






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
目前,基于大型语言模型的智能体(LLM Agents)展现出强大的潜力,能够自主完成各个领域的任务,如机器人规划、游戏角色控制与网站导航。
然而,这些智能体往往是为特定环境和特定任务设计的。如果我们分析一个 LLM Agent 的系统提示词(System Prompts),它通常由这五个部分组成:1.角色描述,2.可供使用的动作函数,3.输出格式,4.额外指示或要求,5.专家示例。对于新的环境,其中的前三项可以根据新环境对已有模板做调整后很快速地定义好。但对于后两项提示词,会需要人工汇总环境知识,并不断调试这些提示,以及准备多个人类专家示例,才能使 LLM Agent在新环境中顺畅运行。
那是否能让 LLM Agents自己从环境交互中学习这些知识?已有的一些工作使用自我反思self-reflection或技能库skill library,来让 LLM Agents能够在交互中自我提升,部分缓解了对人工的依赖。然而,这些反思和技能并没有用于对环境形成深入的理解,即理解环境的知识或机制。因此,直接使用经验中的技能来作为 LLM Agent的上下文示例容易导致【路径依赖】问题。
如今,来自杭州电子科技大学和浙江大学的联合研究团队提出了AutoManual框架有效地解决这一难题。
研究者从人类自身的适应过程上获取灵感:当面对陌生的环境时,人类会通过探索发现、记录与更新自身的理解来逐渐认识到新环境的规律。而且人类可以将自己的理解整理出来,以文本的方式传授给他人。
AutoManual效仿了这种过程来记录和更新LLM Agent对环境的理解。最终,AutoManual框架将生成的一本指导手册,不仅可以提高LLM Agent对新环境的适应性,还可以为较小的LLM的规划提供指导,并且易于人类阅读。仅需一个人类演示,AutoManual便在机器人规划环境ALFWorld将智能体的成功率提高到97%,在网站导航环境MiniWoB++上的任务成功率则达到98%。

论文链接:https://arxiv.org/abs/2405.16247
GitHub地址:https://github.com/minghchen/automanual
研究方法
AutoManual 框架整体由三个阶段组成:
Building阶段:Planner Agent与Builder Agent合作从环境的交互中构建出一系列的规则。当规则超过最大限制时,Consolidator Agent将合并或删除冗余的规则。
Formulating阶段:Formulator Agent将规则制定成一个Markdown格式的指导手册。
Testing阶段:将指导手册提供给测试时的Planner Agent,来评估效果。
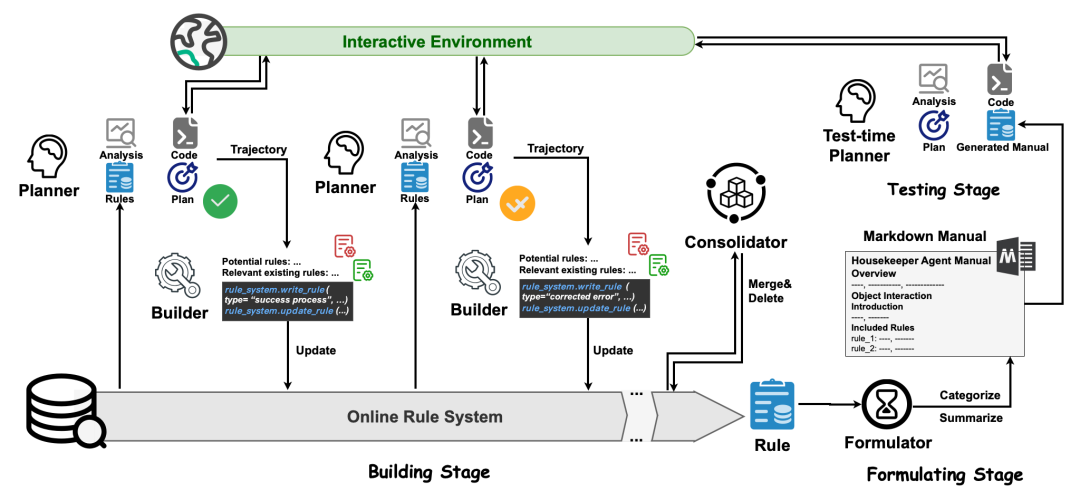
图 | AutoManual框架总览
首先在Building 阶段,研究者受在线强化学习的启发,使用了两个交替的迭代过程来构建环境规则。1. 基于当前规则,Planner Agent与环境进行一轮交互;2. Builder Agent根据该交互轨迹使用规则系统来更新规则。与传统强化学习相比,基于文本的规则管理取代了样本效率低下的参数优化。
具体而言,对于Planner Agent,研究者也采用代码来表示的可执行的计划,这是因为已有工作表明使用代码作为输出能有效提升LLM Agent效果。在每一轮的开始,Planner的输入为目前已知的规则,技能库或反思库中相关的案例,当前的任务与初始观测。而每次Planner 的输出分为四个部分:
1. 对当前观测的分析 2.相关规则的解读 3.总体计划 4.一个划分为多个步骤的 Python 代码块。
然后,代码将在环境中执行,并得到反馈与新的观察结果。
在这一整轮结束时,根据任务是否成功,结果可以分为三种情况:Direct Success、Indirect Success(发生错误但稍后解决)和 Failure。对于不同情况,提示 Planner 相应地汇总技能代码或反思,而这些技能和反思会存入技能库或反思库来辅助后续的任务完成。
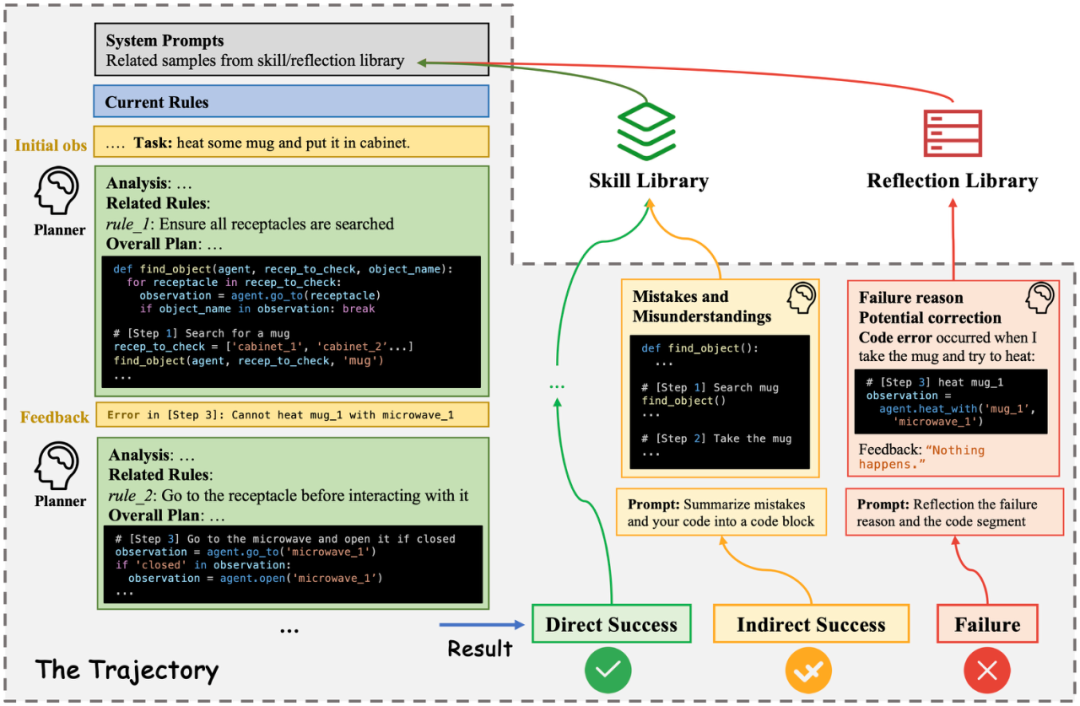
图 | Planner Agent与环境进行交互形成Trajectory的过程示意图
对于Builder Agent,其将根据Planner这轮的轨迹,使用规则系统的工具函数来编写和更新规则。为了促进规则管理,研究者引入了一个结构化的规则系统。规则系统中的每个规则都具有以下四个属性:
1.规则的类型(分为了6种规则); 2.规则的内容; 3. 规则的示例; 4.验证日志。
然而,研究者发现Builder Agent在面对这种结构化的规则系统时,有时候会出现幻觉,例如从失败的轨迹中得出成功经验的规则。为了降低错误创建规则的风险,研究者对Builder采用了case-conditioned prompting策略:Builder 首先需要分析并确定主要错误的来源为 "Imperfect Rules" 或 "Imperfect Agents"。然后,相应的针对性的提示会指导 Builder 进行规则管理。
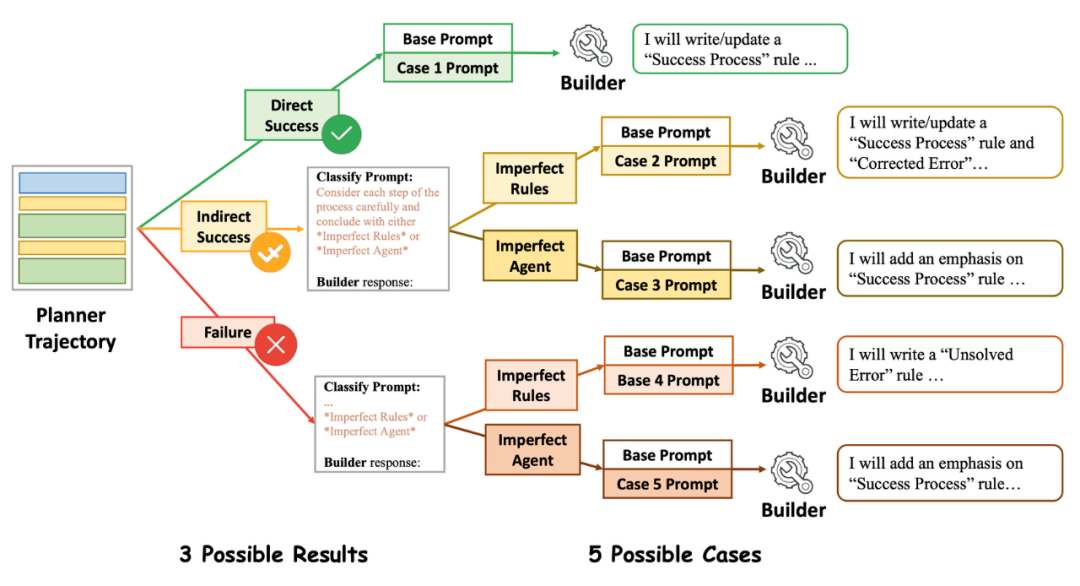
图 | Case-Conditioned Prompting策略示例
在Building阶段结束后,Formulating阶段的目标是增强规则的可读性和全局理解。因此引入Formulator Agent对规则自动进行分类,总结每类的关键点,并以 Markdown 的格式将它们制定成一本指导手册。
实验结果
在三个知名的交互式环境中进行实验:
ALFWorld 是一个家用机器人的虚拟环境,提供了基于文本的交互方式。
MiniWoB++ 是一个模拟的 Web 环境,Agent通过执行键盘和鼠标操作在网页上完成各种任务。
WebArena (Reddit)是一个逼真的 Web 环境,复制了现实的 Reddit 网站的功能和数据。
在Building 和Formulating 阶段,所有Agent都配备了GPT-4-turbo (gpt-4-1106-preview)。在Testing 阶段,Planner Agent将配备GPT-4-turbo 或 GPT-3.5-turbo,来评估生成的手册是否可以指导较小的 LLM。
从 ALFWorld 任务的结果中可以看出,AutoManual 只需要很少的环境相关的专家先验知识:只需要提供了一个人类示例即可获得十分出色的结果。
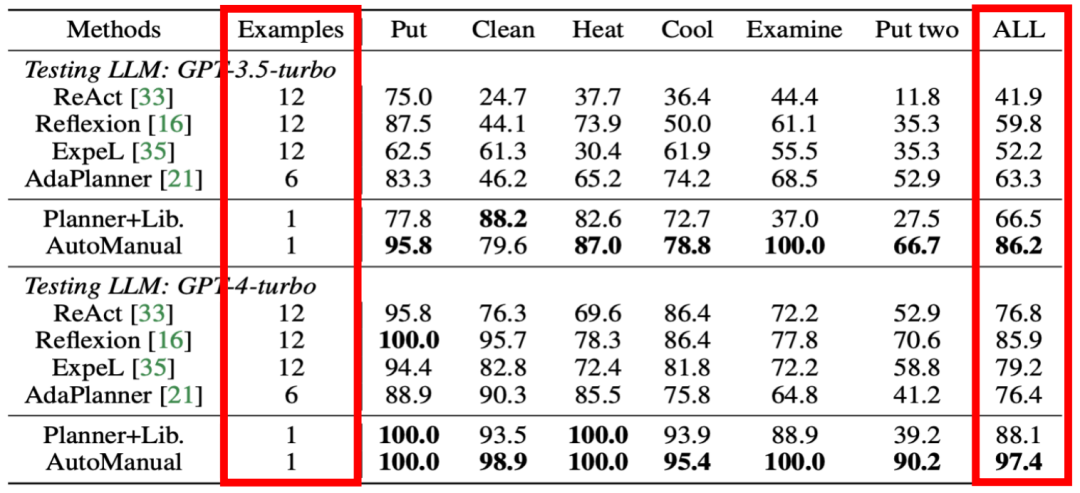
表 | 在ALFWorld环境中,不同LLM Agents方法在6种任务类型上的成功率以及所提供的人类示例
而对于另外两个 Web 环境的结果,也可以得出相同的结论。
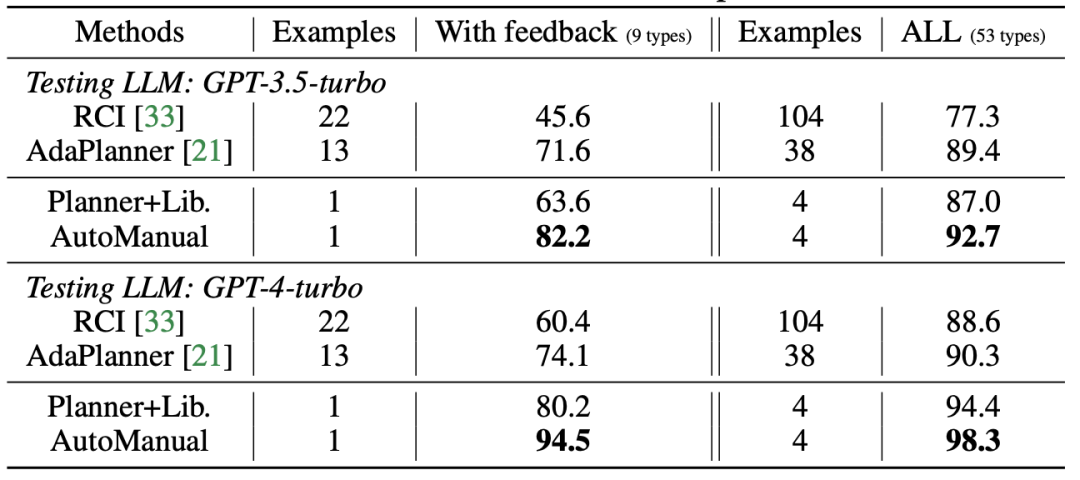
表 | 在Miniwob++环境中,不同LLM Agents方法的成功率以及所提供的人类示例
此外,AutoManual生成的 Markdown 手册对人类阅读也很友好。通过分析AutoManual生成的手册,可以看到其发现许多有价值的环境规则。比如在rule_2,类型为“Special Phenomena”的规则中说:当使用微波炉时,即使里面有另一个物体,智能体拿着什么东西,并且没有明确提到微波门是打开的,智能体也可以与它互动(例如,加热一个物体)。然后其举了一个例子,是在epoch_1中的经历。还有在rule_3中说:Agent一次只能持有一个物体,并且必须在拿走另一个物体之前放下任何持有的物体。
因此,AutoManual 通过更深入地挖掘机制、更新和整合成功流程以及注释重要细节来解决只使用技能的路径依赖问题。
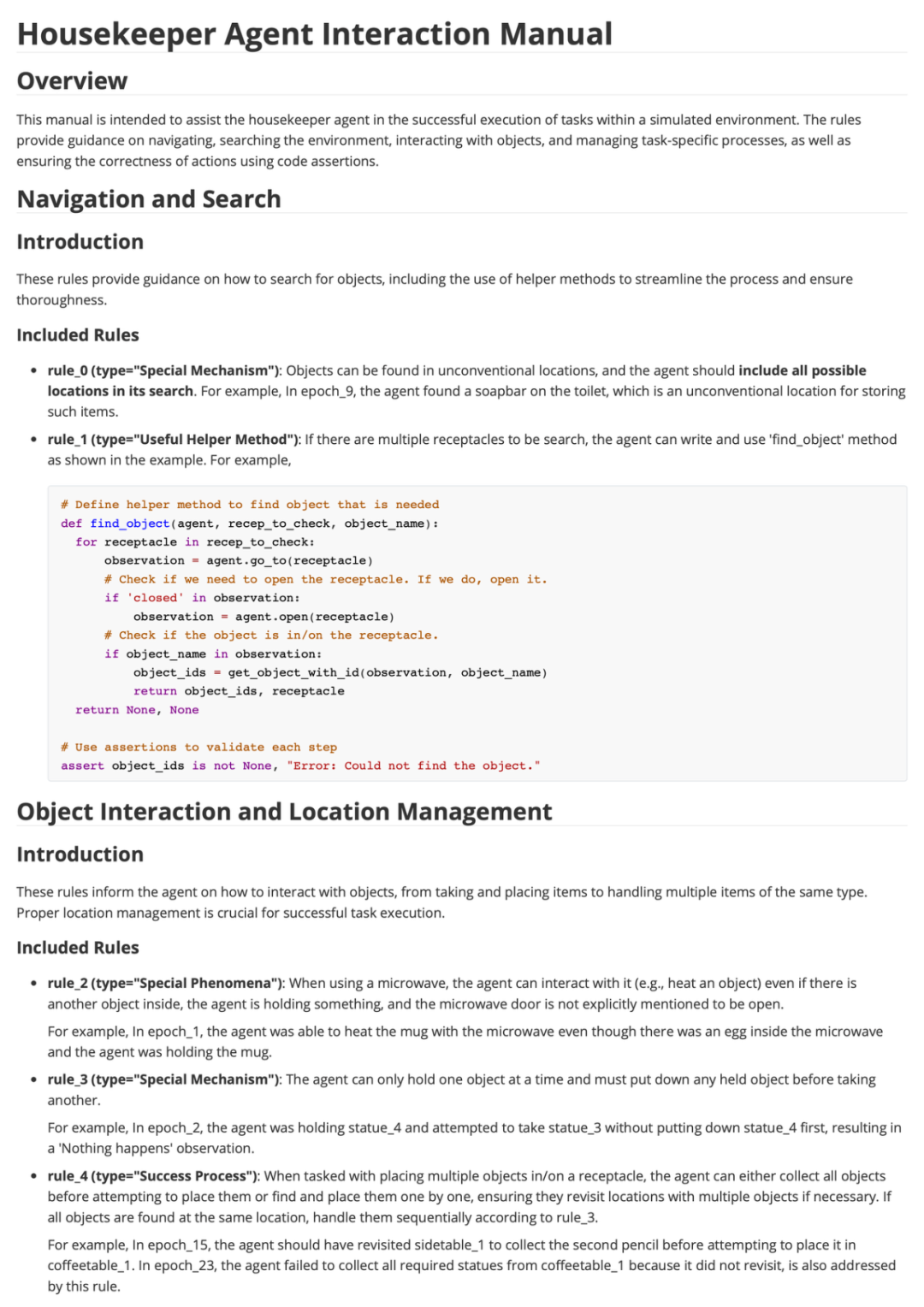

图 | 在ALFWorld环境中,AutoManual生成的Markdown手册
论文《AutoManual: Constructing Instruction Manuals by LLM Agents via Interactive Environmental Learning》
作者信息:该论文由杭州电子科技大学和浙江大学合作完成,第一作者陈铭浩现任杭州电子科技大学特聘副教授。
摘要:该研究有效解决了基于大型语言模型的智能体(LLM Agents)依赖人类专家提供的知识,难以自主适应新环境的问题。虽然基于大型语言模型的智能体在自动完成各种领域的任务方面展现出很大的潜力,例如机器人技术、游戏和网站导航,但是这些智能体通常需要复杂的设计和专家提示才能在特定领域中解决任务,这限制了它们的适应性。为此研究提出了AutoManual框架,使智能体能够通过与新环境互动自主构建知识并适应。AutoManual将环境知识分为多种规则,并通过两个智能体以在线方式优化这些规则:1)“规划者”根据当前规则编写可操作的计划,以便与环境互动。2)“构建者”通过一个结构良好的规则系统更新规则,能够实现在线规则管理和关键细节的保留。最后,“制订者”智能体将这些规则编写成一部指导手册。这种自主生成的手册不仅可以提高适应性,还可以为较小的LLM的规划提供指导,并且易于人类阅读。仅需一个人类演示,AutoManual便能显著提高智能体在机器人规划环境ALFWorld和网站导航环境MiniWoB++上的任务成功率。
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









