







概况
-
本数据集共有大约1200万条数据(tianchi_mobile_data.csv),数据为淘宝APP2014年11月18日至2014年12月18日的用户行为数据,共6列字段,列字段分别是:
- user_id:用户身份,脱敏
- item_id:商品ID,脱敏
- behavior_type:用户行为类型(包含点击、收藏、加购物车、支付四种行为,分别用数字1、2、3、4表示)
- user_geohash:地理位置
- item_category:品类ID(商品所属的品类)
- time:用户行为发生的时间
-
提出问题
- 不同时间维度下用户活跃度如何变化?
- 用户的留存情况如何(复购率及漏斗流失情况)?
- 用户价值情况?
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#中文乱码的处理
#plt.rcParams['font.sans-serif']=['PingFang HK'] #mac系统使用
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']#windows使用设置微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False #避免坐标轴不能正常的显示负号
import warnings
warnings.filterwarnings('ignore')
数据预处理
#加载数据
data = pd.read_csv('./tianchi_mobile_data.csv')
data.head()
#数据集中一行数据就表示一个用户在指定的时间内对某一款商品触发了怎样的行为
data.shape
(12256906, 6)
#查看是否存在重复的行数据
data.duplicated().sum()
4092866
#删除重复的行数据
data.drop_duplicates(inplace=True)
#恢复行索引
data.reset_index(drop=True,inplace=True)
#是否存在缺失数据
data.isnull().any()

#查看缺失数据的占比
data['user_geohash'].isnull().sum() / data['user_geohash'].size * 100
52.76817605009284
#删除user_geohash列
data.drop(columns='user_geohash',inplace=True)
#time列转换成时间类型
data['time'] = pd.to_datetime(data['time'])
#提取time列中的日期和小时作为新的两列数据
data['date'] = data['time'].dt.date
data['hour'] = data['time'].dt.hour
#dt是时间对象的一种固有属性
data['time'].dt.year #提取年份
data['time'].dt.month #提取月份
data['time'].dt.day #提取天
data['time'].dt.week #提取星期
data['time'].dt.hour #提取小时

data.drop(columns='time',inplace=True)
data.head()
data.shape
(8164040, 6)
用户行为分析
活跃度
- 每天活跃度的变化
- 计算出日访问量,日独立访客量和人均访问量,封装成一个新的df
#日访问量
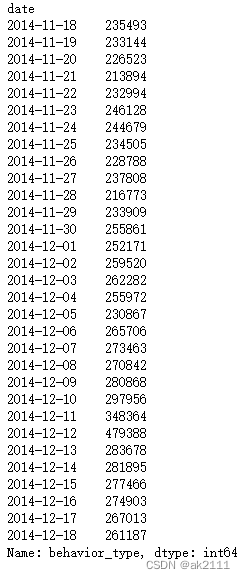
pv_s = data.groupby(by='date')['behavior_type'].count()
pv_s
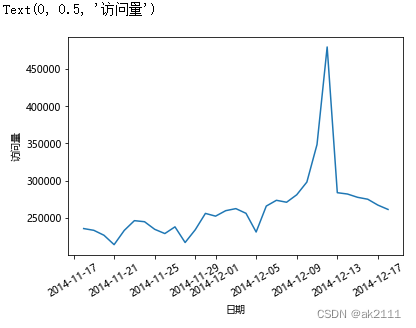
plt.plot(pv_s)
x = plt.xticks(rotation=30)
plt.xlabel('日期')
plt.ylabel('访问量')
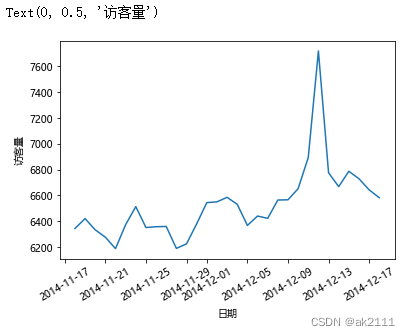
#日独立访客量 uv
uv_s = data.groupby(by='date')['user_id'].nunique()
plt.plot(uv_s)
x = plt.xticks(rotation=30)
plt.xlabel('日期')
plt.ylabel('访客量')
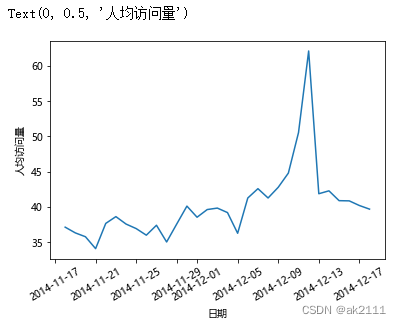
#人均访问量
pv_uv_s = pv_s / uv_s
plt.plot(pv_uv_s)
x = plt.xticks(rotation=30)
plt.xlabel('日期')
plt.ylabel('人均访问量')
-
结论:在12月5日之前,活跃度在一定水平上波动。12月5日后,活跃度开始明显上升,并在双十二当天达到峰值。
-
可能原因:12月5日之后双十二预热活动开始,用户活跃度上升。
-
双十二当天活跃度的变化
- 选择双十二当天的数据,分析其活跃时间段
- 双12当天每小时的访问量
- 双12当天每小时的访客量
- 双12当天每小时的人均访问量
- 形成一个新的df
- 选择双十二当天的数据,分析其活跃时间段
#取出双12当天的行数据
data['date'] = pd.to_datetime(data['date'])
data_1212 = data.loc[data['date'] == '2014-12-12']
data_1212.head()
#访问量
hour_pv = data_1212.groupby(by='hour')['behavior_type'].count()
#访客量
hour_uv = data_1212.groupby(by='hour')['user_id'].nunique()
#人均访问量
hour_pv_uv = hour_pv / hour_uv
plt.plot(hour_pv)
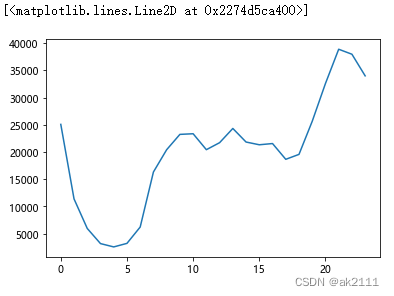
plt.plot(hour_uv)
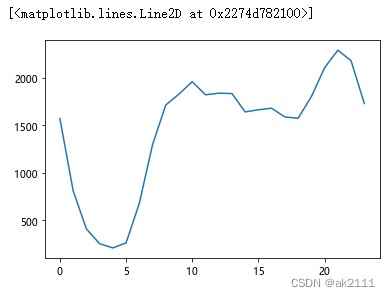
plt.plot(hour_pv_uv)
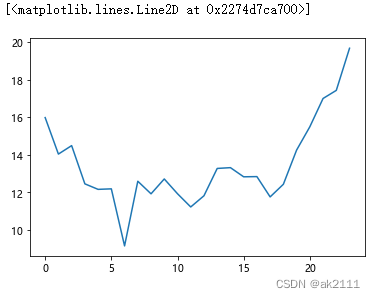
-
结论:双十二当天8点之后淘宝用户活跃度较高,4-6点跌至最低点。
-
建议:商家可以在18点之前设置优惠券或采取其他促销手段,吸引更多人消费,提高购买率。
-
不同用户行为下的活跃度变化
- 查看每天不同行为的各自的总量
- 提示:源数据中的一行数据表示一个用户的某一个行为的数据
- 注意:aggfunc的count和size的区别
- 查看每天不同行为的各自的总量
data.groupby(by='date')['behavior_type'].value_counts()

data.pivot_table(index='date',aggfunc='count')
data.pivot_table(index='date',aggfunc='size')
#size会比count返回更加精简的结果
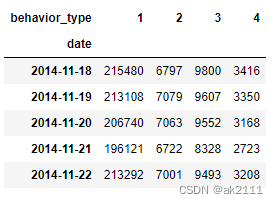
p_df = data.pivot_table(index='date',aggfunc='size',columns='behavior_type')
p_df.head() #不同日期对应所有用户行为的总量
plt.figure(figsize=(12,8))
x = plt.xticks(rotation=30)
plt.plot(p_df.index,p_df[1],label='点击')
plt.plot(p_df.index,p_df[2],label='收藏')
plt.plot(p_df.index,p_df[3],label='加购')
plt.plot(p_df.index,p_df[4],label='支付')
plt.legend()
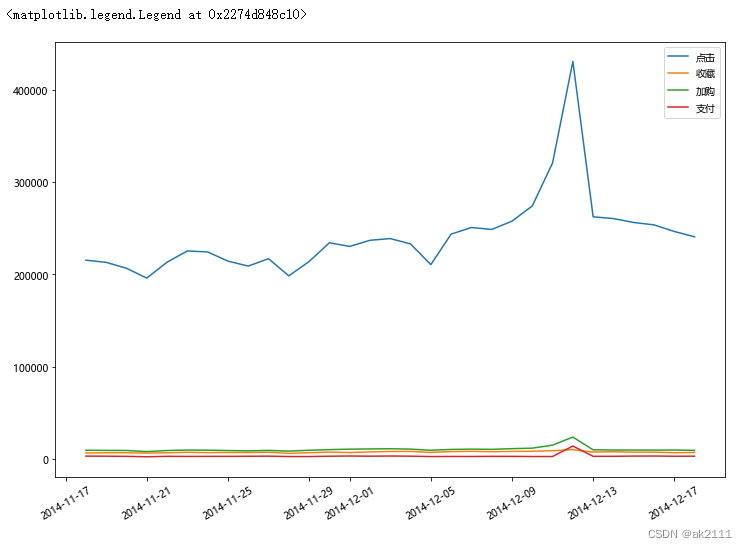
- 结论:
- 点击、收藏、加购物车、支付这四种行为均在双十二当天达到顶峰。
- 只观察支付和收藏,发现双十二当天支付量大于收藏量。
- 支付量大于收藏量说明很多用户购买了目标之外的商品,可能是受到促销的影响冲动消费,又或者是为了凑单等。
留存率
- 漏斗转化情况
- 查看不同行为的总量,封装到df中
- 单一环节转化率(%)-各环节转换率作为新的列存在
- 计算点击到收藏、收藏到加购,加购到支付的转化率
- 整体转化率(%)-作为新的一列存在
- 计算点击到收藏、加购和支付的整体转化率
- 每一环节流失率(%)
- 100-单一环节转化率
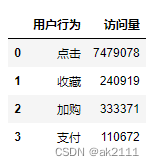
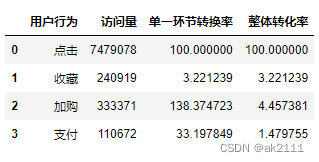
data['behavior_type'].value_counts().sort_index()

#reset_index()可以将series快速转换成df
ret = data['behavior_type'].value_counts().sort_index().reset_index()
ret.columns = ['用户行为','访问量']
ret['用户行为'] = ['点击','收藏','加购','支付']
ret
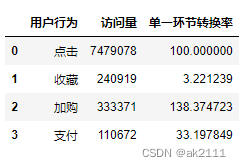
#单一环节转化率(%)
temp1 = ret['访问量'][1:] #后三个值
temp2 = ret['访问量'][:-1] #前三个值
p = temp1.values / temp2.values * 100
p = list(p)
p.insert(0,100)
p
[100, 3.221239302491564, 138.3747234547711, 33.19784864310333]
ret['单一环节转换率'] = p
ret
#整体转化率(%)-作为新的一列存在
ret['整体转化率'] = ret['访问量'] / ret.iloc[0,1] * 100
ret
#每一环节流失率(%)
ret['每一环节流失率'] = 100 - ret['单一环节转换率']
ret
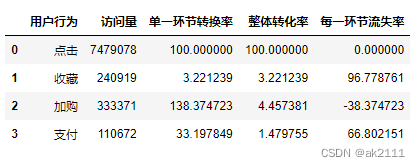
- 可能原因及建议
- 点击-收藏环节流失
- 原因:用户被投放的广告吸引,进入后发现与预期严重不合,造成流失。
- 建议:优化广告。
- 原因:客户通过检索或推荐到列表页面但没找到合适的产品,造成流失。
- 建议:更新搜索引擎和相关算法,尽可能精准推送相关内容。
- 原因:如果商品的评价过低,造成流失。
- 建议:商家要做进一步调查,分析用户对商品评价低的原因,进一步改进,提升用户的购物体验,最终可以口碑营销。
- 收藏-加购物车环节流失
- 此类用户有较强的购买需求。可以对用户进行精准推送促销信息,刺激用户完成购买。
- 加购物车-支付环节流失
- 原因:生成订单页面步骤过多。
- 建议:
- 优化购物流程,尽可能支持多种支付方式,如银行卡、微信支付、支付宝支付、花呗等。
- 考虑目前到淘宝的购物流程已经很难再简化,需要商家进一步调查,了解用户放弃支付的原因,方便做出调整。
- 点击-收藏环节流失
复购情况分析
- 用户购买次数直方图
- 计算复购率=购买次数大于1的用户数量/有购买行为的用户总数
buy_df = data.loc[data['behavior_type'] == 4]#已购用户的行数据
buy_df.head()
#计算不同用户的购买次数
buy_s = buy_df.groupby(by='user_id')['behavior_type'].count()
plt.hist(buy_s,bins=100)
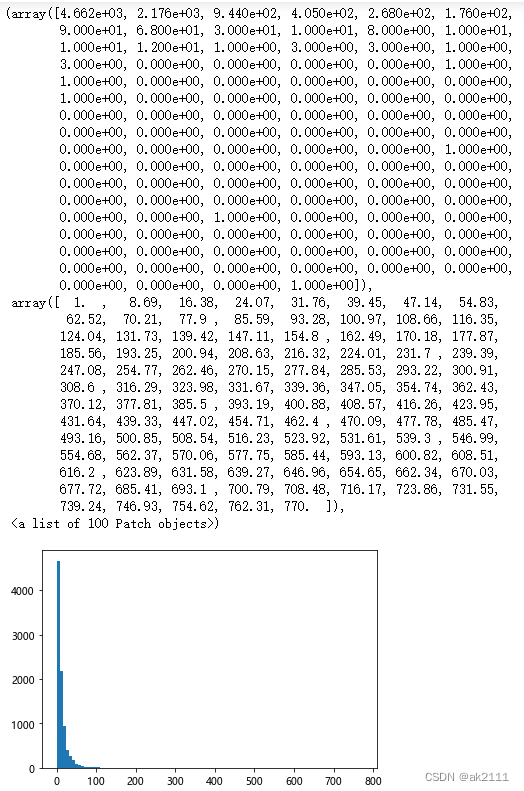
#计算所有用户的复购率:购买次数大于1的用户数量/有购买行为的用户总数
reBuy_rate = (buy_s > 1).sum() / buy_s.count() * 100
reBuy_rate
91.44722034661264
- 在2014-11-18到2014-12-18日这一个月用户的复购率高达91.44
用户价值分析(RFM模型)
- 对已购用户进行价值划分
- 各类用户占比
buy_df = data.loc[data['behavior_type'] == 4] #已购用户的行数据
buy_df.head()
#计算R
import numpy as np
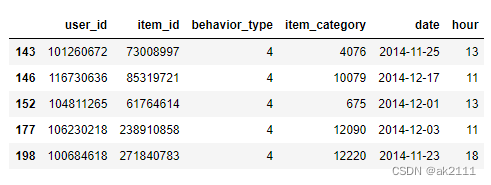
now_date = buy_df['date'].max()
def func(x):
return (now_date - x.max())/ np.timedelta64(1,'D')
R = buy_df.groupby(by='user_id')['date'].apply(func)
R
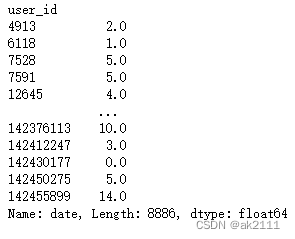
#计算F
F = buy_df.groupby(by='user_id')['date'].count()
rfm = pd.DataFrame(data=[R,F],index=['R','F']).T
rfm
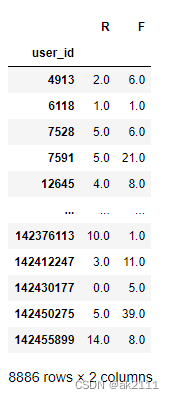
r_avg = rfm['R'].mean()
f_avg = rfm['F'].mean()
def func_r(x):
if x > r_avg:
return '0'
else:
return '1'
def func_f(x):
if x > f_avg:
return '1'
else:
return '0'
rfm['R_value'] = rfm['R'].map(func_r) #R列中的元素如果大于R的均值返回字符串的0表示坏指标,否则返回1表示好指标
rfm['F_value'] = rfm['F'].map(func_f)
rfm['rfm'] = rfm['R_value'] + rfm['F_value'] #拼接字符串
rfm.head()
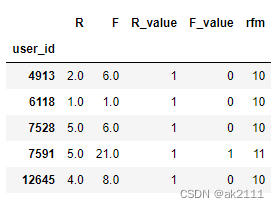
def func(x):
if x == '00':
return '重要挽留客户'
elif x == '11':
return '重要价值客户'
elif x == '10':
return '重要发展客户'
else:
return '重要保持客户'
rfm['用户类别'] = rfm['rfm'].map(func)
rfm
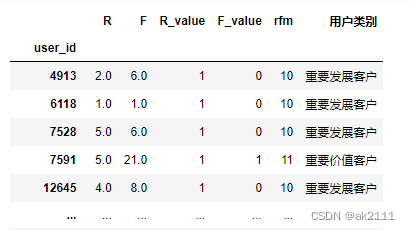
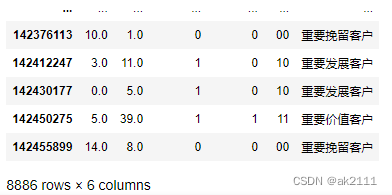
rfm['用户类别'].value_counts()
重要挽留客户 3042
重要发展客户 2968
重要价值客户 2412
重要保持客户 464
Name: 用户类别, dtype: int64
- 结论
- 重要挽留客户:占比最大,该类用户消费时间间隔较远,并且消费频次低。需要主动联系客户,调查清楚哪里出现了问题,可以通过短信,邮件,APP推送等唤醒客户,尽可能减少流失。
- 重要发展客户:消费频次低,可以适当给点折扣或捆绑销售来增加用户的购买频率,尽可能提高留存率。
- 重要价值客户:为重点用户,但用户比较少。可以针对性地给这类客户提供 VIP服务;
- 重要保持客户:消费时间间隔较远,但是消费频次高。该类用户可能一次性购买很多东西。对于这类客户,需要主动联系,关注他们的购物习性做精准化营销,及时满足这类用户的需求。
内容来自大数据分析课程。
















 2579
2579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











