






个人觉得svm和softmax的梯度部分是这份作业的难点,参考了一些代码觉得还是难以理解,网上似乎也没有相关的解释,所以想把自己的想法贴出来,提供一个参考。
首先贴上参考的代码:
def svm_loss_vectorized(W, X, y, reg):
"""
Structured SVM loss function, vectorized implementation.
Inputs and outputs are the same as svm_loss_naive.
"""
loss = 0.0
num_train= X.shape[0]
dW = np.zeros(W.shape) # initialize the gradient as zero
scores = np.dot(X,W)
correct_class_scores = scores[np.arange(num_train),y]
correct_class_scores = np.reshape(correct_class_scores,(num_train,-1))
margin = scores-correct_class_scores+1.0
margin[np.arange(num_train),y]=0.0
margin[margin<=0]=0.0 # ** #
loss += np.sum(margin)/num_train
loss += 0.5*reg*np.sum(W*W)
margin[margin>0]=1.0 # ** #
row_sum = np.sum(margin,axis=1) # ** #
margin[np.arange(num_train),y] = -row_sum # ** #
dW = 1.0/num_train*np.dot(X.T,margin) + reg*W # ** #
return loss, dW 难以理解的地方就是打星号的几行,也就是求梯度的代码。我们首先看看这个Loss是怎么来的,应该不用多说看下图(这里点乘的顺序和代码中的一致):
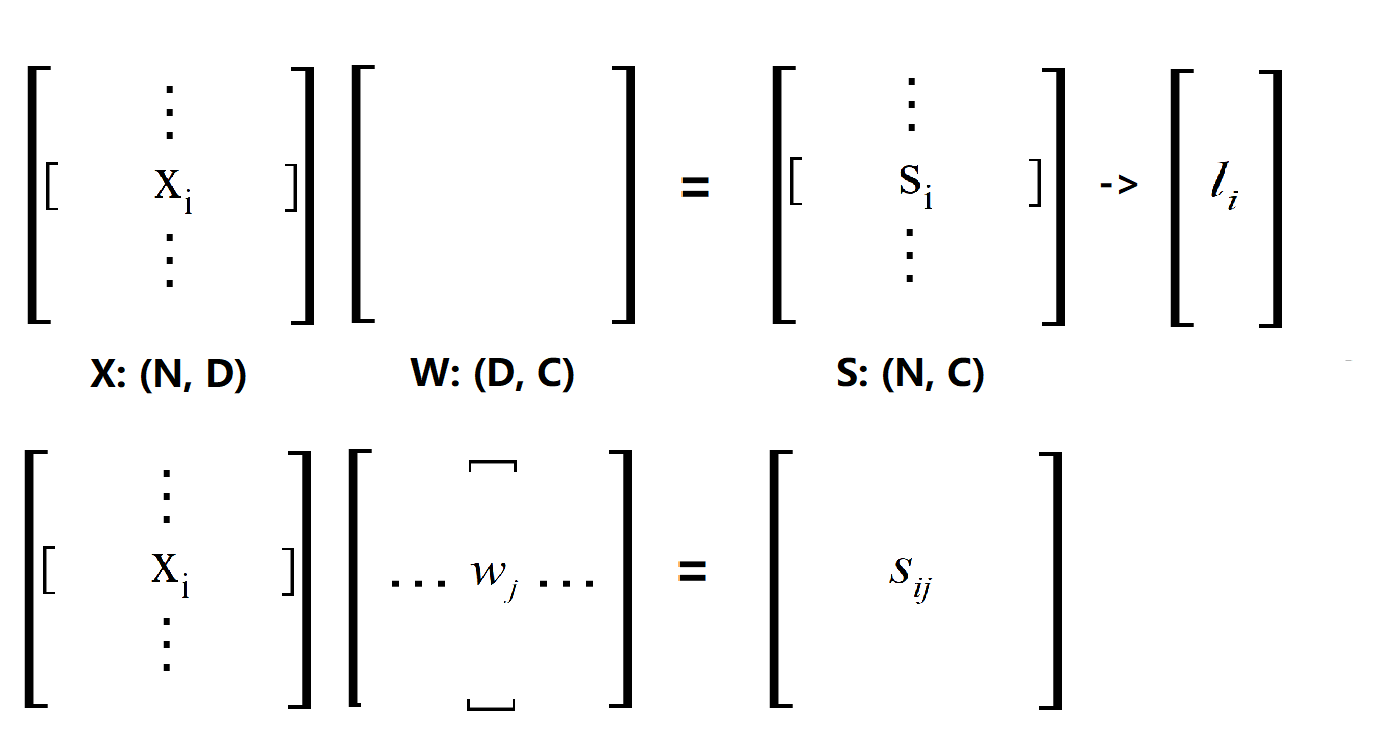
X·W得到的S矩阵,对应代码中的scores,然后根据给出的公式(y是正确类的序号向量):
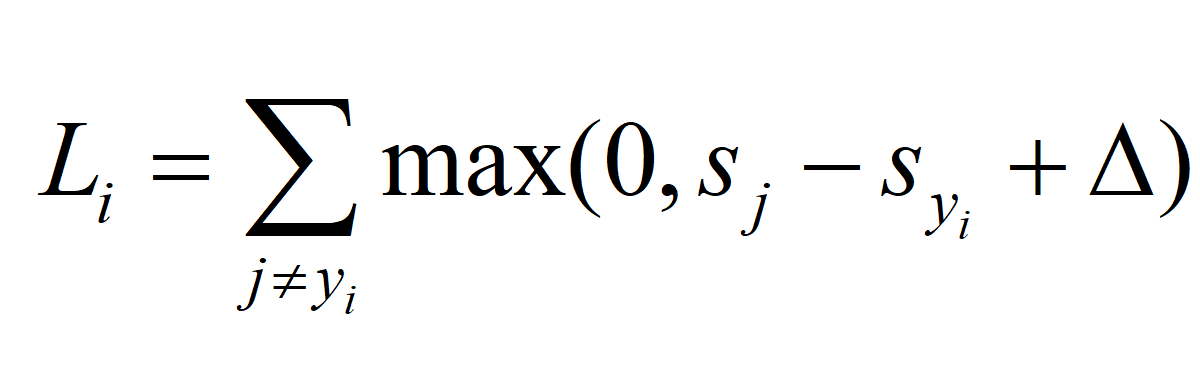
得到 L 矩阵(或者说 L 向量,要注意公式给出的只是计算一条样本的loss),然后求和得到最终的Loss,前面的不用多说。接下来是难点,如何求Loss对W的梯度,首先我们将公式写成原来的样子:

求Loss的过程是先对 i 求和,再对 j 求和的过程,那我们直接用 L(ij)来分析,L(ij)的来源是什么?首先 max()函数后面一部分要大于0,不然对 L(ij) 没有贡献,然后 j != y(i) ,因为 j == y(i) 压根就不算进公式里面,所以 L(ij) 的来源是 j != y(i) 的情况下,max()函数后面要大于0 的部分,那么要给W更新,自然也是这一部分,怎么更新的呢?哦我们给dw(j) 加上 x(i), 同时要给dw(y(i)) 加上 -x(i) 就可以了。要注意的是,在上面这个公式里面,i 不是求和的变量,所以 x(i) 我们可以看成是等着被加的东西,我们看下面一副图 (delta == 1, 与代码一致):
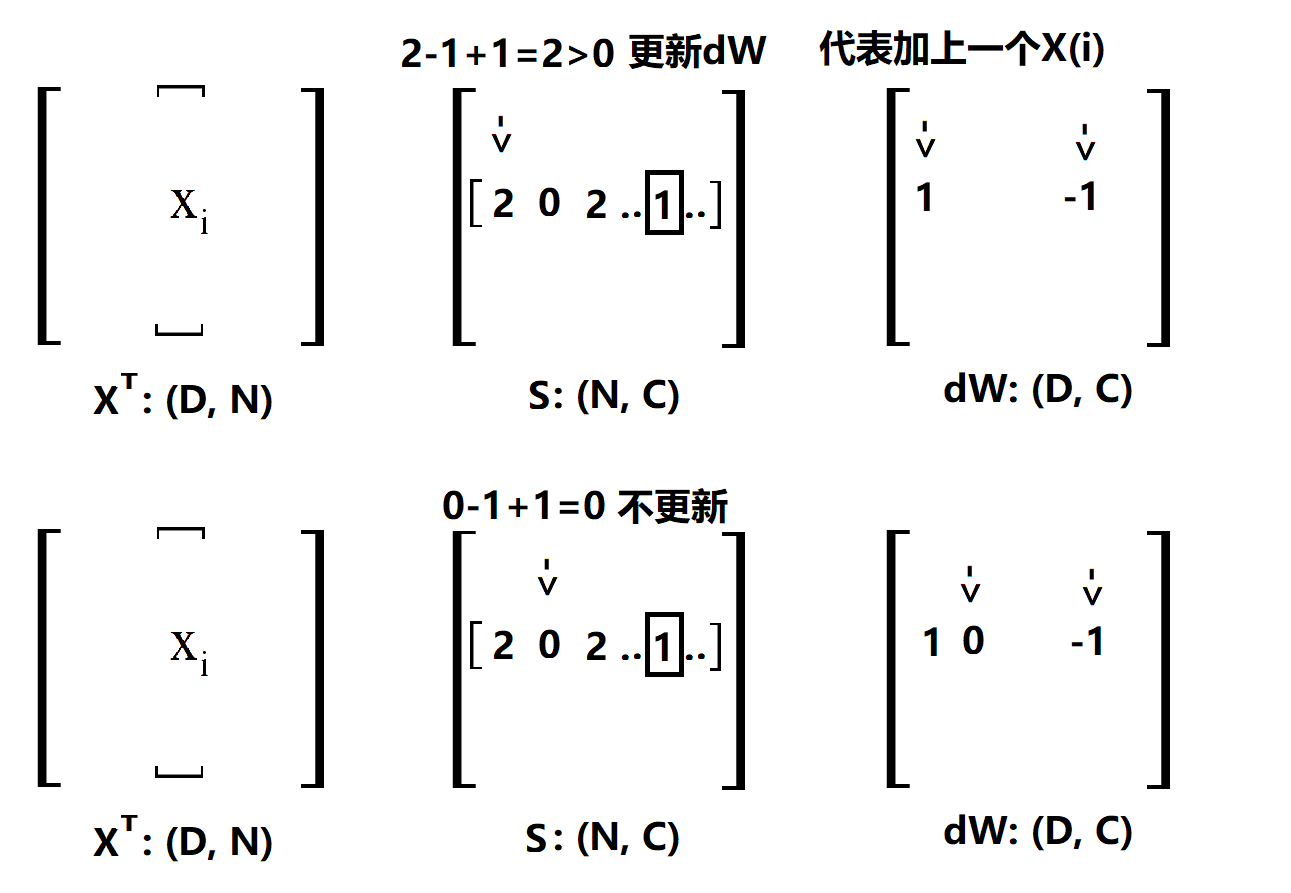
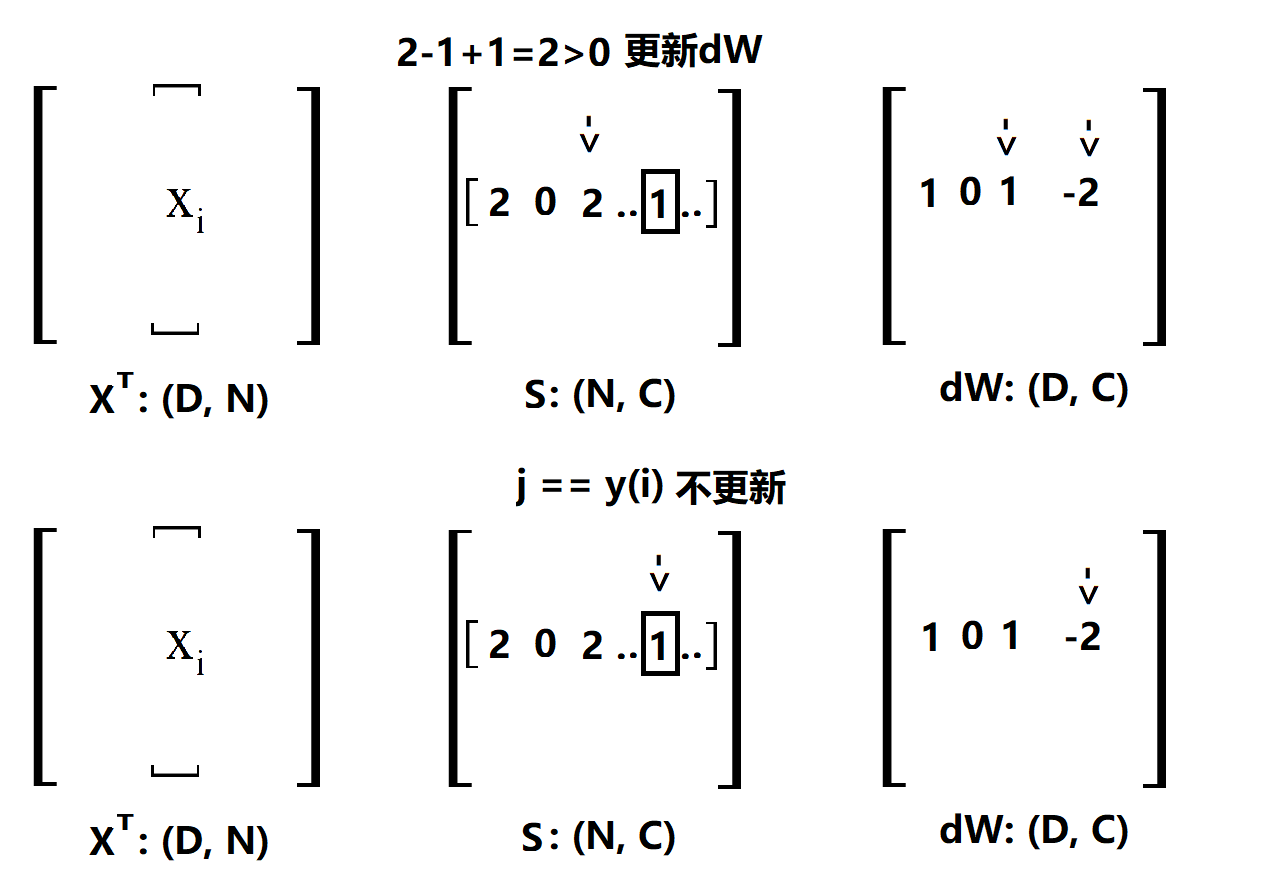
说明一下,一行一行的来看,首先确定一个 i,然后扫描 S(i),这里的 S 就是 X·W,没处理过之前的scores,用方框框住的表示正确类。第一个是2,计算max()的结果为2,所以更新dW,那么我要在dW的第一个位置加 x(i) 在 y(i) 的位置加 -x(i), 为了方便后面解释,这里写1就表示加一个 x(i) ,-1就表示加一个 -x(i)。第二个位置是0,max()结果是0,不更新,后面类似。经过上面的4步,最后得到的dW是这样的(将就着看一看):
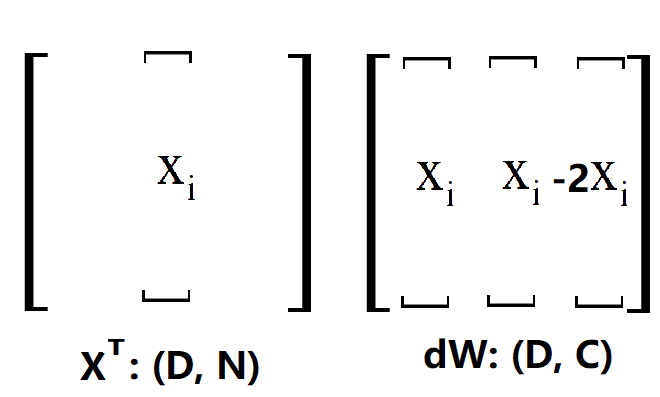
OK,其实这里已经很清楚了,刚刚做出来的是一个用于更新的向量 [ 1 0 1 .. -2 ..],只要用 XT 点乘这个更新的向量就可以得到dW了,这很容易理解,因为对这个更新向量里面的值,比如说第一个1,相当于用这个1数乘x(i)。当然了,上面只是对第 i 条样本做的更新,因为我们是看 L(ij) 的,所以还要把剩下的样本都做一次,代码中的margin就是所有的更新向量放在一起而已,比如说这样(向量不止3个,不然不会出现-3):
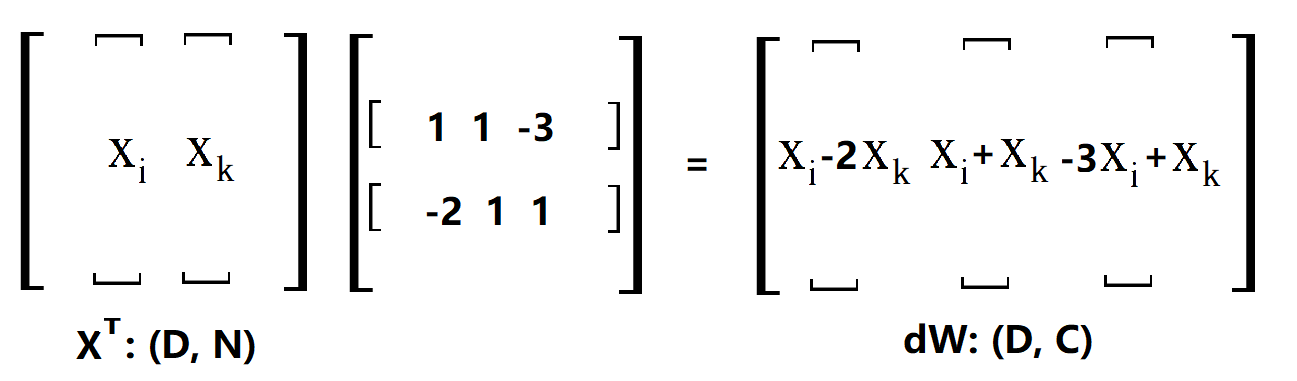
margin[np.arange(num_train),y]=0.0
margin[margin>0]=1.0
row_sum = np.sum(margin,axis=1)
margin[np.arange(num_train),y] = -row_sum 代码当中一开始的margin是在S矩阵的基础上算好了 s(j) - s(y(i))+1 的矩阵,这样就可以直接判断是否需要更新,第一步把所有y的位置置0,第二步把>0的位置置1,这样,只有s(j) - s(y(i))+1>0 且 j != y(i) 的位置为1,第三步计算一行中有多少个1,在第4步为y的位置置为这个数的负数, 就是因为在扫描 S[i] 的过程中,每有一个 w(j) 要更新就要同时更新 w(y(i)) 的缘故,这和之前的分析一致。
这是个人的一些理解,如果有出错的,希望大家能够指出。















 9935
9935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









