






通过前面的介绍,已经获得了相机的参数,我们可以利用这些参数使用基于面片的三维多视角立体视觉算法(PMVS)重建出稠密的点云。下面详细介绍一下PMVS算法。
一、基本概念介绍
1、面片(patch)
面片p是一个近似的正切与重建物体表面的一个小矩形,他的一边平行于参考相机的x轴。对于一个面片p,他的几何特征如下:
中心点:c(p);
单位法向:n(p),该向量指向相机的光心;
面片p对应一个参考图像R(p),在R(p)中p是可见的。针对p有扩展矩形,p在R(p)中的投影是μ×μ大小的,在原论文中μ=5 or 7
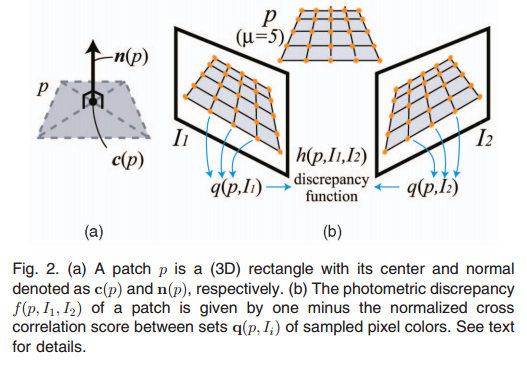
2、灰度一致性函数(Photometric Discrepancy Function)
首先,我们定义图像集合V(p)表示所有在自身图像中可见面片p的图像集合(显然这里有R(p)∈V(p),将在后面介绍V(p)的获得已经R(p)的确定)那么,灰度一致性函数定义如下:
在这里,V(p)\R(p)是指除去R(p)的V(p)的其他元素;h(p,I1,I2)是指I和R(p)的灰度一致性函数,计算过程如下:
1. 首先把面片p划分为μ×μ的小格;
2. 通过双线性差值的方法,对p在Ii的图像上的投影进行差值,得到像素灰度q(p,Ii);
3. 用1减去q(p,I1)和q(p,I1)的NCC(normalized cross correlation)值。
过程如下图所示:
由于g(p)对于图像中出现高光或者有障碍物的情况下的效果不好,因此在实际情况下,我们需要保证图像I和图像R(p)的灰度一致性函数大于一定的值α(后面将会介绍如何选择这个阈值)。因此有:
3、面片的优化
面片优化的目的就是恢复那些g∗(p)较小的面片,每个面片的重建过程分为以下两步:
4. 初始化面片的相关参数中心点c(p),法向量n(p),可视化图像集V∗(p)和参考图像R(p);
5. 优化几何参数c(p)和n(p)
这里的第一步初始化的过程在后面用到,这里先讲以下c(p)和n(p)的优化。几何参数c(p)和n(p)的优化是通过最小化光度一致性分数(the photometric discrepancy score)g∗(p)而得到的。为了简化计算,将c(p)约束在某一条光线上,这样p在其对应的可视图集V∗(p)中某个图像的投影位置就不会变,因此降低了p的自由度和只能求出一个深度。n(p)是由欧拉角(yaw and pitch)决定的,可以用共轭梯度法求解这个优化问题。
4、图像模型
基于面片的物体表面的表示的优势是他的灵活性,然而却不容易找到面片的连续性。为了解决这个问题进行了如下的操作,把图像Ii分成了许多β1×β1像素的的小块Ci(x,y),这里x,y表示图像块的下标,i表示这是第i张图像的。给定一个面片p和对应的V(p),把p投影到V(p)的图像中,以得到面片p对应的图像块,每个图像块Ci(x,y)用一个集合Qi(x,y)记录了所有投影到这个图像块的面片。同理,我们用Q∗i(x,y)来表示用V∗(p)得到的结果。如下图所示:
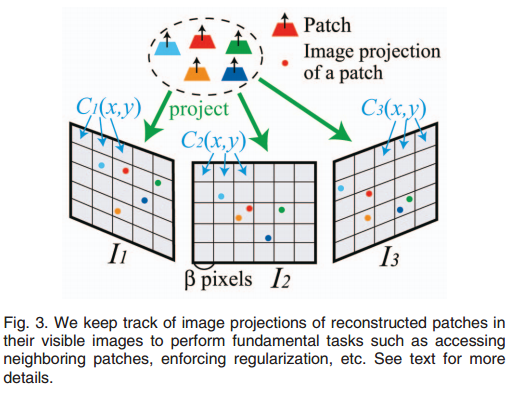
二、面片的重构
基于面片的多视角三维立体视觉算法的目的就是保证在每个图像块Ci(x,y)上至少有一个面片的的投影。主要分为以下三步:
1. 初始化特征匹配(initial feature matching);
2. 面片生成(patch expansion);
3. 面片筛选(patch filtering);
初始化特征匹配的目的就是生成一系列稀疏的面片,面片的生成和筛选都要执行n次使得面片足够稠密,同时去除不好的面片。下面依次进行介绍。
1、初始化特征匹配
首先用DOG和Harris来提取图像的角点特征,即为每幅图像的特征点。对于图像Ii,以及其对应的光心O(Ii),该图像中的特征点f,通过允许有两个像素误差的极线约束找到它在其他图像中的同种类型的特征点f′,构成匹配点对(f,f′)。然后用这些匹配点对使用三角化的方法生成一系列三维空间点,然后将这些点按照距离O(Ii)从小到大顺序进行排列,然后依次尝试生成面片,直到成功。
尝试生成面片的方法如下所示:首先初始化候选面片的c(p),n(p)和R(p),如下所示:
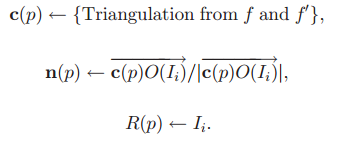
由于生成的面片可能有很多错误的情况,因此我们认为在图像Ii中可见的面片是面片的法向量与面片中心到相机光心的连线夹角小于一定角度α的图像,即满足: 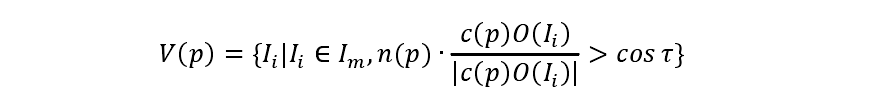
同样V∗(p)的获得与前面所讲的方法相同。这样面片的信息都已经初始化过了,然后根据前面所讲的对c(p)和n(p)进行优化,并将优化过后的c(p)和n(p)带入
具体的算法描述和图示如下图所示,过程就是我上面说的过程,懒得翻译了,很好理解。
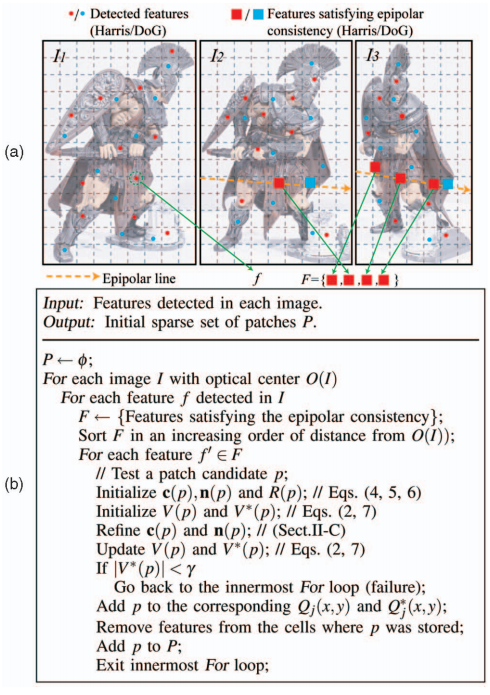
2、面片生成(patch expansion)
面片生成的目的就是保证每个图像块至少对应一个面片。通过上面生成的面片,重复的生成新的面片,具体来说就是给定一个面片p,首先获得一个满足一定条件的邻域图像块集合C(p),然后进行面片生成的过程。
下面是面片p的两个相关概念:
图像块邻域C(p):
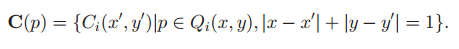
面片p和p′的临近关系:
即当面片p和p′满足上式时,即判定两者为临近关系,上式中的ρ1由R(p)在c(p)和c(p′)中的深度决定。
当存在一个面片p′其所属的图像块Ci(x′,y′)满足Ci(x′,y′)∈C(p),同时p和p′属于近邻关系时,此时将Ci(x′,y′)从C(p)中删除,不对他进行面片生成。同时,即使这个条件没有满足,只要Qi(x′,y′)不为空,也不需要再此图像块上执行生成操作。
对于C(p)中其余的图像块,将会执行面片生成的操作流程以生成新的面片p′。首先用p的相应变量初始化p′的n(p′)、R(p′)和V(p′),对于c(p’)的初始值为穿过Ci(x,y)的可视光线与面片p所在平面的交点。使用
由V(p)得到V∗(p′),再由上面提到的方法对c(p′)和n(p′)进行优化。在优化的过程中,将c(p′)约束在一条直线上,使得p′在图像Ii上的位置不会改变,始终对应的是Ci(x,y)。优化完成后,给V(p′)加上一组图像,这些图像块些根据深度测试判断为p′对其应该是可见的,并根据此更新V∗(p′)。
最终如果|V∗(p′)|≥r,则判定p′是可接受的,即生成成功,同时更新Qi(x,y)和Q∗i(x,y)。具体的参数设置参见原论文。
面片生成的算法流程如图所示:

3、面片过滤(patch filtering)
在面片的重建过程中,可能会生成一些误差较大的面片,因此需要过滤来确保面片的准确性。
第一个过滤器是通过可视一致性进行过滤,另U(p)表示与当前可视信息不连续的面片集合,所谓的不连续就是p和p′两个面片不属于近邻关系,但是却存在于同一个Qi(x,y)中。对于U(p)中的面片p,如果满足下列条件,则将其过滤掉。
直观上来讲,如果p是一个异常值,那么1−g∗(p)和|V∗(p)|都会比较小,这样p一般都会被过滤掉。
第二个过滤器同样也是考虑可视一致性,不过会更加严格,对于每个面片p,我们计算他通过深度测试得到的可视图像的总数,如果数目小于r,那么则认为p是异常值,从而过滤掉。
第三个过滤器,对于每个面片p,在V(p)中,收集这样的一组面片,他们的映射到面片p自己所在的图像块以及所有相邻的图像块,如果p的八邻域内的面片数量占收集所得面片数量的比例小于0.25,则任务p是异常值,将其过滤掉。
三 多边形网格重建
这一章主要讲的是仍然希望将它们的面片集合应用到基于图像的建模应用的表面网格。主要是是两个初始化多边形网格模型的算法:
4.1 网格初始化
1简单使用泊松表面重建软件直接将一组定向点转换为三角化的网格模型。
2从分割信息中计算可视化外壳,然后迭代变形成重构的面片,其中网格中所有顶点的三维坐标模型是通过梯度体方法优化成最小化每个顶点的两个能量函数的总和。
Es(Vi)=|-ζ1Δvi+ζ2Δ^2vi|^2/τ^2
其中Δ表示离散拉普拉斯算子相对到Vi中的切平面的局部参数化,τ是网格模型平均边缘长度,Vi表示一个顶点Vi的位置(ζ1=0.6,ζ2=0.4)
使重构面片的连续性(光度一致性项)
Es(vi)=max(-0.2,min(0.2,d(vi)*n(vi)/τ))^2
n(vi)是在vi处表面的外单位法线,d(vi)是vi和重构面片n(vi)之间的符号距离。
d(vi)=∑p∈∏(vi)w(p)[n(vi)*c(p)-vi]
面片p的法向n(p)与vi方向一致,计算中心点C(P)和由vi和n(vi)定义的线的距离,然后集合π=10,设置∏(vi)的最近面片集,最后计算从vi到∏(vi)沿n(vi)的加权平均距离, 权重n(p)是C(p)和线距离的高斯函数标准偏差ρ1定义在3.2.1中,归一化总和为1.8
4.2 网格细化
所有顶点的是三维坐标被优化和关于每个顶点光度一致性和几何平滑能量函数总和
1)一个表面的深度和方向被估计,它的每对可视化图像集相对每个顶点通过用面片优化过程
2)评估深度和方向信息被联合计算能量函数
V(vi)表示一组图像集,其中vi是可视化的图像,从一个标准深度图测试集评估的当前网格模型
E'p(vi)=ζ3∑p∈P(vi)1-exp(-(d'(vi,p)/τ/4)^2)
d'(vi,p)=n(p)*(c(p)-vi)
其中d‘(vi,p)是面片p和顶点vi沿着单位面片的符号距离,τ是网格平均加权长度,ζ3是线性组合权重。
(以上是我的修改和补充的部分,如有错误请指正,我会继续修改直到最好。。。。。。)















 2925
2925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









