







〔探索AI的无限可能,微信关注“AIGCmagic”公众号,让AIGC科技点亮生活〕
本文作者:AIGCmagic社区 刘一手
前言
随着人工智能技术的发展,多模态大型语言模型(MLLMs)在视觉-文本理解领域取得了显著进展。mPLUG-DocOwl系列模型作为其中的佼佼者,展示了强大的无OCR文档理解能力。本文将解读mPLUG-DocOwl系列模型的架构、训练策略及其在多页文档理解中的应用。
mPLUG-DocOwl系列模型通过统一的指令调优策略、高效的视觉抽象器和低秩适应模块,提升了模型在各种文档理解任务上的性能。mPLUG-DocOwl 1.5引入了统一的结构学习框架和高质量的推理调优数据集,进一步增强了模型的结构理解能力和详细解释能力。
最新的mPLUG-DocOwl2通过高分辨率文档压缩模块和三阶段的训练框架,实现了高效的多页文档理解,显著减少了计算资源的消耗,并在多页文档理解任务中表现出色。

| 模型名称 | 标题 | 主要贡献 |
|---|---|---|
| mPLUG-DocOwl | Modularized Multimodal Large Language Model for Document Understanding | 提出模块化MLLM,平衡语言、视觉-语言和文档理解任务; 构建LLMDoc测试集,评估文档理解能力; 实验结果显示在无OCR文档理解上超越现有方法; |
| mPLUG-DocOwl 1.5 | Unified Structure Learning for OCR-free Document Understanding | 强调结构信息在视觉文档理解中的重要性; 设计H-Reducer视觉到文本模块; 构建DocStruct4M训练集,支持结构学习; 在多个视觉文档理解任务上达到SOTA性能; |
| mPLUG-DocOwl 2 | High-Resolution Compressing for OCR-Free Multi-Page Document Understanding | 提出高分辨率DocCompressor模块,压缩高分辨率文档图像; 在多页文档理解基准测试中达到SOTA性能,减少首次标记延迟; 与类似模型相比,使用更少的视觉标记实现可比性能; |
mPLUG-DocOwl 1.0
研究背景
- 研究问题:这篇文章要解决的问题是如何在不进行领域特定训练的情况下,提升多模态大型语言模型(MLLMs)在无需OCR(光学字符识别)的文档理解任务中的表现。现有的多模态大型语言模型如mPLUG-Owl在浅层OCR-free文本识别中展示了有希望的零样本能力,但在处理复杂的表格或大块文本时表现不佳。
- 研究难点:该问题的研究难点包括:缺乏领域特定训练导致模型难以理解视觉文本与图像中对象之间的复杂关系;现有模型在处理图表、文档和网页等复杂文档类型时表现有限。
- 相关工作:该问题的研究相关工作包括两类模型:一类是利用现成的OCR模型或API从图像中识别文本,然后设计预训练任务以促进跨模态对齐;另一类是端到端模型,利用高分辨率图像编码器在预训练阶段学习文本识别。然而,这两类模型都依赖于特定领域的微调,无法实现开放域的指令理解性能。
研究方法
这篇论文提出了mPLUG-DocOwl,用于解决OCR-free文档理解问题。具体来说,
-
模块化框架:mPLUG-DocOwl基于mPLUG-Owl,采用模块化框架,将预训练的LLM与视觉知识模块链接起来,实现文本和图像的对齐。该框架包括一个视觉抽象器模块,用于提取和蒸馏视觉特征。

-
统一指令调优:通过统一指令调优策略,mPLUG-DocOwl在语言、通用视觉-语言和文档指令调优数据集上进行联合训练。训练过程中,视觉编码器和语言模型保持冻结,只有视觉抽象器和LLM中的低秩适应(LoRA)进行微调。
-
数据集构建:为了确保模型的多样性,收集了包括视觉问答(VQA)、信息抽取(IE)、自然语言推理(NLI)和图像字幕(IC)在内的多种文档理解数据集。这些数据集被转换为统一的指令格式“<image>Human:{question} AI:{answer}”。
实验设计
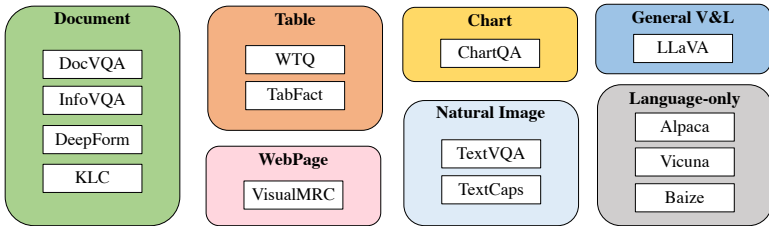
- 数据收集:为了全面评估模型的能力,构建了五个场景的评估数据集,包括表格(TabFact)、图表(ChartQA)、文档(DocVQA)、自然图像(TextVQA)和网页(VisualMRC)。每个数据集从测试集中抽取20张图像,其中10张使用原始问题作为指令,另外10张要求标注者编写更具挑战性的指令。
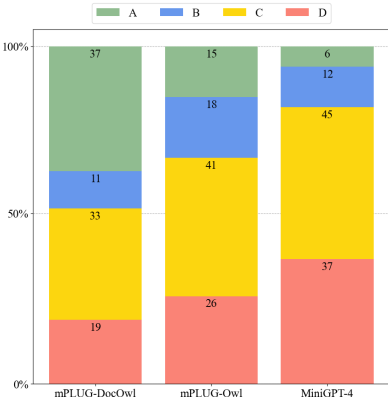
- 人类评估:根据Self-Instruct提出的评分标准,进行人类评估以评分模型的响应。评分标准为A(正确且令人满意的响应)、B(可接受的响应但有轻微缺陷)、C(响应符合指令但有显著错误)和D(无关或无效的响应)。
- 训练细节:采用两阶段训练范式,第一阶段仅使用文档理解数据和LoRA进行微调,持续10个epoch;第二阶段进一步冻结视觉抽象器,仅训练LoRA,并引入语言-only和通用视觉-语言指令调优数据,持续3个epoch。其他训练超参数与mPLUG-Owl相同。
结果与分析
-
LLMDoc评估:在LLMDoc上,mPLUG-DocOwl的表现显著优于其他多模态大型语言模型。在100个测试样本中,有37个样本被评为“A”,显示出更强的文档理解能力。
-
基准评估:在DUE-Benchmark和其他图表、自然图像和网页数据集上,mPLUG-DocOwl在不进行每个数据集微调的情况下,取得了可比甚至更好的性能。
-
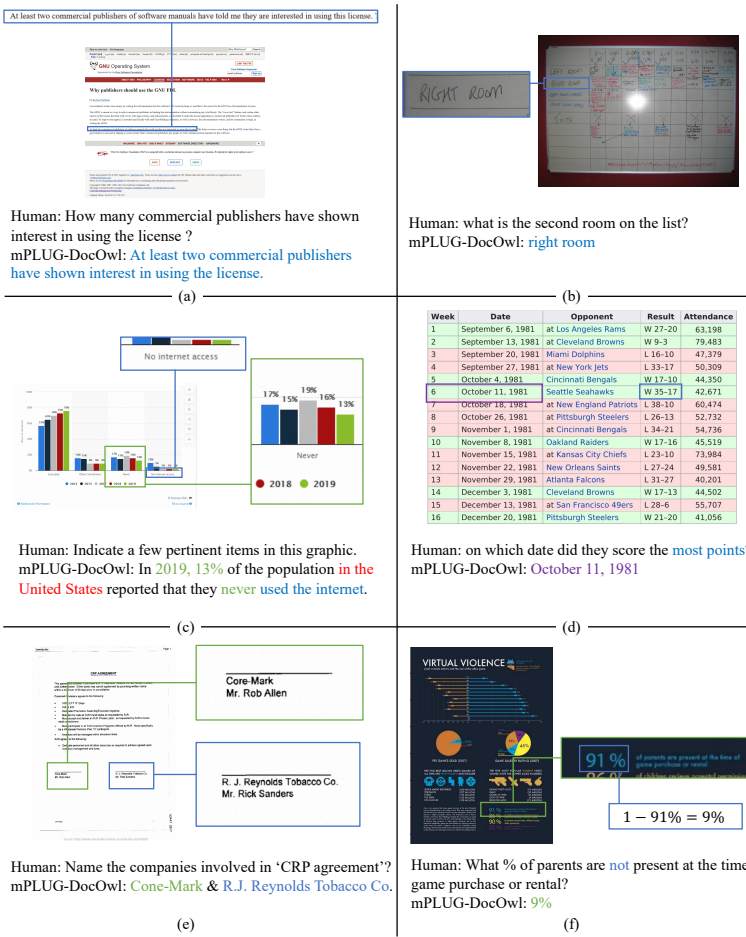
定性分析:定性结果显示,mPLUG-DocOwl能够准确处理复杂网页截图、手写字符表格、图表总结等任务,但也存在一些错误输出,如“in the United States”和“never used internet”。

总体结论
在这项工作中,通过将文档理解数据纳入指令微调,mPLUG-DocOwl成功地将多样化的OCR-free文档理解能力注入到mPLUG-Owl中。实验结果表明,mPLUG-DocOwl在OCR-free文档理解方面达到了可比甚至更好的性能。此外,得益于语言-only和通用视觉-语言指令调优,mPLUG-DocOwl能够更好地理解用户指令和意图,实现更复杂的交互。然而,人类评估揭示出mPLUG-DocOwl在文档相关的常识推理、数学计算和创造性生成方面仍存在挑战。这为未来开发更强的文档理解能力提供了宝贵的见解。
QA解答
问题1:mPLUG-DocOwl在构建指令调优数据集时,具体使用了哪些数据集?这些数据集是如何分类的?
mPLUG-DocOwl在构建指令调优数据集时,使用了多种文档理解数据集,具体包括视觉问答(VQA)、信息抽取(IE)、自然语言推理(NLI)和图像字幕(IC)。这些数据集被分类为以下几类:
- 视觉问答(VQA):包括ChartQA、DocVQA、InfographicsVQA、WikiTableQuestions、TextVQA和VisualMRC等数据集。
- 信息抽取(IE):包括DeepForm和Kleister Charity(KLC)数据集。
- 自然语言推理(NLI):主要是TabFact数据集。
- 图像字幕(IC):包括TextCaps数据集。
这些数据集被用来训练mPLUG-DocOwl,以增强其在不同文档理解任务中的能力。
问题2:在LLMDoc评估中,mPLUG-DocOwl与其他模型相比表现如何?具体有哪些优势?
在LLMDoc评估中,mPLUG-DocOwl的表现显著优于其他模型。具体优势包括:
- 更高的准确率:在LLMDoc的100个测试样本中,mPLUG-DocOwl有37个响应被评为“A”,这是所有参与评估模型中最高的比例,表明其在多样化文档场景中具有更强的理解能力。
- 更好的泛化能力:尽管没有对每个数据集进行微调,mPLUG-DocOwl在DUE-Benchmark和其他图表、自然图像和网页数据集上仍然取得了可比或更好的性能,显示出其良好的泛化能力。
- 多样化的应用场景:mPLUG-DocOwl在处理表格、图表、文档、自然图像和网页等多种类型的文档时表现出色,能够准确找到答案、理解手绘表格、总结图表关键点、处理扫描文档等。
问题3:mPLUG-DocOwl在训练过程中是如何进行优化和改进的?具体的训练步骤是什么?
mPLUG-DocOwl的训练过程采用了两阶段优化策略:
- 第一阶段:在这个阶段,视觉编码器和语言模型保持冻结状态,只对视觉抽象器和LLM中的低秩适应(LoRA)进行微调。训练数据仅为文档理解数据,训练10轮。
- 第二阶段:在第一阶段的基础上,进一步冻结视觉抽象器,只训练LoRA。除了文档理解数据外,还引入了语言-only和通用视觉-语言指令调优数据,并进行了3轮训练。其他训练超参数与mPLUG-Owl相同。
这种分阶段的训练方法使得模型能够在初期专注于文档理解能力的提升,同时在后期通过引入更多的指令调优数据来增强其多样化和泛化能力。
mPLUG-DocOwl 1.5
研究背景
- 研究问题:这篇文章要解决的问题是如何在无需OCR(光学字符识别)的情况下,提升多模态大型语言模型(MLLMs)在视觉文档理解任务中的性能。具体来说,现有的MLLMs在处理文本丰富的图像(如文档、网页、表格和图表)时,缺乏对文本和结构信息的通用理解能力。
- 研究难点:该问题的研究难点包括:如何有效地编码高分辨率图像中的结构信息,以及如何理解和定位图像中的文本。现有的视觉到文本(V2T)模块在处理高分辨率图像时会丢失空间信息,导致模型难以高效理解图像内容。
- 相关工作:该问题的研究相关工作有:一些工作尝试通过设计文本阅读任务来增强文本识别能力,但这些工作要么忽略了结构理解,要么只覆盖了有限的文本丰富图像领域。现有的MLLMs在处理高分辨率图像时,通常选择进一步训练或添加高分辨率视觉编码器,但这些方法在处理复杂文本和结构信息时仍存在不足。
研究方法
这篇论文提出了统一结构学习(Unified Structure Learning, USL)用于解决视觉文档理解问题。具体来说,
- H-Reducer模块:为了更好地保持结构和空间信息,设计了一个简单的有效的视觉到文本模块,称为H-Reducer。该模块通过卷积层聚合水平相邻的视觉特征,从而减少视觉序列长度并保持空间信息。

-
统一结构学习:设计了结构感知解析任务和多粒度文本定位任务,涵盖五个领域:文档、网页、表格、图表和自然图像。结构感知解析任务通过添加换行符和空格来表示文本的结构,多粒度文本定位任务则进一步增强了模型将视觉上的文本与图像中的具体位置关联起来的能力。

-
多任务微调:在统一结构学习之后,模型在多个下游任务上进行联合微调,以学习如何根据用户的指令回答问题。
实验设计
-
数据集构建:构建了一个综合训练集DocStruct4M,通过收集多个公开可用的数据集并构建结构感知的文本序列和多粒度的文本与边界框对来支持统一结构学习。

-
训练框架:采用两阶段训练框架,第一阶段进行统一结构学习,冻结LLM参数并调整视觉编码器和H-Reducer;第二阶段进行多任务微调,主要学习如何根据用户的指令回答问题。
-
指令调优集:构建了一个高质量的指令调优集DocReason25K,基于原始问题从多个数据集中收集详细的解释,并通过与ChatGPT4交互生成。
结果与分析
- 主要结果:在10个文本丰富图像理解的基准测试中,DocOwl 1.5在所有10个基准测试中都取得了最先进的OCR无关性能,相比类似大小的模型在5个基准测试中提高了超过10个百分点。
- 消融研究:通过消融研究验证了H-Reducer和统一结构学习的有效性。结果表明,初始化为更强的通用MLLMs带来了更好的文本丰富图像理解性能,调整视觉编码器显著提高了文档理解性能,H-Reducer在保持丰富文本信息和视觉特征对齐方面表现出色,统一结构学习显著提高了不同领域的性能。
- 多粒度文本定位评估:直接比较了统一结构学习后的文本定位性能,验证了其在保持空间特征方面的优越性。

总体结论
这篇论文提出了一种新的统一结构学习方法,通过设计H-Reducer模块和构建综合训练集DocStruct4M,显著提升了MLLMs在视觉文档理解任务中的性能。实验结果表明,DocOwl 1.5在多个基准测试中取得了最先进的OCR无关性能,验证了其在文本丰富图像理解方面的强大能力。未来的工作将进一步扩展到自然场景文本的理解。
QA解答
问题1:统一结构学习包括哪些具体任务?这些任务在提升MLLMs性能方面的作用是什么?
统一结构学习包括结构感知的解析任务和多粒度的文本定位任务,涵盖五个领域:文档、网页、表格、图表和自然图像。具体任务包括:
- 文档解析:通过添加换行符和空格来表示文档或网页的结构。
- 表格解析:使用Markdown语法表示表格结构,并通过特殊文本标记表示跨行和跨列的单元格。
- 图表解析:将图表解析为表格,并使用Markdown代码表示数据表。
- 自然图像解析:将场景文本与一般标题结合形成目标解析序列。
- 多粒度文本定位:设计了单词、短语、行和块四个粒度的文本定位任务,以支持文本位置学习。
这些任务的作用在于帮助MLLMs更好地理解和解析文本丰富的图像,从而提升其在视觉文档理解任务中的性能。通过这些任务,模型能够学习到文本的结构信息,增强对文本和布局的理解,进而提高在各种视觉文档理解任务中的准确性和效率。
问题2:DocOwl 1.5在实验中是如何进行训练的?两阶段训练框架的具体步骤是什么?
DocOwl 1.5的训练分为两个阶段:
1、第一阶段:统一结构学习
- 冻结LLM参数:在第一阶段,LLM的参数保持不变,只调优视觉编码器和H-Reducer。
- 调优视觉编码器和H-Reducer:使用DocStruct4M数据进行训练,学习率和批量大小分别设置为1e-4和1,024,进行12,000次迭代训练。
2、第二阶段:多任务微调
- 解冻LLM参数:在第二阶段,LLM的参数被解冻,与其他模块一起进行调优。
- 多任务微调:使用下游任务数据进行训练,学习率为2e-5,进行6,500次迭代训练,批量大小为256。
这种两阶段训练框架的目的是先通过统一结构学习打好基础,使模型能够理解和解析文本丰富的图像,然后再通过多任务微调进一步提升模型在各个具体任务上的性能。
mPLUG-DocOwl 2.0
研究背景
- 研究问题:这篇文章要解决的问题是如何在多页文档理解任务中实现高效的高分辨率图像压缩,同时保持OCR无误差的多页文档理解性能。
- 研究难点:该问题的研究难点包括:高分辨率文档图像生成大量视觉标记(tokens),导致GPU内存占用过高和推理速度变慢;现有压缩架构难以在信息保留和标记效率之间取得平衡。
- 相关工作:该问题的研究相关工作有:UReader(Ye et al., 2023b)提出了一种形状自适应裁剪模块来处理高分辨率图像;Monkey(Li et al., 2023b)使用滑动窗口和重采样器减少冗余信息;mPLUG-DocOwl1.5(Hu et al., 2024)提高了低分辨率编码器的基本分辨率并替换了视觉抽象器。
研究方法
这篇论文提出了mPLUG-DocOwl2,用于解决高分辨率文档图像的压缩和多页文档理解问题。具体来说,
- 高分辨率视觉编码:首先,使用形状自适应裁剪模块将高分辨率图像裁剪成固定大小的子图像,并使用低分辨率的基于Transformer的视觉编码器提取每个子图像和全局图像的视觉特征。
- 高分辨率全压缩:然后,设计了一个高分辨率压缩器,通过交叉注意力将高分辨率图像的视觉特征压缩成较少的标记。具体来说,利用全局低分辨率图像的视觉特征作为查询,子图像的重构特征作为键和值,进行交叉注意力操作。
- 多图像建模与LLM:通过高分辨率压缩,为了帮助LLM更好地区分不同图像的视觉特征并理解图像的顺序编号,在每个图像的视觉特征前添加了文本序数标记。
- 模型训练:DocOwl2的训练分为三个阶段:单图像预训练、多图像继续预训练和多任务微调。每个阶段的训练数据和设置如下:
- 单图像预训练:使用DocStruct4M数据集进行统一结构学习。
- 多图像继续预训练:使用MP-DocStruct1M数据集进行多页面文档解析训练,并结合部分PixParse12数据集进行多图像理解任务。
- 多任务微调:结合DocDownstream-1.0和DocReason25K数据集进行单图像和多图像指令调优,并结合MP-DocVQA、DUDE和NewsVideoQA数据集进行多任务微调。
实验设计
- 数据集:实验使用了多个数据集,包括DocStruct4M、MP-DocStruct1M、DocDownstream-1.0、DocReason25K、MP-DocVQA、DUDE和NewsVideoQA。这些数据集涵盖了单页面和多页面文档解析、表格解析、图表解析、自然图像解析和视频理解等多种任务。
- 评估指标:在单页面文档理解任务中,主要评估指标包括视觉标记数量(TokenV)、首次标记延迟(FTL)和文档理解准确率(ANS)。在多页面文档理解任务中,主要评估指标包括视觉标记数量、首次标记延迟和问答准确率(ALS)。
- 实验设置:实验中,最大裁剪数为12,每个子图像或全局图像的分辨率为504x504。高分辨率压缩器包含2层交叉注意力。单图像预训练阶段训练12k步,批量大小为1024,学习率为1e-4。多图像继续预训练阶段训练2.4k步,批量大小为1024,学习率为2e-5。多任务微调阶段训练9k步,批量大小为256,学习率为2e-5。
结果与分析
-
单页面文档理解:在10个单页面文档理解基准测试中,DocOwl2在视觉标记数量减少超过50%的情况下,首次标记延迟减少了50%以上,并在7个基准测试中实现了超过80%的性能。与现有的压缩方法相比,DocOwl2在10个基准测试中表现更好或相当。

-
多页面文档理解:在多页面文档理解基准测试中,DocOwl2在视觉标记数量减少超过50%的情况下,首次标记延迟减少了50%以上,并在多页面问答任务和详细解释任务中表现出色。

-
文本丰富视频理解:在文本丰富视频理解基准测试中,DocOwl2能够区分视频帧中的细粒度文本差异,准确定位相关帧并给出准确答案。

总体结论
这篇论文提出了mPLUG-DocOwl2,一种高效的高分辨率图像压缩和多页文档理解模型。通过引入高分辨率压缩器和三阶段训练框架,DocOwl2在保持OCR无误差的多页文档理解性能的同时,显著减少了视觉标记数量。实验结果表明,对于常见的A4大小文档页面,数千个视觉标记可能是冗余的,过多的计算资源被浪费。希望DocOwl2能够引起更多研究者对高分辨率图像高效表示和无误差文档理解性能之间平衡的关注。
QA解答
问题1:DocOwl2的高分辨率全压缩模块是如何设计的?其核心思想是什么?
DocOwl2的高分辨率全压缩模块通过交叉注意力将高分辨率图像的视觉特征压缩到低分辨率全局图像的视觉特征数量。具体来说,该模块以全局低分辨率图像的视觉特征作为查询,子图像的重组特征作为键和值。通过这种方式,每个查询可以关注与其对应的所有高分辨率特征,从而有效地压缩视觉令牌的数量。此外,由于全局图像和子图像来自同一图像,它们之间的视觉令牌存在明确的映射关系,这有助于在压缩过程中保留更多的文本信息。
问题2:DocOwl2的三阶段训练框架是如何设计的?各阶段的具体目标是什么?
- 单图像预训练:在这个阶段,模型在DocStruct4M数据集上进行统一结构学习,目的是确保压缩后的视觉令牌能够编码大部分视觉信息,特别是视觉文本信息。
- 多图像继续预训练:在这个阶段,模型在MP-DocStruct1M数据集上进行多页面文本解析和多页面文本查找任务。这些任务旨在增强模型关联多张图像的能力。
- 多任务微调:在这个阶段,模型在DocDownstream-1.0和DocReason25K数据集上进行单图像和多图像理解任务的微调。通过结合单图像和多图像的指令调优数据集,模型能够在单页面和多页面文档理解任务上达到最佳性能。
问题3:DocOwl2在实验中表现如何?与其他方法相比有哪些优势?
- 单页面文档理解:在10个单页面文档理解基准测试中,DocOwl2在视觉令牌数量减少超过50%的情况下,首次令牌延迟减少了50%以上,达到了与类似训练数据的最先进的MLLMs相当的性能。
- 多页面文档理解:在多页面文档理解基准测试中,DocOwl2在视觉令牌数量减少超过50%的情况下,首次令牌延迟减少了50%以上,达到了最先进的性能。
- 视频理解:在文本丰富的视频理解基准测试中,DocOwl2能够区分视频中的细粒度文本差异,准确定位相关帧,并给出准确的答案。
与其他方法相比,DocOwl2的优势在于其高效的视觉令牌压缩和高性能的多页面文档理解能力。特别是,通过引入基于交叉注意力的高分辨率全压缩模块和三阶段训练框架,DocOwl2在保持大多数视觉信息的同时,显著减少了视觉令牌的数量,提高了推理速度和模型性能。
推荐阅读
社区简介:
《AIGCmagic星球》,五大AIGC方向正式上线!让我们在AIGC时代携手同行!限量活动中!
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之输出映射器:Output Projector
AI多模态模型架构之模态生成器:Modality Generator
AI多模态实战教程:
AI多模态教程:从0到1搭建VisualGLM图文大模型案例
















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









