







理解TP、FP、TN、FN
TP:被模型预测为正类的正样本
TN:被模型预测为负类的负样本
FP:被模型预测为正类的负样本
FN:被模型预测为负类的正样本

**以西瓜数据集为例,**我们来通俗理解一下什么是TP、TN、FP、FN。
P:预测为好的 N:预测为坏的
TP:被模型预测为好瓜的好瓜(是真正的好瓜,而且也被模型预测为好瓜)
TN:被模型预测为坏瓜的坏瓜(是真正的坏瓜,而且也被模型预测为坏瓜)
FP:被模型预测为好瓜的坏瓜(瓜是真正的坏瓜,但是被模型预测为了好瓜)
FN:被模型预测为坏瓜的好瓜(瓜是真正的好瓜,但是被模型预测为了坏瓜)
查准率、查全率
查准率:模型挑出来的西瓜中有多少比例是好瓜
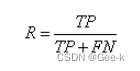
查全率:所有的好瓜中有多少比例是被模型挑出来的
查准率用P来表示:
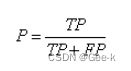
查全率用R来表示:
转原文链接:https://blog.csdn.net/dongjinkun/article/details/109899733














 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









