







看见知乎上说Keras不错,基于Python的,后台是基于Theano或Tensorflow。
安装
环境:ubuntu14.04
首先,安装python环境、theano和keras
sudo apt-get install python-numpy python-scipy python-dev python-pip python-nose g++ libopenblas-dev git
sudo pip install Theano
sudo pip install keras数据及代码准备
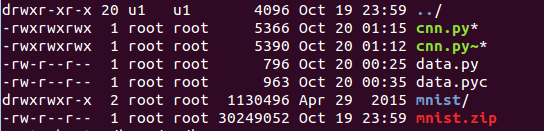
根据博客,下载mnist.zip数据及github上的cnn.py和data.py,解压到同一个目录下:
注意:keras默认的后台是tensorflow,改成theano,修改~/.keras/keras.json文件即可:
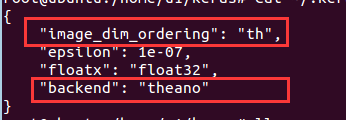
image_dim_ordering和backend两个参数都要修改(默认是tf和tensorflow)。
训练CNN模型
执行python cnn.py文件,即可执行训练:
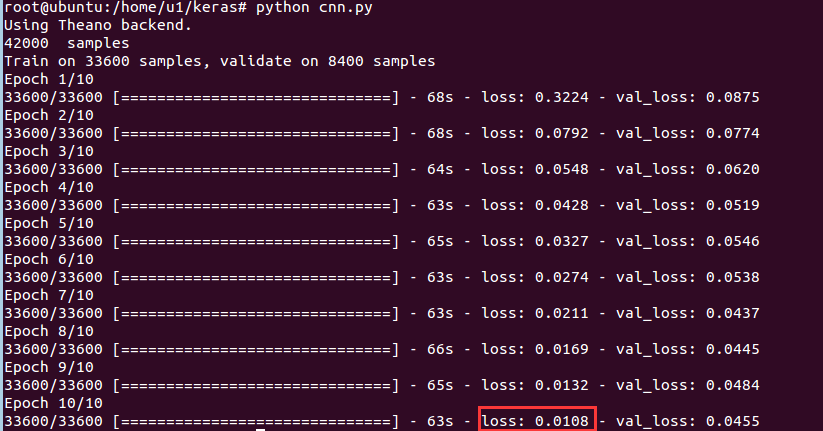
跑了10个epoch,准确率将近99%!
下面通过代码看看CNN长得啥样:
###############
#开始建立CNN模型
###############
#生成一个model
model = Sequential()
#第一个卷积层,4个卷积核,每个卷积核大小5*5。1表示输入的图片的通道,灰度图为1通道。
#border_mode可以是valid或者full,具体看这里说明:http://deeplearning.net/software/theano/library/tensor/nnet/conv.html#theano.tensor.nnet.conv.conv2d
#激活函数用tanh
#你还可以在model.add(Activation('tanh'))后加上dropout的技巧: model.add(Dropout(0.5))
model.add(Convolution2D(4, 5, 5, border_mode='valid',input_shape=(1,28,28)))
model.add(Activation('tanh'))
#第二个卷积层,8个卷积核,每个卷积核大小3*3。4表示输入的特征图个数,等于上一层的卷积核个数
#激活函数用tanh
#采用maxpooling,poolsize为(2,2)
model.add(Convolution2D(8, 3, 3, border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#第三个卷积层,16个卷积核,每个卷积核大小3*3
#激活函数用tanh
#采用maxpooling,poolsize为(2,2)
model.add(Convolution2D(16, 3, 3, border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#全连接层,先将前一层输出的二维特征图flatten为一维的。
#Dense就是隐藏层。16就是上一层输出的特征图个数。4是根据每个卷积层计算出来的:(28-5+1)得到24,(24-3+1)/2得到11,(11-3+1)/2得到4
#全连接有128个神经元节点,初始化方式为normal
model.add(Flatten())
model.add(Dense(128, init='normal'))
model.add(Activation('tanh'))
#Softmax分类,输出是10类别
model.add(Dense(10, init='normal'))
model.add(Activation('softmax'))
#############
#开始训练模型
##############
#使用SGD + momentum
#model.compile里的参数loss就是损失函数(目标函数)
sgd = SGD(lr=0.05, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
#调用fit方法,就是一个训练过程. 训练的epoch数设为10,batch_size为100.
#数据经过随机打乱shuffle=True。verbose=1,训练过程中输出的信息,0、1、2三种方式都可以,无关紧要。show_accuracy=True,训练时每一个epoch都输出accuracy。
#validation_split=0.2,将20%的数据作为验证集。
model.fit(data, label, batch_size=100, nb_epoch=10,shuffle=True,verbose=1,validation_split=0.2)
参考文章:http://blog.csdn.net/zhoubl668/article/details/45559955
keras中文文档:http://keras-cn.readthedocs.io/en/latest/















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









