g_vid: decoder for reconstructing spatial-temporal # decoder for video
features
# t_m: learnable mask tokens # 掩码token
# h_img: image teacher model #image teacher
# h_vid: video teacher model #video teacher
for x, m in loader: # x: video data, m: mask
x_pe = patch_emb(x) # patch embedding of input #patch embedding
x_vis = mask_select(x_pe, 1 - m) # masking tokens # 可见token
q_vis = f(x_vis) # visible local patch features # 编码结果
# reconstruction of target features
p_img = g_img(concat(q_vis, t_m)) # 重建image结果
p_vid = g_vid(concat(q_vis, t_m)) # 重建video结果
# compute target features with teacher models
k_img = h_img(x) # target spatial features # image teacher 预测结果
k_vid = h_vid(x) # target spatial-temporal features # video teacher 预测结果
# compute reconstruction loss
loss_img = smooth_L1_loss(p_img ? m, k_img ? m) # image loss
loss_vid = smooth_L1_loss(p_vid ? m, k_vid ? m) # video loss
loss = λ1 * loss_img + λ2 * loss_vid #总体损失函数
loss.backward()
optimizer.step() # optimizer update```
Masked Video Distillation蒸馏损失函数源码实现:
with torch.cuda.amp.autocast():
output_features, output_video_features = model(videos, bool_masked_pos)
with torch.no_grad():
image_teacher_model.eval() #训练image teacher
if time_stride_loss:
teacher_features = image_teacher_model( #得到image teacher的预测结果
rearrange(videos_for_teacher[:, :, ::tubelet_size, :, :], 'b c t h w -> (b t) c h w'),
)
teacher_features = rearrange(teacher_features, '(b t) l c -> b (t l) c', t=T//tubelet_size)
else:
teacher_features = image_teacher_model(
rearrange(videos_for_teacher, 'b c t h w -> (b t) c h w'),
)
teacher_features = rearrange(teacher_features, '(b t d) l c -> b (t l) (d c)', t=T//tubelet_size, d=tubelet_size)
if norm_feature:
teacher_features = LN_img(teacher_features)
video_teacher_model.eval() # 训练video teacher
videos_for_video_teacher = videos if args.video_teacher_input_size == args.input_size \
else videos_for_teacher
video_teacher_features = video_teacher_model(videos_for_video_teacher)#得到video teacher的预测结果
if norm_feature:
video_teacher_features = LN_vid(video_teacher_features)
B, _, D = output_features.shape
loss_img_feat = loss_func_img_feat(#image teacher 的 loss
input=output_features,
target=teacher_features[bool_masked_pos].reshape(B, -1, D)
)
loss_value_img_feat = loss_img_feat.item()
B, _, D = output_video_features.shape
loss_vid_feat = loss_func_vid_feat(#video teacher 的 loss
input=output_video_features,
target=video_teacher_features[bool_masked_pos].reshape(B, -1, D)
)
loss_value_vid_feat = loss_vid_feat.item()
loss = image_loss_weight * loss_img_feat + video_loss_weight * loss_vid_feat#总的损失函数
```















 2405
2405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









