






 本文介绍了如何利用VLM进行图像理解,LLM生成任务指令,DQN执行动作并根据反馈调整策略,使得机器人具备自我学习和泛化能力,显著提升其技能应用效率。
本文介绍了如何利用VLM进行图像理解,LLM生成任务指令,DQN执行动作并根据反馈调整策略,使得机器人具备自我学习和泛化能力,显著提升其技能应用效率。
VLM:视觉语义模型,准确识别图中有什么,处于什么状态,以及不同物体之间的关联。
LLM:语言大模型,可以针对当前的环境,自动生成可执行的任务,或者将人类指令重新分成可执行的子任务。
以下图为例:将状态S传递给VLM模型 ,通过语义分析知道图中有什么物体,以及机器人在干什么。再将这个信息传递给LLM模型,由它决定,接下来做什么任务合适,再将相关信息全部传递给DQN(一种强化学习模型),由该模型输出相应的动作A(如机械臂不同关节移动的角度,移动机器人的移动方位等),执行相应动作后,会出现新的状态S',再将这个状态传递给VLM,重新对当前状态进行语义分析,并通过LM模型和之前LLM模型给出的任务指示进行对比,得到语义之间相关性的高低,最终给出奖励R,再将奖励R传递给DQN,不断调整策略Π。
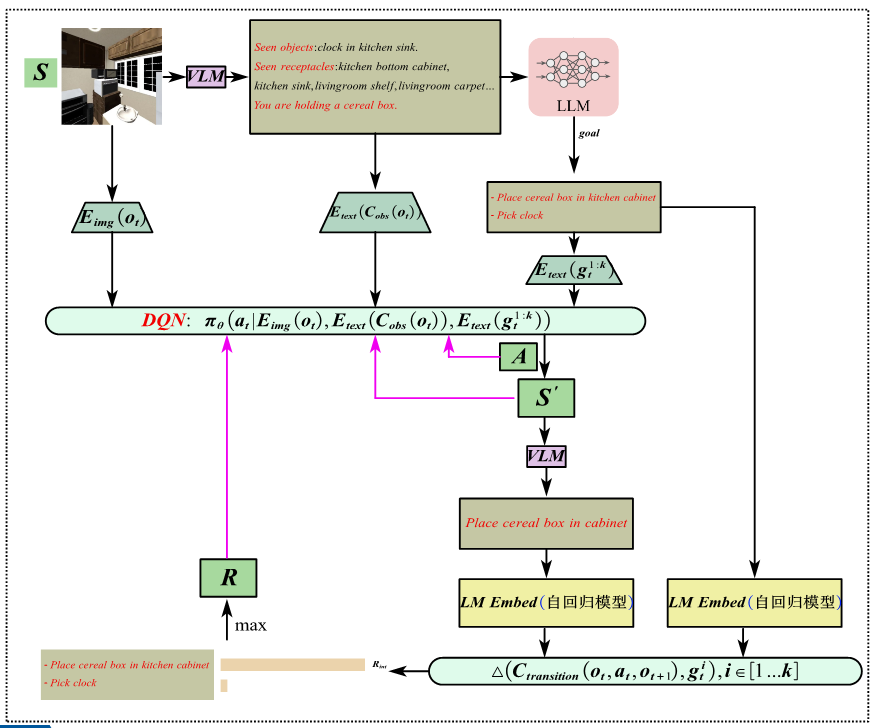
总结:从应用效果上看,相对于传统方法,大模型在机器人上的应用,让机器人具有了真正意义上自我技能的学习。比方说,‘抓’ 这个技能,传统放法抓一个物体就要重新训练一次,或者说一次训练多个物体,但并不能抓没有训练过的物体,该方法不止可以抓训练过的物体(数量比传统方法多的多),对于没有训练过的物体也有很好的泛化性,


















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









