







系列文章目录
前言
本文需要数据库基础知识。涉及到表、主键、连接、分组等内容。
本文只做笔记用,常用的其实只有merge、groupby还有apply这几个。
一、数据集成
1. 【重点】主键合并数据——merge()函数
merge()函数用于根据一个或多个键连接两组数据
merge(left,right,how=‘inner’,on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=False,sumfflxes=‘_x’,‘_y’,copy=True,indicator=False,validate=None)
| 参数名 | 说明 |
|---|---|
| left、right | 表示参与合并的Series类对象或DataFrame类对象 |
| how | 表示数据合并的方式,取值:'inner’内连接,'left’左外连接,'right’右外连接,'outer’全外连接。 |
| on | 表示left与right合并的键,也就是用哪个键来连接两个对象 |
| left_on | 表示将left中列索引作为键 |
| right_on | 表示将right中列索引作为键 |
| left_index | 表示将left中行索引作为键 |
| right_index | 表示将right中行索引作为键 |
| sort | 表示按键对应列的顺序对合并结果进行排序,默认为True |
例如,有学生基础信息表和成绩单如下:
左表是学生信息表,有学号1、2、3三个人
| 学号 | 姓名 | 年龄 |
|---|---|---|
| 1 | 张大 | 16 |
| 2 | 张二 | 15 |
| 3 | 张三 | 14 |
右表是学生成绩表,主键是学号,有学号为1、2、4的三个学生的语文、数学和英语成绩
| 学号 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 1 | 90 | 89 | 88 |
| 2 | 88 | 87 | 86 |
| 4 | 78 | 77 | 76 |
用如下代码合并:
import pandas as pd
df_left=pd.DataFrame({'学号':['1','2','3'],
'姓名':['张大','张二','张三'],
'年龄':[16,15,14]})
df_right=pd.DataFrame({'学号':['1','2','4'],
'语文':[16,15,14],
'数学':[16,15,14],
'英语':[16,15,14]})
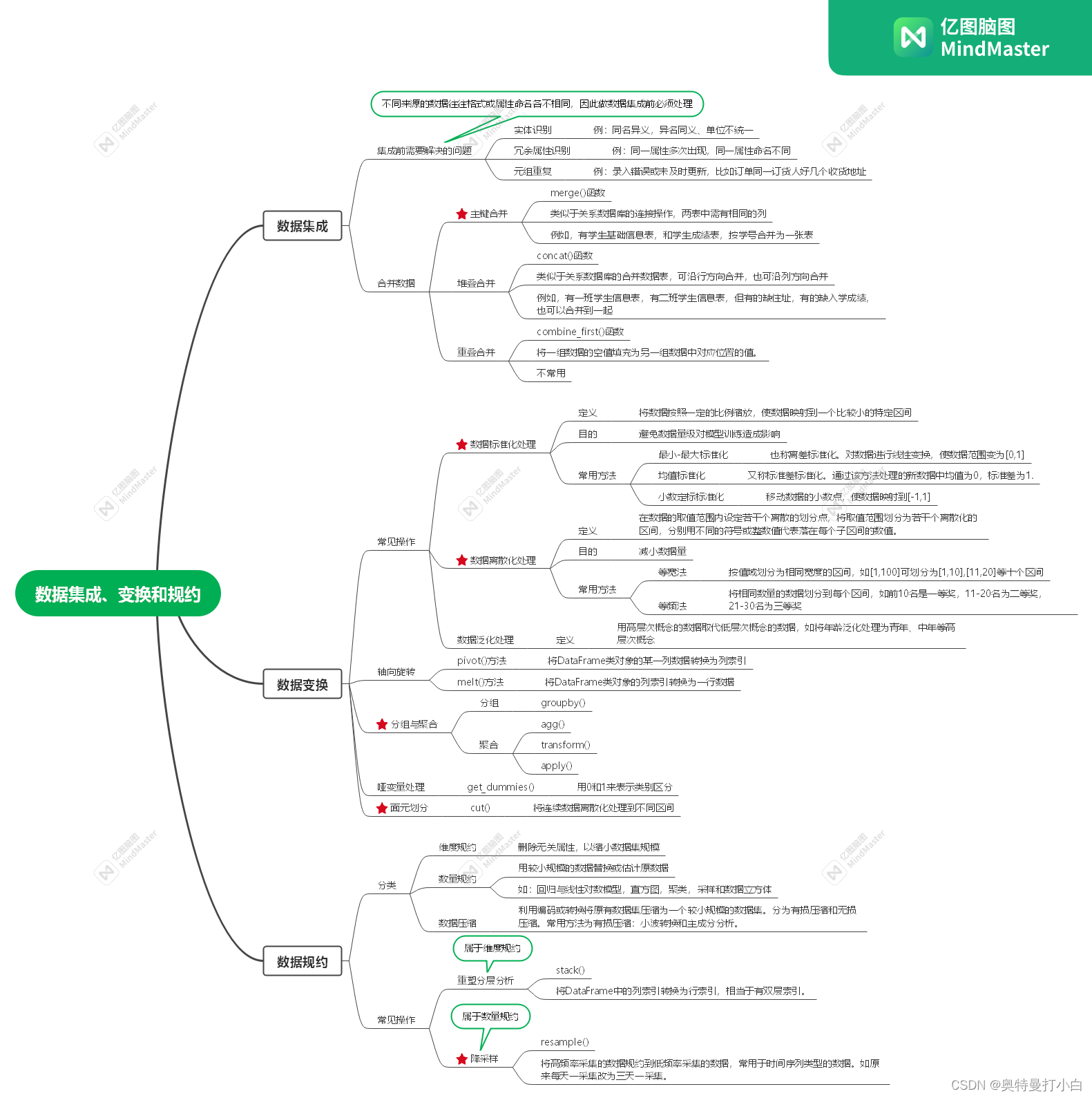
# 以学号为主键,采用内连接的方式合并数据
result_inner=pd.merge(df_left,df_right,how='inner',on='学号')
print(result_inner)
运行结果:

附另外三种连接方式的代码和运行结果:
2. 堆叠合并数据——concat()函数
concat()函数用于数据集的合并,类似于关系数据库中的join。
concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
| 参数名 | 说明 |
|---|---|
| objs | 表示参与合并的Series类对象或DataFrame类对象列表,如[df_left, df_right] |
| axis | 表示要合并的轴,取值可以为0或‘index’,表示沿着行方向的轴合并数据;也可以为1或‘columns’,表示按列合并。默认为0。 |
| join | 表示合并方式,取值:‘inner‘或’outer’。默认为outer。 |
| ignore_index | 是否忽略索引,True或False,默认为False。True意为清除现有索引后重新生成新索引。 |
例如,有学生基础信息表和成绩单如下:
左表是一班学生信息表,有学号1、2、3三个人
| 学号 | 姓名 | 年龄 |
|---|---|---|
| 1 | 张大 | 16 |
| 2 | 张二 | 15 |
| 3 | 张三 | 14 |
右表是二班学生信息表,有学号11、12和14三个人
| 学号 | 姓名 | 性别 |
|---|---|---|
| 11 | 李大 | 男 |
| 12 | 李二 | 男 |
| 14 | 李四 | 男 |
用如下代码合并:
df_left=pd.DataFrame({'学号':['1','2','3'],
'姓名':['张大','张二','张三'],
'年龄':[16,15,14]})
df_right=pd.DataFrame({'学号':['11','12','14'],
'姓名':['李大','李二','李四'],
'性别':['男','男','男']})
# 默认采用外连接的方式逐行堆叠,可理解为两个班名单直接合并
result_concat=pd.concat([df_left,df_right],axis=0)
print(result_concat)
运行结果:
3. 重叠合并数据——combine_first()函数
重叠合并数据并不常用。是指当两组数据的索引完全重合或部分重合,且数据中存在缺失值时,可以采用重叠合并的方式组合数据,能将一组数据的空值填充为另一组数据中对应位置的值。
combine_first(other)
这里要注意两个问题,这两组数据的索引,最好完全重合,因为这个合并非常不智能,不会像连接一样还去对一下主键,是直接无脑复制粘贴。
所以,能不用就不用吧!!!!!!
示例代码如下:
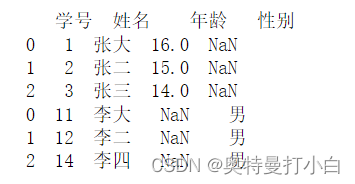
若有两个表,都只有这三个兄弟,表1里缺性别信息,表2里缺年龄,那combine一下,大家就都有了。
import numpy as np
df_left=pd.DataFrame({'学号':['1','2','3'],
'姓名':['张大','张二','张三'],
'年龄':[16,15,14],
'性别':[np.nan,np.nan,np.nan]})
df_right=pd.DataFrame({'学号':['1','2','3'],
'姓名':['张大','张二','张三'],
'性别':['男','男','男']})
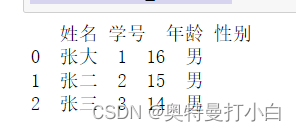
result_combine=df_left.combine_first(df_right)
print(result_combine)
二、数据变换
进行分析或挖掘的数据,必须提前满足一定条件。
如,进行方差分析时要求数据具有正态性、方差齐性、独立性、无偏性,需进行诸如平方根、对数、平方根反正弦的操作,实现一种形式到另一种适当形式的转换,以满足数据分析或数据挖掘的需求,这一过程就是数据变换。
(一)轴向旋转
1. pivot()方法
DataFrame.pivot(index=None, columns=None, values=None)
| 参数名 | 说明 |
|---|---|
| index | 想以哪一列作为新对象的行索引? |
| columns | 新对象打算用哪一列作为索引? |
| values | 哪一列是值? |
若有表格内容如下:
| 序列 | 商品名称 | 出售日期 | 价格(元) |
|---|---|---|---|
| 0 | 荣耀9X | 5月25日 | 999 |
| 1 | 小米6X | 5月25日 | 1399 |
| 2 | OPPO A1 | 5月25日 | 1399 |
| 3 | 荣耀9X | 6月18日 | 800 |
| 4 | 小米6X | 6月18日 | 1200 |
| 5 | OPPO A1 | 6月18日 | 1250 |
现在想以“出售日期”为列索引,“商品名称”中的值作为列标题,展示不同产品6.18降价情况。可以用如下代码实现:
import pandas as pd
df_obj=pd.DataFrame({'商品名称':['荣耀9X','小米6X','OPPO A1','荣耀9X','小米6X','OPPO A1'],
'出售日期':['5月25日','5月25日','5月25日','6月18日','6月18日','6月18日'],
'价格(元)':[999,1399,1399,800,1200,1250]
})
print(df_obj)
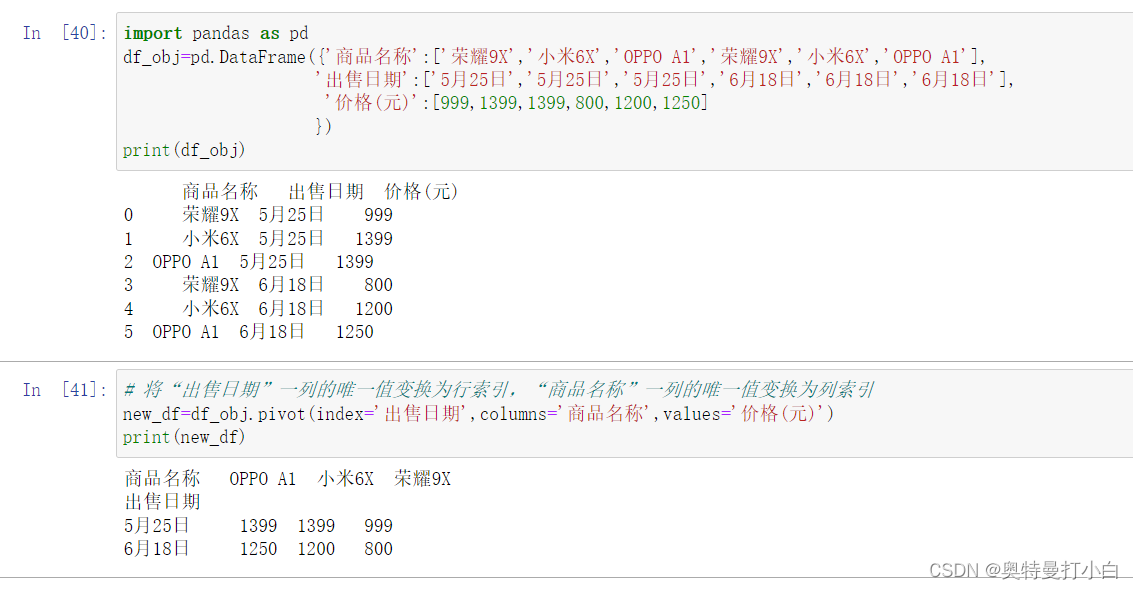
# 将“出售日期”一列的唯一值变换为行索引,“商品名称”一列的唯一值变换为列索引
new_df=df_obj.pivot(index='出售日期',columns='商品名称',values='价格(元)')
print(new_df)
运行结果如图:
2. melt()方法——是pivot方法的逆操作
DataFrame.melt(id_vars=None, value_vars=None, var_name=None, value_name=‘value’, col_level=None, ignore_index=True)
| 参数名 | 说明 |
|---|---|
| id_vars | 表示无需被转换的列索引 |
| value_vars | 表示待转换的列索引。默认全部转换。 |
| var_name | 表示自定义的列索引 |
| value_name | 表示自定义的数据所在列的索引 |
| col_level | 表示列索引的级别。若列索引是分层索引,则可使用此参数 |
| ignore_index | 表示是否忽略索引,默认为True |
若要将刚刚的表格,恢复原来的样子,可用如下代码:
# 将列索引转换为一行数据
new_df.melt(value_name='价格(元)', ignore_index=False)
运行结果如图:
(二)【重点】 分组与聚合

1. 分组操作——groupby()
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_key=True, squeeze=< object object>, observed=False, dropna=True)
| 参数名 | 取值 | 说明 |
|---|---|---|
| by | 表示分组条件 | |
| axis | 0或1 | 表示分组操作的轴编号,默认为0,沿列操作 |
| level | 默认None | 表示标签索引所在的级别 |
| as_index | 默认True | 表示聚合后新数据的索引是否为分组标签的索引 |
| sort | 默认True | 表示是否对分组索引进行排序 |
| group_keys | 默认True | 表示是否显示分组标签的名称 |
import pandas as pd
df_obj=pd.DataFrame({"key":["C","B","C","A","B","B","A","C","A"],
"data":[2,4,6,8,10,1,3,5,7]
})
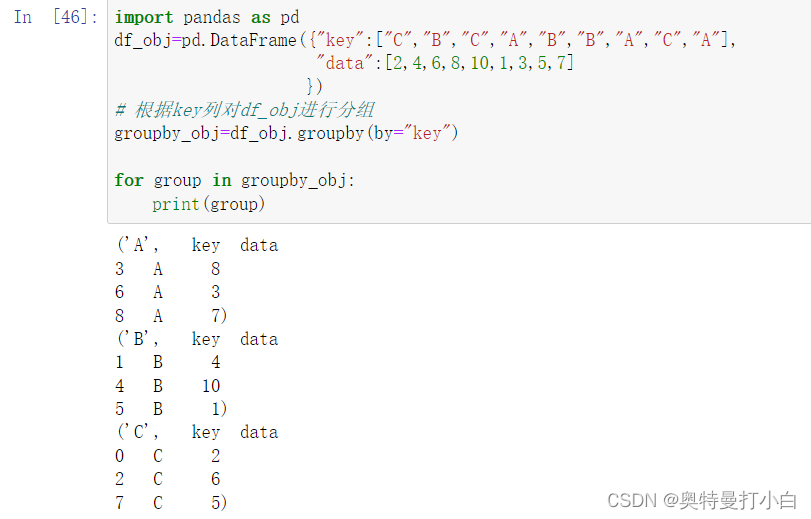
# 根据key列对df_obj进行分组
groupby_obj=df_obj.groupby(by="key")
# 此处必须注意,groupby操作后得到的数据是很多元组,需要for循环遍历才能看到每个分组中的内容
for group in groupby_obj:
print(group)
运行结果如下:
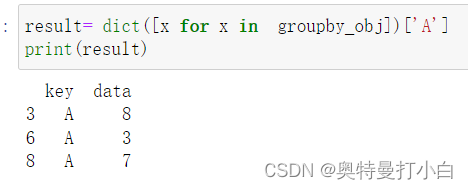
若只想输出制定元组内容,可先转换为字典再输出。
result= dict([x for x in groupby_obj])['A']
print(result)
2. 聚合操作——agg()、transform()和apply()
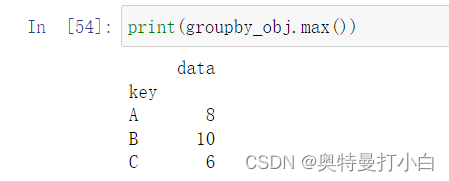
可直接用内置的统计方法,如可以直接用groupby_obj.max()来统计每个分组中的最大值。
print(group_obj.max())
(1)agg()
(2)transform()
(3)【常用】apply()
示例:将groupby_obj对象中的每个数据变为该数据除以100后的结果。
需要先自定义一个函数,用来求某数据除以100后所得结果,再利用apply方法将该函数应用到各分组。
# 先定义一个DataFrame对象,这里复用之前的数据
df_right=pd.DataFrame({'学号':['1','2','4'],
'语文':[90,89,88],
'数学':[88,87,86],
'英语':[78,77,76]})
# 按学号分组,并逐个输出
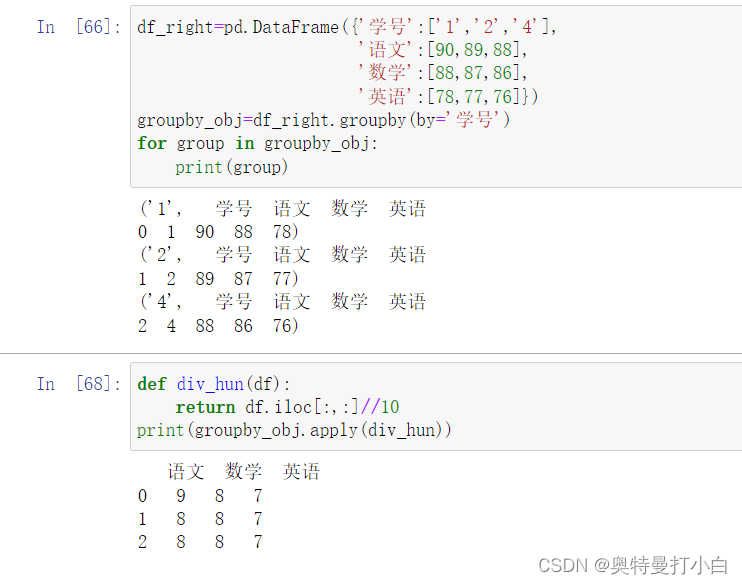
groupby_obj=df_right.groupby(by='学号')
for group in groupby_obj:
print(group)
# 自定义函数,命名为div_hun,若要将成绩都转化为[0,1]之间的数,就需要对对象中的每个数都做/100的操作。
def div_hun(df):
return df.iloc[:,:]/100
# 用apply方法可以直接将自定义函数应用到各分组中
print(groupby_obj.apply(div_hun))
运行结果如下:
(三)哑变量处理——get_dummies()函数
简单来说,哑变量处理就是将类别数据进行“量化”处理。
哑变量,又称虚拟变量,是人为虚设的变量,用来反映某个变量的不同类别,常用取值为0和1,0代表否,1代表是。
示例:
import pandas as pd
position_df=pd.DataFrame({'职业':['工人','学生','司机','教师','导游']})
# 哑变量处理,并给哑变量添加前缀
result=pd.get_dummies(position_df,prefix=['col'])
print(result)

(四)面元划分——cut()函数
面元划分是指数据被离散化处理,按一定的映射关系划分为相应的面元(可理解为区间),只适用于连续数据。
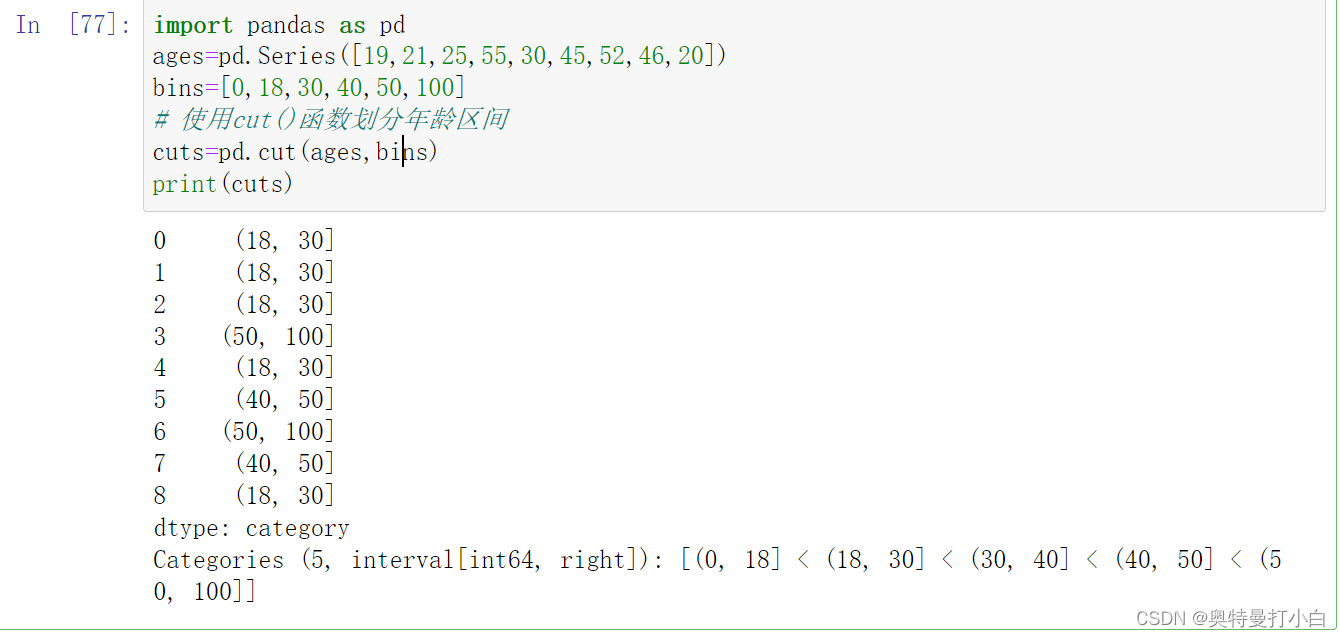
示例:某电商平台统计了一组关于客户年龄的数据,划分面元代码如下:
import pandas as pd
ages=pd.Series([19,21,25,55,30,45,52,46,20])
bins=[0,18,30,40,50,100]
# 使用cut()函数划分年龄区间
cuts=pd.cut(ages,bins)
print(cuts)
三、数据规约——针对大型数据集
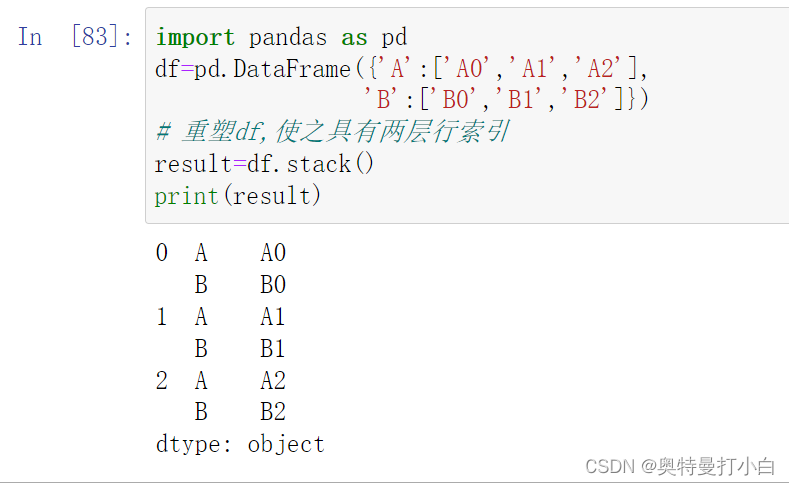
(一)重塑分层索引——stack()
示例:
import pandas as pd
df=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
# 重塑df,使之具有两层行索引
result=df.stack()
print(result)
(二)降采样——resample()
顾名思义,降采样就是降低采样频率,即将高频率采集的数据规约到低频率采集的数据,常用于时间序列类型的数据。如原来每天一采集改为三天一采集。
示例:
import pandas as pd
import numpy as np
# 生成一个时间序列,从2020年6月1日开始,跨度为30天
time_ser=pd.date_range('2020/06/01',periods=30)
# 生成一个含30个随机数的序列,范围40到60之间
stock_data=np.random.randint(40,60,size=30)
# 创建一个Series对象
time_obj=pd.Series(stock_data,index=time_ser)
print(time_obj)
#每7天采集一次数据,实现降采样操作,并且用相同周期内的平均值保证数据的准确与精简
result=time_obj.resample('7D').mean()
result.astype("int64")

总结
暂时学到了这里,其他内容用到了再回来更。。。
参考资料:《Python数据预处理》,黑马程序员编著,人民邮电出版社出版















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









